







大数据技术概述
大数据技术层面及其功能
数据采集与预处理
- 利用ETL(extract-transform-load)工具将分布的、异构数据源中的数据,如关系数据、平面数据文件等,抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中,成为联机分析处理、数据挖掘的基础;
- 利用日志采集工具把实时采集的数据作为流计算系统的输入,进行实时处理分析;
- 利用网页爬虫程序到互联网网站中爬取数据。
数据存储和管理
利用文件系统、关系数据库、数据仓库、并行数据库,分布式文件系统、NoSQL数据库、NewSQL数据库等,实现对结构化、半结构化、非结构化数据的存储和管理。
数据处理与分析
利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘等算法,实现对海量数据的处理和分析。
数据可视化
对分析结果进行可视化呈现,帮助人们更好地理解数据、分析数据。
数据安全和隐私保护
在从大数据中挖掘潜在的巨大商业价值和学术价值的同时,构建隐私数据保护体系和数据安全体系,有效保护个人隐私和数据安全。
数据采集与预处理
数据采集
定义:数据采集,又称数据获取,是利用一种装置,从系统外部采集数据并输入到系统内部的一个接口。
过程:它通过各种技术手段把外部各种数据源产生的数据进行实时或非实时地采集,获得各种类型的结构化、半结构化以及非结构化的海量数据并加以利用。
数据分类
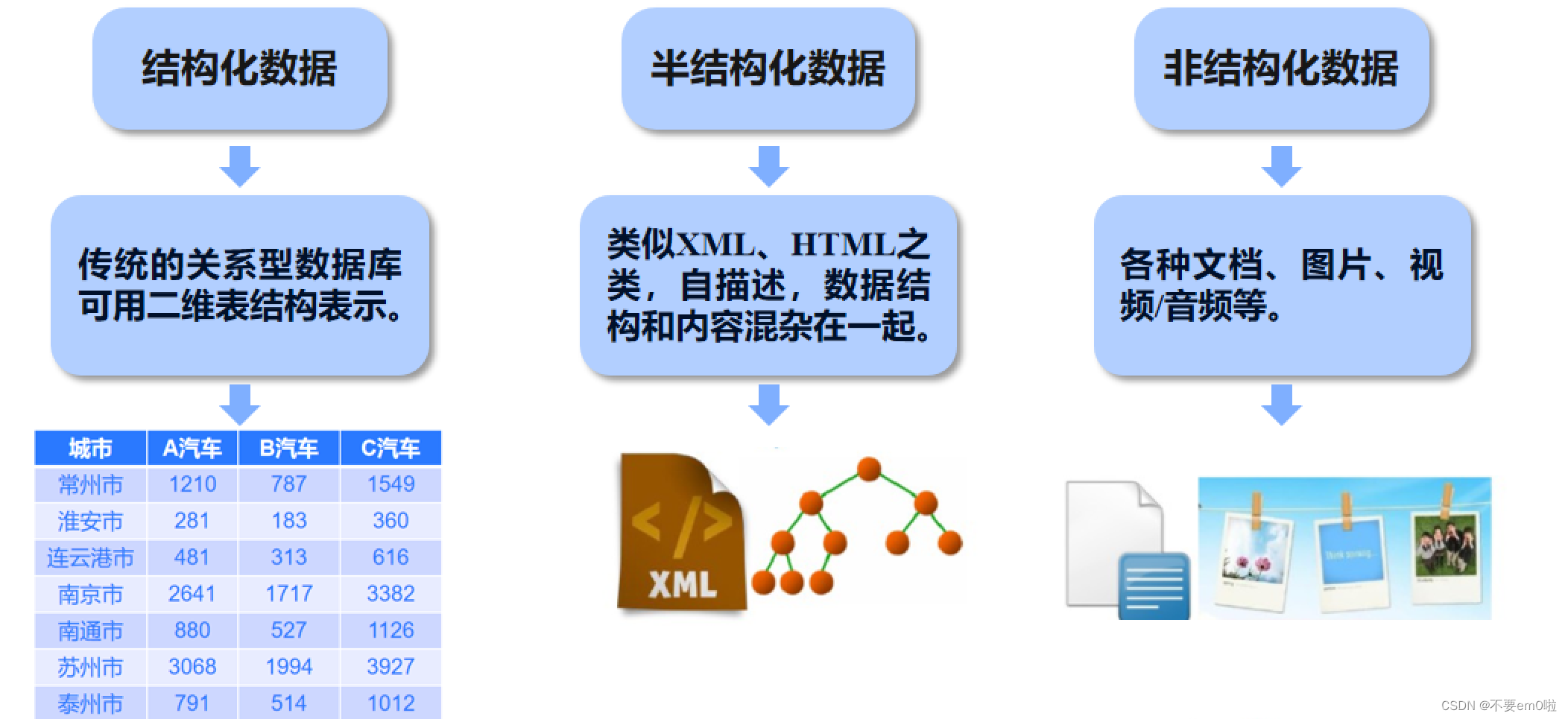
数据采集方式
大数据的采集通常采用多个数据库来接收终端数据,包括智能硬件端、多种传感器端、网页端、移动APP应用端等,并且可以使用数据库进行简单的处理工作。
数据采集数据源
- 数据源: 企业业务系统数据:企业产生的业务数据,以数据库一行记录的形式,被直接写入到数据库中。企业使用传统的关系数据库MySQL和Oracle,或Redis和MongoDB这样的NoSQL数据库来存储业务系统数据。
- 传感器:是一种检测装置,能感受到被测量的信息,并转化为其他形式的信息输出,以满足信息的传输、处理、存储、显示、记录和控制等要求。
- 日志文件:日志文件系统一般由数据源系统产生,用于记录数据源的执行的各种操作活动。比如网络监控的流量管理,金融应用的股票记账和Web服务器记录的用户访问行为。
- 互联网数据:互联网数据采集是借助网络爬虫来实现的,通过对网页数据的定向抓取。数据存储与管理
数据采集要点
- 全面性:数据量大具有分析价值;数据面全,支撑分析需求。比如对于“查看商品详情”这一行为,需要采集用户触发时的环境信息、会话、以及背后的用户id,最后需要统计这一行为在某一时段触发的人数、次数、人均次数、活跃比等。
- 多维性:灵活、快速自定义数据的多重属性和不同类型,满足不同的分析目标。比如“查看商品详情”这一行为,通过埋点,我们才能知道用户查看的商品是什么、价格、类型、商品id等多个属性。从而知道用户看过哪些商品、什么类型的商品被查看的多、某一个商品被查看了多少次。而不仅仅是知道用户进入了商品详情页。
- 高效性:高效性包含技术执行的高效性、团队内部成员协同的高效性、数据分析需求和目标实现的高效性。还要考虑数据的及时性。
数据清洗
数据清洗是指将大量原始数据中的错误信息“洗掉”,它是发现并纠正数据文件中可识别的错误的最后一道程序,包括:一致性检查、无效值和缺失值处理等。
需要清洗的数据的主要类型: 残缺数据、错误数据、重复数据。
数据清洗的内容
- 一致性检查:根据每个变量的合理取值范围和相互关系,检查数据是否合乎要求,发现超出正常范围、逻辑上不合理或者相互矛盾的数据。
- 无效值和缺失值的处理:由于调查、编码和录入误差,数据中可能存在一些无效值和缺失值,需要给予适当的处理。
无效值和缺失值的处理方法
- 整例删除:适合关键变量缺失,或者含有无效值或缺失值的样本比重很小的情况。
- 变量删除:如果某一变量的无效值和缺失值很多,且对研究内容的不是很重要,该变量可以删除。
- 成对删除:用一个特殊码代表无效值和缺失值,同时保留数据集中的全部变量和样本。
- 估算: 统计法:对于数值型的数据(连续值),使用均值、加权均值、中位数等方法补足;对于分类型数据(离散值),使用类别众数最多的值补足。
- 模型法:基于已有的字段,将缺失字段作为目标变量进行预测,从而得到最为可能的补全值。如果带有缺失值的列是数值变量(连续值),采用回归模型补全;如果是分类变量(离散值),则采用分类模型补全。
- 专家补全:对于少量且具有重要意义的数据记录,专家补足也是非常重要的一种途径。
- 其他方法:例如随机法、特殊值法、多重填补等。
















 4163
4163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









