






作者的话
本文介绍整型在计算机中的以什么样的方式存储,包括“三码”相关知识、截断与提升相关知识、大小端存储相关知识~
整型在内存的存储
计算机是一种电器,而电荷只有正电荷和负电荷之分,因此,任何数据在计算机中只能以二进制存储,即0和1的组合。
而在计算机中,整型有三种二进制表示方式,这三种存储方式的名字分别是原码、反码、补码。
三种方式均分为符号位和数值位,从左数第一位是符号位,其余位数值位,像这样 :
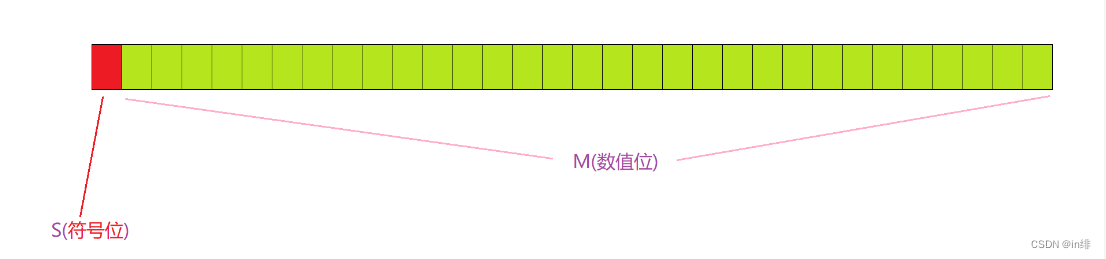
上图是一个32位整型的例子,符号位是1,则这个数是负数;符号位是0,则这个数是正数。
unsigned与signed
然而,并不是所有的整型都有符号位。
以unsigned开头的数据类型就是无符号位类型,比如unsigned int、unsigned short int、unsigned char,这三种。
对于这三种类型来说,他们的符号位和数值位一样,都代表着数据的大小,因此,这三种数据类型也没有正负之分,他们只可能是正数!
比如说:signed char的范围是-128 ~ 127,而unsigned char,因为多了一位做数值位,所以数据的上限要翻一倍,故unsigned char的取值范围是0 ~ 255。
原码反码与补码
刚才我们说到,整型在计算机中有三种二进制存储形式,分别是原码,反码,补码。
对于正数、unsigned型的数来说,原码反码补码完全相同,即这三者的书写方式一模一样。
但对于负数来说,这三者各不相同,转换规则如下:
原码符号位不变,其他位取反,就成了反码。
反码+1,即是补码。
例如:
-119的原码:10000000000000000000000001110111
-119的反码:01111111111111111111111111111001000
-119的补码:01111111111111111111111111111001001
由此可见:
- 原码就是数据按照大小翻译成二进制,再看类型和正负决定符号位。
- 原码与反码的转换过程相同,即原码取反+1后是补码,补码取反+1后又变成了原码。
计算机内的存储
虽然二进制有三种表示方式,但在计算机中,总是以补码的方式保存。
原因如下:
- CPU只有加法器,用补码存储可以无视符号位与数值位的区别,把他们两个放在一起计算。
- 刚才说原码和补码的转换方式相同,这样可以节省硬件电路的复杂度。
计算机存储过程
所谓过程,就是如何把这个数据放进计算机里面。
如果每种整型类型对应放置每种整型数据,那自然没什么好说的。
但是如果类型不同,就会发生截断。
截断:
超出某类型范围的数据放入该类型空间时,只保留一部分,像这样:
signed char的范围是-128~127。
如果我偏要把128放进去,然后打印,会发生什么?

打印的结果居然是-128 , 其原因就是在放入数据和取出数据的时候分别发生了截断和提升。
详解:
128的原码:00000000000000000000000010000000
128的补码:011111111111111111111111111110000000
因为a是1个字节,一个字节占8个bit位,所以从低位截出8位来。
截完以后a的内部:10000000
这就是截断,记住从操作系统从低位开始截,而且截的是补码。
a提升后的补码:11111111111111111111111110000000
a提升后的原码:10000000000000000000010000000
这一串翻译成十进制就是-128
整型如何提升
整型提升,用一句话说就是占用空间小于4个字节的数据类型,在使用时要先转换成至少为4个字节的int类型后,才能使用。
至于提升的方法,一共有两种,对于有符号数(signed)来说,按符号位提升;对于无符号数(unsigned)来说,无脑补0,像这样:
char a=0b10000000;
unsigned char b=0b11110000;
补完以后:
a:11111111111111111111111110000000
b:00000000000000000000000011110000
大小端存储
- 大端字节序存储模式,简称大端模式,是指数据的低位字节保存在内存的高位处。
- 小端字节序存储模式,简称小端模式,是指数据的低位字节保存在内存的低处。
下面演示一个小端字节序的存储,像这样:
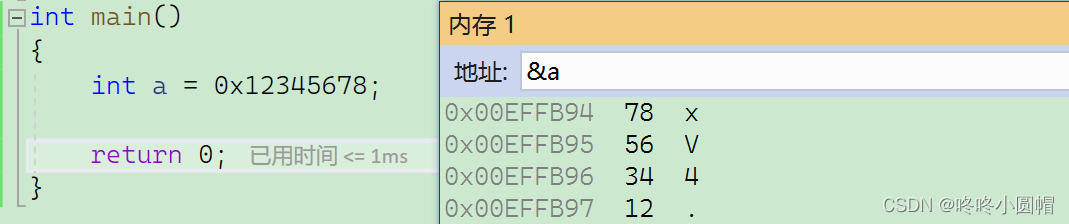
上图可以看到,a的低位地址(0x00EFFB94),存储的是数据的低位字节;a的高位地址(0x00EFFB97),存储的是数据的高位字节。
注意:一个内存单元的大小是一个字节,因此,大小端存储的单位也是一个字节。
存在意义
我们知道,一个内存单元的大小是1个字节,但除了char类型,其他数据的占用空间大小都在1个字节以上,想要把一个数据的每个字节都放在一起,排列的顺序自然就成了一个问题。
历史遗留:
据说灵感来自格列佛游记,在格列佛游记中有一个小人国,有一个大人国,有一天大人国送了小人国一个鸡蛋,小人国的国王就在想,是从鸡蛋大的那一头开始剥,还是从小的那一头开始呢?
于是就有了大小端的说法,不同的模式没有优劣之分,只是选择不同。
如何分辨
当前我们常用的x86机器,采用的是小端存储模式,那么:
如何设计一个程序,可视化地判断当前环境是大端存储还是小端存储呢?
我们知道,计算机读取数据总是从低位开始读取,那么我们只需要令一个占用空间大于1个字节的变量存储一个小于1个字节的数据,然后利用指针类型的特性读取这一个字节就可以了,像这样:
int main()
{
short a = 0x0001;
char* p = (char*)&a;
printf("%d", *p);
return 0;
}
short型数据占两个字节,我们以char类型的指针读取其中的低位第一个字节,查看打印的数字是0还是1即可。
效果图:
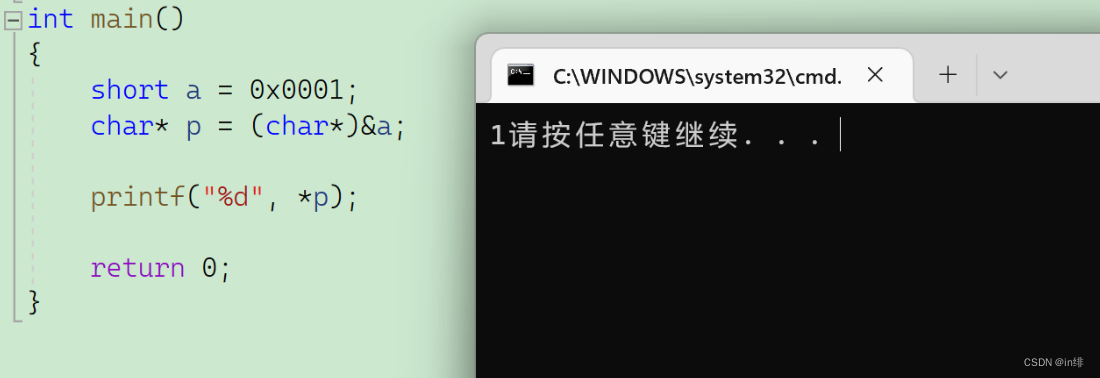
可以看到,打印结果是1,符合我当前的小端机器。















 145
145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











