






是不是经常遇见这种情况:
办公网络日常断网,运营商表示:网络没问题。
到底是哪里出问题?
抛开宽带运营商的原因,还有什么会影响网络稳定性,导致网络差?
百兆口vs千兆口
路由器、网线、宽带运营商三者叠加在一起最终影响网络的稳定性,关于网速常见单位如下:
· MB/s:常见于下载文件当中;
· Mb/s:常见于路由器和带宽的商家介绍中,一般写成Mbps,或者简写为M;
其中,1B=8b,因此当我们的宽带为200M时,理论上它的最大速度为200÷8=25 MB/s,当然这是属于极限速度。
实际上,还要看路由器和网线,如果路由器只有百兆网口,它的极限速度也会被限制在100M,建议在购买路由器时,尽可能选择双千兆网口的路由器,具体参考数据如下:

WAN用于外网,LAN用于内网,这是买路由器时最容易踩坑的地方,很多的商品标明千兆网口,但并非双千兆,而是百兆+千兆。
因此在购买路由器过程中,多加留意这两个端口数据。
优选WiFi 6
随着智能设备的不断优化,我们对网络的要求越来越高,现在的手机、平板、笔记本电脑等也开始适配WiFi 6协议,实现在打游戏、看视频、购物抢购时快人一步,WiFi 6具体优势如下:
高带宽/高并发:相比传输速率只有3.5Gbps,理论速度是867Mbps的WiFi 5,WiFi6的传输速率提升至9.6Gbps,理论速度提升至1201Mbps,还提升多台设备同时传输时的吞吐量;
低延迟/低功耗:WiFi 6平均延迟时间为20ms,而WiFi5为30ms,延迟降低了1/3,另外WiFi 6还支持TWT,联网设备功耗也降低30%左右;
设备价格:随着技术的成熟,WiFi 6的价格也打下来了,办公环境使用WiFi6协议路由器更合适。
具体参数参考如下:

路由器内存与带机量
一般家用路由器对CPU、内存等参数要求并不高,但办公环境外界干扰因素太多,因此建议办公网络环境尽量选择较大内存+CPU更强的设备,才能够流畅处理数据。
此外,建议路由器预留50%的带机量空间,保障设备更好地运行,例如:一台路由器需要承载100台联网设备,那么路由器带机量至少是150台,才能够支撑整个网络的正常运行(带机量越多,价格越贵)。

双频和单频路由器
一般路由器都有2.4G和5G双频段,它们会同时发出2.4G+5G信号,二者的差异如下图:
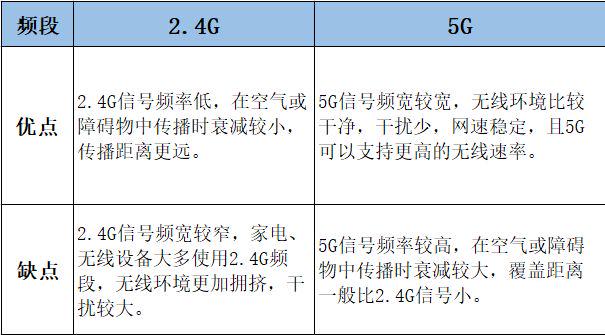
覆盖范围广,提高网速,双频道同时支持是路由器的理想状态,目前一些厂商还将路由器做到了多频合一,能够智能选择最优网络。
建议办公网络选择多频段的路由器,还有一个重要原因是一些物联网设备只支持2.4G频段,例如打印机、摄像机、打卡机等。
路由器的天线
科普一个概念——MIMO,分别有SU-MIMO(单用户多进多出)和MU-MIMO(多用户多进多出)二者差异如下:
1、早期WiFi支持SU-MIMO,可以将它看成连接WiFi的设备排队传输数据,上一个传输完数据才能轮到下一个,这就像只有一辆公交车,但乘客太多,需要乘客排队坐车;
2、目前的绝大部分WiFi6路由器都支持MU-MIMO,这相当于有多辆公交车载客,乘客不需要等待,这样速度也就增加了;

另外,一般使用2根天线就是2x2MIMO,4根天线就是双频道2x2MIMO,但因为大部分电子设备都只支持2x2MIMO,所以天线太多用处也不大。
还有一个误区是,很多用户认为天线越多信号越好,其实并不一定,因为决定路由器信号更重要的是输出功率和天线增益,而不同的厂商实现方式还有所差异。
交换机VS路由器
在家庭网络中,一台性能稍强的路由器足以覆盖所有设备,但在办公网络中除了无线设备之外,还有大量有线设备,仅靠路由器提供的LAN口是远远不够的。
因此还需要一个交换机,其目的是扩展路由器的LAN口,为更多有线设备联网,逻辑图如下:
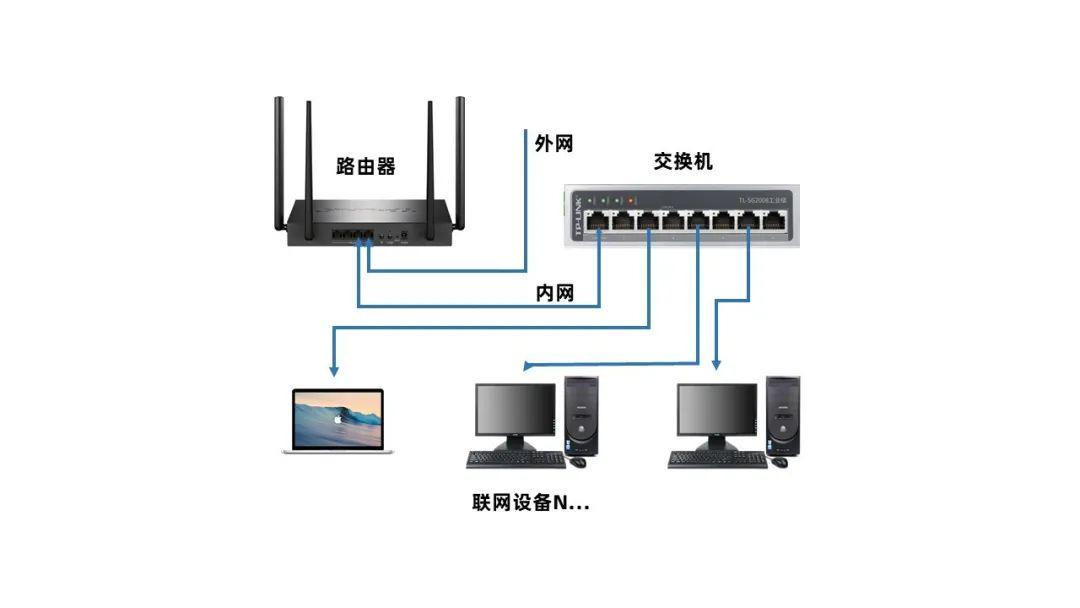
一般办公网络都是由路由器+交换机组成,交换机用于内部数据传输,路由器则利用NAT转发数据与外部网络通信。
中小型办公网络搭配
目前办公网络还在使用家用路由器+交换机,经常遇见多台设备同时联网,就出现网络差且不稳定的情况。
另外在南方炎热的夏天,室内环境温度高,再加上家用路由器散热欠缺,设备更加不稳定,断网重启成为日常操作。
为保障办公网络稳定,泓曚智联建议购买路由器时可以参照如下参数:
双千兆网口+WiFi6+带机量可预留50%空间+多频段
交换机选择建议选择千兆口以上即可,最主要的还是路由器的选择。
路由器+交换机本身的硬品质,但高质量的产品也需要高质量的售前售后,这也是产品的加分项。

















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









