






项目一
【项目一描述】(给出系统描述和要求)
1、项目功能基本要求
(1)认识jieba库和wordcloud库;
jieba是Python中一个重要的第三方中文分词函数库,能够将一段中文文本分割成中文词语的序列。 jieba库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组。除了分词jieba还提供增加自定义中文单词的功能。jieba库支持三种分词模式:其一、精确模式,将句子最精确地切开,适合文本分析;其二、全模式,把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;其三、搜索引擎模式,在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
WordCloud是一款Python的第三方库,可以用于生成词云。词云可以以词语为基本单位,然后根据词语的出现频率确定词语的大小,将所有这些词放到一张图片里,就可以更只管和艺术的展示文本。我们要使用WordCloud库,就需要首先安装,执行命令pip install wordcloud。wordcloud库把词云当作一个WordCloud对象,即 wordcloud.WordCloud() 代表一个文本对应的词云。可以根据文本中词云出现的频率等参数绘制词云绘制词云的形状、尺寸个颜色都可以设定
(2)利用jieba库进行中文词频统计,强调字典、列表的应用;
中文词频统计是文本分析中的常见任务,而jieba是Python中一款优秀的中文分词库,可以帮助我们完成中文词频统计的任务。在这个过程中,字典和列表是非常重要的数据结构。下面是一个使用jieba库进行中文词频统计的示例代码,强调了字典和列表的应用。
首先使用jieba进行分词,并将分词结果存储在一个列表中。然后我们定义了一个停用词列表,并使用列表推导式去除分词结果中的停用词。接着我们使用一个defaultdict(int)来保存词频统计结果,这样我们就可以在对单词进行统计时,直接通过索引访问对应的计数器。最后,我们将词频统计结果输出到文件,其中每一行包括一个单词及其出现的次数,使用tab符分隔。
(3)结合词频统计结果利用wordcloud库进行词云图的可视化;
(4)程序代码存为“学号姓名a.py”,词频统计结果存为“学号姓名a.csv”,词云图存为“学号姓名a.png”;
(5)每个步骤需要运行结果截图,截图中需要加上水印,水印为自己的学号姓名。
2、数据示例
超162亿人次!总台春晚热四海,全球共享中国年!
总台通过68种语言对外新媒体平台,联动全球173个国家和地区的1000多家媒体对春晚进行同步直播和报道。为当地观众带来了耳目一新的文化感受和视听体验。
截至1月26日,总台兔年春晚精编版已在俄罗斯大亚洲电视台、今日哈萨克斯坦通讯社、印度尼西亚NTV等30多国主流媒体播出。节目还通过总台搭建的“融媒体定制化服务平台”等多种渠道在全球120多家主流媒体陆续播出。
春节期间,总台春晚正片或宣传片首度登陆海外1642块户外大屏和院线银幕,其中欧美国家984块。总台2023年春晚吉祥物“兔圆圆”首次登陆美国纽约、华盛顿、洛杉矶等五大城市772块主流院线的电影屏幕。接地气的祝福直海外民众,为影院增添了中国春节欢庆吉祥的氛围。
CGTN多语种主持人、主播在社交媒体平台发起《兔子手势舞》线上挑战活动,全球阅读量突破3.4亿。总台40多个语种的近百名主播陆续推出《这是中国每年最火的节目》《小白兔为何登上春晚大舞台》《这份特殊的“年夜饭”,咱们不见不散!》等特色节目,向海外受众重点推介总台春晚精彩内容和中国春节传统文化。
总台通过68种语言平台快速编译播发春晚报道,多语种记者、主播通过走进外媒演播室、记者连线、接受采访等多种形式登上50余家海外主流媒体平台,宣介总台春晚特色亮点、中国春节传统习俗。
总台多语种对外传播平台与海外总站紧密联动,向海外受众推荐总台春晚及春节文化。截至1月26日,全球超千家海外主流媒体积极转载转发总台春晚相关报道,称赞总台春晚传承中华文明,为全球受众献上中国文化盛宴。
一抹中国红,一缕春意浓。亮相全球的总台春晚,已成为传播中华文明、讲好中国故事的重要窗口。全球受众及媒体的高度关注和广泛好评,汇聚了各国人民的期待和善意,让本届春晚乃至整个春节格外喜庆欢腾。
春晚舞台上,《一带繁花一路歌》沿线国家的代表性花卉与经典歌曲,串联进了中国民歌《茉莉花》中。总台春晚也正像一朵“茉莉花”,不仅刻在了中国人的春节DNA里,也成为了世界对于中国的文化记忆。
花开中华,美美与共。明年春来,期待再会。
项目一知识点
项目一的代码使用了jieba库和wordcloud库来进行文本分词、词频统计和生成词云图的操作。以下是代码中涉及到的主要知识点:
1. jieba库:
使用jieba.cut()函数对文本进行分词,将文本切分成词语。
cuts.get(word, 0)用于统计词语出现的次数。
2. csv模块:
使用csv模块将词频统计结果保存为CSV文件。
writer.writerow()用于写入表头和词频统计结果。
3. WordCloud类:
创建WordCloud对象,设置词云图的各种参数,例如背景颜色、字体路径、最大词数、最大字体大小等。
使用generate()方法根据词频统计结果生成词云图。
to_file()方法将词云图保存为文件。
4. 主程序:
调用count_word()函数对文本进行分词和词频统计,返回词频统计结果。
调用save_to_csv()函数将词频统计结果保存为CSV文件。
调用generate_wordcloud()函数根据词频统计结果生成词云图。
5. 文本处理:
读取文件内容,使用open()函数打开文件并读取内容,使用close()方法关闭文件。
对文本进行分词和统计词频。
设置停用词列表,过滤词云图中不需要显示的常见词语。
这些知识点涉及了文本处理、词频统计、CSV文件操作、词云图生成等方面。通过这段代码,可以了解到如何使用jieba和wordcloud库进行文本处理和可视化。
【项目一实现】
1、创建文件准备好数据
新建记事本把内容存入陈鹏2022231538.txt中,如图1.1

图1.1
2、安装jieba和wordcloud软件包
在终端输入pip install jieba和pip install wordcloud安装jieba和wordcloud软件包。如图1.2
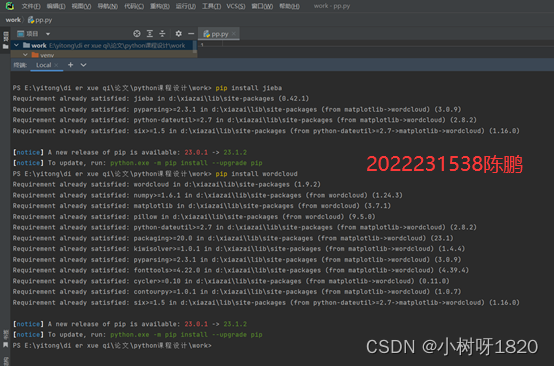
图1.2
3、编写词频统计代码并打印查看结果
使用jieba分词将文本切分成词语words = jieba.cut(string_data) 。return:词频统计结果
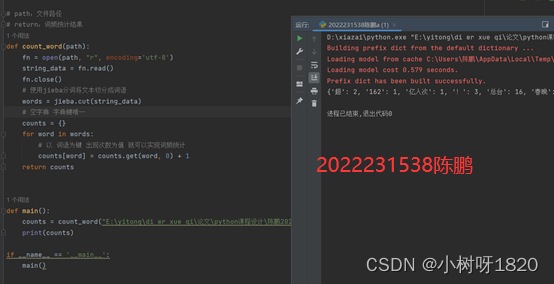
图1.3
4、编写程序代码将词频统计结果存到2022231538陈鹏a.csv
将词频统计结果保存为CSV文件。def save_to_csv(counts, filename):
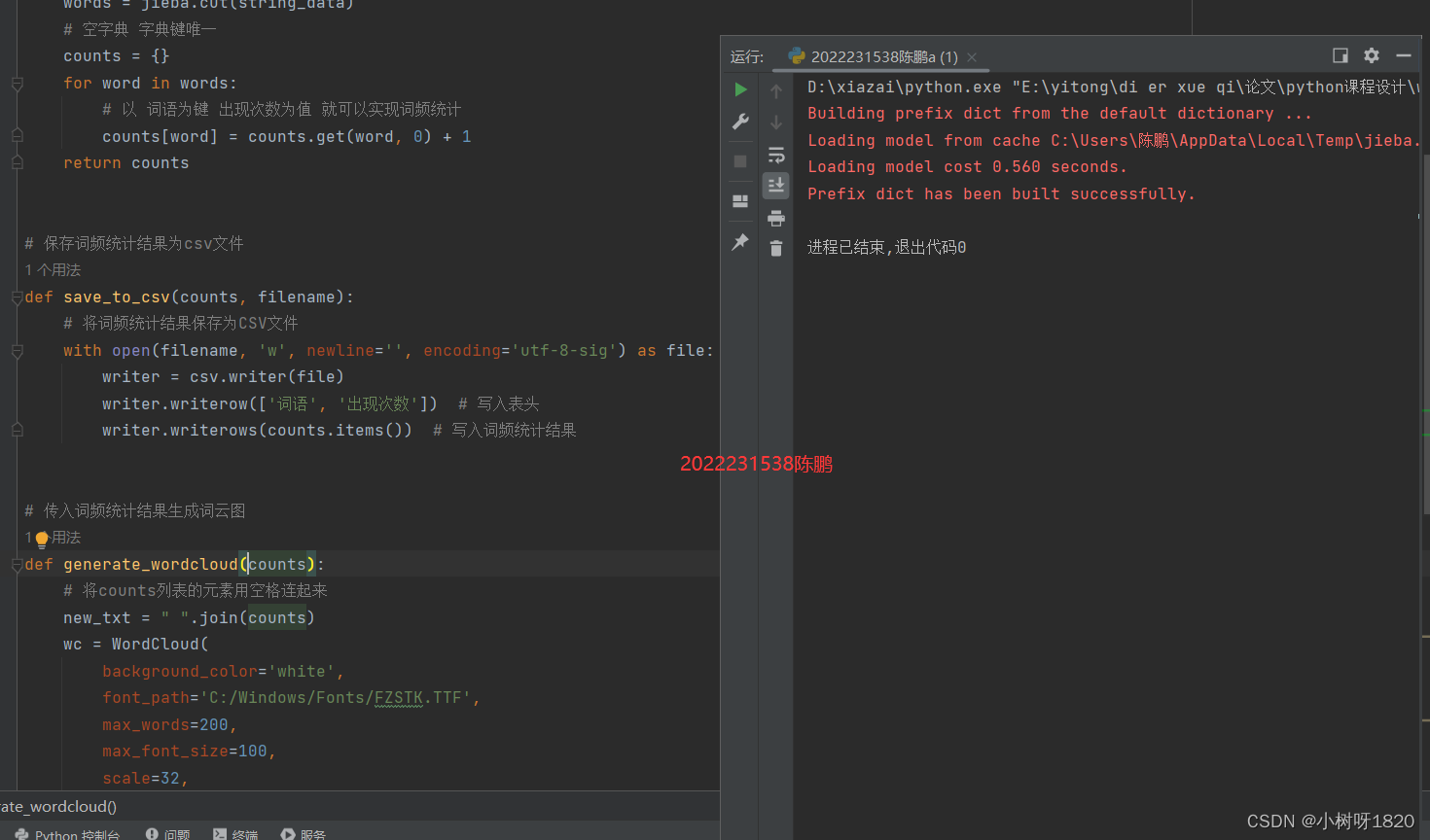
图1.4
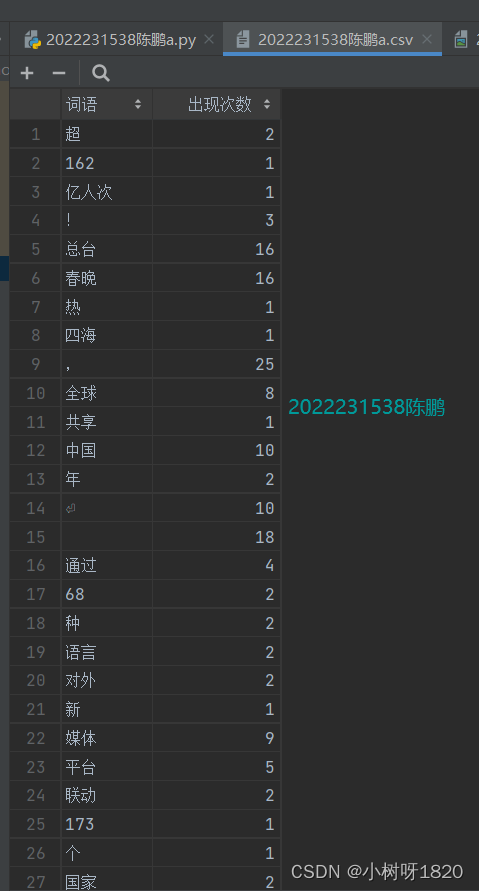
图1.5
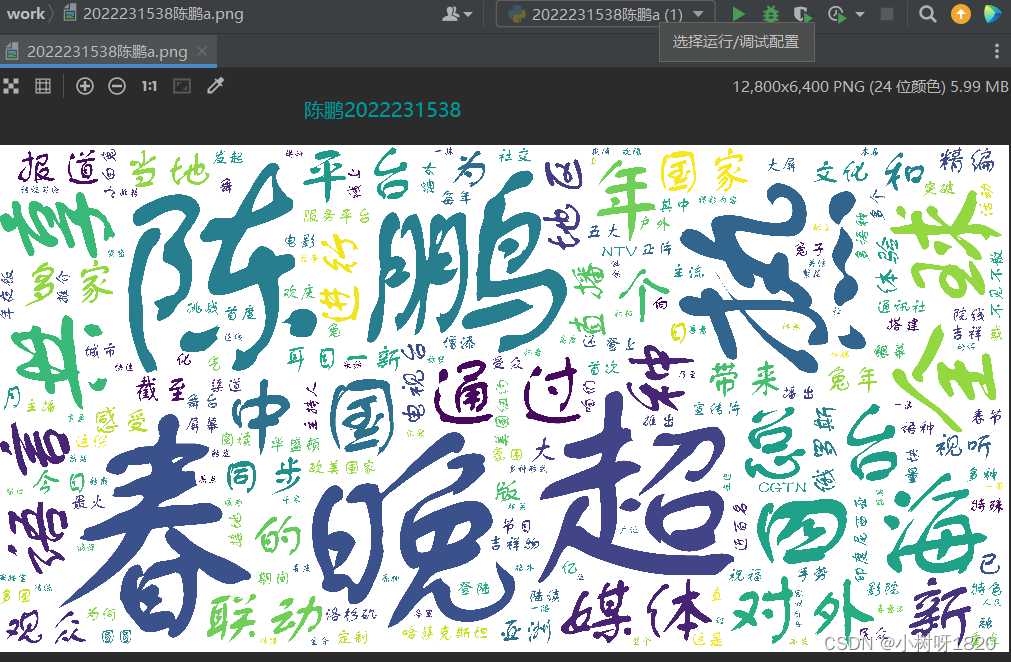
图1.6
5、代码
代码截图:


源码(可复制):
| import jieba |
项目一总结
问题:
没有导入jieba库?代码中的文件路径是否正确?在count_word()函数和main()函数中,读取文件的路径是固定的,是否需要根据实际情况进行修改?
词云图生成过程中,使用了停用词列表来过滤常见词语,但停用词列表中的词语是否适用于您的文本数据?您是否需要根据实际情况自定义停用词列表?
代码中保存CSV文件时使用了绝对路径,这可能导致在不同的操作系统或不同的机器上无法正常保存文件。是否可以考虑使用相对路径或让用户自定义保存路径?
感受:
这段代码使用了jieba库和wordcloud库,展示了如何进行文本分词、词频统计和生成词云图的操作。通过使用这些库,可以更好地理解文本数据并将其可视化。
代码中的注释和命名风格清晰明了,使得代码易于理解和维护。该项目为处理文本数据提供了一种简单而有效的方法,通过统计词频并生成词云图,可以快速了解文本的关键词和出现频率。
代码中的文件操作部分比较简单,但仍然需要注意文件路径的设置,以确保能够正常读取和保存文件。
对于更复杂的文本处理和可视化需求,可能需要进一步扩展代码功能,例如处理多个文本文件、处理特定格式的文本数据等。
问题情况请看下图片

图1.7

图1.8

图1.9
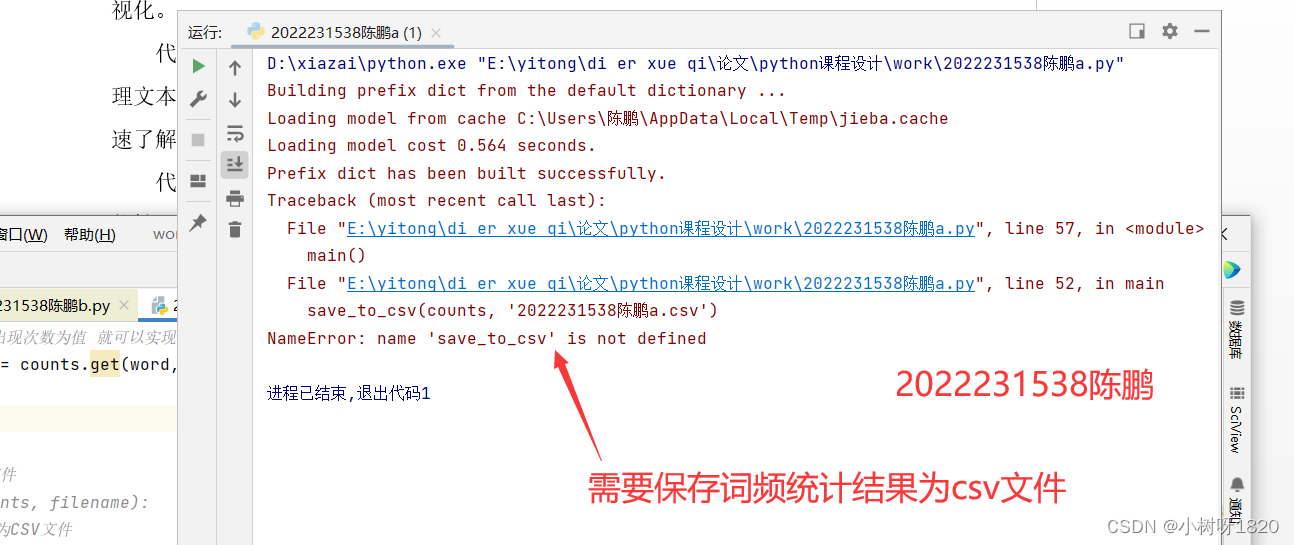
图1.10















 1735
1735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









