







code:TPAMI 2025
Abstract
尽管文本到图像模型取得了令人印象深刻的进步,但它们往往难以有效地组合具有多个对象的复杂场景,显示各种属性和关系。为了应对这一挑战,我们提出了T2I-CompBench++,这是一个用于合成文本到图像生成的增强基准。T2I-CompBench++包含8,000个组合文本提示,分为四大类:属性绑定、对象关系、生成计算和复杂组合。这些进一步分为八个子类,包括新引入的3d空间关系和计算能力。除了基准之外,我们还提出了增强的评估指标,旨在评估这些不同的构成挑战。其中包括为评估3d空间关系和计算能力量身定制的基于检测的指标,以及利用多模态大型语言模型(MLLMs)(即GPT-4V, ShareGPT4v)作为评估指标的分析。我们的实验对11个文本到图像模型进行基准测试,包括最先进的模型,如T2I-CompBench++上的FLUX.1, SD3, DALLE-3, Pixart-α, and
SD-XL。我们还进行了全面的评估,以验证我们的指标的有效性,并探索传销的潜力和局限性。
INTRODUCTION

稳定扩散v2[1]失效案例。我们的组合文本到图像生成基准包括三类:属性绑定(包括颜色、形状和纹理)、生成计算、对象关系(包括2D/ 3d空间关系和非空间关系)和复杂组合。
多数先前的工作通过CLIPScore[11],[12]或BLIP[13],[14]通过图像-文本相似度或文本-文本相似度(从生成的图像预测的标题与原始文本提示之间)来评估模型。然而,由于组合视觉语言理解的模糊性和难度,这两种指标在组合性评估中都表现不佳。
在本文中,提出了一个增强的文本到图像合成的基准,即T2ICompBench++,这是第一个全面的基准,填补了评估文本到图像生成模型的合成能力的关键空白。T2ICompBench++不仅为评估组合性提供了一个鲁棒的评估框架,而且还推动了从复杂的组合文本描述生成复杂、高保真图像的进步。
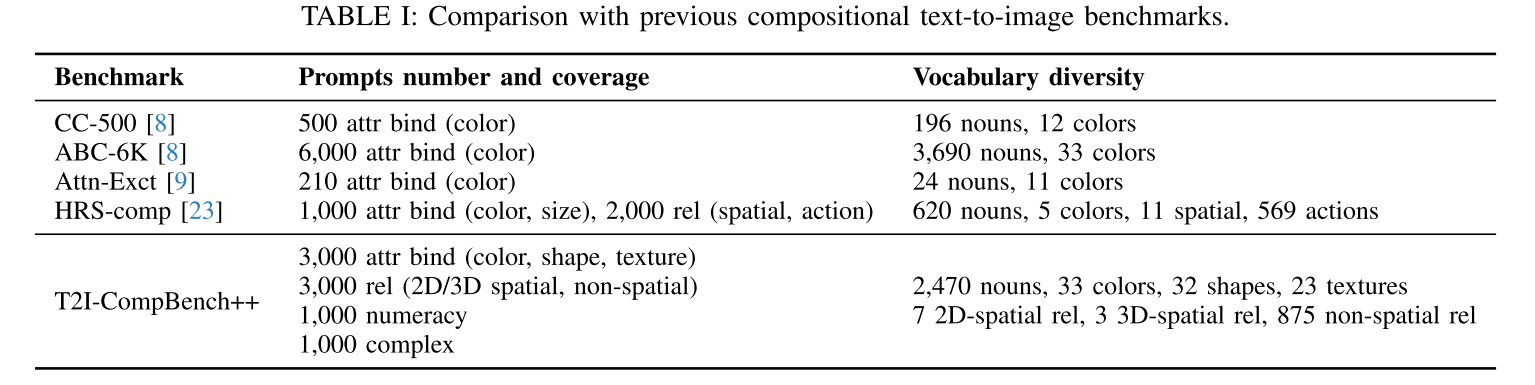
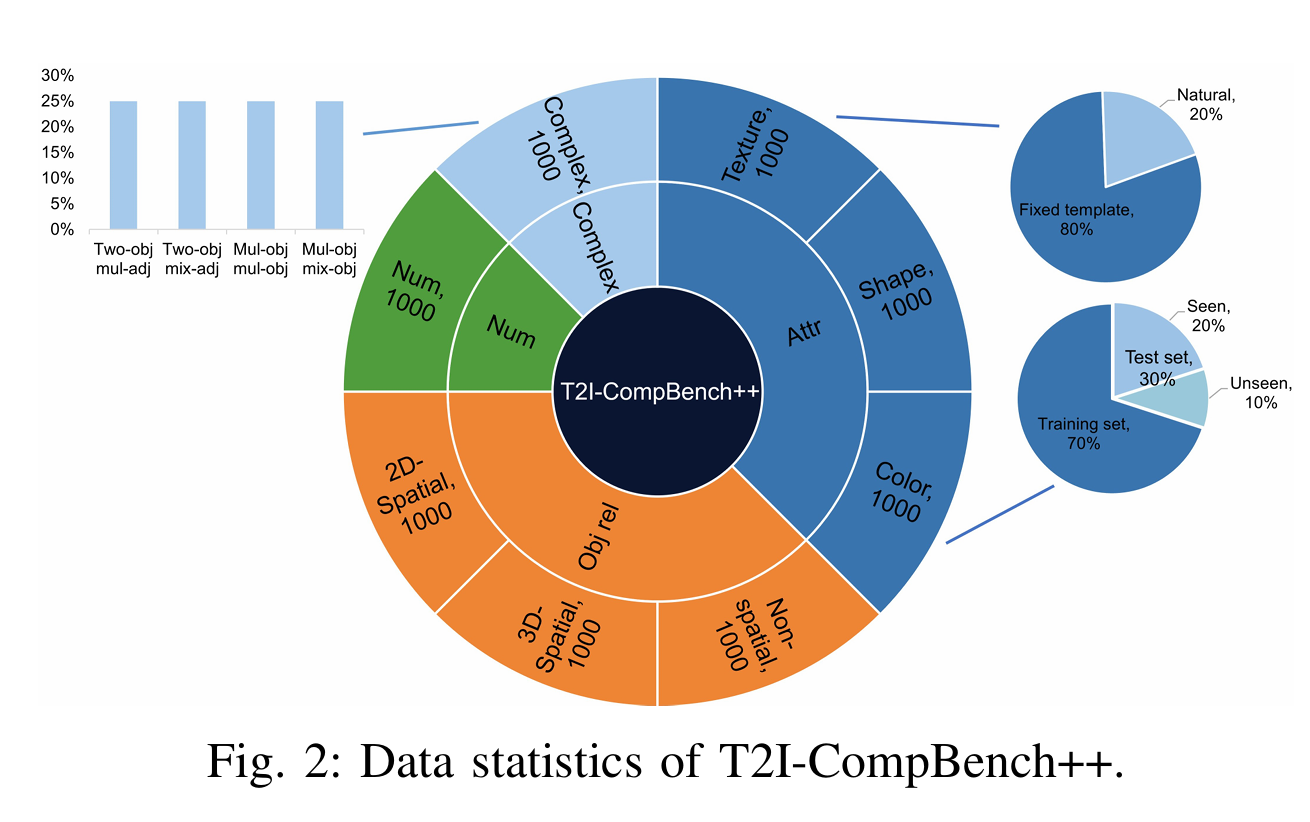
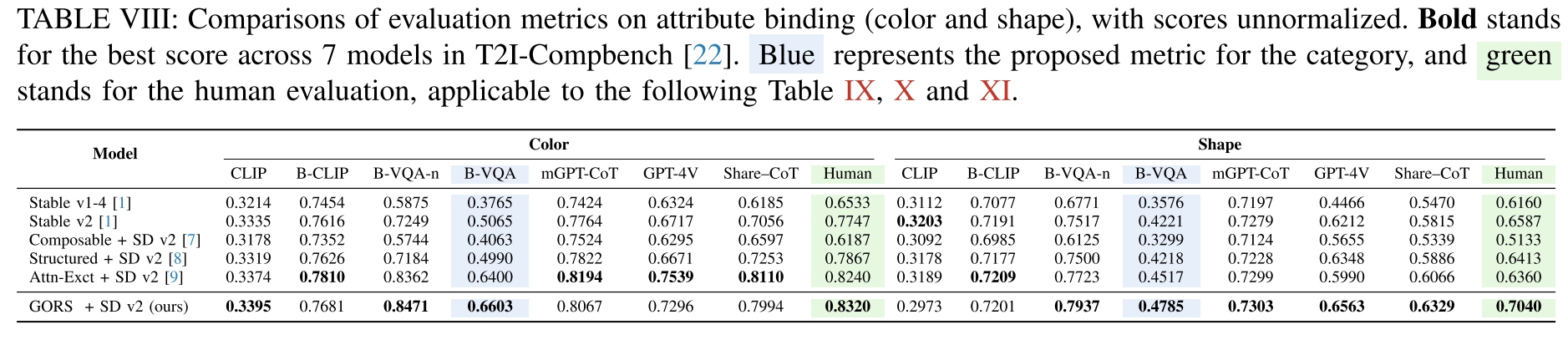
首先,提出了一个组合文本到图像生成基准T2ICompBench++,该基准包含4类和8个子类别的组合文本提示符:(1)属性绑定。该类别中的每个文本提示符至少包含两个对象和两个属性,模型需要将这些属性与正确的对象绑定以生成复杂场景。该类别根据属性类型分为三个子类别(颜色、形状和纹理)。(2)对象关系。此类别中的每个文本提示至少包含两个对象,这些对象之间具有指定的关系。根据关系的类型,该类别包括三个子类别,2D/ 3d空间关系和非空间关系。(3)生成算术。此类别中的每个提示涉及一个或多个具有数字数量的对象类别,范围从1到8。(4)复杂作文,即文本提示包含以上两个对象或两个以上子类别。例如,描述三个对象及其属性和关系的文本提示符。
其次,引入了一组针对不同类别的作文提示量身定制的评估指标。对于属性绑定评估,我们提出了Disentangled BLIP-VQA度量,旨在解决模糊属性-对象对应的挑战。为了评估空间关系和计算能力,我们引入了基于unitet的度量,该度量还结合了深度估计技术和物体检测机制来评估3D空间关系。此外,我们提出了一个基于MLLM(多模态大语言模型)的非空间关系和复杂组合度量,研究了MLLM(如ShareGPT4V[15]和GPT4V[16])用于组合性评估的性能和局限性。
最后,提出了一种新的方法,基于奖励驱动样本选择(GORS)的生成模型微调,用于合成文本到图像的生成。我们对稳定扩散v2[1]模型进行微调,生成的图像与合成提示高度一致,其中微调损失由奖励加权,奖励定义为合成提示和生成图像之间的对齐分数。这种方法简单但有效地提高了模型的合成能力,可以作为未来探索的新基线。
与初版本的拓展:
扩展了合成文本到图像生成的问题定义和类别。
介绍更多的评估指标,并对作为评估指标的传销进行深入讨论。
更全面的基准和分析。
RELATED WORK
Text-to-image generation.
Compositional text-to-image generation.
Benchmarks for text-to-image generation.
Evaluation metrics for text-to-image generation.
保真度评估(Fidelity Assessment):
-
Inception Score (IS):通过分类模型评估生成图像的多样性和类别明确性。
-
Frechet Inception Distance (FID):计算生成图像与真实图像在特征空间中的分布距离,值越小表示生成质量越高。
基于大语言模型的评估(LLM-Based Metrics):
-
LLM多模态理解:通过提示工程让LLM判断图像与文本的一致性(如GPT-4V)。
-
细粒度分析:LLM生成详细评分理由(如布局合理性、属性准确性)。
人工评估与反馈:
-
人工偏好(Human Preferences):通过用户调研或众包平台收集主观评分,直接反映人类感知。
-
动态反馈机制:结合强化学习(RLHF),利用人类反馈优化生成模型。
局限性:
-
传统指标(IS、FID)忽略语义对齐,CLIP类指标对复杂组合场景敏感度不足。
-
LLM评估依赖模型能力,存在解释性差、计算成本高的问题。
T2I-COMPBENCH++
Attribute Binding
根据属性类型引入了颜色、形状和纹理三个子类别,并为每个子类别构造了1000个文本提示。对于每个子类别,有800个固定句子模板的提示“一个{形容词}{名词}和一个{形容词}{名词}”(如“一朵红色的花和一个黄色的花瓶”)和200个没有预定义句子模板的自然提示(如“一个有蓝色窗帘和黄色椅子的房间”)。每个子类别的300个提示的测试集中,有200个提示是看到的(训练集中出现的)和100个提示是没有看到的(训练集中没有出现的)。
Color.与颜色绑定相关的1,000个文本提示由CC500[8]中的480个提示、COCO[59]中的200个提示和ChatGPT生成的320个提示组成。
Shape. 定义了一组通常用于描述图像中的物体的形状:长、高、短、大、小、立方体、圆柱形、金字塔形、圆形、圆形、椭圆形、长方形、球形、三角形、正方形、矩形、圆锥形、五边形、泪滴形、新月形和菱形。
Texture. 纹理也通常用于描述物体的外观。它们可以捕捉物体的视觉属性,如平滑度、粗糙度和粒度。经常用材料来描述质地,比如木头、塑料、橡胶。定义了几个纹理属性和每个属性可以描述的对象。通过从两个对象的可能组合中随机选择生成800个文本提示,每个对象都与一个纹理属性相关联,例如,“一个橡皮球和一个塑料瓶”。还通过ChatGPT生成了200个自然文本提示。

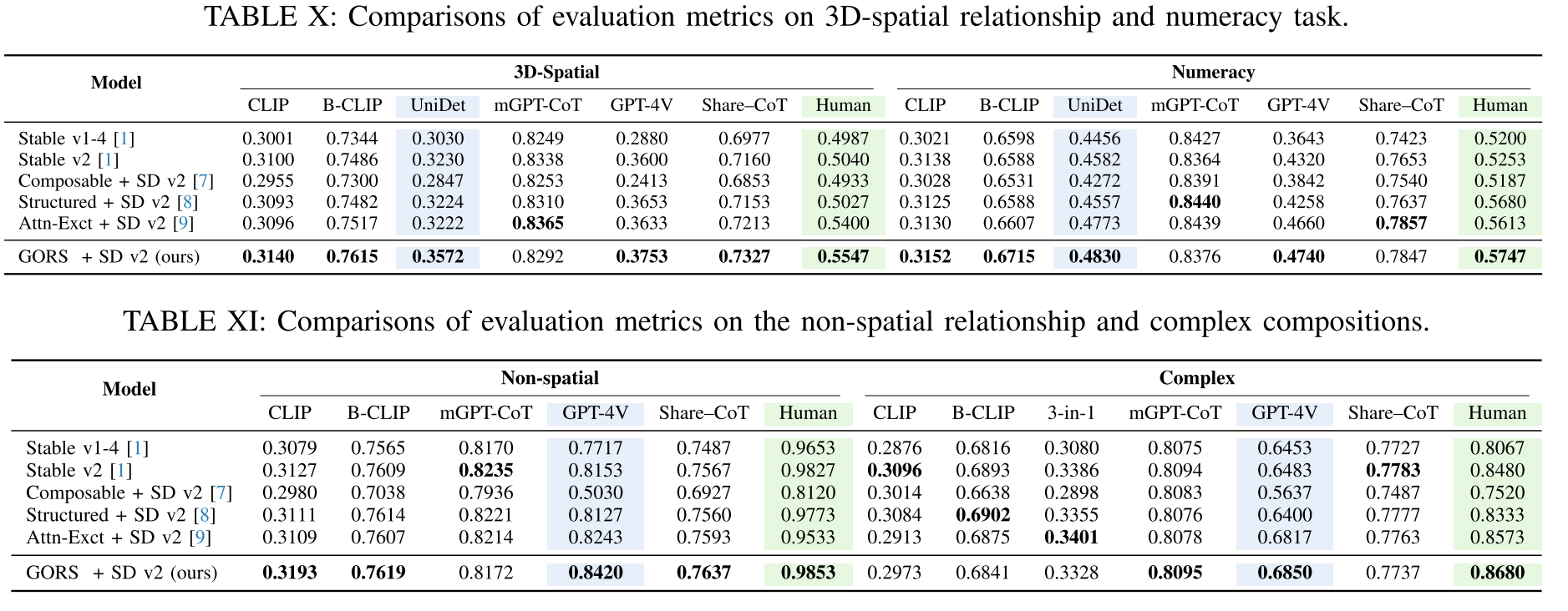
Object Relationship
在复杂场景中组合物体时,物体之间的关系是一个关键因素。分别为2D/ 3d空间关系和非空间关系引入了1000个文本提示。
2D-spatial relationships. 使用“on the side of”、“next to”、“near”、“on the left of”、“on the right of”、“on the bottom of”和“on top of”来定义2d空间关系。这两个名词是从人(例如,男人、女人、女孩、男孩、人等)、动物(例如,猫、狗、马、兔子、青蛙、乌龟、长颈鹿等)和物体(例如,桌子、椅子、汽车、碗、袋、杯、电脑等)中随机抽取的。对于包括左、右、下和上在内的空间关系,通过交换两个名词来构建对比提示,例如,“女孩在马的左边”和“马在女孩的左边”。
3D-spatial relationships. 为了说明3d空间关系,使用“前面”、“后面”和“隐藏的”来定义3d空间关系。与2d空间关系类似,使用相同的词汇在提示中构建成对,例如“一个女孩在一匹马前面”。
Non-spatial relationships 非空间关系通常描述两个对象之间的相互作用。提示ChatGPT生成具有非空间关系的文本提示(例如,“观看”、“与之交谈”、“穿着”、“保持”、“拥有”、“观看”、“与之交谈”、“与之玩耍”、“与之散步”、“站在”、“坐在”等)和任意名词。
Numeracy
在计算数据集的构建中,引入了1000个提示,并采用了基于对象数量的三方结构。计算能力的最初30%部分包含涉及单个物体的场景,随后的30%包含两个物体,剩下的40%包含多个物体,数量从1到8不等。
Complex Compositions
为了在开放世界中使用更自然和更具挑战性的组合提示来测试文本到图像的生成方法,引入了1000个文本提示,这些提示具有超出预定义模式的复杂概念组合。
使用ChatGPT为以下四种场景中的每一种生成250个文本提示:两个具有多个属性的对象、两个具有混合属性的对象、两个以上具有多个属性的对象和两个以上具有混合属性的对象。关系词可以在每个场景中用于描述两个或多个对象之间的关系。对于每个场景,将175个提示分割为训练集,75个提示分割为测试集。
(1)对于2个混合属性的对象,ChatGPT提示为:请生成自然组合短语,包含2个对象,每个对象一个形容词,来自{颜色、形状、纹理}描述和空间(左/右/上/下/旁边/附近/侧面)或非空间关系。
(2)对于2个具有多个属性的对象,ChatGPT提示为:请生成自然组合短语,包含2个对象,其中包含{颜色、形状、纹理}描述中的多个形容词,以及空间(左/右/上/下/旁边/附近/侧面)或非空间关系。
(3)对于混合属性的多个对象,ChatGPT提示为:请生成自然的组合短语,包含多个对象(编号>2),每个对象对应一个形容词,来自{颜色、形状、纹理}描述和空间(左/右/上/下/旁边/附近/侧面)非空间关系。
(4)对于具有多个属性的多个对象,ChatGPT提示为:请生成自然组合短语,包含多个对象(编号>2),其中包含{颜色、形状、纹理}描述中的几个形容词,以及空间(左/右/上/下/旁边/附近/侧面)或非空间关系。
EVALUATION METRICS
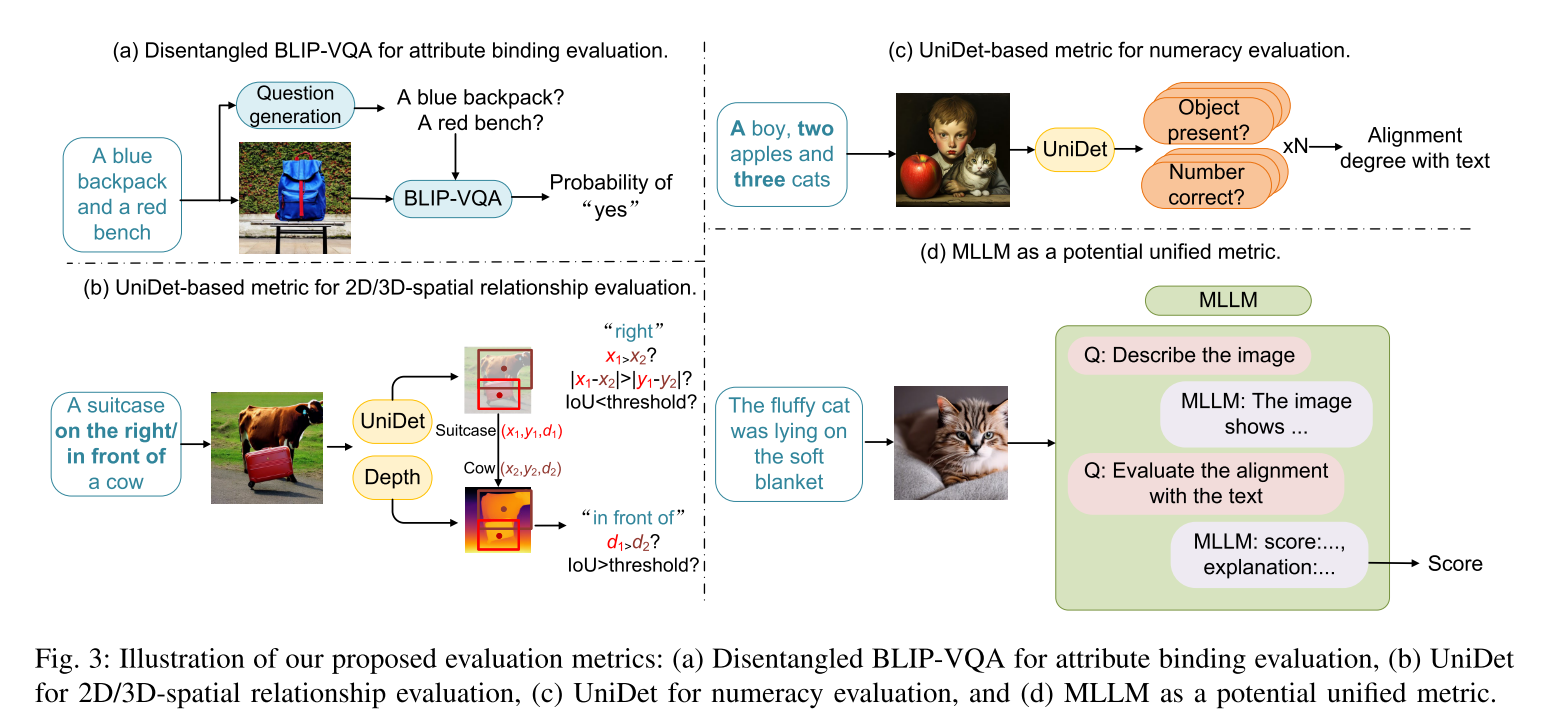
Disentangled BLIP-VQA for Attribute Binding Evaluation
BLIP- clip评估的主要限制是BLIP字幕模型并不总是描述每个对象的详细属性。例如,BLIP字幕模型可能将图像描述为“有桌子、椅子和窗帘的房间”,而生成该图像的文本提示是“有黄色窗帘和蓝色椅子的房间”。因此,明确比较文本-文本相似性可能会导致歧义和混淆。
因此,利用BLIP[13]的视觉问答(VQA)能力来评估属性绑定。例如,给定由文本提示“绿色长凳和红色汽车”生成的图像,我们分别问两个问题:“一条绿色的长凳?”和“一辆红色的车?”通过显式地将复杂的文本提示分解为两个独立的问题,每个问题只包含一个对象-属性对,避免了BLIP-VQA的混淆。BLIP-VQA模型将生成的图像和几个问题作为输入,我们将回答“是”的概率作为一个问题的得分。我们通过乘以每个问题回答“是”的概率来计算总分。将提出的解纠缠BLIP-VQA应用于评估颜色、形状和纹理的属性绑定。
UniDet-based Metric for Spatial Relationships and Numeracy Evaluation
许多视觉语言模型在推理空间关系方面表现出局限性,比如区分“左”和“右”,以及数字计数。因此,建议使用基于检测的评估指标来评估空间关系和计算能力的表现。
2D-spatial relationships. 首先使用UniDet[79]来检测生成图像中的物体。然后通过比较两个边界框中心的位置来确定两个对象之间的空间关系。将两个物体的中心分别表示为(x1, y1)和(x2, y2)。如果x1 < x2, |x1−x2| > |y1−y2|,则第一个对象位于第二个对象的左侧,且两个边界框之间的IoU小于0.1的阈值。其他空间关系“右”、“上”和“下”也进行了类似的评估。我们通过比较两个物体中心之间的距离和阈值来评估“next to”、“near”和“on the side of”。
3D-spatial relationships.对于3d空间关系,利用深度估计[80],结合基于检测的度量。设d1和d2表示两个对象对应的深度图的平均值。具体来说,如果d1 > d2和IoU指标超过预设阈值为0.5,则推断第一个物体位于第二个物体的前面。其他3d空间关系“behind”、“hidden by”也被类似地评估。
Numeracy. 为了计算,首先从提示符中提取对象的名称及其相应的数量。然后,我们利用UniDet来检测图像中的对象。这种评分机制的设计是根据提示中提到的对象类别的数量按比例考虑对象及其数值正确性。让变量n表示给定提示符中引用的不同对象类别的计数。对于图像中每一个被识别的物体,分配的分数计算为1/(2n)分。此外,如果生成的数量与指定的类别准确一致,则分配另外1/(2n)个点。
3-in-1 Metric for Complex Compositions Evaluation
由于不同的评估指标是为评估不同类型的组合性而设计的,所以没有一个单一的指标可以很好地适用于所有类别。对于非mlm度量,实证发现Disentangled BLIP-VQA最适合属性绑定评价,基于unitet的度量最适合2D/ 3d空间关系和计算性评价,CLIPScore最适合非空间关系评价。因此,设计了一个三合一的评估指标,计算CLIPScore, Disentangled BLIP-VQA和UniDet的平均分,作为复杂组合的评估指标。
MLLM-based Evaluation Metric
多模态大型语言模型使用户能够指导大型语言模型分析用户提供的图像输入。通过集成可视化模式,mllm增强了纯语言系统的能力,为它们提供了处理各种任务的新接口。然而,mllm在合成文本到图像生成方面的多模态能力仍不清楚。在此背景下,分析了三种mllm的能力,即MiniGPT-4、ShareGPT4V[15]和GPT-4V[16],重点关注它们在组合问题中的性能。
Evaluation methods of MLLMs.目前的MiniGPT-4模型显示出一些局限性,比如对图像的不准确理解和幻觉问题。ShareGPT4V[15]是一个大规模的图像-文本数据集,包含120万个详细的标题,具有丰富和多样性的特点。GPT-4V是在最先进的大型语言模型 GPT-4[81]的基础上开发的最先进的MLLM,并在包含多模态信息的大规模数据集上进行了广泛的训练[81]。使用MLLM作为评估指标,我们将生成的图像提交给模型,并评估它们与提供的文本提示符的对齐情况。这种评估包括征求对图像-文本对齐分数的预测。
Prompt template for MLLM evaluation.利用mllm作为评估指标,将生成的图像提供给模型,并使用思维链[78]提出两个问题:“描述图像”和“预测图像文本对齐分数”。详细介绍了用于MLLM评估度量的提示符。对于每个子类别,依次提出两个问题:“描述图像”和“预测图像-文本对齐得分”。具体来说,表III显示了评估属性绑定(颜色、形状、纹理)的提示符。与BLIP-VQA类似,对于提示符中的每个名词短语,请求一个与该名词短语等效的数字并执行乘法。表IV、表VI、表V和表VII分别展示了用于2D/ 3d空间关系、非空间关系、算术和复杂构图的提示模板*。由于GPT-4V的鲁棒的和有限的配额约束,我们省略了“描述图像”来提示GPT-4V。





BOOSTING COMPOSITIONAL TEXT-TO-IMAGE GENERATION WITH GORS
微调损失由奖励加权,奖励定义为合成提示和生成图像之间的对齐分数。
-
多提示生成:输入:文本提示集合 {y1,y2,⋯ ,yn} ,对每个提示 yi,生成k张图像,共得到kn张图像 {x1,x2,⋯ ,xkn}
-
对齐评分(奖励计算):使用对齐评估模型(如 CLIP、BLIP2)计算每张图像 xj与其对应文本 yi 的匹配分数 sj,作为奖励值。
-
样本筛选:设定阈值,仅保留奖励值 sj高于阈值的图像,构成筛选后的数据集 Ds。
-
加权微调:损失函数:对筛选样本的扩散损失进行奖励加权:
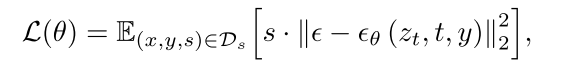
-
权重机制:奖励 s 越高,样本在训练中的贡献越大,迫使模型更关注高质量对齐样本。
-
高效训练:采用低秩适配(LoRA),仅更新模型权重中的低秩残差矩阵,减少计算开销。
EXPERIMENTS
Experimental Setup
Evaluated models.T2I-CompBench++: Stable Diffusion v1-4, Stable Diffusion v2 [1], Composable Diffusion [7], Structured Diffusion [8], Attend-and-Excite [9], and GORS.进一步评估了五个最先进的:PixArt-α [20], Stable Diffusion XL [21], DALL- E 3 [19], Stable Diffusion 3 [18] and FLUX.1 [17].GORS是本文提出的一种方法,它用选定的样本和它们的奖励来微调SDv2。
Stable Diffusion v1-4和Stable Diffusion v2[1]是基于大量图像-文本对训练的文本-图像模型。Composable Diffusion[7]是为预训练扩散模型的概念连接和否定而设计的。Structured Diffusion[8]和Attend-and-Excite[9]是为预训练扩散模型的属性绑定而设计的。在Stable Diffusion v2上重新实现了这些方法,以实现公平的比较。PixArt-α[20]是一种基于变压器的T2I扩散模型,具有竞争力的图像生成质量,可与最先进的图像生成器相媲美,训练成本低。在GORS上测试微调后的PixArt-α,记为PixArt-α-ft。Stable Diffusion XL 1.0[21]建立在以前的稳定扩散模型的迭代,代表了一个强大的文本到图像生成框架。dale -3[19]是一种新的文本到图像生成系统,增强了生成图像和提供的文本描述之间的对齐。Stable Diffusion3[18]结合了扩散变压器架构和流量匹配。FLUX.1 [schnell][17]是一种120亿参数整流变压器。
为了避免用评价指标作为奖励[43]来选择样本的偏差[83],引入了与我们提出的评价指标不同的新的奖励模型,称为GORS-unbiased。具体来说,采用GroundedSAM[84]作为属性绑定类别的奖励模型。使用ground - sam分别提取属性及其相关名词的分割掩码,并使用属性掩码与名词掩码之间的IoU和接地掩码置信度来表示属性绑定性能。将基于glip的[85]选择方法用于2D/ 3d空间关系和计算。对于非空间关系,采用BLIP[13]生成图像标题,CLIP[11],[12]来衡量生成的标题与输入文本提示之间的文本-文本相似度。对于复杂的组合,将上述3种奖励模型整合为总奖励。这些样本选择模型不同于用作评价指标的模型。
Implementation details.
对于BLIP-VQA,使用BLIP w/ ViT-B和CapFilt-L[13]对图像-文本对进行预训练,并对VQA进行微调。使用了在4个大规模检测数据集(COCO[59]、Objects365[86]、OpenImages[87]和Mapillary[88])上训练的UniDet[79]模型。对于CLIPScore,使用“viti - b /32”预训练的CLIP模型[11],[12]。对于MiniGPT4- cot,使用MiniGPT4[77]变种的Vicuna 13B,温度设置为0.7,光束尺寸为1。对于ShareGPT4V[15]和GPT-4V[16],使用默认参数,温度设置分别为0.2和1。
在扩散器的代码库上实现了我们提出的GORS [89] (Apache License),并使用LoRA对CLIP文本编码器的自注意力机制层和U-net的关注层进行了微调[82]。模型由AdamW优化器[90]训练,β1=0.9, β2=0.999, λ =1e-8,权值衰减为0.01。批量大小为5。该模型在8个32GB的NVIDIA v100 gpu上进行训练。
Evaluation Metrics
每个文本提示生成10个图像,用于自动评估。为了确保公平的比较,在所有模型†中使用固定种子生成图像。
Previous metrics.CLIPScore[11],[12](记为CLIP)计算文本特征与CLIP提取的生成图像特征之间的余弦相似度。BLIP-CLIP[9](记为B-CLIP)应用BLIP[13]为生成的图像生成字幕,然后计算生成的字幕与文本提示之间的CLIP文本余弦相似度。BLIP-VQA-naive(记为B-VQA-n)应用BLIP-VQA在整个提示中提出一个问题(例如,绿色的长凳和红色的汽车?)
Our proposed metrics. Disentangled BLIP-VQA(表示为B-VQA)是我们提出的属性绑定评价指标。UniDet是我们提出的用于2D/ 3d空间关系和计算能力评估的度量。
为了评估MLLM作为度量的作用,评估了三个模型,并提出了基于MLLM的非空间关系和复杂组合度量:MiniGPT4(表示为mGPT), ShareGPT4V(表示为Share)和GPT-4V。
Human evaluation.随机选择25个提示,每个提示生成2个图像,最终生成300个图像,每个模型总共有200个提示(25×8=200)。测试集包括每个子类别的300个提示,因此总共有2,400个提示 (8种类别验证集,300×8=2400)。人工评价的提示采样率为8.33%。使用Amazon Mechanical Turk,并要求三个工作人员基于图像-文本对齐独立地对每个生成的图像-文本对进行评分。工人可以从{1,2,3,4,5}中选择一个分数,如图4-6所示。我们将分数除以5,使其归一化。然后我们计算所有图像和所有工作人员的平均分。

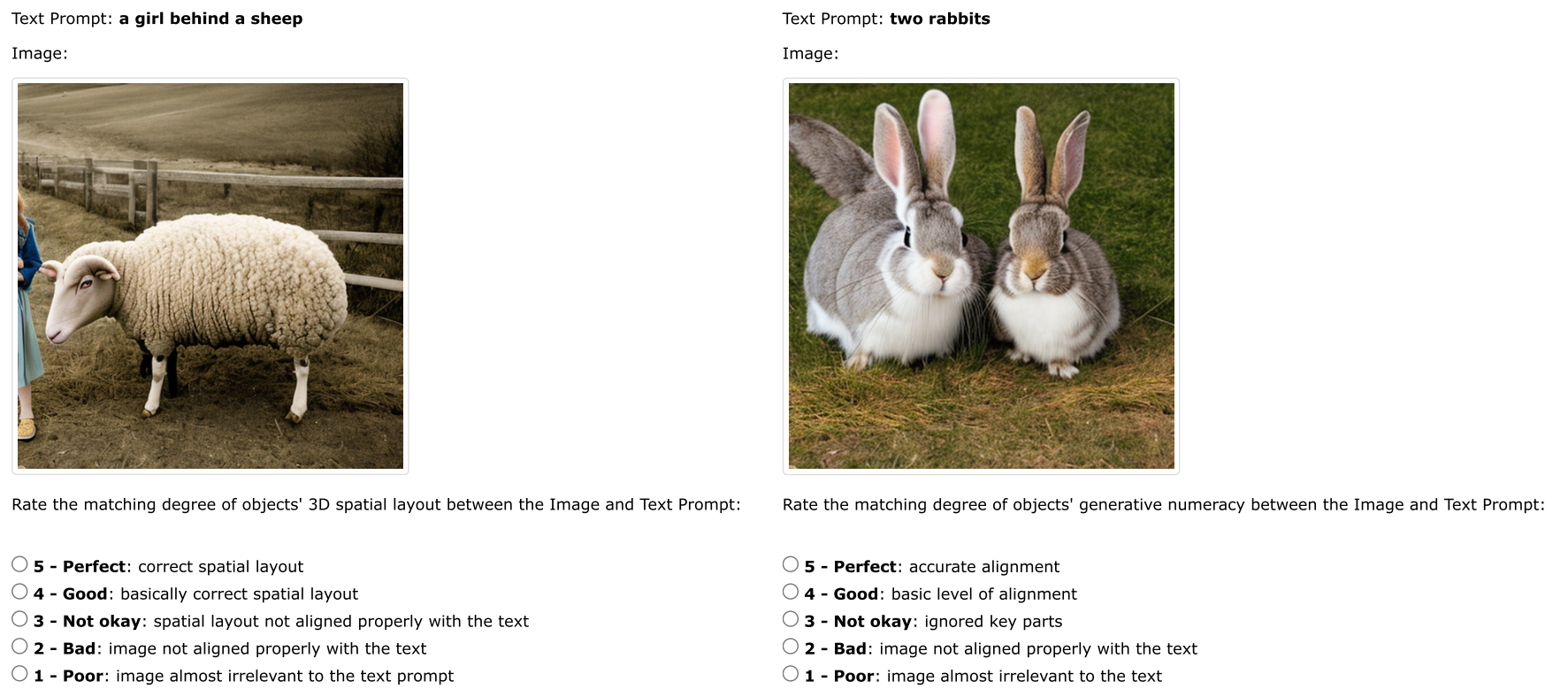
Comparison across Different Evaluation Metrics
Comparions of different evaluation metrics and human evaluation.在表8 - 11中显示了不同评价指标的结果。以前的评价指标CLIP和BCLIP预测不同模型之间的相似分数,不能反映模型之间的差异。提出的指标(蓝色列中突出显示)与人类评估(绿色列中突出显示)显示了类似的趋势。

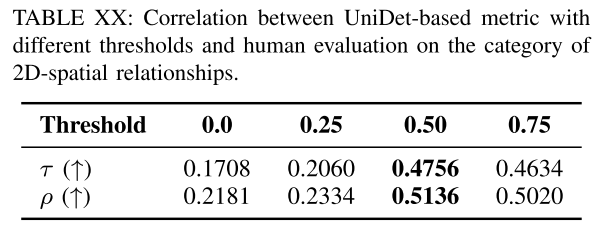
Human correlation of the evaluation metrics. 计算Kendall 's tau (τ)和Spearman 's rho (ρ)来评估自动评估与人工评估之间的排名相关性。人的相关性结果见表十二。结果验证了我们提出的评估指标的有效性,BLIP-VQA用于属性绑定,基于unit的度量用于空间关系和计算。对于MLLM评估,MiniGPT4在与人类感知的相关性方面表现不佳。Share-CoT和GPT-4V在非空间和复杂类别方面表现优异,其次是CLIPScore和三合一评估指标。在形状属性方面,它们表现出与非mlm指标相当的性能。在颜色、纹理、2D/ 3d空间和计算类别中,它们的表现略低于非mlm指标。
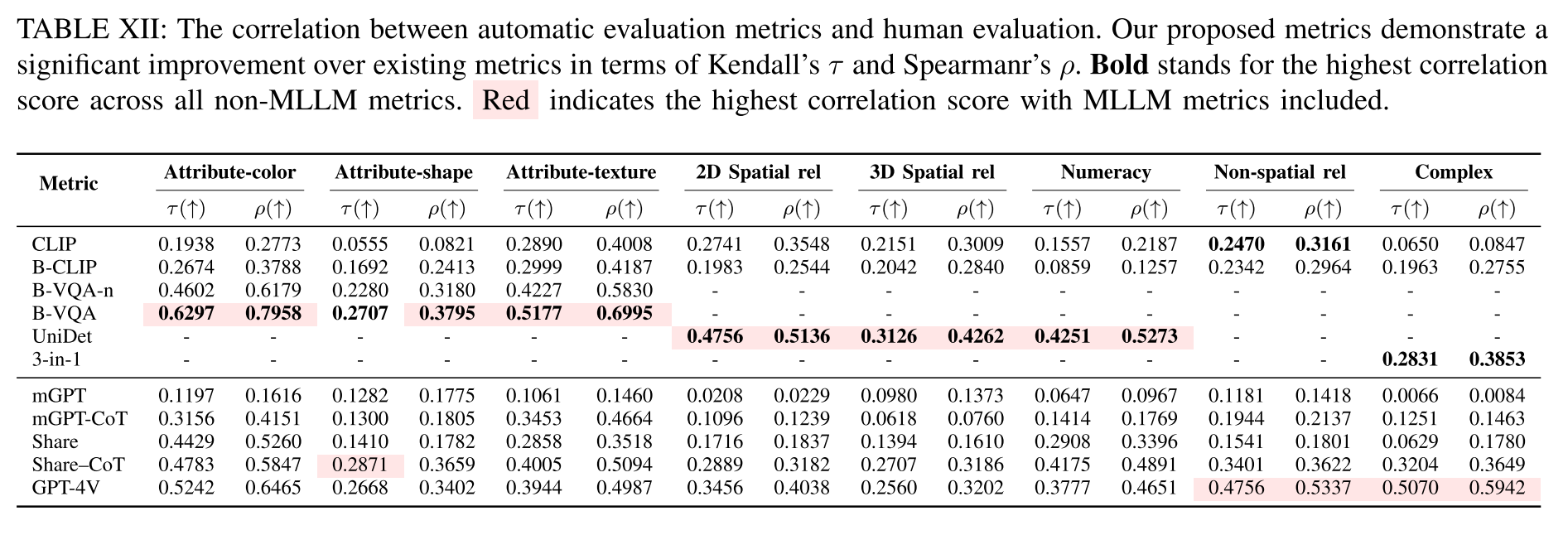
Conclusion on the evaluation metrics. 基于不同评价指标的人类相关性,得出了每个类别或子类别的最佳评价指标,并在接下来的小节中使用这些最优指标对不同的文本到图像生成方法进行基准测试。(1)对于属性绑定,最好的评价指标是BLIP-VQA。(2)对于2D空间关系、3D空间关系和计算能力,基于unitet的度量表现最好。(3)对于非空间关系,最佳度量是GPT-4V,次优度量是Share-CoT (ShareGPT4V with Chain-of-Thought),非mlm最佳度量是CLIP。(4)对于复杂组合,最佳度量是GPT4V,次佳度量是Share-CoT (ShareGPT4V with Chain-of-Thought),最佳非mlm度量是三合一。
Discussion about MLLMs as a unified metric
Comparisons among different MLLMs.我们比较了MiniGPT4、ShareGPT4V和GPT-4V在人类中的相关性。MiniGPT4与人类感知的相关性不足。ShareGPT4V和GPT-4V在非空间和复杂类别方面表现出色。在颜色、纹理、2D/ 3d空间和计算类别中,它们的表现略低于非mlm指标。ShareGPT4V在非空间关系和复杂性方面排名第二,在属性类别方面排名第一到第三,在2d空间方面排名第三,在3d空间方面排名第三(在τ方面)和第二(在ρ方面),在计算能力方面排名第二。GPT-4V在非空间关系和复杂性方面排名第一,在颜色属性方面排名第二,在形状和纹理属性方面排名第三,在2d空间方面排名第二,在3d空间方面排名第二(按τ计算)和第三(按ρ计算),在计算能力方面排名第三。
Comparisons of the effectiveness of Chain-of-Thought for MLLMs.利用Chain-of-thought[78]激发MLLM的评估能力,对MiniGPT4和ShareGPT4V进行了比较。对于CoT, MiniGPT4和ShareGPT4V在大多数类别中都显示了人类相关性方面的改进,突出了有效提示的重要性。在表XIV中对没有思维链的mGPT进行了基准测试,表XIV显示了6个型号使用没有思维链的MiniGPT-4在tti - compbench ++上进行基准测试的额外结果。结果表明,没有思维链的MiniGPT-4评价与人类评价结果并不严格一致。
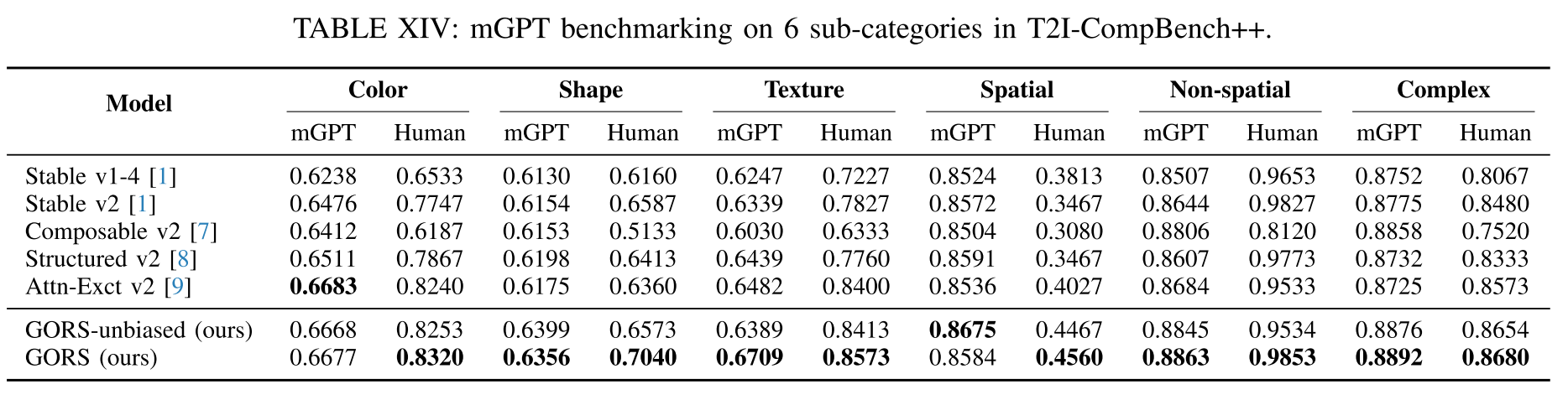
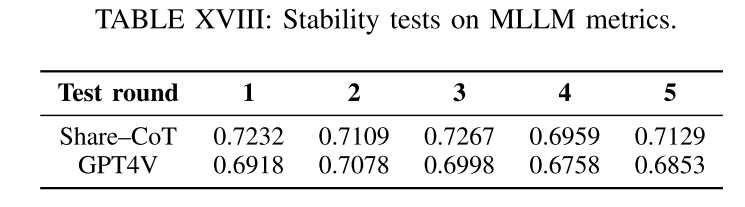
Discussion about the stability of MLLMs’ results. 通过在一组一致的图像上执行多次执行来测试MLLM指标的稳定性。具体来说,使用ShareGPT4V和GPT-4V来分析来自Stable v2颜色类别的50张图像,重复该过程5次。使用默认参数,GPT-4V的温度为1.0,ShareGPT4V的温度为0.2。如表XVIII所示,我们的分析得出的结果一致,GPT-4V的五次执行的变化保持在0.032以内,ShareGPT4V的变化保持在0.0273以内。GPT-4V的平均标准差为7.3235,ShareGPT4V的平均标准差为6.8741。
Limitations of MLLMs as a metric.Share-CoT和GPT4V虽然作为评估指标表现很好,但它们也有局限性。他们没有很好地遵守评分指南的提示。实证观察表明,无论提供什么提示,ShareCoT倾向于给出较少的多样化评级。GPT-4V可以理解评估提示,但转换成准确分数的能力较差。
Benchmarking on Different Methods
Qualitative results
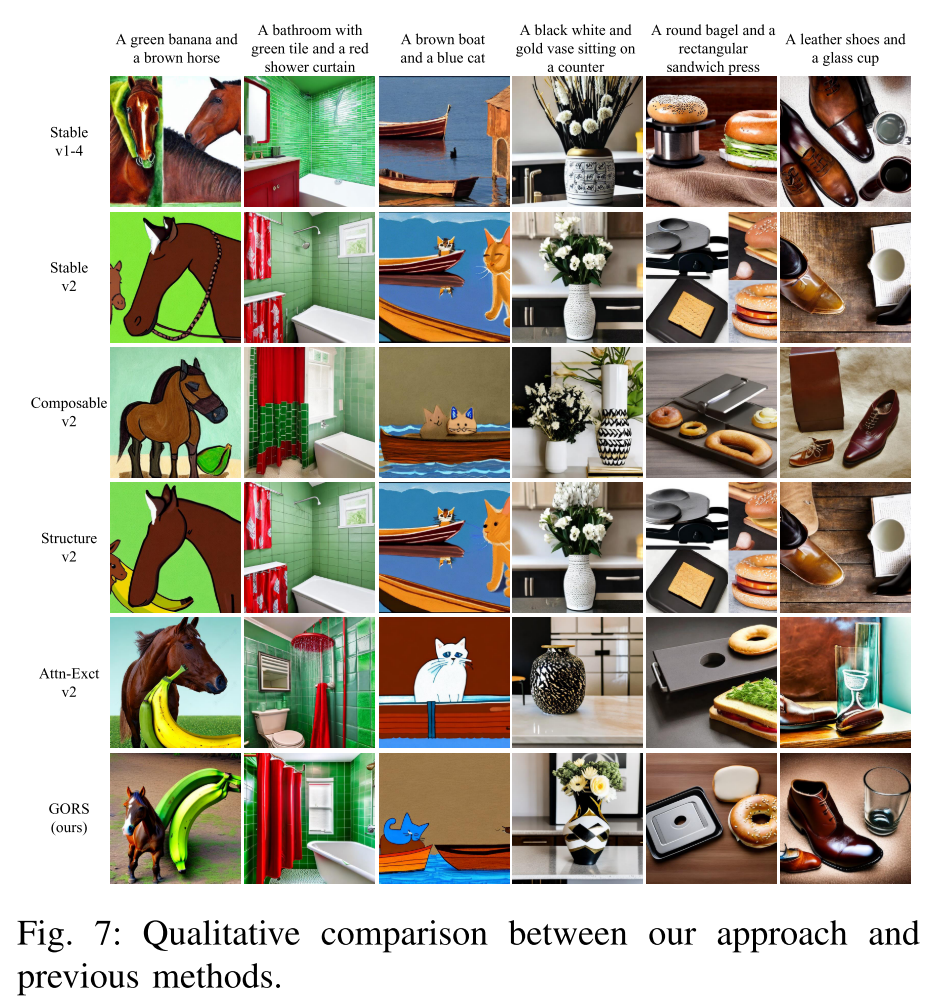


Comparisons across text-to-image models.
(1)在所有类型的作文提示和评估指标中,稳定扩散v2始终优于稳定扩散v1-4。
(2)尽管Feng et al.[8]报道的基于稳定扩散v14构建的结构化扩散在属性绑定方面有很大的性能提升,但基于稳定扩散v2构建的结构化扩散在稳定扩散v2上的性能提升很小。这表明在Stable Diffusion v2更好的基线上提高性能更具挑战性。
(3)基于Stable Diffusion v2的Composable Diffusion不能很好地工作。在之前的工作中也观察到类似的现象,即可合成扩散通常生成包含混合主题的图像。此外,Composable Diffusion是为概念连词和否定而设计的,因此在其他组合场景中表现不佳是合理的。
(4)基于Stable Diffusion v2的Attend-and-Excite改进了属性绑定的性能。
(5)以往的方法Composable Diffusion[7]、Structure Diffusion[8]和Attend-and-Excite[9]都是针对概念连接或属性绑定而设计的,因此它们对对象关系的改善并不显著。
(6)我们提出的方法GORS在所有类型的作文提示中都优于以前的方法,如自动评估、人工评估和定性结果所证明的那样。GORSunbiased和GORS的评价结果显著超过基线Stable v2。此外,gors无偏的性能表明我们提出的方法对用于选择样本的奖励模型不敏感,并且只要选择高质量的样本,所提出的方法就可以很好地工作。
(7)最近的文本到图像模型,Stable Diffusion XL [21], Pixartα-ft [20], DALLE 3 [19], Stable Diffusion 3[18]和FLUX.1 [schnell][17]与之前的方法相比,在所有类别上都有所提高。值得注意的是,DALLE 3和SD3在几乎所有类别中都实现了最先进(SOTA)的性能。
Comparisons across compositionality categories.
从人的评价结果来看,空间关系是文本到图像模型最具挑战性的子类别,属性绑定(形状)也具有挑战性。非空间关系是最简单的子类别。
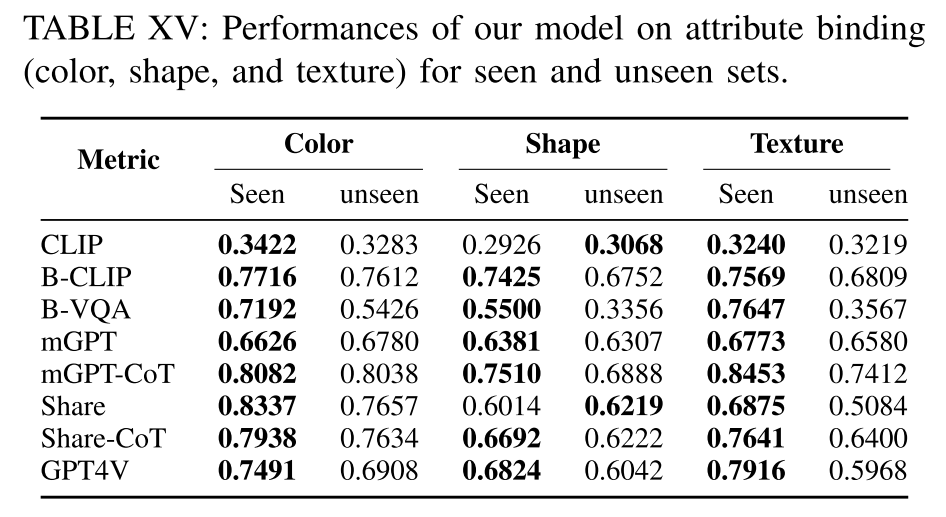
Comparisons between seen and unseen splits.
在属性绑定中为测试集提供了可见和不可见的分割,其中不可见的集由不出现在训练集中的属性-对象对组成。看不见的拆分往往比看到的拆分包含更多不常见的属性-对象组合。表15显示了属性绑定的可见分割和不可见分割的性能比较。我们的观察表明,我们的模型在看不见的集合上的表现略低于看到的集合。
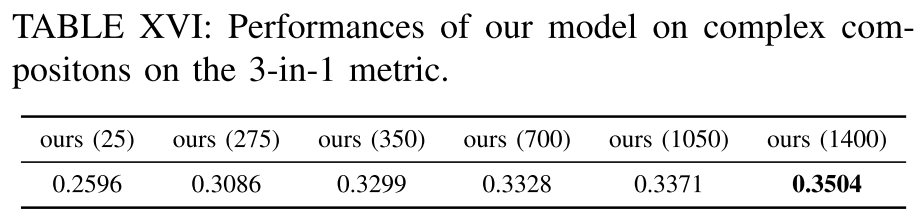
Comparisons of the scalability of our proposed approach.
为了演示提出的方法的可扩展性,引入了额外的700个复杂组合提示,以形成一个包含1,400个复杂提示的扩展训练集。使用相同的方法生成新的提示。进行了6个实验来训练不同训练集大小的模型,即25条提示、275条提示、350条提示、700条提示、1050条提示和1400条提示。表XVI的结果显示,模型的性能随着训练集大小的增加而增长。结果表明,通过扩大训练集可以获得更好的性能。
Comparisons between original prompts and rephrased detailed prompts.增强提示细节并不能显著改善生成结果,因为挑战主要在于视觉内容组成,而不是提示的粒度。虽然更详细的提示可以通过提供额外的描述来提高图像质量,但它们并不一定会增强生成的图像和提示之间的一致性。为了说明这一点,我们使用GPT-4将提示改为更详细的版本,并比较评估结果。具体来说,我们以属性绑定类别(例如,颜色)为例来检查SDXL。结果如表XVII所示,表明T2I模型在原始提示和详细提示方面都面临类似的构成挑战。

Ablation Study
Finetuning strategy. 方法使用LoRA对CLIP文本编码器和稳定扩散U-Net进行微调[82]。使用属性绑定(颜色)子类别进行操作。研究了仅使用LoRA微调CLIP和仅使用U-Net的效果。如表19所示,我们对CLIP和U-Net进行微调的模型性能更好。

Threshold of selecting samples for finetuning.我们的方法微调稳定扩散v2与选定的样本,很好地对准组成提示。我们手动设置对齐分数的阈值,以选择具有比微调阈值更高的对齐分数的样本。我们尝试将阈值设置为原始值的一半,并将阈值设置为0(即,使用所有生成的图像进行带有奖励的微调,而不进行选择)。表XIX的结果表明,半阈值和零阈值会导致性能变差。
Threshold of UniDet-based metrics
Qualitative results.

Limitation and Potential Negative Social Impacts




















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











