







并发库
在C++11之前,涉及到多线程问题,都是和平台相关的,比如Windows和Linux下各有自己的接口,这使得代码的可移植性比较差。C++11中最重要的特性就是对线程进行了支持,使得C++在并行编程时不需要依赖第三方库,而且在原子操作中还引入了原子类的概念。
一. thread 库
- thread 库底层是对各个系统的线程库进行封装,如 Linux 下的 pthread 库和 Windows 下 Thread 库等,所以 C++11 thread 库的第一个特点是可以跨平台,第二个特点是 Linux 和 Windows 下提供的线程库都是面向过程的,C++11 thread 是库面向对象的,并且融合了一些 C++11 语言特点,如右值引用的移动语义,可变模板参数等,用起来会更好用一些。
- 下面线程创建这里有4个构造函数,日常最常用的是第2个,他支持传一个可调用对象和参数即可,相比 pthread_create 而言,这里不再局限于只传递函数指针,其次就是参数传递也更方便, pthread_create 调用时,要传递多个参数需要打包成一个结构体,传结构体对象的指针过去。
- 另外也可以用第 1 个和第 4 个配合来创建线程,我们可以把右值线程对象移动构造或者移动赋值给另一个线程对象。第 3 个可以看到线程对象是不支持拷贝的。
- join 是主线程结束前需要阻塞等待创建的从线程,否则主线程结束,进程就结束了,从线程可能还在运行就被强行终止了。
- class thread::id 是一个 thread 的内部类用来表示线程 id,支持比较大小,流插入和流提取,通过特化 hash 仿函数做 unordered_map 和 unordered_set 的 id 等。底层的角度看 thread 本质还是封装各个平台的线程库接口。各个平台的线程 id 表示类型不同,所以只能用一个类来进行封装。线程对象可以通过 get_id 获取线程 id,在执行体内可以通过 this_thread::get_id() 获取线程 id。
// 默认构造,不会抛异常
thread() noexcept;
// 有参构造,无法隐式类型转换
template <class Fn, class... Args>
explicit thread (Fn&& fn, Args&&... args);
// 不支持拷贝构造
thread (const thread&) = delete;
// 移动构造
thread (thread&& x) noexcept;
// Linux 下创建线程
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
// Windows 下创建线程
HANDLE CreateThread(
LPSECURITY_ATTRIBUTES lpThreadAttributes,
SIZE_T dwStackSize,
LPTHREAD_START_ROUTINE lpStartAddress,
LPVOID lpParameter,
DWORD dwCreationFlags,
LPDWORD lpThreadId)
#include <iostream>
#include <thread>
using namespace std;
void routine(int x, int y)
{
cout << "线程id: " << this_thread::get_id() << ", x + y = " << x + y << endl;
}
int main()
{
thread t1(routine, 10, 20);
thread t2(routine, 30, 40);
// 通过对象获取线程 id
//cout << t1.get_id() << endl;
//cout << t2.get_id() << endl;
// 等待线程结束,回收线程资源
t1.join();
t2.join();
return 0;
}
线程并发执行,由于显示器是公共资源,输出是乱序的,需要加锁!
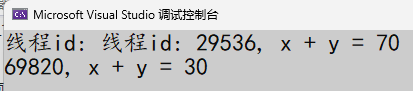
int main()
{
vector<thread> threads(2);
// 利用移动赋值的发送,将创建的临时对象(右值对象)移动赋值给创建好的空线程对象
for (int i = 0; i < 2; ++i)
threads[i] = thread(routine, 1, 2);
for (auto& th : threads)
th.join();
return 0;
}
二. this_thread
- this_thread 是命名空间 std 下的一个命名空间,主要封装了线程相关的 4 个全局接口函数。
- get_id 是当前执行线程的线程 id。
- yield 是主动让出当前线程的执行权,让其他线程先执行。此函数的确切行为依赖于实现,特别是取决于使用中的 OS 调度器机制和系统状态。例如,先进先出实时调度器 (Linux 的 SCHED_FIFO) 会挂起当前线程并将它放到准备运行的同优先级线程的队列尾,而若无其他线程在同优先级,则 yield 无效果。
- sleep_for 阻塞当前线程执行,至少经过指定的 sleep_duration。因为调度或资源争议延迟,此函数可能阻塞长于 sleep_duration。
- sleep_until 阻塞当前线程的执行,直至抵达指定的 sleep_time。函数可能会因为调度或资源纠纷延迟而阻塞到 sleep_time 之后的某个时间点。
thread::id get_id() noexcept;
void yield() noexcept;
template <class Rep, class Period>
void sleep_for (const chrono::duration<Rep,Period>& rel_time);
template <class Clock, class Duration>
void sleep_until (const chrono::time_point<Clock,Duration>& abs_time);
// chrono 是一个命名空间
// duration 管理相对时间段的类
// time_point 管理绝对时间点的类
#include <iostream>
#include <thread>
#include <chrono>
int main()
{
std::cout << "countdown:" << std::endl;
for (int i = 10; i > 0; --i)
{
std::cout << i << std::endl;
// 主线程休眠1秒的倒计时
this_thread::sleep_for(std::chrono::seconds(1));
}
std::cout << "Lift off!" << std::endl;
return 0;
}
三. mutex
- mutex 是封装的互斥锁的类,用于保护临界区的共享数据。mutex 主要提供 lock 和 unlock 两个接口函数。 mutex 提供排他性非递归所有权语义:(1) 调用方线程从它成功调用 lock 或 try_lock 开始,到它调用 unlock 为止占有 mutex。(2) 线程占有 mutex 时,其他线程如果试图要求 mutex 的所有权,那么就会阻塞(对于 lock 的调用),对于 try_lock 不会阻塞,而是返回 false
- mutex 不支持拷贝构造,如果 mutex 在仍为任何线程所占有时即被销毁,或在占有 mutex 时线程终止,那么行为未定义。
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
mutex mtx;
int x = 0;
void routine(int n)
{
// 在多核CPU中,加锁导致临界区中并行变串行,效率变低了
mtx.lock(); // 加锁放在外面比放在for循环里面效率高,频繁加锁解锁会有效率的消耗(切换线程的上下文数据)
for (int i = 0; i < n; i++)
{
++x; // 需要加锁解决线程安全问题,保证 ++x 是原子
}
mtx.unlock();
}
int main()
{
thread t1(routine, 100000);
thread t2(routine, 200000);
t1.join();
t2.join();
cout << x << endl; // 加锁保证结果一定为300000
return 0;
}
// 为什么++x不是原子的 ?
// CPU 不直接读取内存中的数据(二者的读写速度相差较大),大数据放在三级缓存中,小数据放在寄存器中
++x;
00DE4F6F A1 D0 03 DF 00 mov eax,dword ptr [x (0DF03D0h)]
00DE4F74 83 C0 01 add eax,1
00DE4F77 A3 D0 03 DF 00 mov dword ptr [x (0DF03D0h)],eax
// ++x 非原子操作: 由于时间片结束,保护线程上下文数据,线程阻塞,并发/多核CPU,线程并行 而出错
// 1. 先将内存中的数据移到寄存器
// 2. 寄存器中的值 + 1
// 3. 将寄存器中的值写回内存中
- 如果线程对象传参给可调用对象时,使用引用方式传参,实参位置需要加上 ref(obj) 的方式,主要原因是 thread 本质还是系统库提供的线程 API 的封装,thread 构造取到参数包以后,要调用创建线程的 API,还是需要将参数包打包成一个结构体传参过去,那么打包成结构体时,参考包对象就会拷贝给结构体对象,而使用 ref 传参的参数,会让结构体中的对应参数成员类型推导为引用,这样才能实现引用传参。
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
void routine(int n, int& x, mutex& mtx)
{
mtx.lock();
for (int i = 0; i < n; i++)
{
++x;
}
mtx.unlock();
}
int main()
{
int x = 0;
mutex mtx;
// 不能直接使用x和mtx传参
//thread t1(routine, 100000, x, mtx);
//thread t2(routine, 200000, x, mtx);
// 必须使用ref(x)和ref(mtx)传参,保证是引用
thread t1(routine, 100000, ref(x), ref(mtx));
thread t2(routine, 200000, ref(x), ref(mtx));
t1.join();
t2.join();
return 0;
}
int main()
{
int x = 0;
mutex mtx;
// 将上面的代码改为成使用lambda捕获外层的对象,就可以不用传参数
auto routine = [&x, &mtx](int n) {
mtx.lock();
for (int i = 0; i < n; i++)
{
x++;
}
mtx.unlock();
};
thread t1(routine, 100000);
thread t2(routine, 200000);
t1.join();
t2.join();
return 0;
}
- time_mutex 跟 mutex 完全类似,只是额外提供 try_lock_for 和 try_lock_untile 的接口,这两个接口跟 try_lock 类似,只是他不会马上返回,而是直接进入阻塞,直到时间条件到了或者解锁了就会唤醒试图获取锁资源。
- recursive_mutex 跟 mutex 完全类似,recursive_mutex 提供排他性递归所有权语义:(1) 调用方线程在从它成功调用 lock 或 try_lock 开始的时期里占有 recursive_mutex。此时期之内,线程可以进行对 lock 或 try_lock 的附加调用。所有权的时期在线程进行匹配次数的 unlock 调用时结束。(2) 线程占有 recursive_mutex 时,若其他所有线程试图要求 recursive_mutex 的所有权,则它们将阻塞 (对于调用 lock) 或收到 false 返回值 (对于调用 try_lock)
四. lock_guard
- lock_guard 是 C++11 提供的支持 RAII 方式管理互斥锁资源的类,这样可以更有效的防止因为异常等原因导致的死锁问题。他们的大致原理如下面模拟的 LockGuard 类似。
#include <iostream>
#include <chrono>
#include <thread>
#include <mutex>
using namespace std;
template<class Mutex>
class LockGuard
{
public:
LockGuard(const LockGuard&) = delete;
LockGuard(Mutex& mtx)
:_mtx(mtx)
{
_mtx.lock();
}
~LockGuard()
{
_mtx.unlock();
}
private:
Mutex& _mtx; // 引用,const,没有默认构造的自定义类型:必须在初始化列表中初始化
};
int main()
{
int x = 0;
mutex mtx;
auto routine = [&x, &mtx](int n)
{
//lock_guard<mutex> lock(mtx);
LockGuard<mutex> lock(mtx);
//mtx.lock();
for (int i = 0; i < n; i++)
{
++x;
}
//mtx.unlock();
};
thread t1(routine, 1000000);
thread t2(routine, 2000000);
t1.join();
t2.join();
return 0;
}
- lock_guard 的功能简单纯粹,仅仅支持 RAII 的方式管理锁对象。也可以在构造的时候传递第二个参数 std::adopt_lock 告诉 lock_guard 互斥锁 mtx 已经被锁住了,lock_guard 不需要再锁一次,lock_guard 接管这个互斥锁,并确保在作用域结束时自动释放锁。其次 lock_guard 类不支持拷贝构造。
#include <iostream>
#include <vector>
#include <thread>
#include <mutex>
using namespace std;
mutex mtx;
void print_thread_id(int id)
{
mtx.lock();
lock_guard<mutex> lock(mtx, std::adopt_lock); // 将mtx交给lock管理,由lock释放mtx
cout << "thread #" << id << endl;
}
int main()
{
vector<thread> threads(10);
for (int i = 0; i < 10; ++i)
threads[i] = thread(print_thread_id, i + 1);
for (auto& th : threads)
th.join();
return 0;
}
五. unique_lock
- unique_lock 也是 C++11 提供的支持 RAII 方式管理互斥锁资源的类,相比 lock_guard 他的功能支持更丰富复杂。
- unique_lock 首先在构造的时候传不同的 tag,支持在构造的时候不同的方式处理锁对象。defer_lock:不会立即锁定互斥锁,而是延迟到后续手动调用 lock() 方法时才锁定。try_to_lock:尝试非阻塞地锁定互斥锁。如果互斥锁当前不可用,则直接返回,不会阻塞线程。adopt_lock:假设互斥锁已经被锁定,std::unique_lock 接管这个锁的管理。

- unique_lock 首先在构造的时候传时间段和时间点,用来管理 time_mutex 系统,构造时调用 try_lock_for 和 try_lock_until
- unique_lock 不支持拷贝和赋值,支持移动构造和移动赋值。
- unique_lock 还提供了 lock/try_lock/unlock 等系列的接口等系统的接口。
- unique_lock 还可以通过 operator bool 去检查是否 lock 了锁对象。
六. lock 和 try_lock 防止死锁问题
- lock 是一个函数模板,可以支持对多个锁对象同时锁定,如果其中一个锁对象没有锁住,lock 函数会把已经锁定的对象解锁而进入阻塞,直到锁定所有的所有的对象。
template <class Mutex1, class Mutex2, class... Mutexes>
void lock (Mutex1& a, Mutex2& b, Mutexes&... cde);
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
mutex foo, bar;
void task_a()
{
// 可能导致死锁问题
// foo.lock();
// bar.lock();
// 先锁foo,在锁bar,若bar被占用,直接解锁foo,最后阻塞,直到两个锁都锁住
lock(foo, bar);
cout << "task a" << endl;
foo.unlock();
bar.unlock();
}
void task_b()
{
// 可能导致死锁问题
// foo.lock();
// bar.lock();
// 先锁bar,在锁foo,若foo被占用,直接解锁bar,最后阻塞,直到两个锁都锁住
lock(bar, foo);
cout << "task b" << endl;
bar.unlock();
foo.unlock();
}
int main()
{
thread th1(task_a);
thread th2(task_b);
th1.join();
th2.join();
return 0;
}
- try_lock 也是一个函数模板,尝试对多个锁对象进行同时尝试锁定,如果全部锁对象都锁定了,返回 -1,如果某一个锁对象尝试锁定失败,把已经锁定成功的锁对象解锁,并则返回这个对象的下标(第⼀个参数对象,下标从0开始算)
template <class Mutex1, class Mutex2, class... Mutexes>
int try_lock (Mutex1& a, Mutex2& b, Mutexes&... cde);
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
mutex foo, bar;
void task_a()
{
foo.lock();
cout << "task a" << endl;
bar.lock();
// ...
foo.unlock();
bar.unlock();
}
void task_b()
{
int x = try_lock(bar, foo); // 若bar锁失败了,返回0;若foo锁失败了,返回1;若bar和foo都锁成功,返回-1
if (x == -1)
{
cout << "task b" << endl;
// ...
bar.unlock();
foo.unlock();
}
else
{
cout << "[task b failed: mutex " << (x ? "foo" : "bar") << " locked]" << endl;
}
}
int main()
{
thread th1(task_a);
thread th2(task_b);
th1.join();
th2.join();
return 0;
}
七. call_once
- 多线程执行时,让第一个线程执行 Fn 一次,其他线程不再执行 Fn
template <class Fn, class... Args>
void call_once (once_flag& flag, Fn&& fn, Args&&... args);
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
using namespace std;
std::once_flag flag; // 一起使用,用于跟踪是否已经执行过
bool initialized = false;
void initialize()
{
cout << "Initializing..." << endl;
initialized = true;
}
void worker_thread()
{
call_once(flag, initialize); // 确保某个函数或操作只执行一次,即使在多线程环境下也是如此
cout << "Worker thread " << this_thread::get_id() << " sees initialized = " << initialized << endl;
}
int main()
{
vector<thread> threads;
for (int i = 0; i < 10; ++i)
{
// 使用 emplace_back 直接构造线程对象,线程不支持拷贝构造
//threads.emplace_back(worker_thread);
// 使用 move 转移线程所有权,线程支持移动构造
thread t(worker_thread);
threads.push_back(move(t));
}
for (auto& th : threads)
{
th.join();
}
return 0;
}
八. 原子操作
频繁的加锁解锁,导致线程阻塞唤醒,进行线程切换 (恢复上下文数据),若访问临界区的时间非常短,存在代价。利用原子操作可以不需要加锁。
- atomic 是一个模板的实例化和全特化均定义的原子类型,他可以保证对一个原子对象的操作是线程安全的,不需要加锁。
- atomic 对 T 类型的要求模板可用任何满足可复制构造 (CopyConstructible) 及可复制赋值 (CopyAssignable) 的可平凡复制 (TriviallyCopyable) 类型 T 实例化,T 类型用以下几个函数判断时,如果一个返回 false,则用于 atomic 不是原子操作。
struct Date
{
int _year = 1;
int _month = 1;
int _day = 1;
};
template<class T>
void check()
{
cout << typeid(T).name() << endl;
cout << std::is_trivially_copyable<T>::value << endl;
cout << std::is_copy_constructible<T>::value << endl;
cout << std::is_move_constructible<T>::value << endl;
cout << std::is_copy_assignable<T>::value << endl;
cout << std::is_move_assignable<T>::value << endl;
cout << std::is_same<T, typename std::remove_cv<T>::type>::value << endl;
}
int main()
{
check<int>();
check<int*>();
check<double>();
check<Date>();
check<Date*>();
check<string>(); // 非原子,其余都是原子
check<string*>();
return 0;
}
- load和store可以原子的读取和修改atomic封装存储的T对象。
- atomic的原理主要是硬件层面的支持,现代处理器提供了原子指令来支持原子操作。例如,在x86架构中有CMPXCHG(比较并交换)指令。这些原子指令能够在一个不可分割的操作中完成对内存的读取、比较和写入操作,简称CAS,Compare And Set 或是 Compare And Swap。另外为了处理多个处理器缓存之间的数据一致性问题,硬件采用了缓存一致性协议,当一个atomic操作修改了一个变量的值,缓存一致性协议会确保其他处理器缓存中的相同变量副本被正确地更新或标记为无效。具体可以参考下面的代码结合理解一下。
// gcc支持的CAS接口
bool __sync_bool_compare_and_swap(type* ptr, type oldval type newval);
type __sync_val_compare_and_swap(type* ptr, type oldval type newval);
// Windows支持的CAS接口
InterlockedCompareExchange(__inout LONG volatile* Target, __in LONG Exchange, __in LONG Comperand);
// C++11支持的CAS全局函数接口
template <class T>
bool atomic_compare_exchange_weak(atomic<T>* obj, T* expected, T val) noexcept;
template <class T>
bool atomic_compare_exchange_strong(atomic<T>* obj, T* expected, T val) noexcept;
// C++11中atomic类的成员函数接口
bool compare_exchange_weak(T& expected, T val, memory_order sync = memory_order_seq_cst) noexcept;
bool compare_exchange_strong(T& expected, T val, memory_order sync = memory_order_seq_cst) noexcept;
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using namespace std;
// atomic_int acnt; 与下面等价
atomic<int> acnt;
int cnt;
void Add(atomic<int>& acnt)
{
int old = acnt.load();
// 如果cnt的值跟old相等,则将cnt的值设置为old+1,并且返回true,这组操作是原子的
// 那么如果在load和compare_exchange_weak操作之间cnt对象被其他线程改了
// 则old和cnt不相等,则将old的值改为cnt的值,并且返回false
// 全局函数
while (!atomic_compare_exchange_weak(&acnt, &old, old + 1));
// 成员函数
//while (!acnt.compare_exchange_weak(old, old + 1));
}
void f()
{
for (int n = 0; n < 10000; ++n)
{
++acnt;
// Add的用CAS模拟atomic的operator++的原子操作
// Add(acnt);
++cnt;
}
}
int main()
{
std::vector<thread> pool;
for (int n = 0; n < 4; ++n)
pool.emplace_back(f);
for (auto& e : pool)
e.join();
cout << "原子计数器为:" << acnt << endl;
cout << "非原子计数器为:" << cnt << endl;
return 0;
}

- C++11的CAS操作支持,atomic对象跟expected按位比较相等,则用val更新atomic对象并返回值true。若atomic对象跟expected按位比较不相等,则更新expected为当前的atomic对象并返回值 false。
- compare_exchange_weak在某些平台上,即使原子变量的值等于expected,也可能“虚假地”失败(即返回false),这种失败是由于底层硬件或编译器优化导致的,但不会改变原子变量的。compare_exchange_strong保证在原子变量的值等于expected时不会虚假地失败。只要原子变量的值等于expected,操作就会成功。compare_exchange_weak在某些平台上可能比compare_exchange_strong更快。compare_exchange_weak可能会虚假的失败主要是由于硬件层间的缓存一致性和编译器优化等等,compare_exchange_strong要避免这些原因就要付出一定的代价,比如要使用硬件的缓存一致性协议(如MESI协议)
- 编译器可能会对代码进行优化,例如重排指令以提高性能。这些优化可能会导致操作的执行顺序与代码中的顺序不一致,从而引发问题。内存顺序模型通过规定操作的执行顺序,可以避免这种问题。
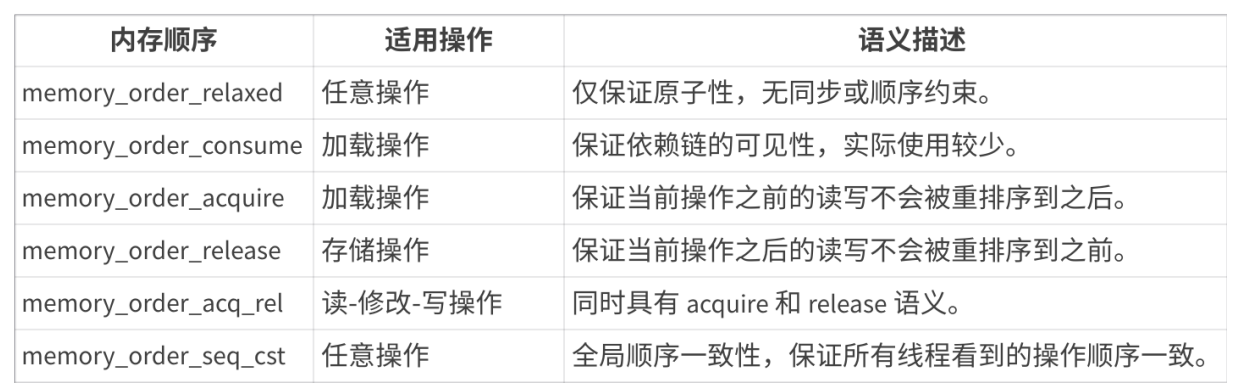
- 在C++11标准库中, std::atomic 提供了多种内存顺序( memory_order )选项,用于控制原子操作的内存同步行为。这些内存顺序选项允许开发者在性能与正确性之间进行权衡,特别是在多线程编程中。以下是std::atomic支持的六种内存顺序选项:
- memory_order_relaxed最宽松的内存顺序,仅保证原子操作的原子性,不提供任何同步或顺序约束。使用场景:适用于不需要同步的场景,例如计数器或统计信息。
std::atomic<int> x(0);
x.store(42, std::memory_order_relaxed); // 仅保证原子性
- memory_order_consume限制较弱的内存顺序,仅保证依赖于当前加载操作的数据的可见性。通常用于数据依赖的场景。使用场景:适用于某些特定的依赖链场景,但实际使用较少。
std::atomic<int*> ptr(nullptr);
int* p = ptr.load(std::memory_order_consume);
if (p)
{
int value = *p; // 保证 p 指向的数据是可见的
}
- memory_order_acquire保证当前操作之前的所有读写操作(在当前线程中)不会被重排序到当前操作之后。通常用于加载操作。使用场景:用于实现锁或同步机制中的“获取”操作。
std::atomic<bool> flag(false);
int data = 0;
// 线程 1
data = 42;
flag.store(true, std::memory_order_release);
// 线程 2
while (!flag.load(std::memory_order_acquire)) {}
std::cout << data; // 保证看到 data = 42
- memory_order_release保证当前操作之后的所有读写操作(在当前线程中)不会被重排序到当前操作之前。通常用于存储操作。使用场景:用于实现锁或同步机制中的“释放”操作。
std::atomic<bool> flag(false);
int data = 0
// 线程 1
data = 42;
flag.store(true, std::memory_order_release); // 保证 data = 42 在 flag = true 之前可见
// 线程 2
while (!flag.load(std::memory_order_acquire)) {}
std::cout << data; // 保证看到 data = 42
- memory_order_acq_rel结合了memory_order_acquire和memory_order_release的语义。适用于读-修改-写操作(如fetch_add或compare_exchange_strong)。使用场景:用于需要同时实现“获取”和“释放”语义的操作。
std::atomic<int> x(0);
x.fetch_add(1, std::memory_order_acq_rel); // 保证前后的操作不会被重排序
- memory_order_seq_cst最严格的内存顺序,保证所有线程看到的操作顺序是一致的(全局顺序一致性)。默认的内存顺序。使用场景:适用于需要强一致性的场景,但性能开销较大。
std::atomic<int> x(0);
x.store(42, std::memory_order_seq_cst); // 全局顺序一致性
int value = x.load(std::memory_order_seq_cst);
- 内存顺序的关系, 宽松到严格:memory_order_relaxed < memory_order_consume < memory_order_acquire < memory_order_release < memory_order_acq_rel < memory_order_seq_cst 。宽松的内存顺序(如 memory_order_relaxed )性能最好,但同步语义最弱。严格的内存顺序(如memory_order_seq_cst )性能最差,但同步语义最强。
- 总结一下,根据具体需求选择合适的内存顺序,可以在保证正确性的同时最大化性能。
1. 实现无锁栈
#include <iostream>
#include <atomic>
#include <thread>
#include <mutex>
#include <vector>
using namespace std;
template<class T>
struct Node
{
int _data;
Node* _next;
Node(const T& data)
: _data(data), _next(nullptr)
{}
};
namespace NotLock
{
template<class T>
class stack
{
public:
void push(const T& data)
{
Node<T>* newnode = new Node<T>(data);
// 将 _head 的当前值放到 newnode->_next 中
newnode->_next = _head.load();
//newnode->_next = _head.load(std::memory_order_relaxed);
// 如果 _head == newnode->_next 说明没有其他线程修改 _head
// 直接将 _head 修改为 newnode,返回 true
// 如果 _head != newnode->_next 说明有其他线程修改 _head
// 直接将 newnode->_next 修改为 _head,返回 false
while(!_head.compare_exchange_weak(newnode->_next, newnode)) { }
//while(!_head.compare_exchange_weak(newnode->_next, newnode, std::memory_order_release, std::memory_order_relaxed)) { }
}
private:
std::atomic<Node<T>*> _head = nullptr;
};
}
namespace Lock
{
template<class T>
class stack
{
public:
void push(const T& data)
{
Node<T>* newnode = new Node<T>(data);
newnode->_next = _head;
_head = newnode;
}
private:
Node<T>* _head = nullptr;
};
}
int main()
{
NotLock::stack<int> st1;
Lock::stack<int> st2;
std::mutex mtx;
int n = 1000000;
auto not_lock_stack = [&st1, n]
{
for (size_t i = 0; i < n; i++)
{
st1.push(i);
}
};
auto lock_stack = [&st2, &mtx, n]
{
for (size_t i = 0; i < n; i++)
{
std::lock_guard<std::mutex> lock(mtx);
st2.push(i);
}
};
// 4个线程分别使用无锁方式和有锁方式插入n个数据到栈中对比性能
size_t begin1 = clock();
std::vector<std::thread> threads1;
for (size_t i = 0; i < 4; i++)
threads1.emplace_back(not_lock_stack);
for (auto& th : threads1)
th.join();
size_t end1 = clock();
std::cout << "无锁栈插入 " << n << " 个数据花费的时间: " << end1 - begin1 << std::endl;
size_t begin2 = clock();
std::vector<std::thread> threads2;
for (size_t i = 0; i < 4; i++)
threads2.emplace_back(lock_stack);
for (auto& th : threads2)
th.join();
size_t end2 = clock();
std::cout << "有锁栈插入 " << n << " 个数据花费的时间: " << end2 - begin2 << std::endl;
return 0;
}

2. 实现自旋锁
自旋锁(SpinLock)是一种忙等待的锁机制,适用于锁持有时间非常短的场景。在多线程编程中,当一个线程尝试获取已被其他线程持有的锁时,自旋锁会让该线程在循环中不断检查锁是否可用,而不是进入睡眠状态。这种方式可以减少上下文切换的开销,但在锁竞争激烈或锁持有时间较长的情况下,会导致CPU资源的浪费。
atomic_flag是一种原子布尔类型。与所有atomic的特化不同,它保证是免锁的。与atomic不同,atomic_flag不提供加载或存储操作。主要提供test_and_set操作将flag原子的设置为true并返回之前的值,clear原子将flag设置为false。
以下是使用atomic_flag和atomic< bool >实现的一个简单自旋锁示例:
class SpinLock
{
public:
void lock()
{
// test_and_set将内部值设置为true,并且返回之前的值
// 第一个进来的线程将值原子的设置为true,返回false
// 后面进来的线程将原子的值设置为true,返回true,所以卡在这里空转
// 直到第一个进去的线程unlock,clear,将值设置为false
while (flag.test_and_set());
}
void unlock()
{
// clear将值原子的设置为false
flag.clear();
}
private:
// ATOMIC_FLAG_INIT默认初始化为false
std::atomic_flag flag = ATOMIC_FLAG_INIT;
};
class SpinLock
{
public:
void lock()
{
// 原子的对当前值进行替换,返回之前持有的值
// 第一个线程进来时:_flag 由 flase 替换为 true,返回 false
// 后面进来的线程:_flag 由 true 替换为 true,返回 true,所以卡在这里空转
// 直到第一个进去的线程unlock,将值设置为 false
while (_flag.exchange(true));
}
void unlock()
{
// 将 flag 修改为 false
_flag.store(false);
}
private:
std::atomic<bool> _flag = false;
};
测试自旋锁
#include <iostream>
#include <vector>
#include <atomic>
#include <thread>
// 测试自旋锁
void worker(SpinLock& lock, int& sharedValue)
{
lock.lock();
// 模拟一些工作
for (int i = 0; i < 1000000; ++i)
++sharedValue;
lock.unlock();
}
int main()
{
SpinLock lock;
int sharedValue = 0;
std::vector<std::thread> threads;
// 创建多个线程
for (int i = 0; i < 4; ++i)
threads.emplace_back(worker, std::ref(lock), std::ref(sharedValue));
// 等待所有线程完成
for (auto& thread : threads)
thread.join();
std::cout << "Final shared value: " << sharedValue << std::endl;
return 0;
}

九. 条件变量
wait系列成员函数
wait系列成员函数的作用就是让调用线程进行阻塞等待,包括wait、wait_for和wait_until。
//版本一
void wait(unique_lock<mutex>& lck);
//版本二
template<class Predicate>
void wait(unique_lock<mutex>& lck, Predicate pred);
函数说明:
- 调用第一个版本的wait函数时只需要传入一个互斥锁,线程调用wait后会立即被阻塞,直到被唤醒。
- 调用第二个版本的wait函数时除了需要传入一个互斥锁,还需要传入一个返回值类型为bool的可调用对象,与第一个版本的wait不同的是,当线程被唤醒后还需要调用传入的可调用对象,如果可调用对象的返回值为false,那么该线程还需要继续被阻塞。
为什么调用wait系列函数时需要传入一个互斥锁?
- 因为wait系列函数一般是在临界区中调用的,为了让当前线程调用wait阻塞时其他线程能够获取到锁,因此调用wait系列函数时需要传入一个互斥锁,当线程被阻塞时这个互斥锁会被自动解锁,而当这个线程被唤醒时,又会自动获得这个互斥锁。
- 因此wait系列函数实际上有两个功能,一个是让线程在条件不满足时进行阻塞等待,另一个是让线程将对应的互斥锁进行解锁。
wait_for和wait_until函数的使用方式与wait函数类似:
- wait_for函数也提供了两个版本的接口,只不过这两个版本的接口都比wait函数对应的接口多了一个参数,这个参数是一个时间段,表示让线程在该时间段内进行阻塞等待,如果超过这个时间段则线程被自动唤醒。
- wait_until函数也提供了两个版本的接口,只不过这两个版本的接口都比wait函数对应的接口多了一个参数,这个参数是一个具体的时间点,表示让线程在该时间点之前进行阻塞等待,如果超过这个时间点则线程被自动唤醒。
- 线程调用wait_for或wait_until函数在阻塞等待期间,其他线程调用notify系列函数也可以将其唤醒。此外,如果调用的是wait_for或wait_until函数的第二个版本的接口,那么当线程被唤醒后还需要调用传入的可调用对象,如果可调用对象的返回值为false,那么当前线程还需要继续被阻塞。
注意: 调用wait系列函数时,传入互斥锁的类型必须是unique_lock。
notify系列成员函数
notify系列成员函数的作用就是唤醒等待的线程,包括notify_one和notify_all。
- notify_one:唤醒等待队列中的首个线程,如果等待队列为空则什么也不做。
- notify_all:唤醒等待队列中的所有线程,如果等待队列为空则什么也不做。
注意: 条件变量下可能会有多个线程在进行阻塞等待,这些线程会被放到一个等待队列中进行排队。
1. 实现两个线程交替打印奇数和偶数
该题目主要考察的就是线程的同步和互斥。
- 互斥:两个线程都在向控制台打印数据,为了保证两个线程的打印数据不会相互影响,因此需要对线程的打印过程进行加锁保护。
- 同步:两个线程必须交替进行打印,因此需要用到条件变量让两个线程进行同步,当一个线程打印完再唤醒另一个线程进行打印。
但如果只有同步和互斥是无法满足题目要求的。
- 首先,我们无法保证哪一个线程会先进行打印,不能说先创建的线程就一定先打印,后创建的线程先打印也是有可能的。
- 此外,有可能会出现某个线程连续多次打印的情况,比如线程1先创建并打印了一个数字,当线程1准备打印第二个数字的时候线程2可能还没有创建出来,或是线程2还没有在互斥锁上进行等待,这时线程1就会再次获取到锁进行打印。
鉴于此,这里还需要定义一个flag变量,该变量的初始值设置为true。
- 假设让线程1打印奇数,线程2打印偶数。那么就让线程1调用wait函数阻塞等待时,传入的可调用对象返回flag的值,而让线程2调用wait函数阻塞等待时,传入的可调用对象返回!flag的值。
- 由于flag的初始值是true,就算线程2先获取到互斥锁也不能进行打印,因为最开始线程2调用wait函数时,会因为可调用对象的返回值为false而被阻塞,这就保证了线程1一定先进行打印。
- 为了让两个线程交替进行打印,因此两个线程每次打印后都需要更改flag的值,线程1打印完后将flag的值改为false并唤醒线程2,这时线程2被唤醒时其可调用对象的返回值就变成了true,这时线程2就可以进行打印了。
- 当线程2打印完后再将flag的值改为true并唤醒线程1,这时线程1就又可以打印了,就算线程2想要连续打印也不行,因为如果线程1不打印,那么线程2的可调用对象的返回值就一直为false,对于线程1也是一样的道理。

















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









