







Hi~!这里是奋斗的明志,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~
🌱🌱个人主页:奋斗的明志
🌱🌱所属专栏:笔试强训
📚本系列文章为个人学习笔记,在这里撰写成文一为巩固知识,二为展示我的学习过程及理解。文笔、排版拙劣,望见谅。

笔试强训
一、ACM模式下(Java)
- 在ACM模式环境下,输入和输出的时候会先将输入输出的东西放在一个文件里面,这个文件可以称为IO设备

1、为什么 Scanner 在输入的时候会慢
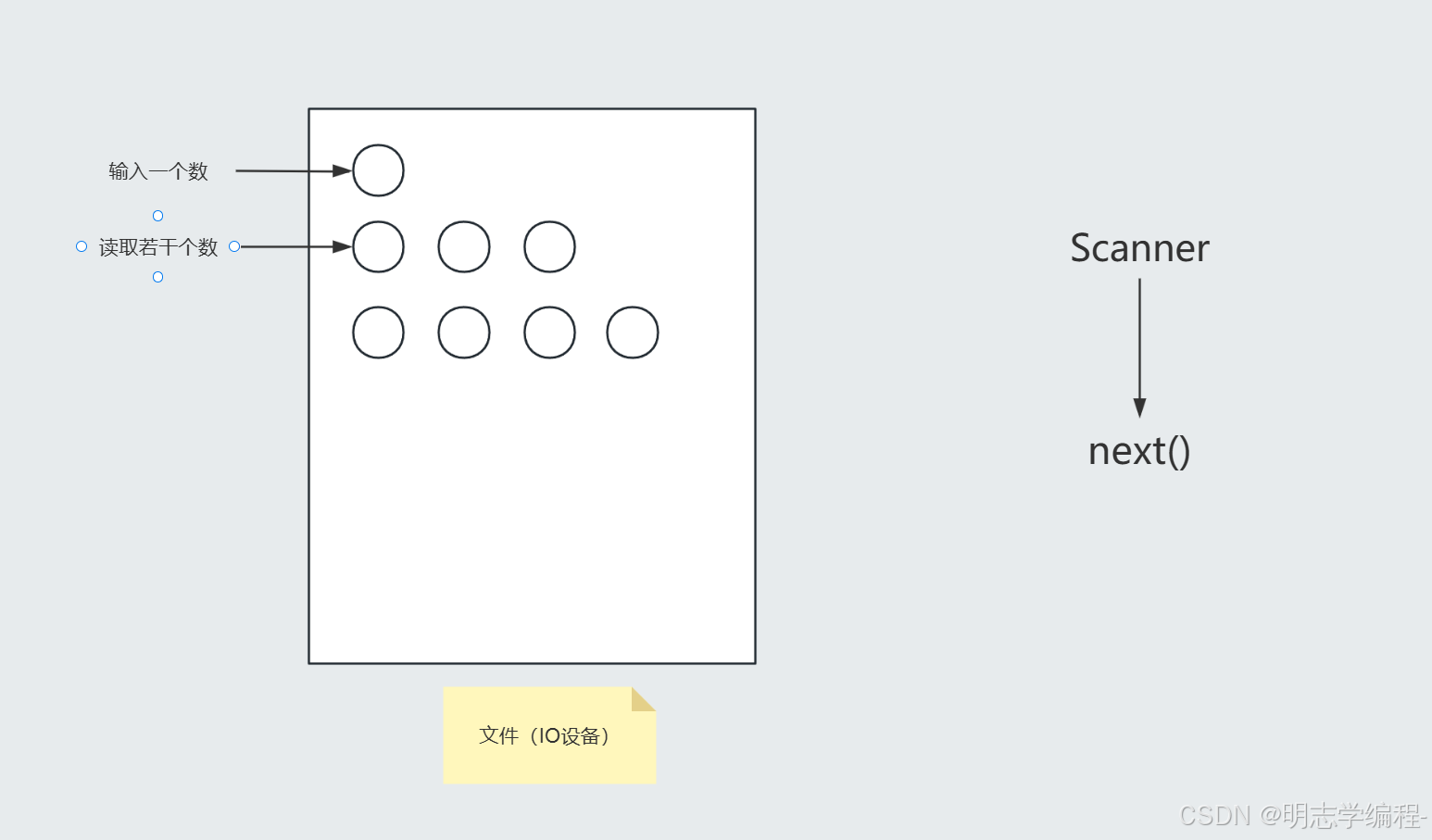
new 一个 Scanner ,在 Scanner 里面调用 next 的时候,程序会直接访问 IO 设备。在调用一个 next() 的时候,只会在 IO 设备中拿出一个数,再将这个数返回程序
调用一个 next() 就会访问一次 IO 设备,程序访问 IO 设备的速度特别慢。所以当输入的数据量很大的时候,就会多次访问这个 IO 设备,所以就会超时。
2、为什么 System.out 在输出的时候会慢
和 Scanner 读取数据一样。当输出数据的时候,也是将数据一个一个拿到 IO 设备中。由于程序访问 IO 设备的速度特别慢,所以只要数据量稍微多一些,就会超时
二、利用自定义快读模版(Java)
Java 在处理 IO 的时候,有两套标准:
字节流(System.in)
字符流(带 Reader 或者 Writer)
import java.util.*;
import java.io.*;
public class Main
{
public static PrintWriter out = new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out)));
public static Read in = new Read();
public static void main(String[] args) throws IOException
{
// 写代码
out.close();
}
}
class Read // 自定义快速读入
{
// 字符串分割器
StringTokenizer st = new StringTokenizer("");
// 缓冲读取器
BufferedReader bf = new BufferedReader(new InputStreamReader(System.in));
// 核心方法:获取下一个输入片段
String next() throws IOException
{
while(!st.hasMoreTokens())
{
st = new StringTokenizer(bf.readLine());
}
return st.nextToken();
}
String nextLine() throws IOException
{
return bf.readLine();
}
int nextInt() throws IOException
{
return Integer.parseInt(next());
}
long nextLong() throws IOException
{
return Long.parseLong(next());
}
double nextDouble() throws IOException
{
return Double.parseDouble(next());
}
}
三、Java StringTokenizer 类使用方法
Java StringTokenizer 属于 java.util 包,用于分隔字符串。
StringTokenizer 构造方法:
- StringTokenizer(String str) :构造一个用来解析 str 的 StringTokenizer 对象。java 默认的分隔符是空格(“”)、制表符(\t)、换行符(\n)、回车符(\r)。
- StringTokenizer(String str, String delim) :构造一个用来解析 str 的 StringTokenizer 对象,并提供一个指定的分隔符。
- StringTokenizer(String str, String delim, boolean returnDelims) :构造一个用来解析 str 的 StringTokenizer 对象,并提供一个指定的分隔符,同时,指定是否返回分隔符。
StringTokenizer 常用方法:
- int countTokens():返回nextToken方法被调用的次数。
- boolean hasMoreTokens():返回是否还有分隔符。
- boolean hasMoreElements():判断枚举 (Enumeration) 对象中是否还有数据。
- String nextToken():返回从当前位置到下一个分隔符的字符串。
- Object nextElement():返回枚举 (Enumeration) 对象的下一个元素。
- String nextToken(String delim):与 nextToken 类似,以指定的分隔符返回结果。
1、案例一
import java.util.*;
public class Main
{
public static void main(String[] args)
{
String str = "runoob,google,taobao,facebook,zhihu";
// 以 , 号为分隔符来分隔字符串
StringTokenizer st=new StringTokenizer(str,",");
while(st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
}
}
输出结果为:
runoob
google
taobao
facebook
zhihu
2、案例二
import java.util.*;
public class Main
{
public static void main(String args[])
{
System.out.println("使用第一种构造函数:");
StringTokenizer st1 = new StringTokenizer("Hello Runoob How are you", " ");
while (st1.hasMoreTokens())
System.out.println(st1.nextToken());
System.out.println("使用第二种构造函数:");
StringTokenizer st2 = new StringTokenizer("JAVA : Code : String", " :");
while (st2.hasMoreTokens())
System.out.println(st2.nextToken());
System.out.println("使用第三种构造函数:");
StringTokenizer st3 = new StringTokenizer("JAVA : Code : String", " :", true);
while (st3.hasMoreTokens())
System.out.println(st3.nextToken());
}
}
使用第一种构造函数:
Hello
Runoob
How
are
you
使用第二种构造函数:
JAVA
Code
String
使用第三种构造函数:
JAVA
:
Code
:
String


四、BufferedReader
它是一个带内存缓冲区的字符流。将要读取数据的时候,先将 IO 设备里面的数据一次性放到这个"内存缓冲区中"。然后 BufferedReader 再调用 next() 的时候,就是直接在内存缓冲区里面拿数据的
这对比 Scanner 调用 next 之后,一次一次地重复在 IO 设备中读取数据来说,BufferedReader 在调用 next 的时候,只需要读取一次内存缓冲区,就能读取到所有数据。
直接从内存中拿数据,肯定是比访问 IO 设备要快得多的
1、为什么要用while循环
因为有一些输入输出的题目,输入的数据不止只有一行,当把第一行的数据一个一个裁完之后,你是要读取下一行数据的。所以需要一个 while 循环判断,当后面没有数据了,就重新再读入一行,然后再返回新读入的一行的字符串
BufferedReader 相较于 System.in 快,就是因为他带了一个缓冲区。先把文件里面的数据刷新到缓冲区里面,然后在缓冲区里面拿一行一行的数据。随后通过 StringTokenizer 将读取的一行一行数据(bf.readLine())一个个地进行裁剪工作。当后面还有的行时候,就一个一个的裁;当后面没有行的时候,就再重新读一行,一个一个地裁
2、快速写
new BufferedWriter(new OutputStreamWriter(System.in))
这里是把字符流转换为字节流
此处的 BufferedReader 是在输出的时候,不直接将数据从 IO 设备输出到程序,而是先将数据输出到内存缓冲区中,然后程序在内存缓冲区中直接读取数据(与输入原理一致)
PrintWriter 其实 BufferedWriter 已经满足我们的需求了,为什么还要套一层 PrintWriter 呢?
因为 BufferWriter 的输出方式不好写,而 PrintWriter 的输出方式和 System.out 是完全一样的(使用方式完全一样)


















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









