







python遍历文件夹
假设:当前目录下有一个test文件夹,test的目录结构如下所示。
test
|
|--1级文件夹1
| |
| |--2级文件夹1
| | |
| | |--e.txt
| |
| |--c.txt
|
|--1级文件夹2
| |
| |--2级文件夹2
| | |
| | |--f.txt
| |
| |--d.txt
|
|--a.txt
|
|--b.txt现在我们编写python代码来遍历test文件夹,你可以在你的文件夹中创建上面的test文件夹。
使用递归函数遍历文件夹
我们可以借助os库中的一些函数来写一个递归函数,可以实现遍历文件夹。
os.listdir()
os库中的listdir()函数可以接收一个文件路径,它会输出这个文件下的目录列表。
import os
cat_log = os.listdir('./test')
print(cat_log)执行结果如下:

listdir()函数把test文件夹下的两个文件夹和两个文件放到了一个列表中。
os.path.isdir()
os.path.isdir()可以接收一个文件路径,它能判断这个文件是否是文件夹。
import os
print(os.path.isdir('./test')) # True文件test是文件夹,所以os.path.isdir()函数返回了True。
组合上面两个函数
我们可以利用上面两个函数编写出一个遍历文件夹的递归函数。
import os
def ergodic_dir(path: str):
"""
遍历文件
:param path: 文件路径
:return:
"""
if os.path.isdir(path): # 判断当前文件是否为文件夹
for i in os.listdir(path): # 循环输出当前文件的子级文件名称
ergodic_dir(f'{path}/{i}') # 使用递归方式遍历当前文件的子级文件
else: # 当前文件不是文件夹时
print(path) # 打印出文件路径
ergodic_dir('./test')执行结果如下:
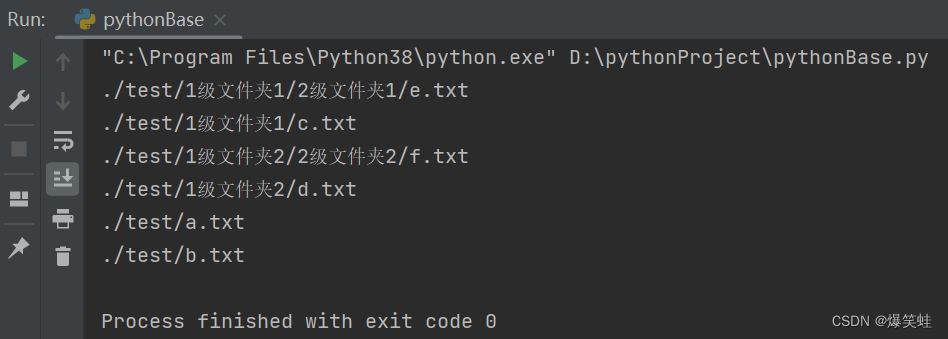
递归文件的逻辑如下图所示:
使用os.walk()遍历文件夹
os库中的walk函数可以遍历文件,我们只需给walk函数传递一个文件夹路径,它就能遍历这个文件夹,输出这个文件夹下的所有文件夹和文件。walk函数是一个生成器,我们可以使用next函数调用它,也可以使用for循环调用它(for循环就是通过不断使用next函数实现的)。
我们先尝试使用next函数一次一次的去遍历,因为walk每次返回3个值(当前文件、子文件夹列表、子文件列表),我们需要用3个变量来接收返回值。
import os
my_dir = os.walk(r'.\test')
top, dirs, files = next(my_dir)
print(f'当前文件: {top}')
print(f'子文件夹: {dirs}')
print(f'子文件: {files}')
top, dirs, files = next(my_dir)
print(f'当前文件: {top}')
print(f'子文件夹: {dirs}')
print(f'子文件: {files}')
top, dirs, files = next(my_dir)
print(f'当前文件: {top}')
print(f'子文件夹: {dirs}')
print(f'子文件: {files}')执行结果如下:
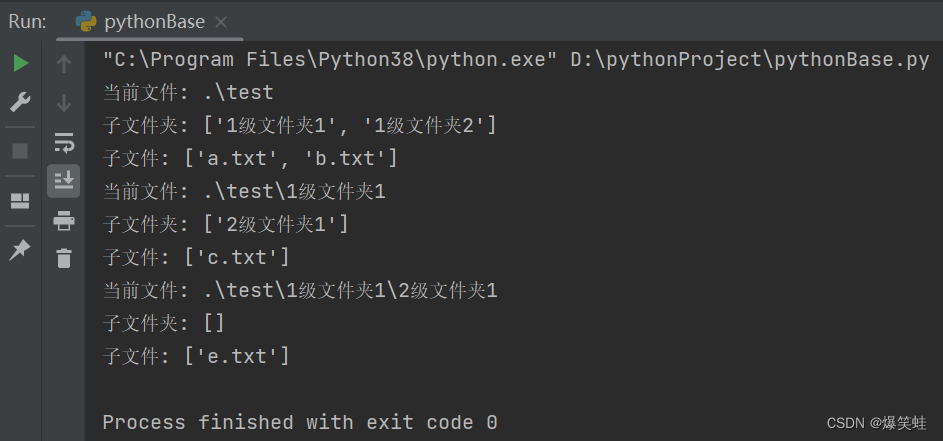
从执行结果中可以看出walk函数遍历文件夹的方式,跟我们上面写的递归函数一样。都是以深度优先,每一次都从第一个文件开始,直到第一个文件是文件时才返回到上一层,继续遍历第二个文件。
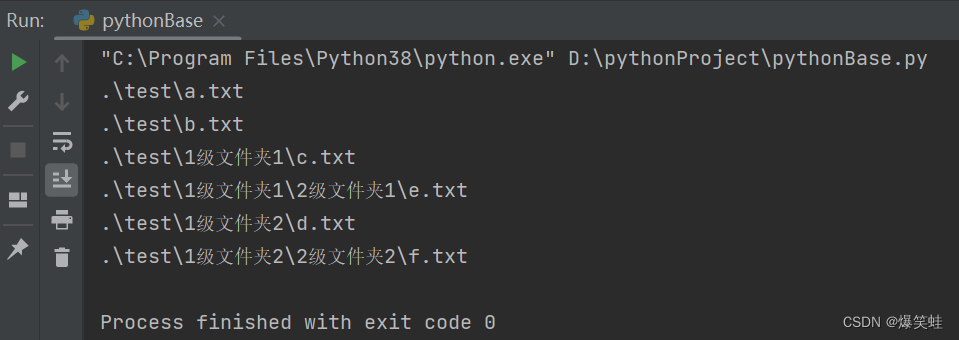
使用嵌套for循环可以轻松遍历文件夹。
import os
for top, dirs, files in os.walk(r'.\test'):
for i in files:
print(f'{top}\{i}')
执行结果如下:
python获取当前路径
os库中的getcwd函数可以输出当前py文件在计算机中所处的绝对路径。使用方式如下:
import os
path = os.getcwd()
print(path)父级路径
os库中的path模块的dirname函数可以获取某个文件的父级文件夹路径。使用方式如下:
import os
path = os.getcwd()
print(path) # 打印当前路径
parent = os.path.dirname(path)
print(parent) # 打印当前文件的父级路径python复制文件
shutil库中的copy函数可以复制文件,copy函数接收两个参数,第一个参数为原文件路径,第二个参数为复制文件的存放路径。使用方式如下:
import shutil
shutil.copy('abc.txt', '/test')通过上面的代码,我们就能把当前目录下的abc.txt文件复制到当前目录下的test文件夹中。跟遍历文件夹相结合就可以批量复制某种文件。
python删除文件
os库中的remove函数可以删除文件,remove函数可以接收两个参数,第一个参数为要删除文件的路径(只能是文件,不能是文件夹),第二个参数为文件描述符必须用关键字dir_fd传参(我们一般不传文件描述符)。
import os
os.remove('/test/abc.txt')通过上面的代码,我们就可以把当前目录下test文件夹中的abc.txt文件删除掉。跟遍历文件相结合就可以批量删除某种文件。
python读写文件
python的内置函数open可以读写文件。
参数介绍
open函数可以接收以下几个参数:
def open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True):除了file是必传的参数外,其他的缺省参数都可以不传值。
file
file参数我们一般传入文件路径,例如:在D盘的test文件夹中有一个test.txt文件,test.txt文件中的内容为hello world,我们可以使用open函数读出test.txt的内容。
file = open(r'D:\test\test.txt')
print(file.read()) # hello world
file.close()mode
mode参数的默认值是'r',我们可以给mode参数传入以下几个值:
| r | 只能读取文件中的内容 |
| w | 只能向文件中写入内容,而且是以覆盖的方式写入内容(写入内容时,光标置于文件开头,如果文件中本来就有内容,原来的部分会被现在写入的内容替换掉),如果文件不存在时会自动创建该文件再写入内容。 |
| a | 只能向文件中写入内容,是以追加的方式写入内容(写入内容时,光标置于文件末尾,如果文件中本来就有内容,会在原来的部分后面新增内容),如果文件不存在时会自动创建该文件再写入内容。 |
| rb | 只能读取文件中的内容,并且以2进制的方式读取文件中的内容,可以读取2进制文件(例如读取C++的编译文件、图片文件等) |
| wb | 只能向文件中写入内容,以2进制的方式写入内容,并覆盖原来的内容(写入内容时,光标置于文件开头,如果文件中本来就有内容,原来的部分会被现在写入的内容替换掉),如果文件不存在时会自动创建该文件再写入内容,可以写2进制文件(例如生成图片文件等) |
| ab | 只能向文件中写入内容,以2进制的方式写入内容,并在原来的内容后追加内容(写入内容时,光标置于文件末尾,如果文件中本来就有内容,会在原来的部分后面新增内容),如果文件不存在时会自动创建该文件再写入内容,可以写2进制文件(例如生成图片文件、修改图片文件等) |
| r+ | 既能读取文件中的内容,也能向文件中写入内容,是以覆盖的方式写入内容(写入内容时,光标置于文件开头,如果文件中本来就有内容,原来的部分会被现在写入的内容替换掉) |
| w+ | 既能读取文件中的内容,也能向文件中写入内容,是以覆盖的方式写入内容(写入内容时,光标置于文件开头,如果文件中本来就有内容,原来的部分会被现在写入的内容替换掉),如果文件不存在时会自动创建该文件再写入内容。 |
| a+ | 既能读取文件中的内容,也能向文件中写入内容,是以追加的方式写入内容(写入内容时,光标置于文件末尾,如果文件中本来就有内容,会在原来的部分后面新增内容),如果文件不存在时会自动创建该文件再写入内容。 |
| rb+ | 既能读取文件中的内容,也能向文件中写入内容,以2进制的方式读取文件中的内容,可以读取2进制文件(例如读取C++的编译文件、图片文件等)。以2进制的方式写入内容,并覆盖原来的内容(写入内容时,光标置于文件开头,如果文件中本来就有内容,原来的部分会被现在写入的内容替换掉),可以修改2进制文件(例如修改图片文件等) |
| wb+ | 既能读取文件中的内容,也能向文件中写入内容,以2进制的方式读取文件中的内容,可以读取2进制文件(例如读取C++的编译文件、图片文件等)。以2进制的方式写入内容,并覆盖原来的内容(写入内容时,光标置于文件开头,如果文件中本来就有内容,原来的部分会被现在写入的内容替换掉),如果文件不存在时会自动创建该文件再写入内容,可以写2进制文件(例如生成图片文件等) |
| ab+ | 既能读取文件中的内容,也能向文件中写入内容,以2进制的方式读取文件中的内容,可以读取2进制文件(例如读取C++的编译文件、图片文件等)。以2进制的方式写入内容,并在原来的内容后追加内容(写入内容时,光标置于文件末尾,如果文件中本来就有内容,会在原来的部分后面新增内容),如果文件不存在时会自动创建该文件再写入内容,可以写2进制文件(例如生成图片文件、修改图片文件等) |
我们不难发现,r表示读、w表示写、a表示追加,当它们遇到b的时候就变成了2进制文件的读、写和追加,当它们遇到+的时候就变成了可读、可写(r+不能创建新文件),当它们遇到b+的时候就变成了2进制文件的可读、可写(rb+不能创建新文件)。
buffering
buffering参数是用来设置缓冲区的,当快速读写大量数据时,可能磁盘反应不及时,会有数据溢出(内存的读写速度大于磁盘,跟它们各自存放数据的结构有关)。这时就需要一个缓冲区来控制每次写入数据的大小,先把数据放到缓冲区,缓冲区满了再进行读写操作,防止内存和磁盘读写速度不一致造成数据丢失。buffering默认值为-1,表示使用系统默认的缓冲区;buffering为0时,表示不缓冲;buffering为1时,表示行缓冲只能缓存1行数据,遇到换行符就必须把数据写入磁盘后才能再次缓存;buffering大于1时,表示缓冲区的大小,以字节为单位,buffering=1000就表示1000Byte大小的缓冲区。我们一般不需要设置缓冲区,用系统默认的缓冲区就行了。
encoding
encoding参数是用来设置文件编码的,字符的编码库有很多,例如:ansi、ucs-2、utf-8、gbk等等,我们常用的就是uif-8(万国码)。如果这个文件的编码是gbk,那我们就要使用gbk来解码,如果使用utf-8来解码就会出现中文乱码的现象。
errors
errors参数用来设置编码或解码过程中报错的处理方式,默认值为strict表示遇到不能编码或解码的字符,抛出错误终止程序;如果想忽略编码解码错误,设置errors='ignore',这样做可能会导致文件中出现数据缺失。如果想替换掉不能编码或解码的字符,设置errors='replace',会使用?替换掉不能编码或解码的字符。
newline
newline参数用来规定换行符,因为不同操作系统上使用的换行符不同,Windows使用的换行符为'\r\n',Linux使用的换行符为'\n',苹果使用的换行符为'\r'。我们在不同的操作系统上就设置不同的操作符,以免读写文件的时候换行失败。我们可以不用管它,直接使用默认值None,写入内容时会采用通用的新换行模式,读取文件时会使用操作系统默认的换行符。
closefd
closefd参数用来控制file参数的传值类型,file其实可以接收两种类型的参数,一种是字符串类型的文件路径,另一种是整型的文件描述符。当closefd为True时,file只能接收字符串;当closefd为False时,file只能接收整型。closefd默认为True,所以我们不用管closefd参数。
方法介绍
假设当前文件夹中有一个test.txt文件,test.txt文件内容如下:
test.txt
hello world
你好,世界
爆笑蛙你可以在你的文件夹下真正的创建这样一个文件,来学习下面的代码。
readable()
readable()方法可以判断当前文件对象是否可读取数据,mode是'r'或者含有'+'都是可读取数据的。使用方式如下:
file = open('./test.txt', 'r')
print(file.readable()) # True
file.close()
file = open('./test.txt', 'w')
print(file.readable()) # False
file.close()read()
read()方法可以读取文件内容,read()可以接收一个整型参数,可以设置读取多少个字节的数据,默认值为-1,表示读取所有的内容。使用方式如下:
file = open('./test.txt')
print(file.read()) # hello world
print(file.read(2)) # he
file.close()readline()
readline()方法可以读取一行内容,连续使用readline()可以读取多行内容。readline()可以接收一个整型参数,可以设置读取多少个字节的数据,默认值为-1,表示读取一个完整的行。使用方式如下:
file = open('./test.txt', 'r')
print(file.readline()) # hello world
print(file.readline(2)) # 你好
file.close()readlines()
readlines()方法可以读取文件中所有内容,并按行把内容拆分成多个元素放入一个列表中,最后返回这个列表。readlines()可以接收一个整型参数,可以设置读取多少个字节的数据,默认值为-1,表示读取所有内容。使用方式如下:
file = open('./test.txt', 'r')
print(file.readlines(15)) # ['hello world\n', '你好,世界\n']
file.close()
file = open('./test.txt', 'r')
print(file.readlines()) # ['hello world\n', '你好,世界\n', '爆笑蛙']
file.close()writable()
writable()方法可以判断当前文件对象是否可以写入数据,mode是'w'、'a'或者含有'+'都是可写入数据的。使用方式如下:
file = open('./test.txt', 'w')
print(file.writable()) # True
file.close()
file = open('./test.txt', 'r')
print(file.writable()) # False
file.close()write()
write()方法可以向文件中写入内容,write()可以接收一个字符串,字符串就是要写入文件的内容。使用方式如下:
file = open('./test.txt', 'w', encoding='utf-8')
file.write('鱼有水自生,人有炁长存')
file.close()注意我把'r'变成了'w',你用'r+'也可以,因为test.txt文件本来就存在。我们再去看test.txt文件,是不是就变成下面这样了:
test.txt
鱼有水自生,人有炁长存writelines()
writelines()方法可以向文件中写入内容,writelines()接收一个可迭代对象,它会把可迭代对象中所有的元素连续写入文件中。使用方式如下:
str_list = ['hello world\n', '你好,世界\n', '爆笑蛙']
file = open('./test.txt', 'w', encoding='utf-8')
file.writelines(str_list)
file.close()我们再去看test.txt文件,是不是就变成下面这样了:
test.txt
hello world
你好,世界
爆笑蛙我们可以看出writelines()和readlines()就是一个相反的过程。
close()
close()方法可以释放文件对象,关闭文件。为了防止文件数据不会出错和及时释放文件对象,请在操作完文件后使用close()方法。使用方式就不介绍了,上面都使用过好多次了。
with open
如果你会忘记使用close()方法,那么请使用with(上下文管理)。with中会有一个生命周期过程,从打开到关闭。代码执行到with之外时,with会自动关闭打开的对象。使用方式如下:
with open('./test.txt', 'r', encoding='utf-8') as file:
print(file.readlines()) # ['hello world\n', '你好,世界\n', '爆笑蛙']如此一来我们就能省略close()方法了。
python读写json
python中的json库可以实现对json文件的操作,json模块提供了load()、loads()、dump()、dumps()4个方法。loads()和dumps()用于python数据和json数据的相互转换(主要是列表和字典),load()和dump()用于json文件的读写操作(需要和上面的open函数结合)。
dumps()
dumps()方法可以把python中的字典或列表数据变成json数据,使用方式如下:
data_dict = {'novel': ['斗破苍穹', '遮天', '仙逆'], "class": [1, 2, 3]}
data_json = json.dumps(data_dict)
print(data_json) # {"novel": ["\u6597\u7834\u82cd\u7a79", "\u906e\u5929", "\u4ed9\u9006"], "class": [1, 2, 3]}我们可以看到里面的中文已经全部被转码了,字典data_dict已被dumps转换为了json数据了。一般我们用不到它,在Django这种web框架中用得多。
loads()
loads()方法可以把json数据变成python中的字典或列表数据,使用方式如下:
data_dict = {'novel': ['斗破苍穹', '遮天', '仙逆'], "class": [1, 2, 3]}
data_json = json.dumps(data_dict)
print(data_json) # {"novel": ["\u6597\u7834\u82cd\u7a79", "\u906e\u5929", "\u4ed9\u9006"], "class": [1, 2, 3]}
data_python = json.loads(data_json)
print(data_python) # {'novel': ['斗破苍穹', '遮天', '仙逆'], 'class': [1, 2, 3]}我们可以看到json数据又被loads转换成了python中的字典了。
dump()
def dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False, **kw):dump()方法可以把python中的字典或列表数据写入json文件中,dump中有很多个形参,我们主要关注obj、fp、ensure_ascii、indent这几个参数。其中obj是我们要传入的字典或列表;fp是文件对象(用open函数打开的文件);ensure_ascii为True时只能保证ASCⅡ码中的字符不会被转码,ensure_ascii为False时所有的字符都不会被转码;indent可以设置json文件的格式,例如indent=4时json中的内容会变得有层次结构,每一级之间会缩进4个字符。使用方式如下:
data_dict = {'novel': ['斗破苍穹', '遮天', '仙逆'], "class": [1, 2, 3]}
with open('./test.json', 'w', encoding='utf-8') as f:
json.dump(data_dict, f, ensure_ascii=False, indent=4)执行上面的代码,我们将在当前文件夹下得到一个test.json文件,test.json文件中的内容如下:
test.json
{
"novel": [
"斗破苍穹",
"遮天",
"仙逆"
],
"class": [
1,
2,
3
]
}是不是很有层次感,如果不设置indent参数,就会写成一行。如果不设置ensure_ascii=False,中文就会被转码。
load()
load()方法可以把json文件中的数据读取出来,变成python中的数据(字典或列表)。使用方式如下:
import json
with open('./test.json', 'r', encoding='utf-8') as f:
python_dict = json.load(f)
print(f'python_dict type is {type(python_dict)}')
print(python_dict)执行结果如下:
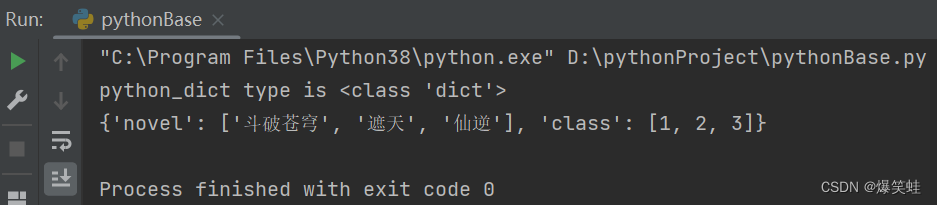
从执行结果中我们可以看到python_dict是字典类型的数据,打印出来也是一个字典。以上就是python操作json文件的方法,我们如果想把一些代码中的配置内容放到json文件中,并实现对配置内容的动态修改,使用这些方法就可以轻松做到了。
python时间计算
在python代码中我们想要获得当前时间、打印当前时间、计算时间差以及得到一段时间后的时间点,我们可以使用time库和datetime库就能轻松做到。
获得当前时间
使用time库中的time()函数可以获得当前时间的时间戳。
import time
print(time.time())执行结果如下:

使用datetime库中的datetime类的now()方法可以获得当前时间的时间戳,datetime是对time做了封装,我们可以得到一个格式化(人性化)的时间戳。
import datetime
print(datetime.datetime.now())执行结果如下:

打印当前时间
使用time库中的strftime()函数可以格式化输出当前时间字符串。我们可以给它指定要输出的时间格式,%Y给年占位、%m给月占位、%d给日占位、%H给时占位、%M给分占位、%S给秒占位,在这些占位符之间我们可以插入任意的字符串,以达到输出我们想要的时间格式。
import time
print(time.strftime('%Y-%m-%d %H:%M:%S'))
print(time.strftime('%Y年%m月%d日%H时%M分%S秒'))执行结果如下:
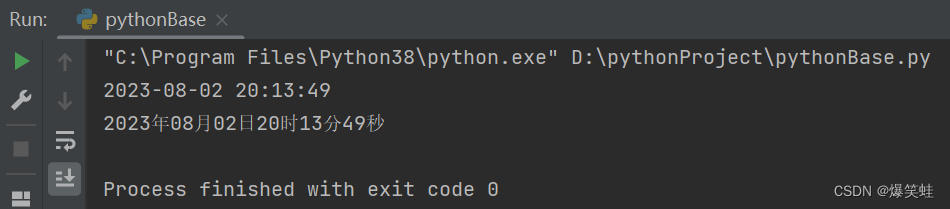
datetime库中的datetime类的strftime()方法可以格式化输出时间字符串,因为strftime()是实例方法,所以我们需要先得到datetime类的实例,才能使用strftime()方法。
import datetime
last = datetime.datetime(2023, 1, 1, 1, 1, 1)
print(last.strftime('%Y-%m-%d %H:%M:%S'))执行结果如下:

计算时间差
使用datetime库中的datetime可以计算时间差。我们只需实例化两个datetime类型对象出来,就可以对它们进行计算。datetime中的now()方法也是返回datetime的实例对象。两个datetime对象相减后会得到一个timedelta类型的对象,timedelta的days属性为两个datetime对象相差的天数,timedelta的seconds属性为两个datetime对象相差的秒数,timedelta的microseconds属性为两个datetime对象相差的微秒数。timedelta的total_seconds()方法可以得到两个datetime对象相差总的秒数。
import datetime
last = datetime.datetime(2023, 1, 1, 1, 1, 1)
now = datetime.datetime.now()
interval = now - last
print(interval) # 总间隔时间
print(interval.days) # 间隔天数
print(interval.seconds) # 间隔秒数
print(interval.microseconds) # 间隔微秒数
print(interval.total_seconds()) # 总的间隔秒数执行结果如下:
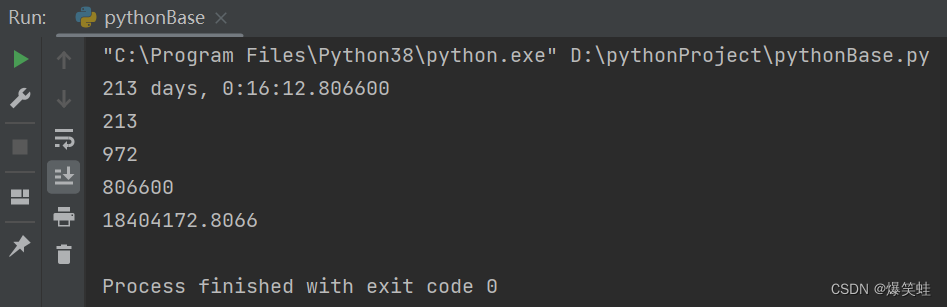
时间增减计算
datetime库中的timedelta类可以增减datetime对象,从而得到datetime对象在一段时间(几天、几小时、几分钟、几秒钟)前或后的时间点,也是一个datetime对象。
得到当前时间两天后的时间。
import datetime
now = datetime.datetime.now()
after = now + datetime.timedelta(days=2)
print(f'当前时间: {now}')
print(f'两天后的时间: {after}')执行结果如下:
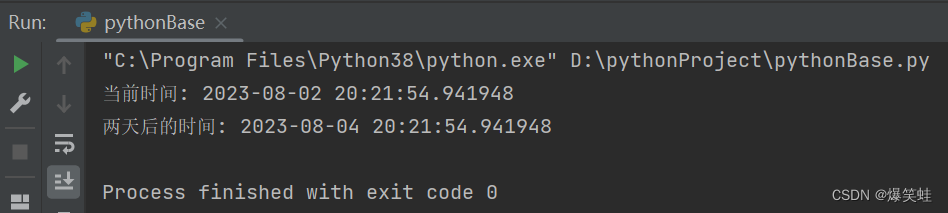
得到当前时间两小时后的时间。
import datetime
now = datetime.datetime.now()
after = now + datetime.timedelta(hours=2)
print(f'当前时间: {now}')
print(f'两小时后的时间: {after}')执行结果如下:

得到当前时间两分钟后的时间。
import datetime
now = datetime.datetime.now()
after = now + datetime.timedelta(minutes=2)
print(f'当前时间: {now}')
print(f'两分钟后的时间: {after}')执行结果如下:
得到当前时间两秒钟后的时间。
import datetime
now = datetime.datetime.now()
after = now + datetime.timedelta(seconds=2)
print(f'当前时间: {now}')
print(f'两秒钟后的时间: {after}')执行结果如下:
如果想得到当前时间之前的时间,请把加法变成减法,我就不举例了。
比较时间的大小
两个datetime对象可以比较大小。
import datetime
time1 = datetime.datetime(2023, 1, 1)
time2 = datetime.datetime(2023, 1, 2)
print(time1 < time2) # True
now = datetime.datetime.now()
after = now + datetime.timedelta(seconds=2)
print(after > now) # True利用上面这些方法,我们就可以在代码中获取时间、计算时间、比较时间、输出时间了。
python执行终端指令
在python中我们可以执行终端指令并得到执行指令后的输出内容,可以使用的库有os和subprocess。(例如:Linux上的ls指令查看文件,Windows上的tasklist指令查看正在运行的进程)
os.system()
os库中的system()方法可以执行终端指令,但不返回执行指令后的输出内容。system()方法只接收一个参数,我们通常传入一个指令字符串,它就可以帮我们在终端执行字符串中的指令。
import os
os.system('touch test.txt') # 在当前目录下创建一个test.txt文件system()方法虽然能执行终端指令,但由于不会返回执行指令后的输出内容,想执行ls查看文件时就没办法看到文件。所以system()方法只能用来执行一些不需要关注返回信息的指令。
os.popen()
os库中的popen()方法可以执行终端指令,并返回执行指令后的输出内容。其实popen()是对subprocess库中Popen()方法的封装,我们给popen()传入一个指令字符串,它就可以帮我们在终端执行字符串中的指令,并把执行指令后的输出内容读取出来(需要使用read()方法或readlines()方法)。
import os
result = os.popen('echo hello world').read()
print(result) # hello world
result = os.popen('ls /home/desktop').readlines()
print(result) # ['AndroidStudio\n', 'Document\n', 'Pycharm\n']我们可以看到read()方法是读取所有内容,readlines()方法是把每一行作为一个元素放到列表中。
subprocess.Popen()
subprocess库中的Popen类是专门用来执行终端指令的,通过创建一个子进程来执行终端指令。
参数
def __init__(self, args, bufsize=-1, executable=None,
stdin=None, stdout=None, stderr=None,
preexec_fn=None, close_fds=True,
shell=False, cwd=None, env=None, universal_newlines=None,
startupinfo=None, creationflags=0,
restore_signals=True, start_new_session=False,
pass_fds=(), *, encoding=None, errors=None, text=None):Popen的参数很多,但我们不需要关注太多的参数,我们只需要注意下面几个参数即可:
args为我们要执行的指令
stdin为额外指令输入管道(可选值有:PIPE = -1、DEVNULL = -3)
stdout为执行指令后的内容输出管道(可选值有:PIPE = -1、STDOUT = -2、DEVNULL = -3)
stderr为执行指令发生错误的输出管道(可选值有:PIPE = -1、STDOUT = -2、DEVNULL = -3)
PIPE(用-1也行)为标准通信流,设置后可以实时与管道交互(传入数据或者获取数据);STDOUT(用-2也行)为标准输出流,设置后可以得到标准的输出数据;DEVNULL(用-3也行)为None,设置后什么也不能做什么也得不到。
shell为以shell指令的方式执行指令(bool值:True or False),为True时args接收字符串,为False时args接收字符串列表(使用一串连续指令时)。
encoding为设置输入指令和输出结果的编码方式(utf-8、gbk....)
通过这几个参数,我们已经能创建一个执行终端指令的子进程了。我们还需要一些方法来使用这个子进程,从而执行指令和获取输出。
方法和属性
poll()
poll()方法用来查看子进程是否结束,结束返回0,没结束返回None,返回其他值为执行出错。
wait()
wait()方法用来等待指令执行结束,指令执行结束后我们才能获取输出内容。
terminate()
terminate()方法用来结束子进程。
kill()
kill()方法用来强行杀死子进程。
stdin
stdin属性,当形参stdin=subprocess.PIPE(或-1)时,stdin为一个文件对象(跟open函数打开的文件对象一样)。拥有open函数中的方法,比如read、write、close等。
stdout
stdout属性,当形参stdout=subprocess.PIPE(或-1)时,stdout为一个文件对象(跟open函数打开的文件对象一样)。拥有open函数中的方法,比如read、write、close等。
stderr
stderr属性,当形参stderr=subprocess.PIPE(或-1)时,stderr为一个文件对象(跟open函数打开的文件对象一样)。拥有open函数中的方法,比如read、write、close等。
pid
得到当前子进程PID。
使用方式
结合上面的参数、方法和属性,我们就能灵活的使用subprocess.Popen执行终端指令了。
我们先来个最简单的操作,只执行一条指令,并打印输出结果。
cmd = r'ls /home/desktop' # 定义终端指令
process = subprocess.Popen(cmd, shell=True, stdout=-1, stderr=-2, stdin=-3,
encoding='utf-8') # 执行指令
process.wait() # 等待指令执行结束
result = process.stdout.read() # 读取输出结果
process.stdout.close() # 关闭stdout文件对象(标准输出管道)
print(process.poll()) # 打印子进程状态(0为结束状态)
print(result) # 打印输出结果形参shell=True,因为我们执行字符串指令;形参stdout=-1,因为我们要得到一个文件对象,方便我们主动从中读取标准输出信息(用指定的变量接收);形参stderr=-2,因为我们只需要错误信息自动输出,不用主动获取(直接输出到python执行终端);形参stdin=-3,因为我们不执行其他指令,所以把它设置为空;形参encoding='utf-8',把编码设置为utf-8防止中文乱码,防止出现中文路径执行失败的问题。
下面上点难度,一次性执行多条连续指令。
cmd = [r'cd /home/desktop', 'ls'] # 定义终端指令
process = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT,
stdin=subprocess.DEVNULL, encoding='utf-8') # 执行指令
process.wait() # 等待指令执行结束
result = process.stdout.read() # 读取输出结果
process.stdout.close() # 关闭stdout文件对象(标准输出管道)
print(process.poll()) # 打印子进程状态(0为结束状态)
print(result) # 打印输出结果当形参shell=False时,我们可以用字符串列表连续执行多条指令。
继续上难度,执行不会主动结束的指令。例如adb shell这种指令,进入手机的终端界面后,如果我们不手动按Ctrl+c或者执行exit指令,将一直在手机终端界面。这种情况下,Popen一直不会结束。我们可以连续在手机终端执行指令,直到我们输入exit指令或者杀掉子进程。
cmd = 'adb shell' # 定义终端指令
process = subprocess.Popen(cmd, shell=True, stdout=-1, stderr=-2, stdin=-1,
encoding='utf-8') # 执行指令
time.sleep(1) # 延时1秒执行后面的代码,让指令执行完成
process.stdin.write('ls /sdcard\n') # 使用stdin文件对象执行ls指令,一定要加\n代替按回车
time.sleep(1) # 延时1秒执行后面的代码,让指令执行完成
process.stdin.write('exit\n') # 使用stdin文件对象执行exit指令,一定要加\n代替按回车
time.sleep(1) # 延时1秒执行后面的代码,让指令执行完成
process.stdin.close() # 关闭stdin文件对象(标准输入管道)
result = process.stdout.read() # 获取输出结果
process.stdout.close() # 关闭stdout文件对象(标准输出管道)
print(process.poll()) # 打印子进程状态
print(result) # 打印输出结果在这种不会主动结束的指令中,我们就不能再使用wait()方法来等待指令结束了,因为指令不会结束wait就一直等待,会卡在等待的地方不能向下执行代码了。所以我们用time中的sleep方法来代替wait方法,但我们需要预估一下执行指令结束需要的时间。使用stdin文件对象,我们就可以想执行多少指令就执行多少指令(注意指令后要加\n代替手动按回车),相当于自己开了一个终端窗口,通过这种方式我们可以在一些UI框架中制作一个模拟终端。
如果我们想从终端实时获取一些日志信息,可以一行一行的输出stdin文件对象中的信息。就相当于终端在stdin文件对象中写一行,我们就去读一行。
cmd = 'adb shell logcat' # 定义终端指令
process = subprocess.Popen(cmd, stdout=-1, stderr=-2, stdin=-3,
encoding='utf-8') # 执行指令
number = 0
while number < 10:
line = process.stdout.readline() # 读取一行输出结果
print(line) # 打印一行输出结果
number += 1
process.stdout.close() # 关闭stdout文件对象(标准输出管道)
process.terminate() # 结束子进程通过上面的代码,我们可以连续读取10行手机的日志信息。















 443
443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









