






 本文介绍了如何使用Python编写网络爬虫,包括使用BeautifulSoup解析HTML,以及如何通过Scrapy框架进行更高效的数据抓取,涉及了安装、环境配置和代码示例。
本文介绍了如何使用Python编写网络爬虫,包括使用BeautifulSoup解析HTML,以及如何通过Scrapy框架进行更高效的数据抓取,涉及了安装、环境配置和代码示例。
Python爬虫技术
1、目标:使用Python编写网络爬虫
2、BeautifulSoup
Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库
注意: BeautifulSoup只是一个xml和HTML的解析工具,不是网络爬虫,只是借助理解网络爬虫的原理
A、安装Node.js(当前用不到) cmd- “node -v”
B、打开PyCharm——需要破解的自行破解
C、新建Python工程 BsTest(名字自取)
D、准备一个页面(HTML),举例,jd.html(打开www.jd.com——右击——另存为——单个页
面)
E、在PyCharm安装插件 bs4和lxml
bs4的安装:file——settings——Project:BsTest——-Project Interperter——点击右侧的“+”——搜索框中输入bs4——点击左下方的InstallPackage按钮
lxml的安装:同bs4
问题 :如果安装失败,选择多安装几次
F、将jd.html放置到D盘根目录下
G、编写爬虫程序

H、程序升级
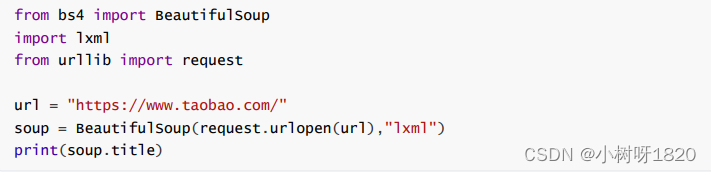
3、网络爬虫
我们使用 Scrapy 框架:
A、安装Scrapy:前提python安装完成,并且环境变量配置正确

cmd中执行如下命令#管理员身份运行cmd
B、创建Scrapy工程(PyCharmWorkSpace目录下执行如下命令)

C、使用PyCharm打开刚创建好的项目
D、在项目的spiders文件夹中新建python文件:jd.py
E、编写该程序的内容,如下:
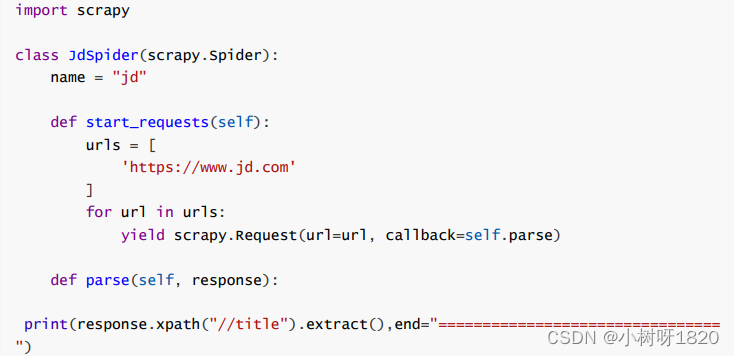
F、在项目的根目录下运行,启动爬虫
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









