






考虑到要结合llm,我们进而想到直接偏好优化DPO,尽管诸如chatGPT等llm使用的是基于强化学习人类反馈RLHL,但考虑到rlhl计算成本高,复杂度大,并且我们想要迁移到推荐系统,我们还是先考虑DPO。
以下是DPO学习笔记:
一、先前工作的分类、方法及缺点分析
1)基于监督微调(Supervised Fine-Tuning)的方法
方法:通过人工标注的高质量回答(如专家撰写的指令响应)直接微调模型。例如,指令微调(Instruction-Tuning)通过将任务描述(指令)与正确答案配对,让模型学习遵循指令生成高质量内容。
缺点:
依赖高质量标注数据:需要大量专家级的人类示范数据,成本高昂且难以覆盖所有用户需求。
无法捕捉复杂偏好:人类偏好是多样且隐式的,单纯模仿有限示范数据难以泛化到所有场景(例如模型可能学会错误但高频的编程习惯)。
2)基于强化学习人类反馈(RLHF/RLAIF)的方法
方法:
奖励建模:用人类对回答的偏好标注(如A比B好)训练一个奖励模型(Reward Model),建模人类偏好。
强化学习优化:通过RL算法(如PPO)最大化奖励模型的输出,同时约束模型不要偏离原始模型太远(KL散度约束)。
缺点:
流程复杂:需维护奖励模型和策略模型,涉及多阶段训练。
计算成本高:RL需反复从策略模型采样生成回答,计算开销大。
训练不稳定:RL超参数敏感(如KL惩罚系数),易出现梯度爆炸或策略崩溃。
奖励模型偏差:奖励模型可能无法完美拟合人类偏好,导致策略优化偏离真实目标。
3)基于偏好学习的非RL方法(如CDB/PbRL)
方法:在非语言模型领域(如赌博机或机器人控制):
上下文赌博机(CDB):在线学习时通过偏好反馈选择动作(如A比B好),目标为找到“胜率最高”的策略。
偏好强化学习(PbRL):将偏好视为隐式评分函数,先估计奖励再优化策略。
缺点:
依赖在线交互:CDB需实时获取偏好反馈,不适用于离线数据。
间接优化:PbRL仍需显式建模奖励函数,无法直接优化策略。
我们会思考,为什么会这样呢?
我认为有下面三点,RL的固有复杂性,难以训练,奖励建模的局限性,人类偏好可能无法完全由标量奖励函数表示,数据效率低下,训练过程复杂。
二、本文的动机与问题建模
Motivation(核心动机)
问题发现:现有RLHF方法虽有效但复杂,需两阶段训练(奖励建模+RL优化),导致计算成本高、调试困难。
关键洞察:是否可以直接优化策略,绕过显式的奖励建模和RL步骤?
目标:提出一种单阶段、无强化学习的方法,直接通过偏好数据优化策略,简化流程并提升稳定性。
1.原RLHL目标:最大化奖励函数,同时约束策略与原模型的KL散度
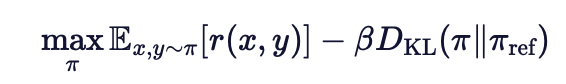
其中r(x,y)为奖励函数,ref为原始模型
2.关键变换:通过数学推导,将奖励函数 r(x,y) 与策略 π 隐式绑定,证明最优策略可表示为:
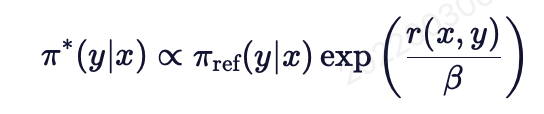 由此可将原问题转化为直接优化策略 π
由此可将原问题转化为直接优化策略 π
3.损失函数:

其中 y w和 y l是偏好对中的优/劣回答,σ 是sigmoid函数。
好处:
去复杂化:无需训练奖励模型或RL优化,直接用分类损失微调策略。
稳定性:损失函数仅依赖策略的生成概率比,避免RL中的策略采样和方差问题。
理论保障:通过数学变换严格等价于原RLHF目标,但实现更简单高效。
三、方法详解:Direct Preference Optimization (DPO)
核心思想
DPO通过隐式奖励参数化,将传统RLHF的两阶段(奖励建模+RL优化)简化为单阶段优化,直接通过偏好数据调整策略(语言模型),无需显式奖励模型或强化学习。





设计动机与优势
避免RL复杂性:传统RLHF需PPO等算法,涉及策略采样、方差高的优势函数估计,DPO通过闭式解绕过这些步骤。
隐式奖励建模:将奖励函数嵌入策略参数中,避免显式奖励模型的训练误差传递。
稳定高效:单一交叉熵损失,无需策略采样或多次迭代,适合大规模模型微调。
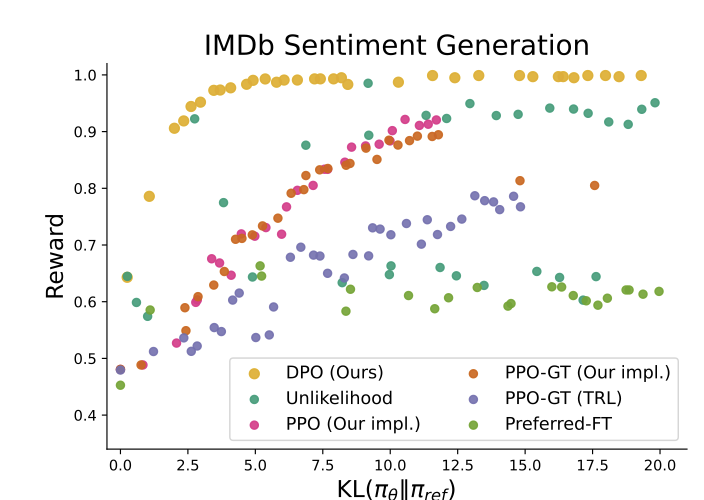
可以看到在所有的KL值下均能提供最高的期望奖励。

















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









