






目录
3. HDFS HA集群搭建 Hadoop相关配置文件配置。
1.前期准备 搭建HDFS HA集群环境的前期准备工作。
比如:设置静态IP、主机名的配置,创建用户、免密码登录等;这些内容在前两章Hadoop环境搭建中已进行讲解,此处不再赘述;另外不建议通过修改中搭建的单节点的集群实现HA,最好搭建一套新的虚拟机环境来实现,此处以三个节点为例
2.ZooKeeper集群搭建
(1)将下载的Zookeeper(此处以Zookeeper_3.5.5为例,下载地址为https://archive.apache.org/dist/zookeeper/)复制到master节点上。
(2)解压Zookeeper解压命令如下我是在usr/local下进行解压:
tar -xzvf zookeeper_3.5.5.tar.gz
觉得打的名称太多可以重命名zookeeper_3.5.5.tar.gz
mv zookeeper_3.5.5.tar.gz zookeeper
(3)进入解压后的Zookeeper的conf目录下,将zoo.sample.cfg文件修改为zoo.cfg,命令如下:
cp zoo.sample.cfg zoo.cfg
(4)使用vi命令打开zoo.cfg,将其内容中的dataDir修改为自定义的目录:
dataDir=/usr/local/zookeeper/zkdata
在文件末尾添加如下内容(要跟自己自定义的名称相符合,不然会导致后面运行不了):
server.1=mater:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
上面配置中的1,2,3指Zookeeper集群各节点的编号,等号右侧以冒号分割的内容分别指的是对应的主机名,节点间的心跳端口,数据交互的端口。
(5)zoo.cfg文件修改保存后,创建其中指定的dataDir目录,并且将配置中对应的节点编号保存到一个名称为myid的文件中。
cd /usr/local/zookeeper/zkdata
vim myid 写入1
(6)通过scp命令将解压的Zookeeper文件夹分发到slave1和slave2节点在usr/local下分发
scp -r usr/local/zookeeper root@slave1:/usr/local/
scp -r usr/local/zookeeper root@slave2:/usr/local/
(7)分别在slave1和slave2上修改zkdata文件夹,并在其中修改包含对应编号的myid文件。 在slave1和slave2节点分别执行如下命令:
在第二台cd /usr/local/zookeeper/zkdata
vim myid修改为2
在第三台cd /usr/local/zookeeper/zkdata
vim myid修改为3
(8)执行Vi /ect/profile命令,在文件中添加如下内容将ZooKeeper安装目录下的bin文件夹添加到path环境变量中,以方便启动ZooKeeper服务
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=.:$ZOOKEEPER_HOME/bin$PATH
生效 source /etc/profile
(9)执行Zookeeper启动命令来测试ZooKeeper是否安装成功
zkServer.sh start
在三个节点上分别执行如下命令,也是在bin下执行
zkServer.sh status
如果提示如下,说明zookeeper安装成功了(看的出来slave1是主,另外两台是从)



3. HDFS HA集群搭建 Hadoop相关配置文件配置。
包括core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml和slaves五个文件,下面依次介绍每个文件的配置内容。
(1) 使用vi命令打开core-site.xml文件,添加如
<configuration>
<!--指定hdfs的nameservice为ns-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value> 这里自定义,可以用自己想用的,但要跟后面名称一致
</property>
<!--指定hadoop数据得到临时存放目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/metadata</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,slave1:2181,slave2:2181</value> 名称要跟自己主机一致
</property>
</configuration>
(2) 使用vi命令打开hdfs-site.xml文件,添加如下内容:
<configuration>
<!--HDFS保存数据的副本数量,默认值为3,这里设置为2-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--定hdfs的nameservice为ns,需要和core-site.xml中的保持一致-->
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!--ns下面有两个NameNode.分别是nn1,nn2-->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!--nn1的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>master:8020</value>
</property>
<!--nn1的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>master:50070</value>
</property>
<!--nn2的RPC通信地址-->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>slave1:8020</value>
</property>
<!--nn2的http通信地址-->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>slave1:50070</value>
</property>
<!--指定NameNode的元数据在Journa1Node上的存放位置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/ns</value>
</property>
<!--指定JournalNode在本地磁盘存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/ha/journal</value>
</property>
<!--开启NameNode故障时自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置失败自动切换实现方式-->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置隔离机制-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--使用隔离机制时需要SSH免密登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>usr/local/hadoop/.ssh/id_rsa</value>
</property>
</configuration> (3)使用vi命令打开mapred-site.xml文件,添加如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--MapReduce JobHistory Server地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>(4)使用vi命令打开yarn-site.xml文件,添加如下内容:
<!--指定nodemanager启动时加载server的方式为shuffle server -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanger地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>(5)使用vi命令打开slaves文件,添加如下内容,设置三个DataNode节点。
master
slave1
slave2
(6)使用scp命令将配置好的hadoop分发到slave1和slave2节点。
scp -r /usr/local/hadoop/etc/hadoop root@slave1:/usr/local/hadoop/etc/
scp -r /usr/local/hadoop/etc/hadoop root@slave2:/usr/local/hadoop/etc/(7)启动HA集群所需的各个服务
① 启动Zookeeper 由于namenode要向journalnode写入日志,而journalnode依赖于Zookeeper,因此需要先启动ZooKeeper;在各个节点执行如下命令:
zkServer.sh start
然后使用如下命令查看ZooKeeper的状态:
zkServer.sh status
如果一个leader两个follower,则表示Zookeeper启动成功。
② 启动JournalNode 在master上执行如下命令:在cd /usr/local/hadoop/bin下进行
hadoop-daemons.sh start journalnode
执行完毕后,在各个节点使用jps命令查看每个节点中的进程,如果显示类似如下内容表示启动成功。
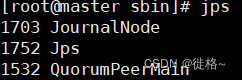


③ 格式化HDFS 在master上执行如下命令:
hdfs namenode -format
3.重点,很重要,没有按照这样子都是不行
① 首先在第一台启动master的namenode
hadoop-daemons.sh start namenode
② 然后在第二台同步第一台的namenode
hdfs namenode -bootstrapStandby
③ 再然后关闭第一台的namenode
hadoop-daemons.sh stop namenode
前面这三个步骤都要在格式化ZKFC前面弄完。
④格式化HDFS 在master上执行如下命令:
hdfs zkfc -formatZK
⑤ 启动hdfs和yarn集群,在master上执行如下命令:
start-dfs.sh 启动dfsde
start-yarn.sh 启动yarn
start-all.sh 这个是一键启动
最后通过使用jps命令可以查看已经启动的进程
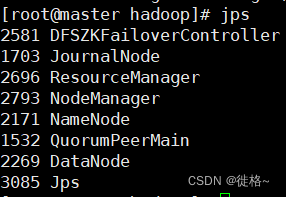
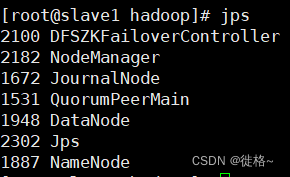
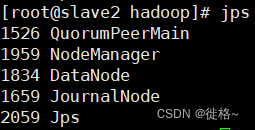
可以通过游览器输入“http://master:50070和“http://slave1:50070”.
高可用就这样子完成了!
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











