







 本文介绍了如何在highway-env环境中使用DQN(DeepQ-Network)进行驾驶模拟,包括构建模型(使用状态表示法Kinematics)、定义动作和奖励机制,以及通过训练和学习策略来控制车辆。作者强调了持续学习在IT行业的重要性,尤其是对于编程人员保持竞争力的关键作用。
本文介绍了如何在highway-env环境中使用DQN(DeepQ-Network)进行驾驶模拟,包括构建模型(使用状态表示法Kinematics)、定义动作和奖励机制,以及通过训练和学习策略来控制车辆。作者强调了持续学习在IT行业的重要性,尤其是对于编程人员保持竞争力的关键作用。
生成一张W*H的灰度图像,W代表图像宽度,H代表图像高度
Occupancy grid
生成一个WHF的三维矩阵,用W*H的表格表示ego vehicle周围的车辆情况,每个格子包含F个特征。
(2) action
highway-env包中的action分为连续和离散两种。连续型action可以直接定义throttle和steering angle的值,离散型包含5个meta actions:
ACTIONS_ALL = {
0: 'LANE_LEFT',
1: 'IDLE',
2: 'LANE_RIGHT',
3: 'FASTER',
4: 'SLOWER'
}
(3) reward
highway-env包中除了泊车场景外都采用同一个reward function:
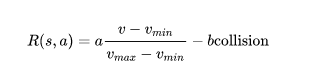
这个function只能在其源码中更改,在外层只能调整权重。
(泊车场景的reward function原文档里有)
2、搭建模型
DQN网络,我采用第一种state表示方式——Kinematics进行示范。由于state数据量较小(5辆车*7个特征),可以不考虑使用CNN,直接把二维数据的size[5,7]转成[1,35]即可,模型的输入就是35,输出是离散action数量,共5个。
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from torch import FloatTensor, LongTensor, ByteTensor
from collections import namedtuple
import random
Tensor = FloatTensor
EPSILON = 0 # epsilon used for epsilon greedy approach
GAMMA = 0.9
TARGET_NETWORK_REPLACE_FREQ = 40 # How frequently target netowrk updates
MEMORY_CAPACITY = 100
BATCH_SIZE = 80
LR = 0.01 # learning rate
class DQNNet(nn.Module):
def __init__(self):
super(DQNNet,self).__init__()  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









