






项目三
目录
【项目三描述】
1、项目功能基本要求
(1)了解绘图基础语法与常用参数;
1、绘图是计算机图形学的重要应用之一,而常用的绘图基础语法主要用于二维图形绘制。下面是常用的绘图基础语法和参数:
绘图基础语法:
设置绘图区域:plt.figure()
绘制直线:plt.plot()
绘制散点图:plt.scatter()
绘制柱状图:plt.bar()
添加文本标注:plt.text()
添加标题:plt.title()
添加坐标轴标签:plt.xlabel()和plt.ylabel()
显示图形:plt.show()
2. 常用参数:
线条样式:linestyle=线条样式参数,如-、--、:等
线条粗细:linewidth=线条粗细参数
颜色设置:color=颜色参数,如red、blue、green等
标记点样式:marker=标记点样式参数,如o、*、^等
标记点大小:s=标记点大小参数
图例位置:loc=图例位置参数,如‘upper right’、‘lower left’等
柱状图颜色:color=颜色参数,如red、blue、green等
柱状图宽度:width=柱状图宽度参数
柱状图边框:edgecolor=边框颜色参数,如black、grey等
添加颜色映射:cmap=颜色映射参数,如‘Blues’、‘YlOrRd’等
绘图基础语法和常用参数,可以帮助我们快速地绘制出二维图形,让图像更加美观,易于展示和分析。同时,在使用过程中,还需要结合实际需求,不断尝试不同的参数组合,以达到更好的绘图效果。
(2)分析特征间的关系;
在Python中,我们可以使用多种库和工具来分析特征间的关系。下面是常见的一些,
Pandas
Pandas是一个强大的数据分析库,其中包括DataFrame和Series数据结构,以便于我们处理数据和可视化数据。我们可以使用Pandas来计算两个特征之间的相关系数、通过散点图和矩阵散点图来可视化分析特征之间的关系。
例如,我们可以使用以下代码计算数据集df中两个特征Sales和Profit之间的皮尔逊相关系数,并使用散点图和矩阵散点图可视化这两个特征之间的关系:
import pandas as pd
import matplotlib.pyplot as plt
# load dataset
df = pd.read_csv('data.csv')
# calculate pearson correlation coefficient
correlation = df['Sales'].corr(df['Profit'], method='pearson')
print('Pearson correlation coefficient:', correlation)
# plot scatter plot
plt.scatter(df['Sales'], df['Profit'])
plt.xlabel('Sales')
plt.ylabel('Profit')
plt.show()
# plot matrix scatter plot
pd.plotting.scatter_matrix(df[['Sales', 'Profit']])
plt.show()
Seaborn
Seaborn是一个流行的可视化库,提供了多种高级的绘图函数和美观的图形风格。我们可以使用Seaborn绘制热力图,快速查看数据集中多个特征之间的相关性。
例如,我们可以使用以下代码绘制数据集df中多个特征之间的热力图:
import seaborn as sns
# load dataset
df = sns.load_dataset('tips')
# plot correlation heatmap
sns.heatmap(df.corr(), annot=True, cmap='YlGnBu')
plt.show()
Scikit-learn
Scikit-learn是一个广泛使用的机器学习库,提供了多种特征选择和降维方法。我们可以使用Scikit-learn来选择最相关的特征集,以提高模型的预测性能。其中,SelectKBest和PCA是常用的特征选择和降维方法。
例如,我们可以使用以下代码选择数据集X中最相关的两个特征:
from sklearn.feature_selection import SelectKBest, f_regression
# load dataset
X, y = load_dataset()
# select top two features
selector = SelectKBest(score_func=f_regression, k=2)
X_new = selector.fit_transform(X, y)
print(X_new.shape)
总之,在Python中分析特征间的关系可以使用多种工具和库,选择合适的工具组合可以帮助我们更快地理解和分析数据,以优化模型的预测性能。
(3)分析特征内部数据分布与分散状况;
(4)根据老师提供的“国民经济核算季度数据.npz”,用散点图来展示数据中的两个属性:时间(横坐标)、国内生产总值_当季值(亿元)(纵坐标)。
(5)程序代码存为“学号姓名c.py”,这两列数据结果存为“学号姓名c.xls”;
(6)每个步骤需要运行结果截图,截图中需要加上水印,水印为自己的学号姓名。
2、数据示例

图2 数据示例

图3 散点图示例
项目三知识点
这段代码利用NumPy、Matplotlib和Pandas库进行了以下操作:
1. NumPy库的使用:
使用np.load()函数读取NPZ文件,将文件中的数据加载到一个NumPy数组中。使用索引获取数组中的特定数据。
2. Matplotlib库的使用:
使用plt.rcParams['font.sans-serif']设置图表的字体为黑体。
使用plt.scatter()创建散点图,传入时间和不同产业的生产总值数据。
使用plt.xlabel()和plt.ylabel()设置坐标轴的标签。
使用plt.title()设置图表的标题。
使用plt.xticks()设置x轴刻度的旋转角度和字体大小。
使用plt.legend()添加图例。
使用plt.savefig()保存散点图为图片文件。
使用plt.show()显示散点图。
3. Pandas库的使用:
使用pd.DataFrame()创建DataFrame对象,将时间和产业生产总值数据组合为一个数据表格。
使用df.to_excel()将DataFrame保存为Excel文件。
4. 主要操作:
读取NPZ文件,获取其中的时间和产业生产总值数据。
创建散点图,以时间为x轴,不同产业的生产总值为y轴,绘制三个产业的散点图,并添加标题、坐标轴标签和图例。
保存散点图为图片文件。
创建DataFrame对象,并将时间和产业生产总值数据组合为数据表格。
将DataFrame保存为Excel文件。
这段代码涵盖了读取和处理NPZ文件、绘制散点图、保存图表和数据为文件等方面的知识点。它展示了如何使用NumPy读取和处理数据,Matplotlib绘制散点图,并使用Pandas处理和保存数据。
【项目三实现】
1、创建准备好的文件
准备好的国民经济核算季度数据.npz添加到文件里面,然后单击右键选择新建python文件2022231538陈鹏c.py。如图3.1
图3.1
2、查看文件的键
读取NPZ文件data = np.load('国民经济核算季度数据.npz', )

图3.2
3、查看详细数据
输出print(data['columns'])和print(data['values'])查看详细数据

图3.3
4、获取需要的值
获取时间和第一到第三产业生成总值当季值数据
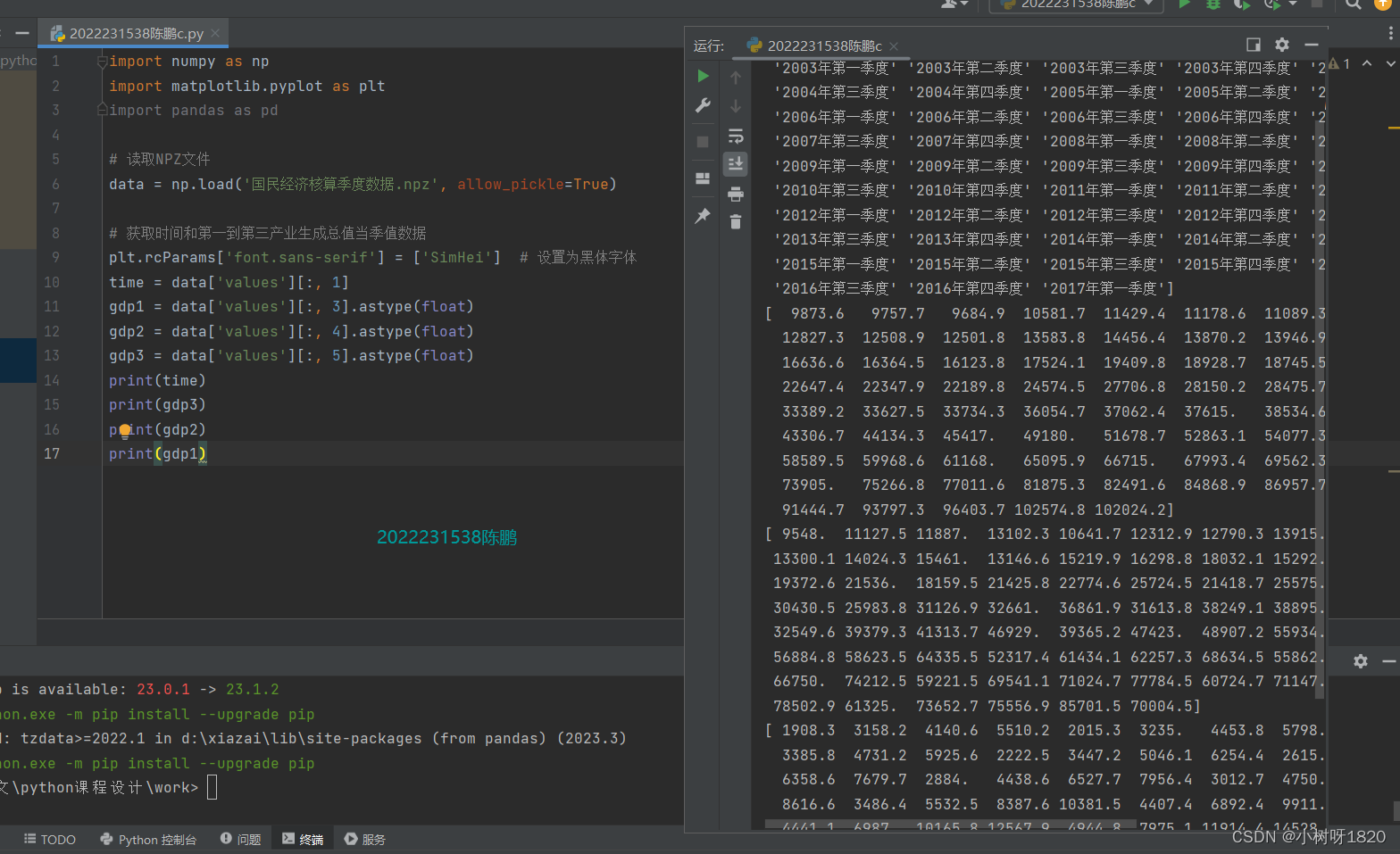
图3.4
5、绘制散点图
创建散点图,添加图例左上角小图,保存散点图,创建DataFrame并保存为Excel文件命名为2022231538陈鹏c.xlsx',显示散点图
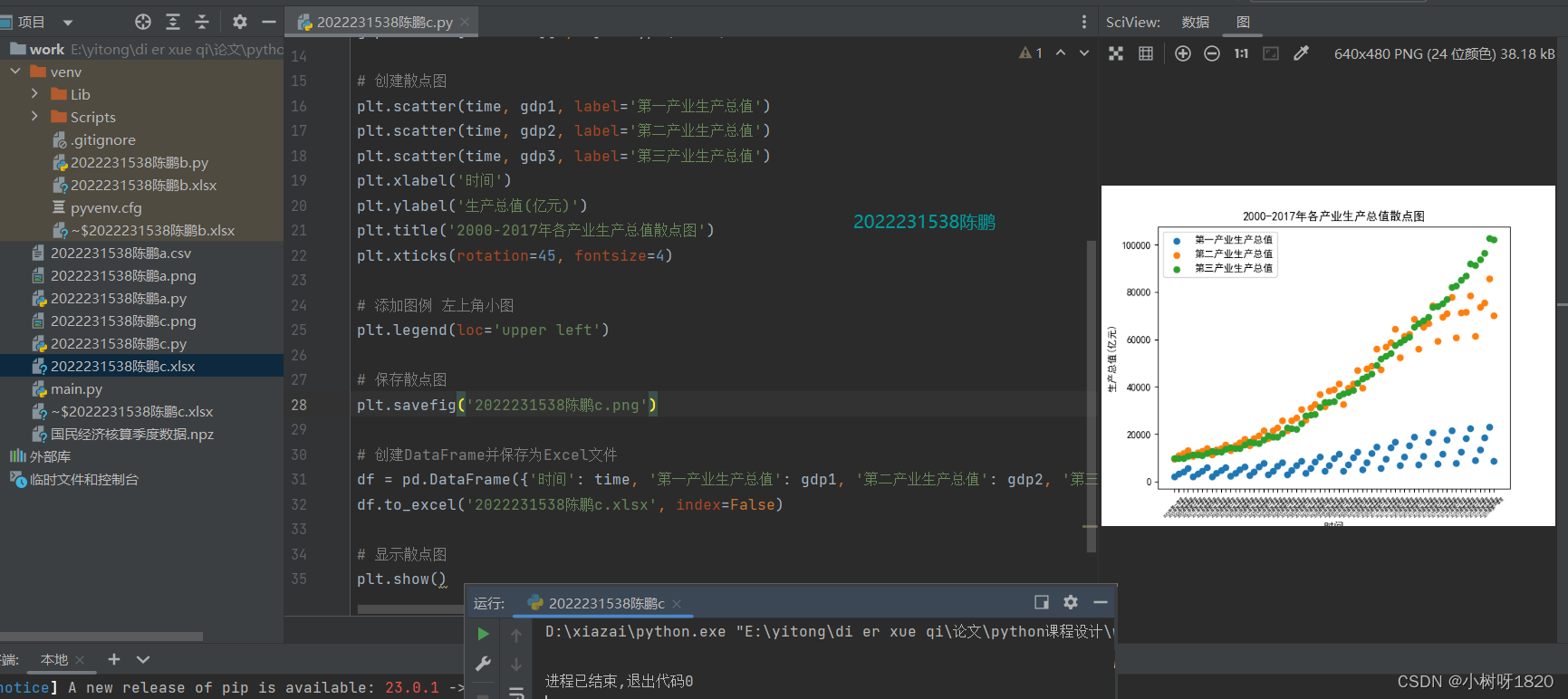
图3.5
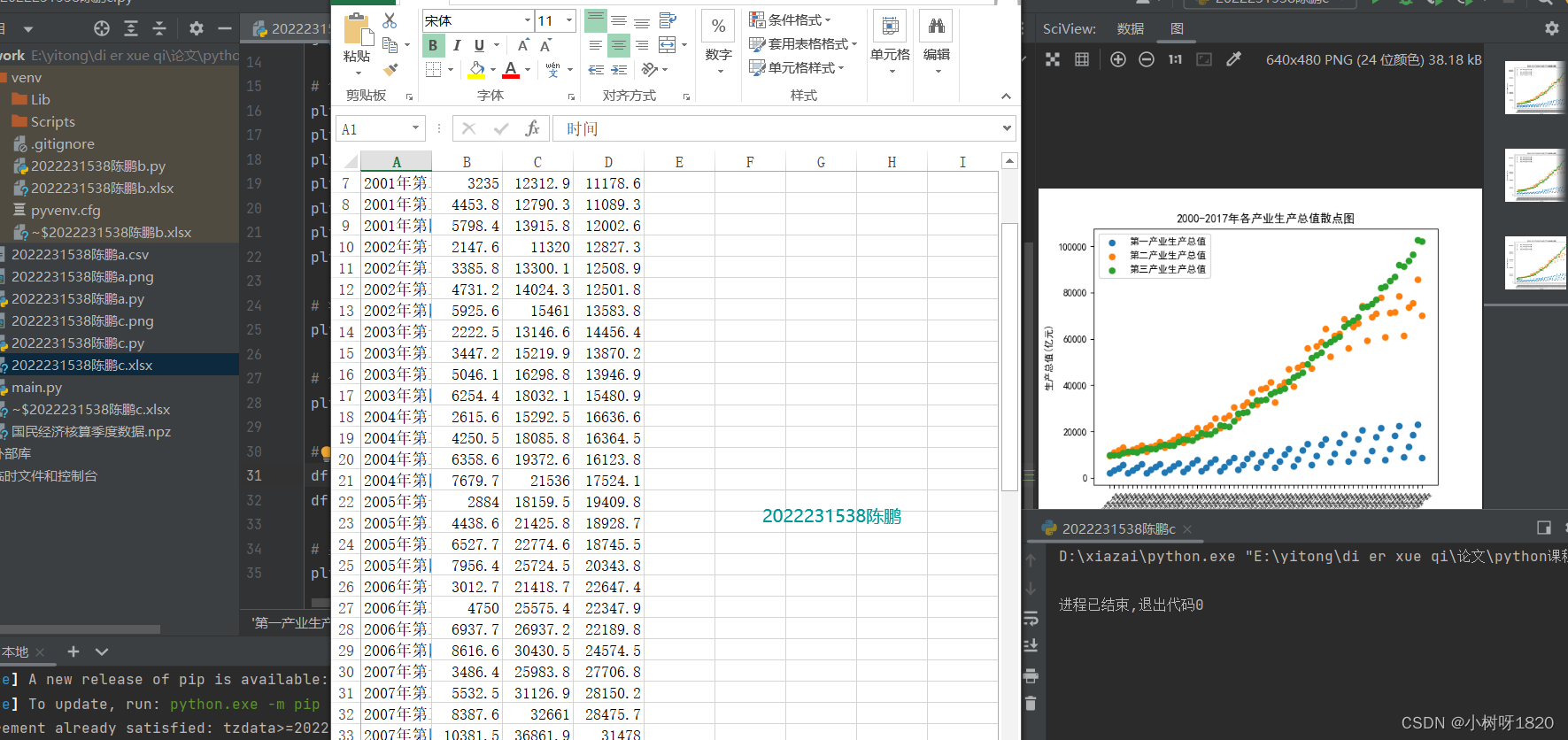
图3.6
6、代码
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# 读取NPZ文件
data = np.load('国民经济核算季度数据.npz', allow_pickle=True)
# 获取时间和第一到第三产业生成总值当季值数据
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置为黑体字体
time = data['values'][:, 1]
gdp1 = data['values'][:, 3].astype(float)
gdp2 = data['values'][:, 4].astype(float)
gdp3 = data['values'][:, 5].astype(float)
# 创建散点图
plt.scatter(time, gdp1, label='第一产业生产总值')
plt.scatter(time, gdp2, label='第二产业生产总值')
plt.scatter(time, gdp3, label='第三产业生产总值')
plt.xlabel('时间')
plt.ylabel('生产总值(亿元)')
plt.title('2000-2017年各产业生产总值散点图')
plt.xticks(rotation=45, fontsize=4)
# 添加图例 左上角小图
plt.legend(loc='upper left')
# 保存散点图
plt.savefig('2022231538陈鹏c.png')
# 创建DataFrame并保存为Excel文件
df = pd.DataFrame({'时间': time, '第一产业生产总值': gdp1, '第二产业生产总值': gdp2, '第三产业生产总值': gdp3})
df.to_excel('2022231538陈鹏c.xlsx', index=False)
# 显示散点图
plt.show()项目三总结
问题:
1.NPZ文件是什么?它包含了什么样的数据?
2.代码中的`allow_pickle=True`参数的作用是什么?
3.为什么在绘制散点图之前要设置Matplotlib的字体为黑体字体?
4.代码中使用`plt.scatter()`绘制了散点图,是否还有其他绘图函数可供选择?
5.为什么需要设置x轴刻度的旋转角度和字体大小?
6.图表中的图例是什么?为什么要添加图例?
7.DataFrame是什么?为什么要将数据保存为DataFrame对象?
8.代码中使用的`df.to_excel()`函数可以将DataFrame保存为Excel文件,是否还有其他保存数据的方式可供选择?
感受:
1.该代码使用了NumPy、Matplotlib和Pandas库进行数据处理、可视化和保存。
2.使用NumPy的`np.load()`函数读取了一个NPZ文件,并将数据加载到NumPy数组中。
3.使用Matplotlib绘制了散点图,展示了不同产业的生产总值随时间变化的趋势。
4.使用Pandas创建了一个DataFrame对象,将时间和产业生产总值数据组合成一个数据表格。
5.最后,将散点图保存为图片文件,并将DataFrame保存为Excel文件。
问题情况请看如下图片

图3.7

图3.8















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









