






1、什么是Python?
Python简介
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
Python发展历史
Python 是由 Guido van Rossum 在八十年代末和九十年代初,在荷兰国家数学和计算机科学研究所设计出来的。
Python 本身也是由诸多其他语言发展而来的,这包括 ABC、Modula-3、C、C++、Algol-68、SmallTalk、Unix shell 和其他的脚本语言等等。 像 Perl 语言一样,Python 源代码同样遵循 GPL(GNU General Public License)协议。 现在 Python 是由一个核心开发团队在维护,Guido van Rossum 仍然占据着至关重要的作用,指导其进展。
Python 2.0 于 2000 年 10 月 16 日发布,增加了实现完整的垃圾回收,并且支持 Unicode。
Python 3.0 于 2008 年 12 月 3 日发布,此版不完全兼容之前的 Python 源代码。不过,很多新特性后来也被移植到旧的Python 2.6/2.7版本。
Python 3.0 版本,常被称为 Python 3000,或简称 Py3k。相对于 Python 的早期版本,这是一个较大的升级。
Python 2.7 被确定为最后一个 Python 2.x 版本,它除了支持 Python 2.x 语法外,还支持部分 Python 3.1 语法。
Python特点
-
易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
-
易于阅读:Python代码定义的更清晰。
-
易于维护:Python的成功在于它的源代码是相当容易维护的。
-
一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
-
互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
-
可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
-
可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
-
数据库:Python提供所有主要的商业数据库的接口。
-
GUI编程:Python支持GUI可以创建和移植到许多系统调用。
-
可嵌入: 你可以将Python嵌入到C/C++程序,让你的程序的用户获得"脚本化"的能力。
Python典型应用
-
• Youtube - 视频社交网站
-
• Reddit - 社交分享网站
-
• Dropbox - 文件分享服务
-
• 豆瓣网 - 图书、唱片、电影等文化产品的资料数据库网站
-
• 知乎 - 一个问答网站
-
• 果壳 - 一个泛科技主题网站
-
• Bottle - Python微Web框架
-
• EVE - 网络游戏EVE大量使用Python进行开发
-
• Blender - 使用Python作为建模工具与GUI语言的开源3D绘图软件
-
• Inkscape - 一个开源的SVG矢量图形编辑器。
-
• …
2、Python能干什么?
-
• 爬取网站,爬取表格,爬学习资料。
-
• 玩转图表,生成数据可视化。
-
• 批量命名文件,实现自动化办公。
-
• 批量搞图,加水印、调尺寸。
-
• …
3、Python好学吗?
引用一句名言:种一棵树,最好的时间是十年前,其次是现在。
不管有没有开发经验,是否是计算机科班毕业,都不是影响你学习一门语言的门槛,相反,因为兴趣去学习,理解可能会更深。
4、Python常用场景
(1)爬取文档、学习资料
首先,需要明确爬取的内容是什么?比如爬图片、爬文件、爬资讯、爬新闻等。根据爬取的内容来确定最终爬取的内容是什么格式,比如我们这里,需要爬资讯,搜集指定网站的所有文章标题和链接,方便后续浏览。 那么,我们本次爬取的网站和目的就明确了:
网站:https://zkaoy.com/sions/exam 目的:收集文章标题和链接
那么,使用Python,可以参考以下两步的代码模板实现(在写Python代码前,别忘了安装Python运行环境和需要依赖的库:urllib3,bs4)
第一步,下载网页并保存为文件,代码如下:
import urllib3
# 第一个函数,用来下载网页,返回网页内容
# 参数 url 代表所要下载的网页网址。
def download_content(url):
http = urllib3.PoolManager()
response = http.request("GET", url)
response_data = response.data
html_content = response_data.decode()
return html_content
# 第二个函数,将字符串内容保存到文件中
# 第一个参数为所要保存的文件名,第二个参数为要保存的字符串内容的变量
def save_to_file(filename, content):
fo = open(filename,"w", encoding="utf-8")
fo.write(content)
fo.close()
# 下载报考指南的网页
url = "https://zkaoy.com/sions/exam"
result = download_content(url)
save_to_file("tips1.html", result)
第二步,解析网页,并提取出文章的链接和标题
from bs4 import BeautifulSoup
# 输入参数为要分析的 html 文件名,返回值为对应的 BeautifulSoup 对象
def create_doc_from_filename(filename):
fo = open(filename, "r", encoding='utf-8')
html_content = fo.read()
fo.close()
doc = BeautifulSoup(html_content)
return doc
doc = create_doc_from_filename("tips1.html")
post_list = doc.find_all("div",class_="post-info")
for post in post_list:
link = post.find_all("a")[1]
print(link.text.strip())
print(link["href"])
执行以上代码后,你就会发现网页中的标题和链接已经被打印到屏幕上了。
(2)抓取表格,做数据分析
我们日常在上网的时候,往往都会看到一些有用的表格,都希望保存下来日后使用,但直接复制到 Excel 往往都很容易发生变形,或者乱码,或者格式错乱等种种问题,借助 Python 可以轻松实现网页中表格的保存。(提示:需要先安装依赖: urllib3, pandas) 以招行外汇页面为例:地址:http://fx.cmbchina.com/Hq/ Python代码如下:
import urllib3
import pandas as pd
def download_content(url):
# 创建一个 PoolManager 对象,命名为 http
http = urllib3.PoolManager()
# 调用 http 对象的 request 方法,第一个参数传一个字符串 "GET"
# 第二个参数则是要下载的网址,也就是我们的 url 变量
# request 方法会返回一个 HTTPResponse 类的对象,我们命名为 response
response = http.request("GET", url)
# 获取 response 对象的 data 属性,存储在变量 response_data 中
response_data = response.data
# 调用 response_data 对象的 decode 方法,获得网页的内容,存储在 html_content
# 变量中
html_content = response_data.decode()
return html_content
html_content = download_content("http://fx.cmbchina.com/Hq/")
# 调用 read_html 函数,传入网页的内容,并将结果存储在 cmb_table_list 中
# read_html 函数返回的是一个 DataFrame 的list
cmb_table_list = pd.read_html(html_content)
# 通过打印每个 list 元素,确认我们所需要的是第二个,也就是下标 1
cmb_table_list[1].to_excel("tips2.xlsx")
执行之后,会在代码文件所在的目录生成 tips2.xlsx 的 excel 文件,打开之后即可查看数据。
(3)批量下载图片
当我们看到一个网页上有很多喜欢的图片时,一张一张保存效率比较低。
通过 Python 我们也可以实现快速的图片下载。以堆糖网为例,我们看到了这个网页。 地址:https://www.duitang.com/search/?kw=ins%E9%A3%8E%E8%83%8C%E6%99%AF%E5%9B%BE&type=feed 我们首先下载网页,然后分析其中的 img 标签,然后把图片下载下载来。首先我们在工作目录建立一个文件夹 tips_3 用来放下载的图片。
首先还是下载网页,Python 代码如下。
import urllib3
# 第一个函数,用来下载网页,返回网页内容
# 参数 url 代表所要下载的网页网址。
# 整体代码和之前类似
def download_content(url):
http = urllib3.PoolManager()
response = http.request("GET", url)
response_data = response.data
html_content = response_data.decode()
return html_content
# 第二个函数,将字符串内容保存到文件中
# 第一个参数为所要保存的文件名,第二个参数为要保存的字符串内容的变量
def save_to_file(filename, content):
fo = open(filename,"w", encoding="utf-8")
fo.write(content)
fo.close()
url = "https://www.duitang.com/search/?kw=ins%E9%A3%8E%E8%83%8C%E6%99%AF%E5%9B%BE&type=feed"
result = download_content(url)
save_to_file("tips3.html", result)
然后是抽取 img 标签,下载图片。
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
# 输入参数为要分析的 html 文件名,返回值为对应的 BeautifulSoup 对象
def create_doc_from_filename(filename):
fo = open(filename, "r", encoding='utf-8')
html_content = fo.read()
fo.close()
doc = BeautifulSoup(html_content)
return doc
doc = create_doc_from_filename("tips3.html")
images = doc.find_all("img")
for i in images:
src = i["src"]
filename = src.split("/")[-1]
# print(i["src"])
urlretrieve(src, "tips_3/" + filename)
执行完毕后打开 tips_3 目录,可以看到图片都被下载下来了。
(4)玩转图表,实现数据可视化
除了使用 Python 编写爬虫来下载资料, Python 在数据分析和可视化方面也非常强大。往往我们在工作中需要经常使用 Excel 来从表格生成曲线图,但步骤往往比较繁琐,而用 Python 则可以轻松实现。
1、从 csv 或 excel 提取数据来画图
本节需要先安装 pandas 、matplotlib、seaborn conda install pandas conda install matplotlib conda install seaborn
我们以刚才创建的 tips_2.xlsx 这个 excel 为例,来介绍我们如何把 Excel 表格中的数据画成图。
我们这次将 excel 中的卖出价一列,生成柱状图。
代码如下所示:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 使用 pandas 读取 excel, csv 文件的话换成 pd.read_csv 即可
df = pd.read_excel("tips2.xlsx")
# 因为第一行是中文表头,所以我们先过滤掉
df = df[df.index>0]
sns.set()
figure2 = plt.figure(figsize = (10, 5))
figure2.add_subplot(1,1,1)
# 设置轴的属性
plt.xlabel("",fontsize = 14)
plt.ylabel("卖出价", fontsize = 14)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.title("外汇情况", fontsize=14)
# 设置字体的属性
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
plt.rcParams["axes.unicode_minus"] = False
category = df[0]
index_category = np.arange(len(category))
# 将 卖出价 转换为数字
df[3] = pd.to_numeric(df[3])
plt.xticks(rotation = 90)
plt.bar(x=df[0], height=df[3].values, color=[1,0,1])
plt.show()
大家可以自行执行代码查看效果。
2、从文本文件中生成词云
需要先安装 wordcloud,jieba conda install -c conda-forge wordcloud conda install -c conda-forge jieba
词云是最近数据分析报告中非常常见的数据表现形式了,它会从一段文字中抽取出高频的词汇并且以图片的形式将它们展示出来。
如何用 Python 生成词云呢?为了做示范,我们首先解析第一步我们抓取的 tips_1.html 网页(考研网),将所有的新闻标题都存储到一个文本文档中。
from bs4 import BeautifulSoup
# 输入参数为要分析的 html 文件名,返回值为对应的 BeautifulSoup 对象
def create_doc_from_filename(filename):
fo = open(filename, "r", encoding='utf-8')
html_content = fo.read()
fo.close()
doc = BeautifulSoup(html_content)
return doc
doc = create_doc_from_filename("tips1.html")
post_list = doc.find_all("div",class_="post-info")
result = []
for post in post_list:
link = post.find_all("a")[1]
result.append(link.text.strip())
result_str="\n".join(result)
with open("news_title.txt", "w") as fo:
fo.write(result_str)
接下来我们将 news_title.txt 这个文本文件中的汉字进行分词,并生成词云。代码如下:
import jieba
import wordcloud
text = ""
with open ("news_title.txt", encoding="utf-8") as fo:
text = fo.read()
split_list = jieba.lcut(text)
final_text = " ".join(split_list)
stopwords= ["的", "是", "了"]
# Windows 系统的 font_path 替换为'C:\Windows\Fonts\STZHONGS.ttf'
wc = wordcloud.WordCloud(font_path = "/System/Library/Fonts/PingFang.ttc", width=1000, height=700, background_color="white",max_words=100,stopwords = stopwords)
wc.generate(final_text)
import matplotlib.pyplot as plt
plt.imshow(wc)
plt.axis("off")
plt.show()
如果你想生成自己的词云,首先你需要想清楚你的数据来源,一般是一个网页或者一个文本文件。
如果是网页的话可以首先保存到本地,提取文本,之后就可以进行代码替换来生成了。
(5)使用 Python 实现批量重命名文件
使用 Python 进行批量的文件重命名是比较简单的。比如我们要把一批图片导入到 PS 中编辑,或者导致一批视频文件到 PR 中操作,如果资源的文件名杂乱的话会严重影响效率。所以一般情况下我们都需要首先将相关的文件批量的按照某个规则重命名。
这里我们以前面爬虫示例的 3 小节中批量下载的图片文件夹为例,批量把该文件夹中的所有图片名字重命名为 “图片_0x.jpg ”的形式,其中 x 是图片的序号,逐一递增。 代码如下:
import os
root, dirs, files = next(os.walk("tips_3/"))
idx = 0
for item in files:
old_file_path = os.path.join(root,item)
new_file_path = os.path.join(root, f"图片_{idx}.jpg")
os.rename(old_file_path, new_file_path)
idx = idx + 1
执行过后,重新查看 tips_3 文件夹,可以看到下面的图片均已变成我们希望的格式。
(6)批量搞图,秀翻全场
1、批量给照片加水印
需要首先安装 opencv、pillow pip3 install opencv-python pip3 install pillow
如果手中有非常多的图片,想保护自己版权,或者申明来源,我们可以在图片上加水印。那如何用 Python 给非常多的图片批量加上文字水印呢?
还是以我们在爬虫示例的 3 小节中批量下载的图片文件夹为例。
下述代码会给该文件夹下所有图片的(100,100) 这个坐标点加上“文字水印”这四个中文。坐标点是以图片左上角为基准的。如果图片的宽高小于 100,则不会打上水印。
# -*- coding: utf-8 -*-
import cv2
import numpy
from PIL import Image, ImageDraw, ImageFont
import os
def process_file(file_path,output_dir):
img = cv2.imread(file_path)
if (isinstance(img, numpy.ndarray)):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
# 字体的格式
textSize = 50
# Windows 系统的 font_path 替换为'C:\Windows\Fonts\STZHONGS.ttf'
fontStyle = ImageFont.truetype(
"/System/Library/Fonts/PingFang.ttc", textSize, encoding="utf-8")
# 绘制文本
left = 100
top = 100
text = '文字水印'
textColor = (168, 121, 103)
draw.text((left, top), text, textColor, font=fontStyle)
# 转换回OpenCV类型
img2 = cv2.cvtColor(numpy.asarray(img), cv2.COLOR_RGB2BGR)
# 保存图片
file_name = file_path.split("/")[-1]
cv2.imwrite(os.path.join(output_dir, file_name), img2)
print(f"proceed {file_path}")
root, dirs, files = next(os.walk("tips_3/"))
for item in files:
file_path = os.path.join(root,item)
process_file(file_path, "tips_3_watermark")
代码执行完后,可以去 tips_3_watermark 这个文件夹中查看图片,可以看到这里的所有图片都已经被打上了文字水印。
2、批量给照片调整饱和度
我们在生活中有经常需要给照片、图片调色的场景,虽然用 PS 可以很方便地完成,但是一张照片一张照片的处理还是比较麻烦。
使用 Python 我们可以非常方便的批量地对照片调整饱和度。
这一节我们还是以前面 03 节批量下载的图片目录为例,给所有照片的饱和度升高为 1.5 倍。
我们首先建立 tips_3_sa 文件夹,用来存放处理过的图片,之后输入代码:
import cv2
import numpy as np
import os
def process_image(file_path, target_dir):
pic = cv2.imread(file_path, cv2.IMREAD_UNCHANGED)
pic1 = cv2.cvtColor(pic, cv2.COLOR_BGR2HSV)
H,S,V = cv2.split(pic1)
new_pic = cv2.merge([np.uint8(H ), np.uint8(S * 1.5), np.uint8(V)])
pic2 = cv2.cvtColor(new_pic, cv2.COLOR_HSV2BGR)
file_name = file_path.split("/")[-1]
cv2.imwrite(os.path.join(target_dir, file_name), pic2)
root, dirs, files = next(os.walk("tips_3/"))
for item in files:
file_path = os.path.join(root,item)
process_image(file_path, "tips_3_sa")
3、批量调整照片尺寸
除了调整饱和度外,批量调整照片尺寸也是非常常见的需求。我们继续以 tips_3 文件夹中的图片为例,来批量将所有图片缩写为之前的1/2, 然后存储在 tips_3_resize 目录中。
首先需要在我们的工作目录中建立 tips_3_resize 目录,之后输入如下代码:
import cv2
import numpy as np
import os
def process_image(file_path, target_dir):
pic = cv2.imread(file_path, cv2.IMREAD_UNCHANGED)
x,y = pic.shape[0:2]
pic1 = cv2.resize(pic, (int(y/2), int(x/2)))
file_name = file_path.split("/")[-1]
cv2.imwrite(os.path.join(target_dir, file_name), pic1)
root, dirs, files = next(os.walk("tips_3/"))
for item in files:
file_path = os.path.join(root,item)
process_image(file_path, "tips_3_resize")
学习资源推荐
除了上述分享,如果你也喜欢编程,想通过学习Python获取更高薪资,这里给大家分享一份Python学习资料。
这里给大家展示一下我进的兼职群和最近接单的截图
😝朋友们如果有需要的话,可以点击下方链接领取或者V扫描下方二维码联系领取,也可以内推兼职群哦~
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!

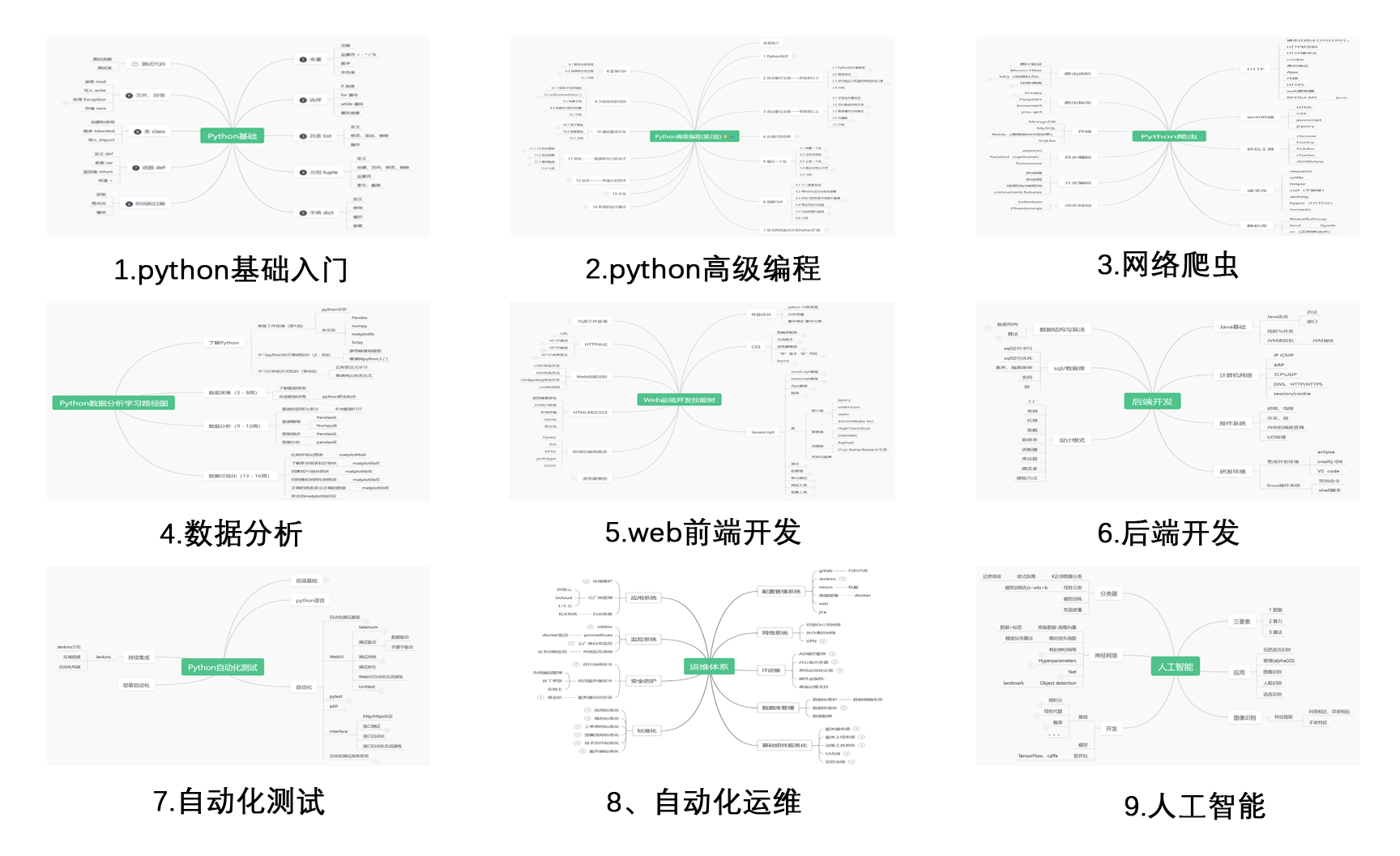
1.Python学习路线

2.Python基础学习
01.开发工具

02.学习笔记
03.学习视频
3.Python小白必备手册

4.数据分析全套资源

5.Python面试集锦
01.面试资料
02.简历模板















 314
314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









