






12.1 关键字的特点
常见关键字是什么?我们仔细一点都会发现,我们在写代码的时候,是不是里边有很多这种 int,return 等就直接用,这叫常见关键字,这是 C 语言提供的关键字
这些关键字有这么一些特点:
1. 是 C 语言提供的,不能自己创建关键字
2. 关键字不能做变量名
起个变量名字叫 int ,或者说有个变量名叫 char 肯定不行,举个例子,比如说这个地方写上个 int char,什么意思呢?就是说我们创建一个变量名叫 char,这样不行,如图所示:

因此我们可以得出:变量名和关键字不能冲突,关键字不能做变量名,或者变量名不能是关键字
12.2 关键字有哪些
关键字到底有哪些呢?肯定很多,因为定义变量名的时候,不能是关键字,所以在 C 语言中一共有32个关键字,接下来我们就来了解一下哪些是关键字:

在这里我们一口气全部干完(一个不剩、奥里给):
1. auto:自动的,它用于什么场景呢?每个局部变量都是 auto 修饰的
举例如下:创建了一个 a = 10,这个地方的 a 128行进这个大括号它创建,130行出这个大括号它销毁,所以对于这个 a 来说它是自动创建,自动销毁的,所以它是自动变量,其实对于局部变量,它本身前面都应该有个 auto,既然局部变量都是 auto 的,所以基本上都是省略掉了,如图所示:
当然 auto 在新的 C 语言语法中也有其他语法,暂时不考虑,因此,auto 是修饰局部变量的,而局部变量基本上都是自动创建,自动销毁。所以它叫自动变量,而这个 auto 基本上都省略掉了
2. break:在循环里边,switch 里边都会有
3. case:switch/case 语句里边会用
4. char:字符类型
5. const:常变量,修饰变量,它是不能改的
6. continue:继续
7. default:默认,在后边分支和循环语句的时候,我们会把 break,default,continue 这样的关键字会再来讲解,也在 C 语言里边用到 switch/case 语句里边去
8. do:适用于 do...while 循环
9. double:双精度
10. else:if...else 语句
11. enum:枚举
12. extern:是用来声明外部符号的
13. float:单精度浮点型
14. for:for 循环
15. goto:goto语句
16. if:if 语句
17. int:整型
18. long:长整型
19. register:寄存器
20. return:返回,main 函数最后 return 0,返回的0要和 int 呼应起来
21. short:短整型
22. signed:有符号的(数字有正有负,如10,-20 有正有负就有符号位,描述的数字是有符号的,就是有正负的)
23. sizeof:求字节大小
24. static:静态的
25. struct:结构体
26. switch:switch 语句
27. typedef:类型定义
28. union:联合体(公用体)
29. unsigned:无符号的(在它看来,定义的某些变量是没有符号位概念的)
30. void:无的,空的
31. volatile:这是体现 C 语言段位的一个关键字(这个关键字是体现你 C 语言段位的关键字,如果你懂这个关键字,说明你的 C 语言理解的还不错;如果你不懂,那说明你的 C 语言还有待提高,上升空间很大)
32. while:while 循环
看到这里,我想我们已经明白哪些是关键字,哪些不是关键字了,那我们就出一个很常见的题:
define 是不是关键字?不是
include 是不是关键字?不是
define 和 include 都是预处理,不是关键字,预处理不是等待处理,而是在预编译期间处理的指令所以叫预处理指令
补充一下 signed 和 unsigned:整型家族里边都可以用 signed,unsigned 进行修饰,char 类型在存储变量的时候,其实存储的是字符ASCII码值,所以 char 也属于整型家族里边
signed(有符号的):有符号的关键字,用它修饰的类型所创造的变量可以带有正负号,包括负值(signed 有符号的,都可以省略)
unsigned(无符号的):无符号的关键字,用它修饰的类型所创造的变量不带正负号,只表示0和正整数(unsigned 无符号的不能省略,它们都是用来修饰类型的)
12.3 auto关键字
在前面已经讲解了auto,于是在这里直接拷过来,这样看更方便
auto:自动的,它用于什么场景呢?每个局部变量都是 auto 修饰的
举例如下:创建了一个 a = 10,这个地方的 a 128行进这个大括号它创建,130行出这个大括号它销毁,所以对于这个 a 来说它是自动创建,自动销毁的,所以它是自动变量,其实对于局部变量,它本身前面都应该有个 auto,既然局部变量都是 auto 的,所以基本上都是省略掉了,如图所示:

当然 auto 在新的 C 语言语法中也有其他语法,暂时不考虑,因此,auto 是修饰局部变量的,而局部变量基本上都是自动创建,自动销毁。所以它叫自动变量,而这个 auto 基本上都省略掉了
12.4 register关键字
register 是寄存器的意思,由这个关键字创建的变量,我们建议把它放到寄存器里边去。
举个例子,写个在第141行代码 register num = 100中,这样写的意思就是 num 被 register 修饰了,建议 num 的值存放在寄存器中(仅仅是建议的作用,是不是就存放到寄存器里边去呢,register 说了不算,是编译器说了算,编译器自己会做决定的,我们只是建议说,能不能把这个 num 放到寄存器里边去),如图所示:
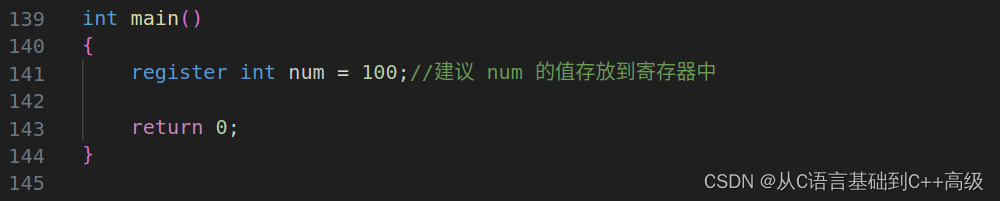
问题:请问为什么要放到寄存器里边去?
在计算机里边,数据可以存储到哪里呢?第一可以存放到内存中去,然后还可以存到硬盘上,还可以存到网盘上,其实在内存之上还有一个东西叫高速缓冲存储器 cache,还有一个叫寄存器,因此,在计算机里边,数据可以存到大概这么几个地方,如图所示:

值得注意的但是:网盘其实严格意义上来说不属于本机了,是连网之后我们才能存放,例如:注册了百度网盘,这个时候把数据放上去,这个时候是依赖于网络存的百度的服务器上去了,但是它也可以存,动不动就送2个 T,领回来之后还是免费的。网盘呢因为它依赖于网络,所以它的传输速度要慢一些
再说硬盘,例如500个 G 硬盘,这都是买的。硬盘的速度比网盘当然要快(我们在硬盘上传输数据的时候拷贝起来几十个 MB/s)
再往上走就到了内存,内存一般只有8/16 G 的内存。内存的读写速度比硬盘更快,所以它的造价也更高,技术含量也更高
再往上的话高速缓存,可能就只有几百个 MB,或者几十个 MB。它的速度比内存又要快
再往上寄存器的话就更小了。寄存器的速度又要比高速缓存块
因此,这个时候就形成了一种金字塔的结构,在计算机里边就形成了这样一种存储的金字塔的结构吗,如图所示:
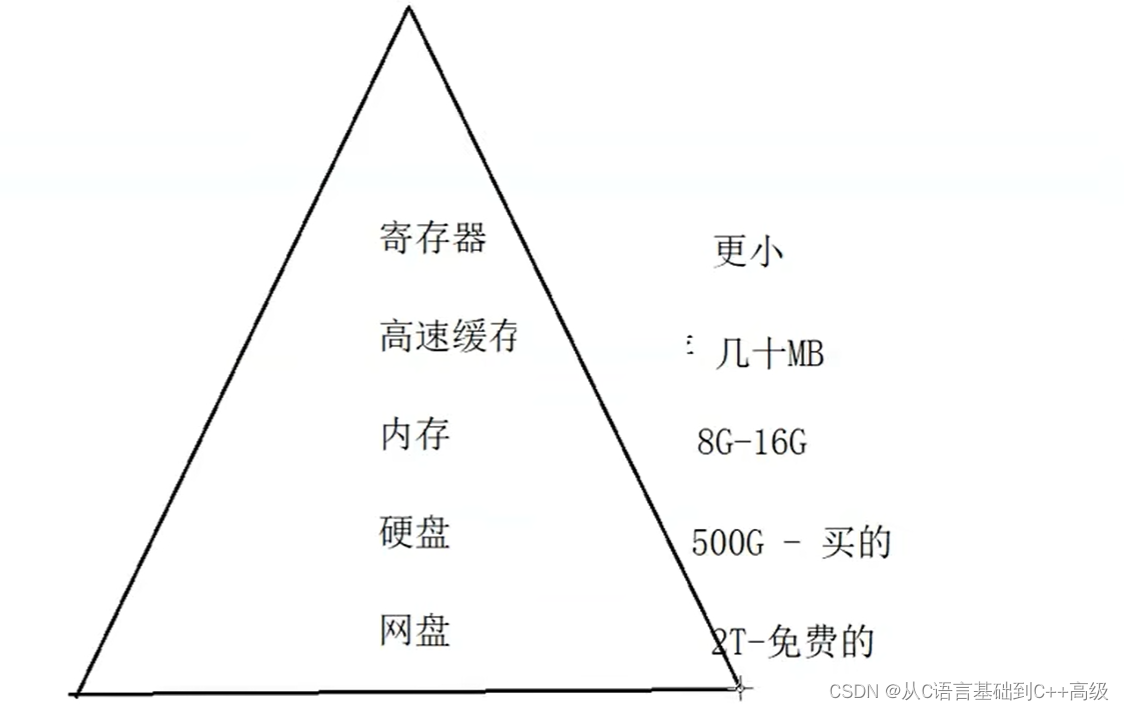
这个时候我们会发现:越往上,造价越高,速度越快,但是空间越小
那问题又来了,为什么会有这样金字塔的结构?
其实在早期,计算机里边处理数据是 CPU 处理的(CPU 叫中央处理器),它是进行相关的计算工作的,那计算的时候数据来自于哪里呢?计算的数据是从内存里边去读取(需要数据了,去内存里边去拿),早期的电脑都是这样的
但是,随着技术的发展,CPU 的处理速度越来越快,而内存的读写速度其实并没有跟上 CPU 的处理速度,因此,只会形成一种结果:CPU 的处理速度越来越快,但是内存的处理速度可能读写速度跟不上,它也涨,但是跟不上。这个时候我们也可以推断出:CPU 的速度再快,内存的读写速度如果过不了的话,这就会导致 CPU 很多情况可能在闲置,也就是没事干。(举一个生动有趣的例子:盖房子,我是一个盖房子的人,旁边有个人是搬砖的,我盖的特别快,但是那个搬砖的速度跟不上,那我这个房子也盖不快)
因此,CPU 再快也不行,后来内存的速度跟不上的话咋弄?后来有人就想说,那 CPU 去处理数据的时候,原来是去内存里边去拿,现在不去了,而是在内存之上提供一个高速缓存,在高速缓存之上再提供一个寄存器。这样 CPU 拿数据的时候都去寄存器里边去拿,寄存器的读写速度更快,所以 CPU 拿到的数据也就更快,处理起来就更快一些。
当我们在处理寄存器里边数据的时候,就把高速缓存里的数据放到寄存器里边去,把内存里的数据放在高速缓存里边去,所以大部分情况下,我们想要的数据都在寄存器里边都能找到,如果寄存器找不到,再往下高速缓存找,高速缓存又没找到,再去内存去拿。这样我们在万不得已的情况下才从内存里边去拿,整体我们的效率就提升了
所以在我们买电脑的时候,我们可以看到内存有多大,硬盘有多大,高速缓存有多大,经常会有这样一个存储结构所以这个地方给大家一说,其实主要强调的一个点就是寄存器的速度非常快,既然寄存器的速度非常快的话,那我们一般像那些大量频繁被使用的数据,想放在寄存器中,提升效率,这个时候我们就可以建议放到寄存器里边去,当然现在编译器已经非常聪明了,即使不写 register,它认为寄存器该放到寄存器里边去了,它也会把某些变量直接放到寄存器里边去
讲到了这里,终于明白了吧~
12.5 typedef关键字
typedef 是什么呢?类型定义,其实这种描述方式是不准确的,我们再全面一点的话叫类型重定义,tupedef 这个关键字可以让类型变得更加简单,这样才能更加准确一些,什么意思呢,举个例子:
如果你打字不好,你觉得慢,尤其是这么长的关键字,我们写起来不方便,这个时候有同学在想:能不能把这个类型简化一下?这个时候我们就可以 typedef unsigned int u_int 我们把这个 unsigned int 类型能不能写成名字叫 u_int 类型,就这样缩写一下
这个时候 typedef 是把 unsigned int 类型重新起了个新的名字叫 u_int,未来有人写 u_int2 = 100的时候,那么 unsigned int num = 100和 u_int num2 = 100这两个代码是一摸一样的,也就是说,第153行代码和第154行代码是一摸一样的,u_int num2中的 u_int 其实就是 unsigned_int 的一个别名,类型是一摸一样的,如图所示:
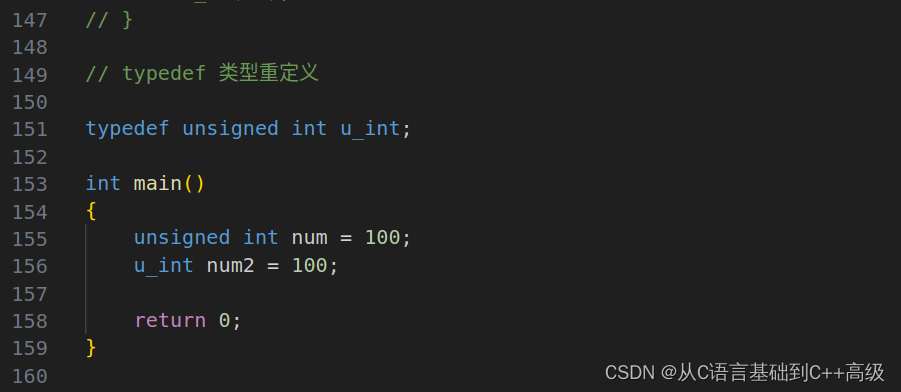
补充:别名是什么意思?假设你叫蔡徐坤,这是你的大名,但是你的家里人呢,喜欢叫你坤坤,所以坤坤其实就是蔡徐坤的一个别名,叫坤坤其实叫的就是蔡徐坤,所以 u_int 其实就是 unsigned int 的别名
12.6 static 关键字
static 英文是静态的,我们肯定学过这个单词,接下来我们看看 static 可以做什么:
static 有什么用呢?这个地方我们要讲3个,static 有3个用法:
1. static 修饰局部变量,改变了局部变量的生命周期,本质上是改变了变量的存储类型
2. static 修饰全局变量,使这个全局变量只能在自己所在的源文件(.c 文件)内部可以使用,其他源文件不能使用
3. static 修饰函数,使这个函数只能在自己所在的源文件(.c 文件)内部使用,不能在其他源文件内部使用
大概就是这3个点,接下来我们分别来学一下:
12.6.1. static修饰局部变量
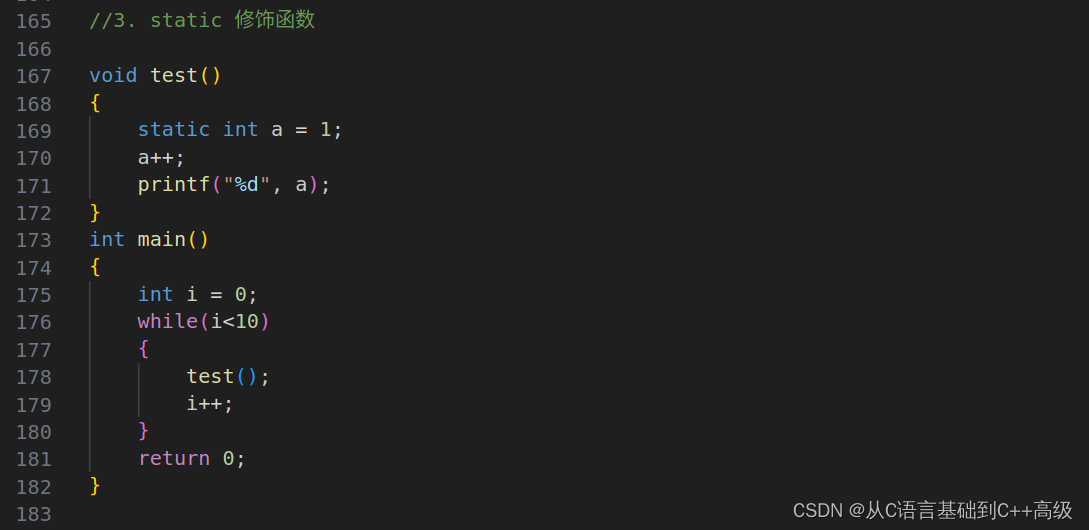
首先举个例子,写一个函数,定义临时变量 i = 0,写一个 while 循环,当 i < 10的时候,i 就++一次,i 从0开始,小于10,每次 i 是+1的话,那我们这循环几次呢?循环10次,然后每次循环调一个 test 函数,这个函数写在上面,在 test 函数里边,这个代码执行的结果是什么?是10个2
接下来就解析一下为什么是10个2:我们的代码从第175行开始往下走,走到 while 循环,里面的条件 i<10,<10的时候我们进来去调用 test 函数,每一次调用 test 函数的时候,进到这个函数里边创建 a,a 是个局部变量(特点是进入范围 a 创建,出范围 a 销毁),因此创建1,然后 a++会变成2,2的地方打印2就出来了
而当我们出范围的时候,a 就出它的局部范围了,a 就要销毁了,就不在了。那不在怎么办呢?下次再过来,进来之后继续 i++,再上去<10又进去了,然后再调用 test 函数再上去,再次进入这个函数的时候又发现这是个局部变量 a,再创建 a 是1,1++会变成2,2再打印,以此类推这样10次,我们的屏幕上应该会打印10个2,如图所示:


刚刚要讲 static 要修饰局部变量,第169行 a 是个局部变量,用 static 修饰一下,现在它的结果变成什么?现在是2-11
接下来就解析一下结果为什么是2-11:首先第一次进去,我们第一次进去调用这个 test 函数的时候,我们肯定会创建第169行变量 a,a 就有了,a是1,++后变成2,那我们第一次打印2是毋庸置疑、天经地义的,这个没有任何问题,但是第二次打印的是3,第二次如果打印3的电话,而 a 又是++了的,a 是2才行,所以从第二次进去之后没有新建 a 。所以,这个2是上一次保留下来的。
也就是说 static 修饰局部变量 a 的时候,它第一次进去的时候就在,a 就创建好了,是1,a++用完之后变成2,变成之后的2打印,完了出这个范围的时候 a没有销毁,没有销毁,它下一次进入这个函数的时候 a 依然还在,在的时候第169行代码就没有意义了,它不是1,它是2,2在++变成3,3再打印
因此 a 被 static 修饰之后出它的范围,它不销毁,不销毁就意味着它的生命周期变长了,进来进入范围的时候创建,出这个范围的时候销毁,它的生命周期就到期了,而现在进它的范围创建,出它的范围不销毁,如图所示:

因此,我们就可以总结出 static 的一个特点:static 修饰局部变量,改变了局部变量的生命周期,本质上是改变了变量的存储类型,致使它改变了变量的生命周期
什么是存储类型?举个例子:这是我们的内存,内存基本上都会划分为几个区域(在学习语言的层次上,我们会讨论这几个区域),第一个区域叫栈区,还有个叫堆区,还有个静态区。
其中栈区里边存的是局部变量,函数的参数(只要是局部的、临时的这种变量都在栈上放着)
堆区是用来动态内存分配的,如malloc,calloc,realloc,free 等
静态区存两种值:一种是全局变量,另一种是 static 修饰的静态变量,如图所示:

而刚刚这个 a 没有被修饰的时候,a 是局部变量,是放在栈区上的,当被 static 修饰之后,它就不放在栈区了,它直接放到静态区去了,其实本质上是 a 由栈区变到了静态区,改变了它的存储类型,因为存在不同的区域了,这个数据就有了不同的特点
(静态区里边我们就只看全局变量,全局变量的声明周期非常长,其实跟静态变量的生命周期是一样的,静态变量和全局变量的生命周期都是一样的,它的生命周期和程序的生命周期是一样的,程序不结束,全局变量/静态变量就不销毁)
所以,如果我们希望一个变量出了它的范围不销毁,还要继续使用,下次进去之后它希望保留它原来的值,我们就可以用 static 修饰一下,如果 static 不修饰的话,它出了范围就销毁了
12.6.2. static修饰全局变量
我们现在有一个 test.c 源文件,还有另外一个 Add.c 源文件,也就是说,我们现在有2个文件。然后我们在 Add.c 文件里边定义一个全局变量 int g_val = 2022,这是我们定义的一个全局变量。在 test.c 里边写一个 main 函数,在 main 函数里边想使用一下 Add.c 文件中的的全局变量
那怎么使用呢?我们直接用:printf("%d\n", g_val),当我们直接用的时候,test.c 中第189行代码报了一个错误:未声明的标识符号,即声明不了。如图所示:
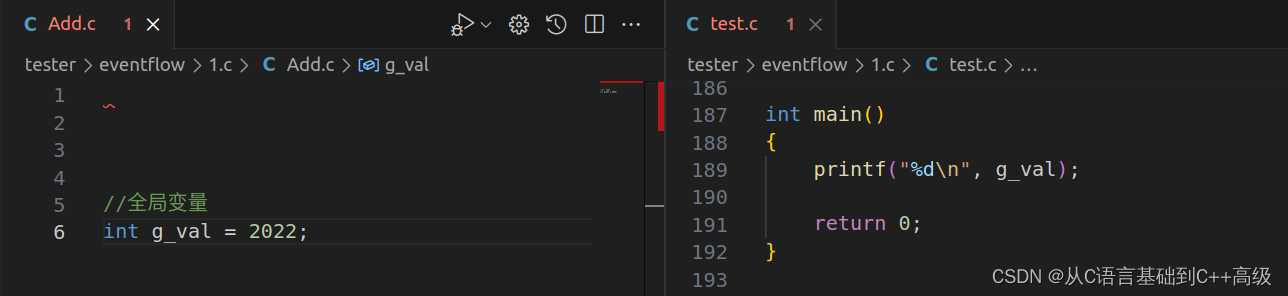

它这个地方提示的错误,说是未声的标识符,那就是没有声明,声明一下就可以了。因为 Add.c 文件定义的变量,test.c 文件不知道。那需要怎么弄呢?告诉它,即声明一下。
声明其实就是告诉它,怎么告诉它呢,我有个变量是 int 类型的,我的名字叫 g_val 就可以了(在 test.c 第187行代码),但是其实我们通常在它的前面会加上 extern(extern 用来声明外部符号,这个符号是来自于其他地方,声明的时候,不需要指定它的值,我们只要指定类型、名字就可以了)。如图所示:
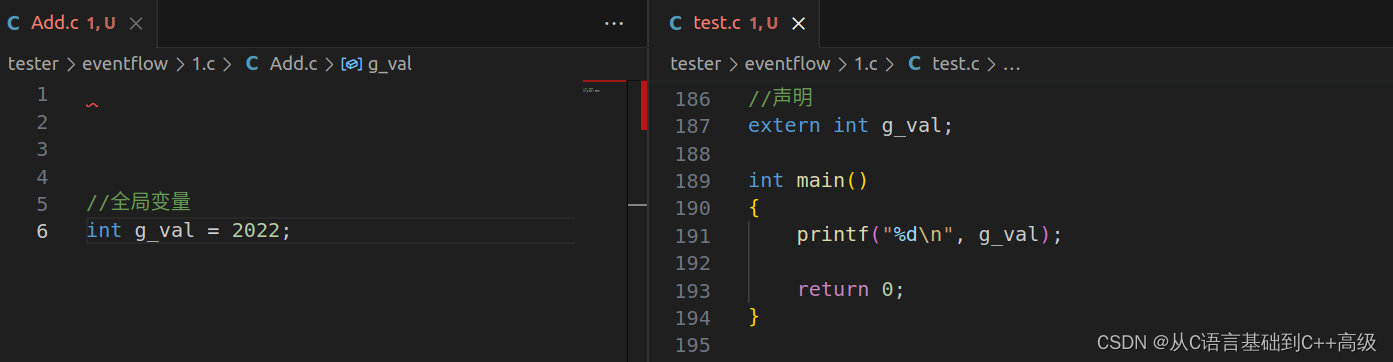

这个时候,我们大概就清楚了:当我们在 Add.c 文件中定义的全局变量,在 test.c 文件中想使用的时候,只要声明,然后就可以用。这就是全局变量的特点,全局变量在整个工程中都可以用所以跨文件使用,没有任何问题
这个时候我们用 static 修饰一下,那 test.c 文件中还能不能用呢?这个时候它就会报错,这一次全局变量被 static 修饰了,然后报的错误结果是:无法解析的外部符号,
当我们这些被 static 修饰之后,即使在 test.c 文件中声明了,依然没法使用全局变量,显示着不识别这个东西。也就是说,static 修饰了全局变量之后,其实声明也没用了,如图所示:
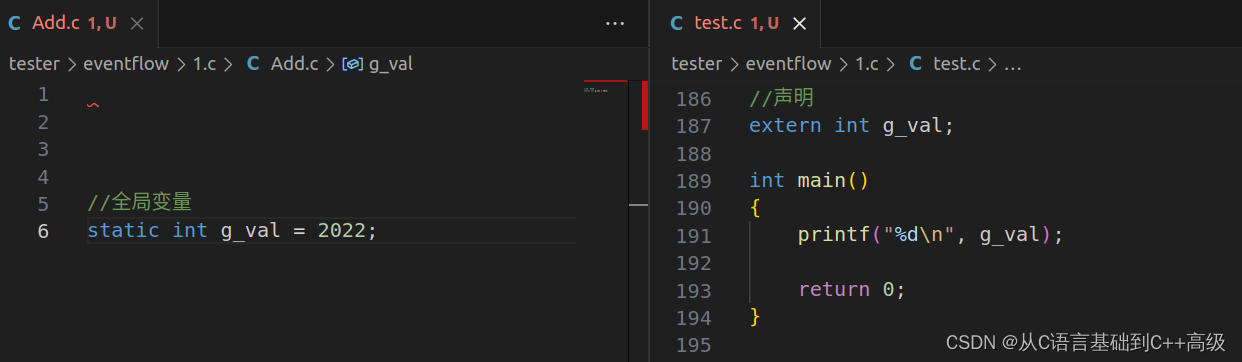

因此:static 修饰全局变量,使这个全局变量只能在自己所在的源文件(.c 文件)内部可以使用,其他源文件不能使用
static 一旦修饰这个全局变量,这个全局变量不能在其他地方使用了,只能在本源文件内部使用,给我们的感觉是好像修改了它的作用域,我们的原来一个全局变量在整个工程里边都可以使用,现在好像不是了。其实不能讲作用域,感觉好像是它的作用范围变小了,但实际上,这个地方不是在改变作用域!(不要调入误区!)
全局变量在其他源文件内部可以被使用,是因为全局变量具有外部链接属性,但是被 static 修饰之后,就变成了内部链接属性,其他源文件就不能链接到这个静态的全局变量了,因此给我们的感觉是:一个全局变量在一个文件里定义的链接之后被 static 修饰,其他源文件就不能使用它了,如果不被 static 修饰,那别的文件是可以使用的。
补充:外部链接属性:外部谁想使用它,链接它就可以了
12.6.3. static修饰函数
修饰函数跟修饰全局变量是非常非常相似的:同理,我们在 Add.c 源文件中写一个 Add 函数,Add 函数叫加法函数,使两个 int 相加。在函数体里边写上 return x + y,也就是说,我们现在有2个文件
然后在 Add.c 源文件中定义的函数,我们想在 test.c 源文件中它,我们还是在 test.c 里边写一个 main 函数,在 main 函数里边写上 int a = 10,int b = 20,int sum = 0,然后用 Add 函数把 a 和 b 相加一下,加出来的和,我们放到 sum 里边去,然后打印 sum 值就行
(以下都是重点)我们在 Add.c 文件中定义的 Add 函数,想在 test.c 文件中用它,这是两个不同的文件,那这个时候能不能用呢?其实从原理上讲,也是可以被使用的。但是还是那句话:Add.c 文件中定义的函数,test.c 文件中的 main 函数怎么知道呢?它是不知道的。那怎么办呢?我们要声明,声明函数
关于这个发布声明这个事情,比如说某个明星发布了声明,说我现在有女朋友了或者有男朋友了,我结婚了等等,其实我只是告诉你这些事情,我不需要告诉你细节的。我是怎么结婚的,我怎么找到女朋友的,我可能你不需要告诉你。女朋友叫什么,身高多少,不需要告诉你
声明函数其实就是这样的,声明函数和声明全局变量是一样的道理,声明,声明外部的符号 extern,然后紧接着下来,我们就告诉它的是:我的返回类型是 int,我的函数名叫 Add,我的参数,第一个是 int 类型,第二个也是 int 类型,我有两个 int 参数就够了,剩下的细节不用告诉它,没必要告诉它,就可以了(请参考 test.c 文件中第198行代码),如图所示:
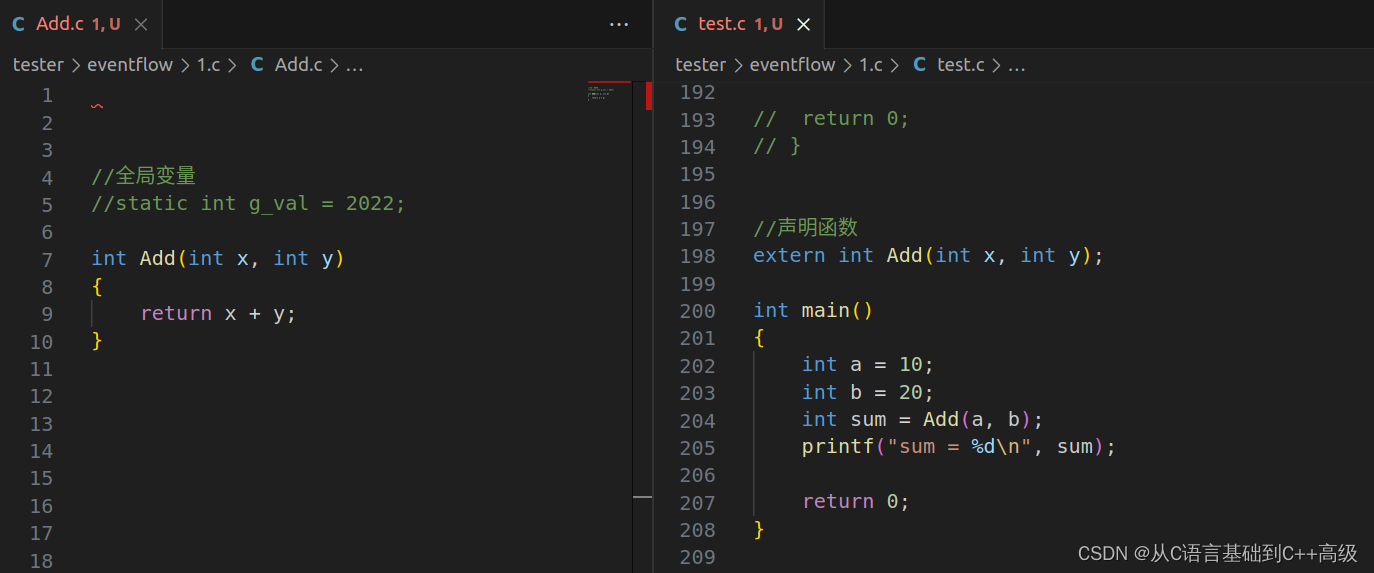

值得注意的是:第198行代码参数中,第一个 int 后面跟个 x,没问题;第二个 int 后面跟个 y,也没问题,想跟就跟,不想跟也可以
我们要保持跟这个函数的原型一摸一样,可以跟上否则也可以不跟,没有任何问题,只要告诉我返回类型是什么、函数名是什么、参数类型是什么就可以了
那我们 static 修饰一下,又会发生什么事情呢?这个时候就是 static 修饰函数了,如图所示:
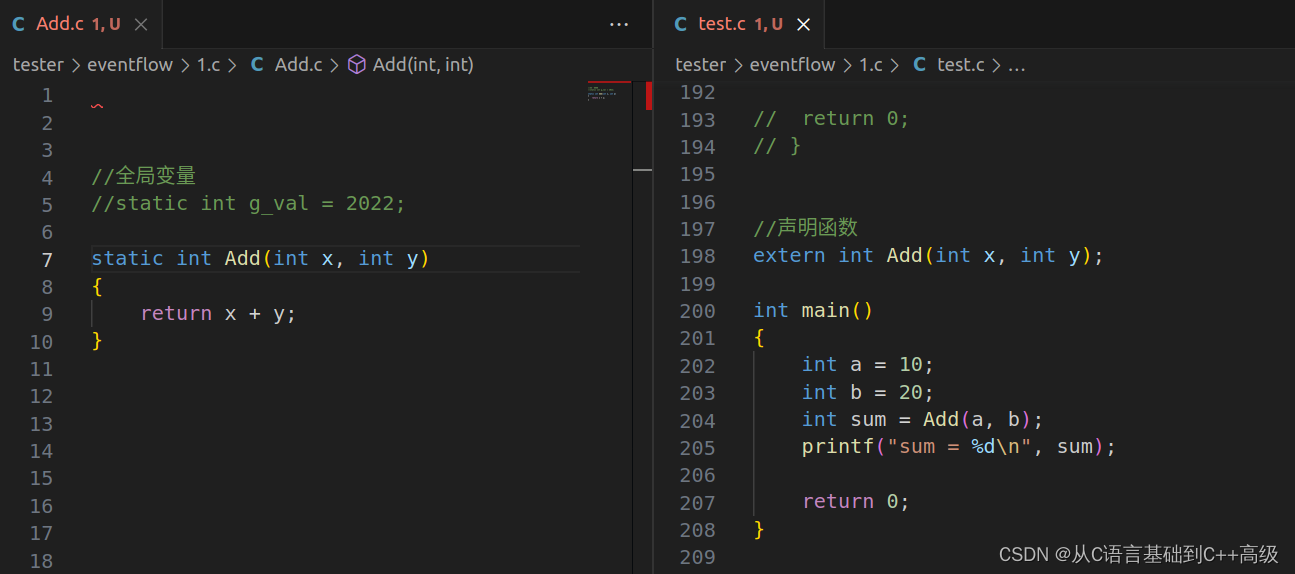

这个时候我们发现了:它的错误信息跟我们之前,修饰全局变量是一模一样的,无法解析的外部符号_Add,这个地方只是多了一个_Add,Add 还是 Add,然后第204行代码去用 Add 的时候找不到,无法解析的外部符号,来自外部的这个符号我不知道,没见过这个符号
因此我们大概的也就可以得出一个结论:
static 修饰函数,使函数只能在自己所在的源文件内部使用,不能在其他源文件内部使用
本质上:static 是将函数的外部链接属性变成了内部链接属性!(和 static 修饰全局变量一样)















 5983
5983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









