






前言
好久不见,我又回来了。前段时间因为学业和实习的事情,耽误了很久没有时间更新,但是我并没有闲着我一直在努力学习大模型的各种知识,对我来说感触最深的就是两个,一个是大概半个月前在一个讲定制企业私有化AI大模型的视频里,这里他说到‘AI是电,以前有了电后出现了空调;AI出现后,未来会出现类似于空调的AI agent’这是他的原话,我觉得他空调这个比喻不太符合,但是这个事确实是这样子的,就是ChatGPT的插件以后大量开发之后的世界那样,我只需要通过他我就可以链接一切需求,甚至我们大胆想的话,我们不仅不用那么多的APP甚至可以不用手机。第二个感触比较深的是昨天晚上看到一个视频是财经大佬的圆桌会吧类似于,里面我们中国国际经济交流中心副理事长朱民先生说2025年中国将成为数据最大国,并且他预测10年后个人ChatGPT将普及。这也更让我深信应该走数据这条路并丰富自己的大模型这方面的能力。
OK,废话就扯这么多,下面开始干货部分,以下的所有内容都是以我个人的视角看到的学习到的东西,可能有更好的方法或者途径这些就留给大家去实践了。
ChatGPT的API申请
首先你要有一个ChatGPT的账号,怎么有呢?自己注册或者买一个。
第二来到下面这个页面创建你的key

第三来到下面这个页面查看你有没有额度,这个地方很坑,我是之前的账号可能不是新用户注册时间超过三个月了,所以一直没有额度用,你这里的后台如果是0,那么你就要去充钱,或者还有一种方式进去别人有额度的组织用别人的,反正充钱还挺麻烦看你们自己。
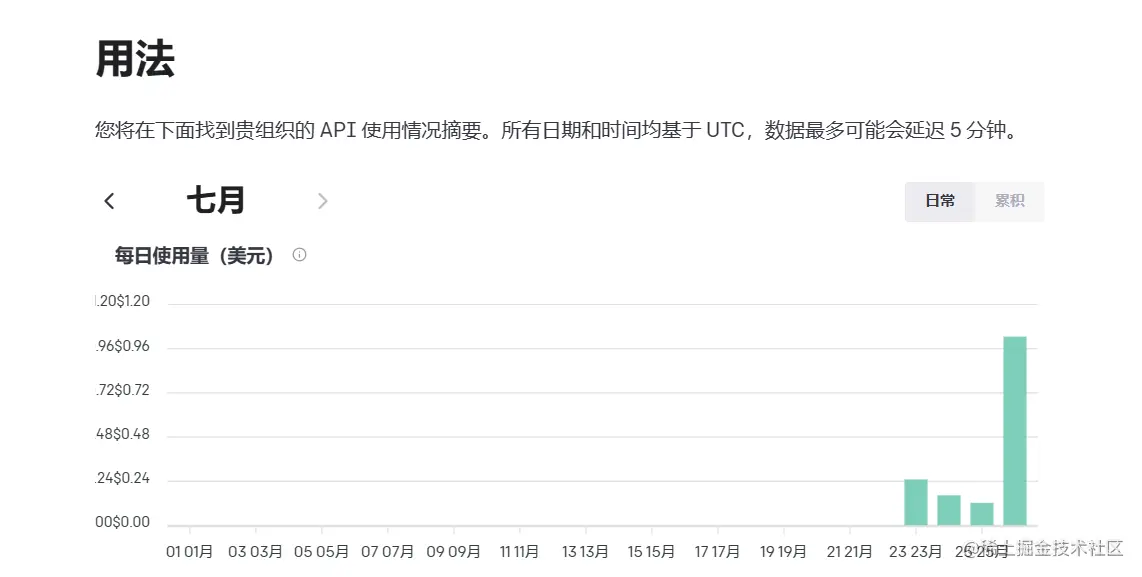
到这里其实你的API就可以用了。所以难点就是1.账号2.API的额度3.科学上网,申请根本不难,你新建一个key就行了,不用像国内的大模型还要等他审核个几天或者打电话给你询问什么的。
ChatGPT的API调用实战
import openai
API_KEY = 'sk-***'
openai.api_key = API_KEY
output = openai.ChatCompletion.create(
model = 'gpt-3.5-turbo',
messages = [{'role':'user',
'content':'can you tell me what is the basketball?'
}]
)
print(output)
这是他给出的结果,我这是演示示例而已比较简单 
下面我们来看吴恩达老师请OpenAI官方人员的演示代码
def get_completion(prompt,model="gpt-3.5-turbo"):
messages = [{"role":"user","content":prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
prompt = f"""给我一些晚餐的建议"""
response= get_completion(prompt)
print(response)
这是GPT给出的结果,这里对输出做了格式要求,所以我们可以直接看到答案,比较清晰没有其他的没必要的内容。

文心一言的API申请
首先你要进去百度智能云的首页,在橙色的圈那里登录或者注册一下账号,然后再点中间红色那个文心一言 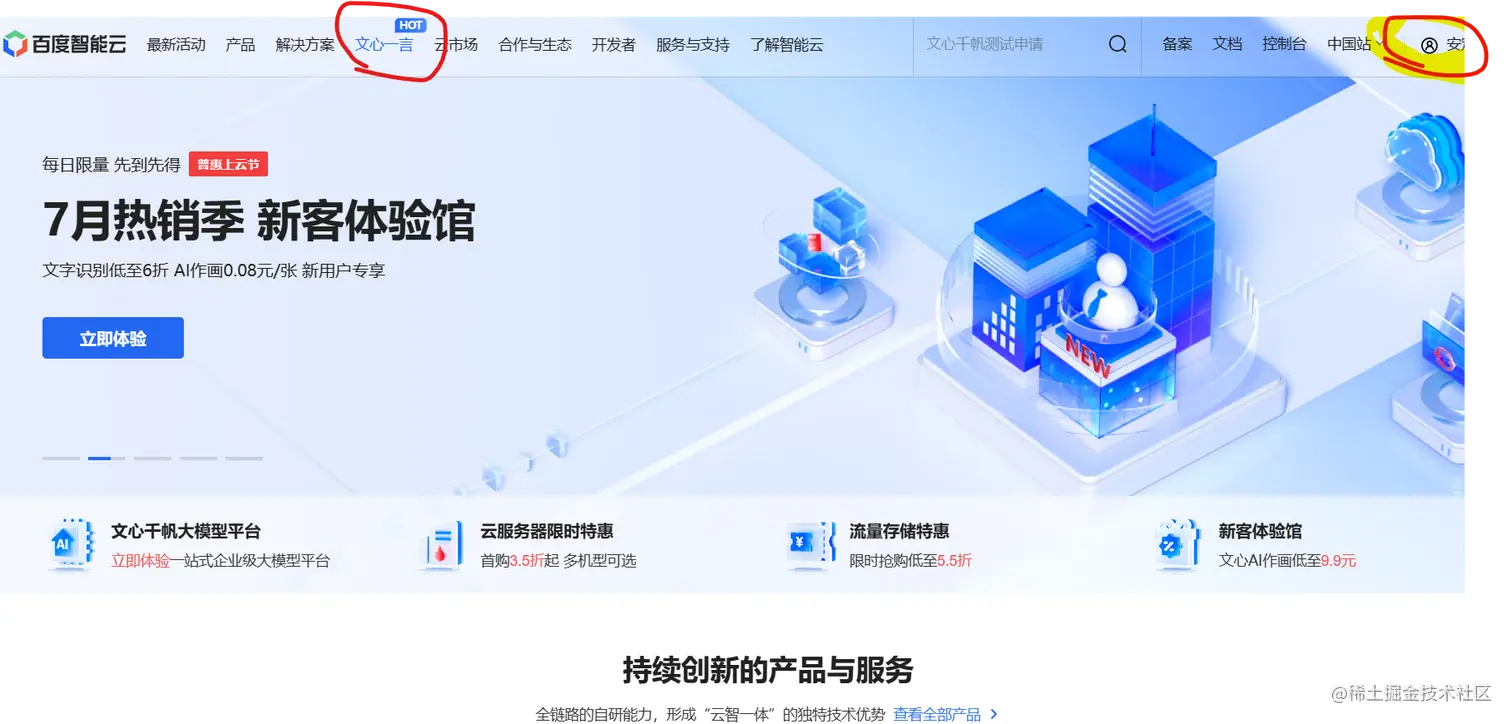
进来之后你就可以看到下面那个大大的申请体验按钮,点击他申请就行了,好像是要填一些资料包括你是用来干嘛的呀,你的姓名呀,你的电话呀这些不多一下就可以填完,填完提交就等百度电话联系你,然后简单沟通沟通几句,他就让你通过了会有短信通知你的。 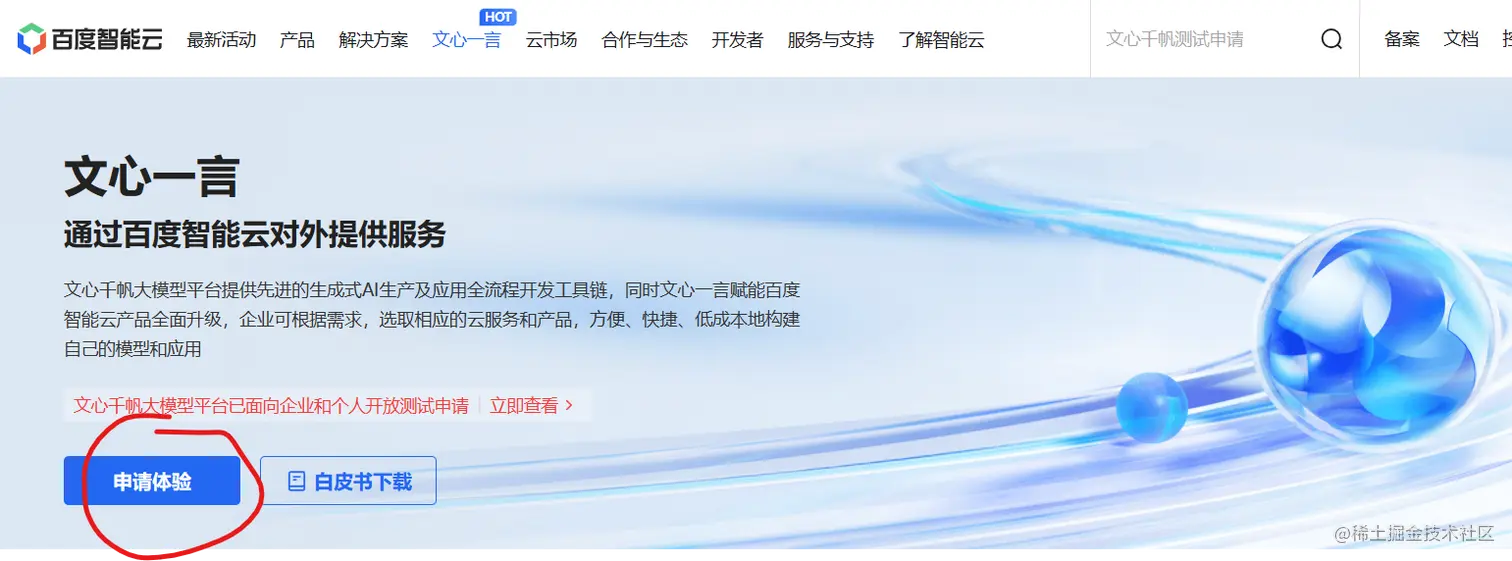 通过之后你就可以通过这个点击进入控制台这个地方进到下面的文心千帆控制台
通过之后你就可以通过这个点击进入控制台这个地方进到下面的文心千帆控制台 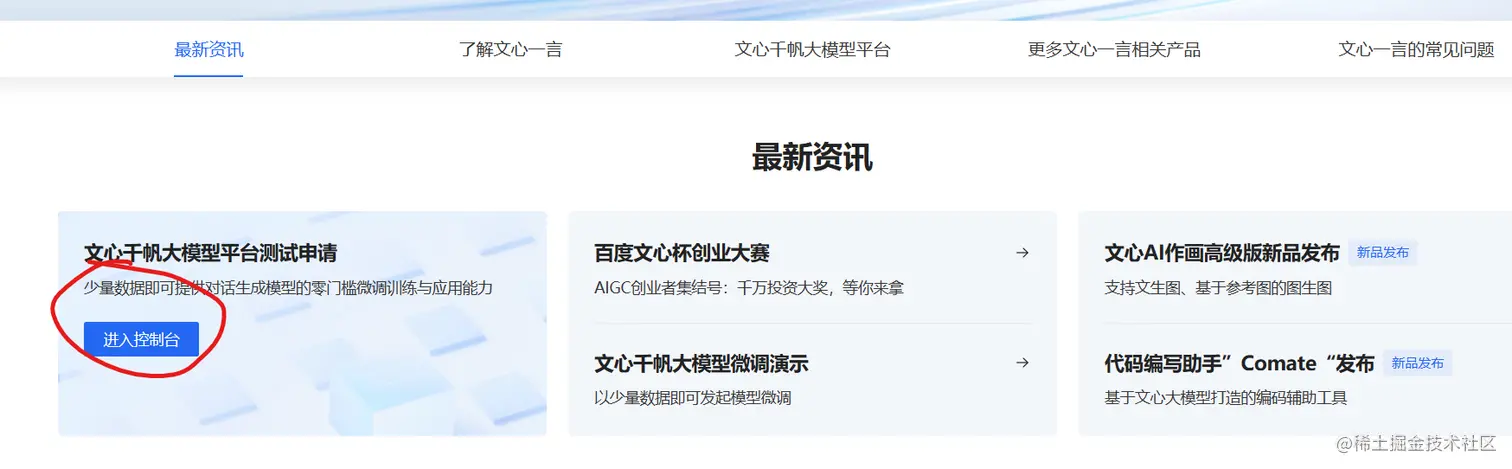 在这里文心千帆控制台,你按下面的指引一步步走,先创建应用获取一个key
在这里文心千帆控制台,你按下面的指引一步步走,先创建应用获取一个key 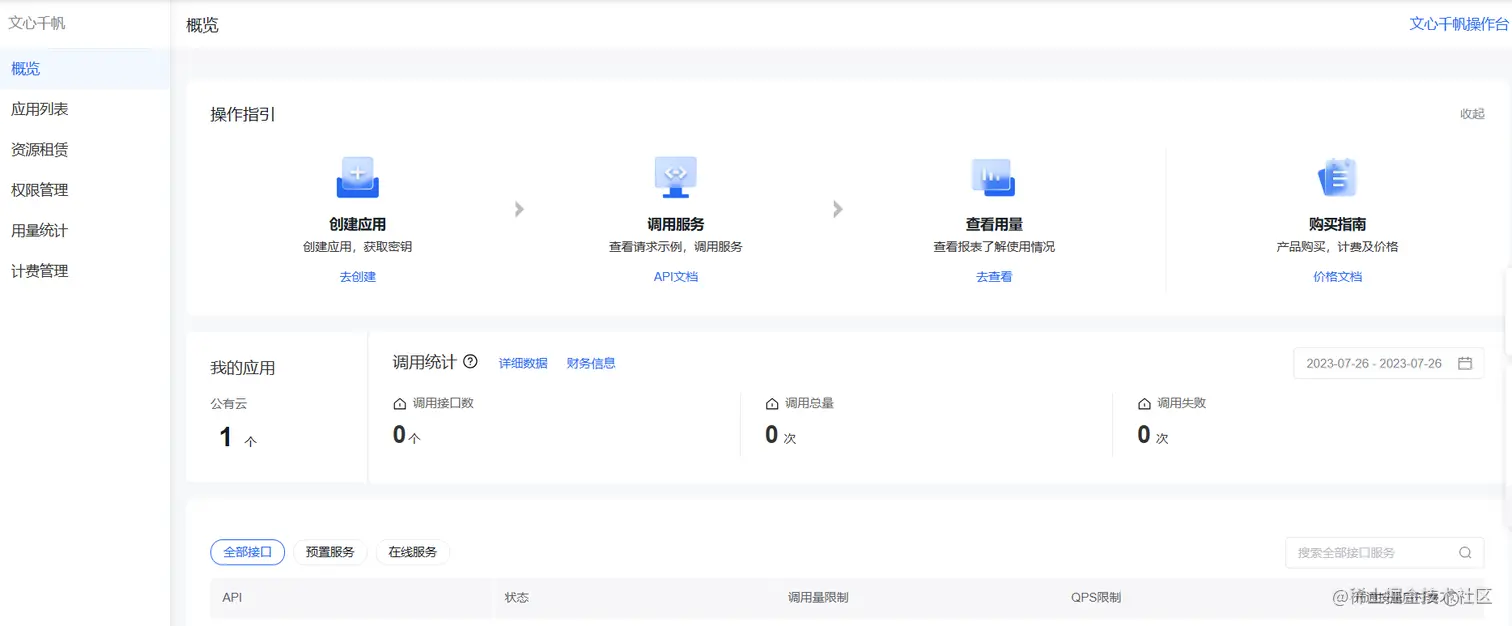 大概就是这样子,OK到这里你就可以调用文心一言的API了。
大概就是这样子,OK到这里你就可以调用文心一言的API了。 
文心一言的API调用实战
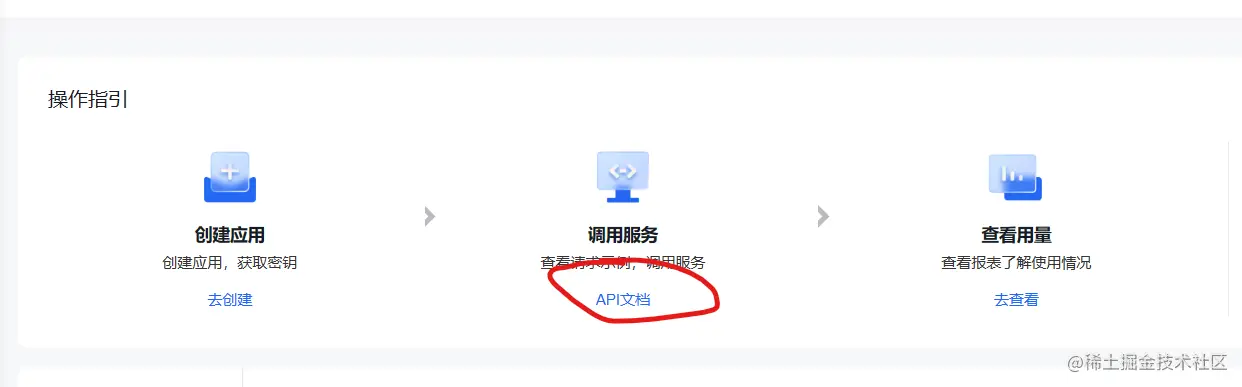 在这里进入他的调用API的文档
在这里进入他的调用API的文档 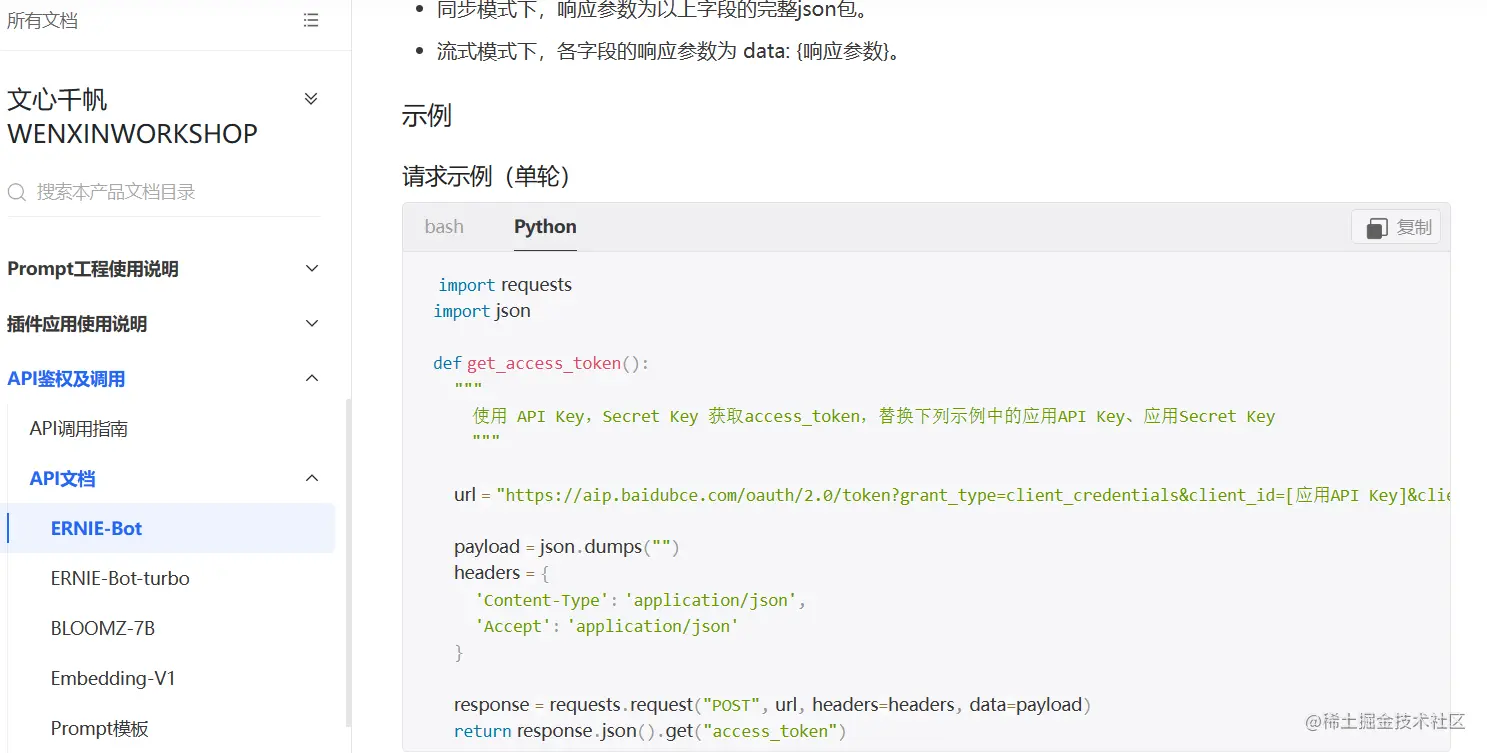 找到文档的这个部分把他的请求示例复制到自己的电脑运行就好了,我只会Python所以我就用的Python这个代码,这里记得按代码里的提示把你自己的APIkey和Secret key填上去,下面我们来看看效果
找到文档的这个部分把他的请求示例复制到自己的电脑运行就好了,我只会Python所以我就用的Python这个代码,这里记得按代码里的提示把你自己的APIkey和Secret key填上去,下面我们来看看效果
import requests
import json
def get_access_token():
"""
使用 API Key,Secret Key 获取access_token,替换下列示例中的应用API Key、应用Secret Key
"""
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=应用API Key&client_secret=应用Secret Key"
payload = json.dumps("")
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
return response.json().get("access_token")
def main():
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/completions?access_token=" + get_access_token()
payload = json.dumps({
"messages": [
{
"role": "user",
"content": "你的问题"
}
]
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
if __name__ == '__main__':
main()
在测试的过程中我问了他三个问题分别是
1.介绍一下你自己 2.介绍一下百度这家公司 3.请将“hello,world!”翻译成中文



讯飞星火的 API申请
首先你要去讯飞开放平台登录,然后在下面这个红圈进入控制台  进来之后就是下面这个界面你也要和文心一言一样创建一个应用(太久了我也忘了,可能这个要通过后才能创建吧)
进来之后就是下面这个界面你也要和文心一言一样创建一个应用(太久了我也忘了,可能这个要通过后才能创建吧) 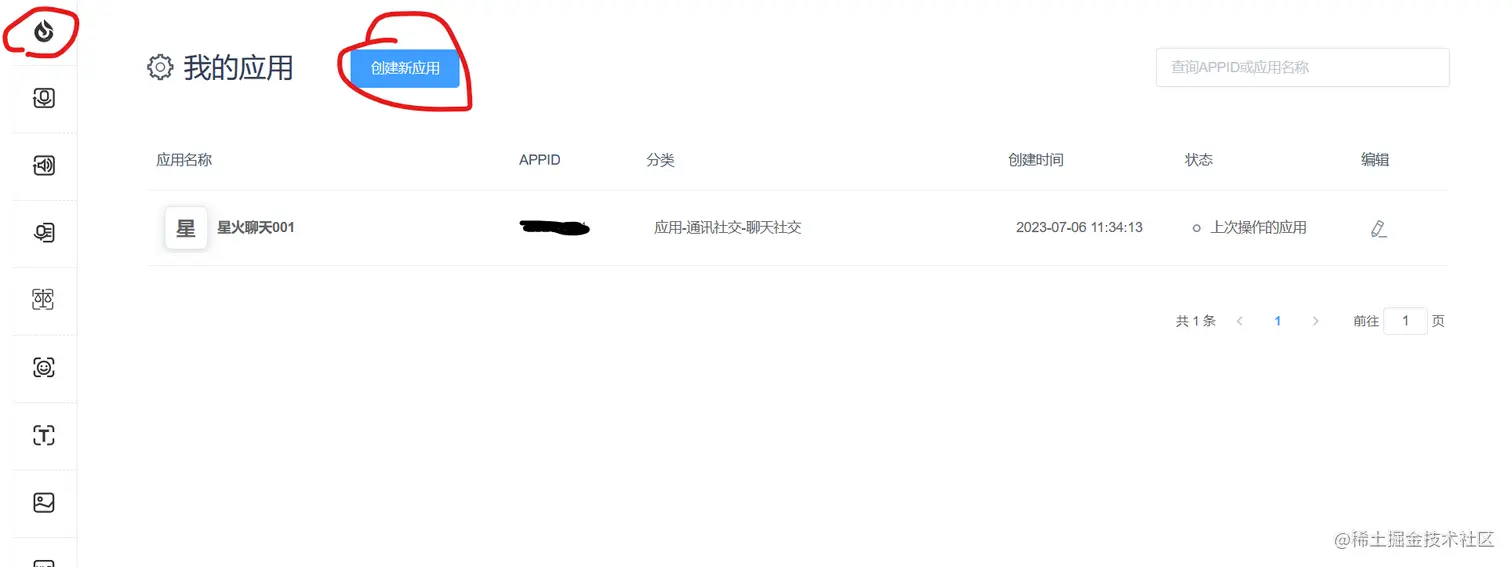 然后点上面那个小圈圈进入大模型,在下面这个界面那个合作咨询进行API申请,然后也是和上面一样填一些基础的信息和你要用来干嘛,大概也是过几天讯飞的人就会联想你。我这是通过了的界面,你们的界面可能和我不一样,反正差不多就是这个步骤。
然后点上面那个小圈圈进入大模型,在下面这个界面那个合作咨询进行API申请,然后也是和上面一样填一些基础的信息和你要用来干嘛,大概也是过几天讯飞的人就会联想你。我这是通过了的界面,你们的界面可能和我不一样,反正差不多就是这个步骤。 
讯飞星火的API调用实战
通过之后在星火大模型那个界面下面找到下面这个文档  点进去之后找到调用示例,我用的是Python版
点进去之后找到调用示例,我用的是Python版 
import _thread as thread
import base64
import datetime
import hashlib
import hmac
import json
from urllib.parse import urlparse
import ssl
from datetime import datetime
from time import mktime
from urllib.parse import urlencode
from wsgiref.handlers import format_date_time
import websocket
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, gpt_url):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.host = urlparse(gpt_url).netloc
self.path = urlparse(gpt_url).path
self.gpt_url = gpt_url
# 生成url
def create_url(self):
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = f'api_key="{self.APIKey}", algorithm="hmac-sha256", headers="host date request-line", signature="{signature_sha_base64}"'
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": self.host
}
# 拼接鉴权参数,生成url
url = self.gpt_url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
return url
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
thread.start_new_thread(run, (ws,))
def run(ws, *args):
data = json.dumps(gen_params(appid=ws.appid, question=ws.question))
ws.send(data)
# 收到websocket消息的处理
def on_message(ws, message):
print(message)
data = json.loads(message)
code = data['header']['code']
if code != 0:
print(f'请求错误: {code}, {data}')
ws.close()
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
print(content, end='')
if status == 2:
ws.close()
def gen_params(appid, question):
"""
通过appid和用户的提问来生成请参数
"""
data = {
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": "general",
"random_threshold": 0.5,
"max_tokens": 2048,
"auditing": "default"
}
},
"payload": {
"message": {
"text": [
{"role": "user", "content": question}
]
}
}
}
return data
def main(appid, api_key, api_secret, gpt_url, question):
wsParam = Ws_Param(appid, api_key, api_secret, gpt_url)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close, on_open=on_open)
ws.appid = appid
ws.question = question
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
if __name__ == "__main__":
# 测试时候在此处正确填写相关信息即可运行
main(appid="",
api_secret="",
api_key="",
gpt_url="ws://spark-api.xf-yun.com/v1.1/chat",
question="你是谁?你能做什么")
我大概问了一下翻译的问题,他给出的下面的结果,可能输出格式没有调整好,但是也是完成了任务的。 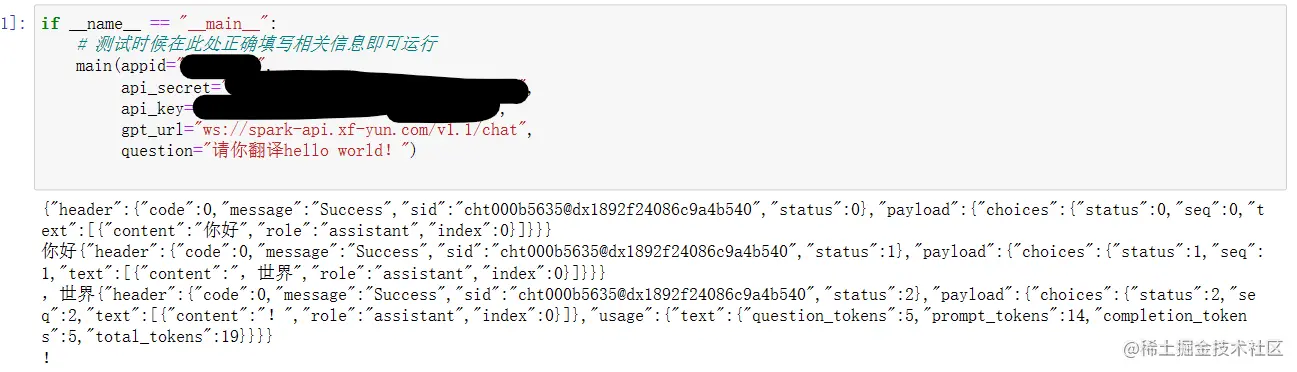
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









