







 本文介绍了如何使用R语言进行数据描述统计,包括计算平均数、分位数、极差、四分位差、标准差、偏度系数和峰度系数,并以50名网络购物消费者为例,分析了网购金额的分布特点。结果显示,网购金额呈现中等偏右的右偏分布和尖峰特性。
本文介绍了如何使用R语言进行数据描述统计,包括计算平均数、分位数、极差、四分位差、标准差、偏度系数和峰度系数,并以50名网络购物消费者为例,分析了网购金额的分布特点。结果显示,网购金额呈现中等偏右的右偏分布和尖峰特性。
目录
数据描述统计量
1、描述水平的统计量
(1)平均数
平均数是一组数据的均值,在R语言中使用mean函数计算平均数。
mean(x,trim=0,na.rm=FALSE)中,x为数值向量,trim表示计算均值前去掉与均值差较大数据的比例,比如trim=0.1表示去掉前10%和后10%的数据后再进行平均数计算,缺省值为0即包括全部数据,trim值在0~0.5之间,na.rm表示是否允许缺失数据。
(2)分位数
分位数是一组数据排序后处于具体百分比位置的数值,在计算前必须对数据进行排序,在R语言中使用quantile函数计算分位数。
quantile(x, probs, na.rm = FALSE)中,x为数值向量,probs表示取值在[0,1]之间的分位数向量,即用小数表示分位值。
2、描述差异的统计量
(1)极差
极差是一组数据的最大值与最小值之差,在R语言中使用diff函数计算极差。
(2)四分位差
四分位差是一组数据75%位置上的四分位数与25%位置上的四分位数之差,反映了中间50%的数据的离散情况,数值越小,表明中间数据越集中,反之。在R语言中使用IQR函数计算四分位差。
(3)标准差
标准差为方差开平方根的结果,在R语言中使用sd函数计算标准差。
3、描述分布形状的统计量
(1)偏度系数
偏度系数(SK)用于测度数据分布不对称性,当数据对称分布时,SK = 0,偏度系数越接近0,偏斜程度越低。若SK > 1或SK < -1,视为严重偏斜分布;若0.5 < SK < 1或-1 < SK < -0.5,视为中等偏斜分布;若0 < SK < 0.5或-0.5 < SK < 0,视为轻微偏斜分布。偏度系数为负值表示左偏分布,为正值表示右偏分布。在R语言中使用skewness函数计算偏度系数。
(2)峰度系数
峰度系数(K)用于测度数据分布峰值高低,K = 0为标准正态分布峰值,K > 0为尖峰分布,数据相对集中;K < 0为扁平分布,数据相对离散。在R语言中使用kurtosis计算峰度系数。
4、数据标准化
(1)标准分数
标准分数是把一组数据变换成均值为0,方差为1的另一组数据,可用于度量每个数值在该组数据中的相对位置判断一组数据是否有离散点。在R语言中使用scale函数计算标准分数。
(2)极值标准化
极差标准化是将一组数据缩放到[0,1]的范围内,公式为Ti=(Xi-Xmin)/(Xmax-Xmin)。
题目
(统计学-基于R-第五版-第四章习题4.1)
随机抽取50名网络购物的消费者,调查他们某个月的网购金额(单位:元),结果如下表所示。
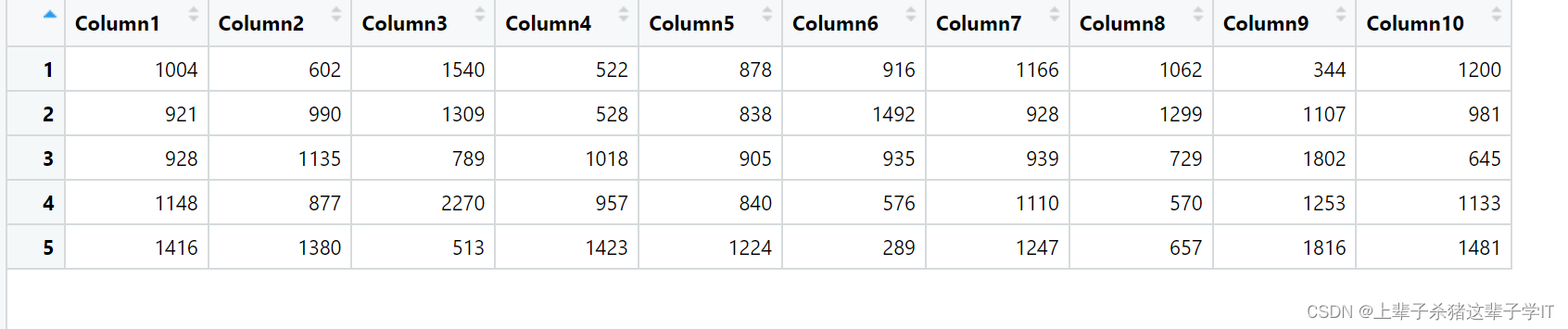
- 计算平均数、标准差、极差和四分位差。
- 计算10%、25%、50%、75%、90%的分位数。
- 计算标准分数和极差标准化值。
- 计算偏度分数和峰度系数,分析网购金额的分布特点。
实现代码和结果
实现代码如下:
#引入消费者网购金额表
example2<-read.csv("C:/Users/lenovo/OneDrive/大二/大数据统计学实验/实验表格/网购金额表格.csv")
tab1<-as.vector(as.matrix(example2)) #表格转换为向量
#求平均分
mean(tab1)
#求标准差
sd(tab1)
#求极差
diff(range(tab1))
#求四分位差
IQR(tab1,type=7)
#求10%、25%、50%、75%、90%的分位数
quantile(tab1,probs=c(0.10,0.25,0.50,0.75,0.90))
#求标准分数
as.vector(round(scale(tab1),4))
#求极值标准化值
d=tab1
T<-(d-min(d))/(max(d)-min(d))
round(T,4)
#求偏度系数
library(e1071)
skewness(tab1,type=3)
#求峰度系数
kurtosis(tab1,type=3)计算结果如下:
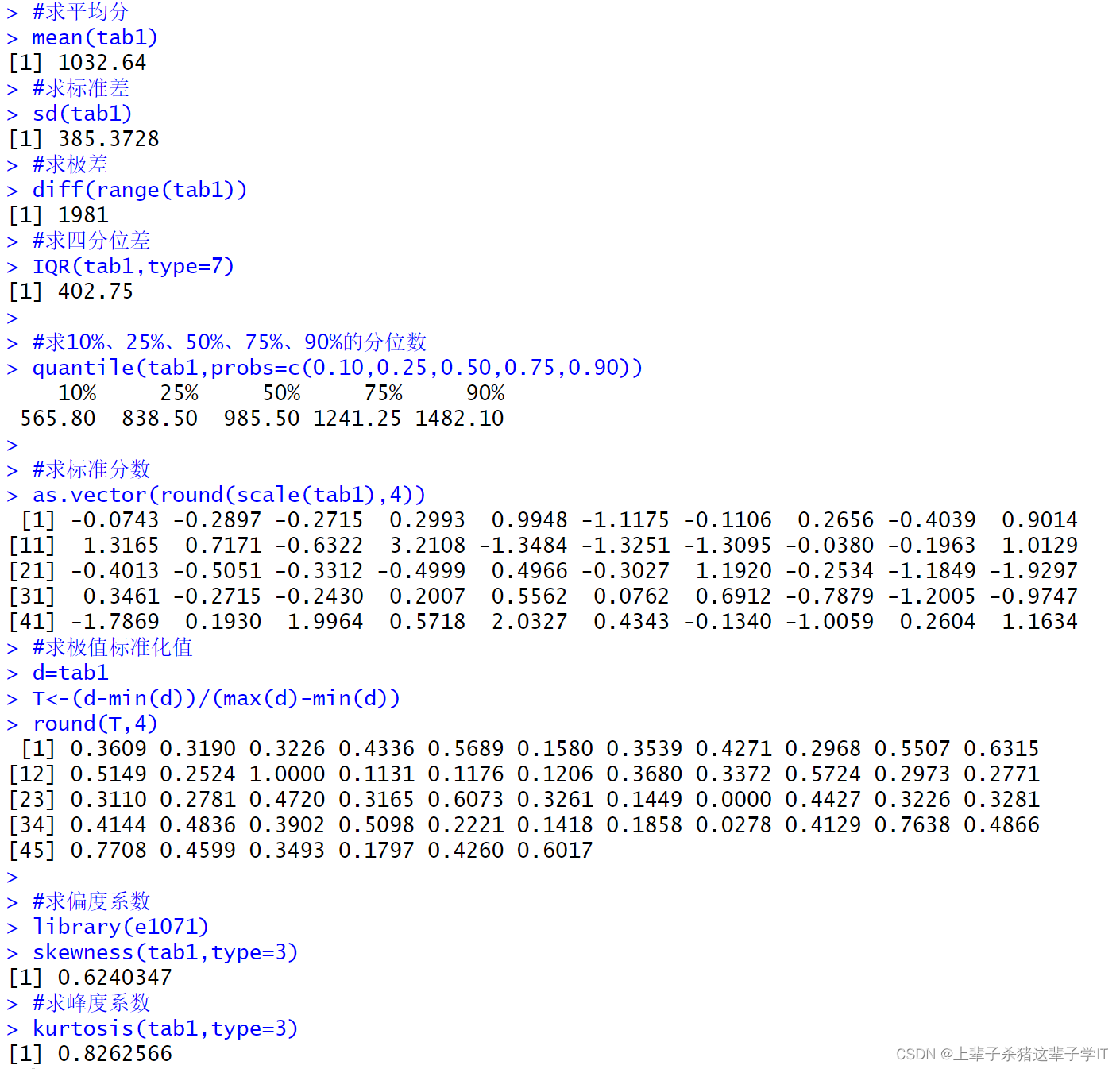
网购金额分布特点分析:由计算结果可知,偏度系数为0.6240347,表示消费者的网购金额为中等偏斜的右偏分布,峰度系数为0.8262566,表示消费者的网购金额峰值比标准正态分布要高一些,为尖峰分布,也相对集中。

















 2389
2389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









