







既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
数据挖掘本身是一件事。它不能具体的指向某一学科,技术和领域。它需要我们能够综合利用所学的知识。比如统计学、数据科学、高等数学、机器学习、数据分析等发现数据中有价值的信息。而数据挖掘在不同的领域有不同的处理方式。如在不同领域如教育、医疗、互联网、金融等。会有不同数据,比如银行交易数据,超市购物数据,天气情况数据,学生学习行为数据等。有着不同的处理思路和方式。而这种处理思路和方式,要当时情况而定,数据特征而定,具体问题具体分析。是我们经过学习高等数学、数据科学、统计学等多种学科,深入理解后共同达成的结果。所以实际上这是一个需要深入思考的过程。
而对于编写教材的前辈们很难实际在该领域做过类似实际项目。则只能以学科分类的角度去写。
所以,对于此类教材可能很难有较为理想的版本,大多只能泛泛而谈,点到为止。同时在AI时代下,教育的框架和方式需要有所变革,注重学生的自主学习力,创造力等高阶思维能力。才能更好的较好学生。然而在实际教学中,由于学生数量多,及整体听课情况,加上自身积累不够等因素。所以学生要想学好此项技能。难度较大。所以写下此文,希望能够对学习这有所帮助,省些搜索资料的时间。
0 总序(书中内容)
短短几年间,大数据以一日千里的发展速度快速实现了从概念到落地,直接带动了相关产业的井喷式发展。数据采集、数据存储、数据挖掘、数据分析等大数据技术在越来越多的行业中得到应用,随之而来的即是大数据人才缺口问题的凸显。根据《人民日报》的报道,未来3~5年,中国需要180万大数据人才,但目前只有约30万人,人才缺口达到150 万之多。
大数据是一门实践性很强的学科,在其呈现金字塔型的人才资源模型中,数据科学家居于塔尖位置,然而该领域对于经验丰富的数据科学家需求相对有限,反而是对大数据底层设计、数据清洗、数据挖掘及大数据安全等相关人才的需求急剧上升,可以说后者占据了大数据人才需求的80%以上。
迫切的人才需求直接催热了相应的大数据应用专业。2021年全国892所高职院校成功备案大数据技术专业,40所院校新增备案数据科学与大数据技术专业,42所院校新增备案大数据管理与应用专业。随着大数据的深入发展,未来几年申请与获批该专业的院校数量仍将持续走高。
即使如此,就目前而言,在大数据人才培养和大数据课程建设方面,大部分专科院校仍然处于起步阶段,需要探索的问题还有很多。首先,大数据是个新生事物,懂大数据的老师少之又少,院校缺“人”;其次,院校尚未形成完善的大数据人才培养和课程体系,缺乏“机制”;再次,大数据实验需要为每位学生提供集群计算机,院校缺“机器”;最后,院校没有海量数据,开展大数据教学实验工作缺少“原材料”。
对于注重实操的大数据专业专科建设而言,需要重点面向网络爬虫、大数据分析、大数据开发、大数据可视化、大数据运维等工作岗位,帮助学生掌握大数据专业必备知识,使其具备大数据采集、存储、清洗、分析、开发及系统维护的专业能力和技能,成为能够服务区域经济的发展型、创新型或复合型技术技能人才。无论是缺“人”、缺“机制”、缺“机器”,还是缺少“原材料”,最终都难以培养出合格的大数据人才。
第一章 数据挖掘概念
1.1 数据挖掘基础概念
什么是大数据?随着大数据技术的不断发展,数据的复杂程度愈来愈高,不断有人针对大数据特征提出新的论断,大数据的特性也由原来的4V增加至现在的7V:①规模大(Volume):数据的大小决定所考虑的数据的价值大小和潜在的信息多少;②多样化(Variety):数据类型的多样性;③高速性(Velocity):指获得数据的速度;④价值化(Value):合理运用大数据,以低成本创造高价值;⑤准确性(Veracity):数据的质量:⑥动态性(Variability):妨碍了处理和有效地管理数据的过程;⑦可视化(Visualization):能帮助数据工作者更好地理解数据中可能存在的结构和规律。
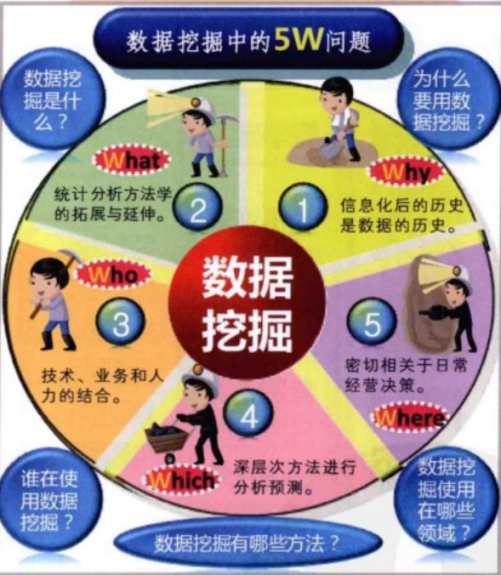
1.1.1 开篇点题引五问
在企业的业务运营中,通常会借助数据挖掘技术来辅助产品设计,营销推广等环节的工作。需要问自己5个问题。
why:表示通过日常监控分析发现的运营问题;
what:表示制定解决目标问题的总体策略方针。
who:表示结合运营数据并组织开展数据挖掘工作的各类专业人员;
which:表示针对特定目标用户设计的精细化运营方案,主要目的是促进用户活跃和业务的有效使用。
where:表示通过跟踪用户发展和业务推广情况作出的相应优化和改进,并评估市场反馈。
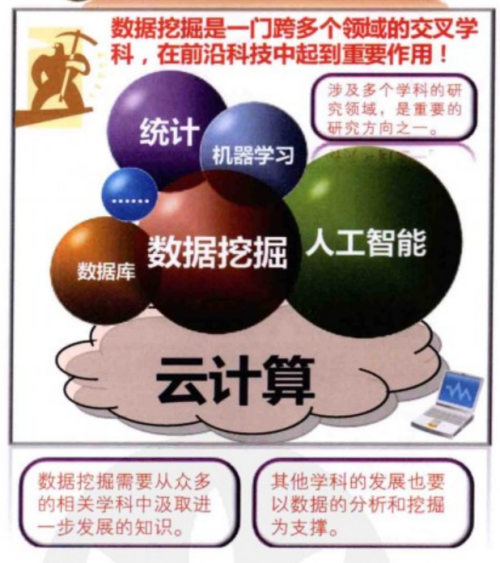
1.1.2 知识决策跨领域
数据挖掘与统计学有很多共同之处,二者有着相似的研究目标,都在探寻在于大量数据中有价值的信息和知识。同时数据挖掘还借鉴并应用了其他许多科学领域的思想和方法,比如数据库、机器学习和人工智能等。通过基于云计算的大规模数据存储和处理技术,也为海量数据挖掘提供了新的手段和方法。
1.1.3 什么是数据挖掘
数据挖掘(Data Mining),就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
广义:数据挖掘是指知识发现的全过程
狭义:数据挖掘是知识发现的一个重要环节,利用机器学习、统计分析等发现数据模式的智能方法,侧重于模型和算法。
数据挖掘的数据源包括数据库、数据仓库、Web或其他数据存储库。
知识发掘的过程如下:
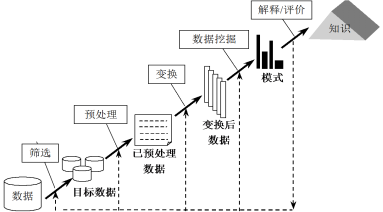
(1)数据准备:掌握知识发现应用领域的情况,熟悉相关的背景知识,理解用户需求。
(2)数据选取:数据选取的目的是确定目标数据,根据用户的需要从原始数据库中选取相关数据或样本。
(3)数据预处理:对数据选取步骤中选出的数据进行再处理,检查数据的完整性及数据一致性,消除噪声,滤除与数据挖掘无关的冗余数据,根据时间序列和已知的变化情况,利用统计等方法填充丢失的数据。
(4)数据变换:根据知识发现的任务对经过预处理的数据进行再处理,将数据变换或统一成适合挖掘的形式,包括投影、汇总、聚集等。
(5)数据挖掘:确定发现目标,根据用户的要求,确定要发现的知识类型。根据确定的任务选择合适的分类、关联、聚类等算法,选取合适的模型和参数,从数据库中提取用户感兴趣的知识,并以一定的方式表示出来。
(6)模式解释:对在数据挖掘中发现的模式进行解释。经过用户或机器评估后,可能会发现这些模式中存在冗余或无关的模式,此时应该将其剔除。如果模式不能满足用户的要求,就返回前面的相应步骤中反复提取。
(7)知识评价:将发现的知识以用户能了解的方式呈现给用户。
数据挖掘标准流程:
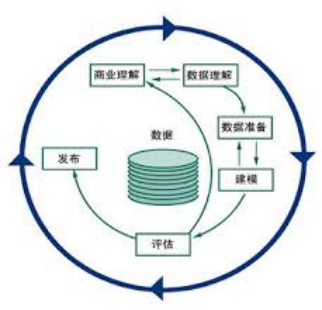
跨行业的标准数据挖掘流程CRISP-DM(CRoss-Industry Standard Process for Data Mining)
CRISP-DM从方法论的角度将整个数据挖掘过程分解商业理解、数据理解、数据准备、建立模型、模型评估、和结果部署六个阶段。
1.1.4 数据挖掘常用分类
数据挖掘的任务模式按照功能类型分成描述型和预测型两类,且都有各自的使用范围和特点。一般来说,描述型任务则基于数据进行检验推断。数据挖掘的主要功能是找到任务中所需要的各种模式类型,同时将这些功能归纳演绎成为一个知识发现的过程,其中每项数据挖掘功能能够在具体的实践操作中互相联系,综合发挥作用,从而来满足不同的业务应用需求。常用的数据挖掘功能包括分类、聚类、预测和关联四大类模型。
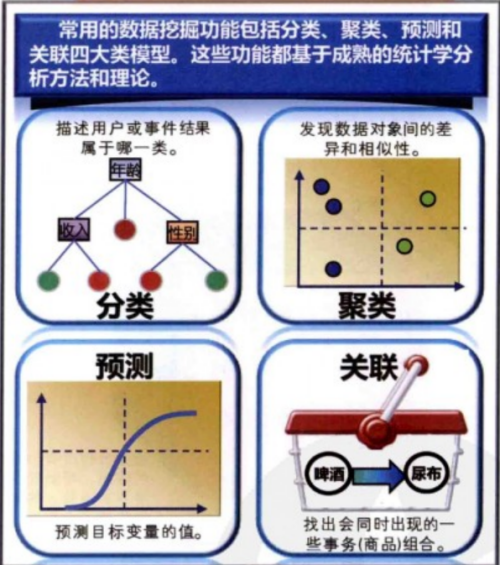
分类:分类(classification)属于有监督学习,即从给定的有标记训练数据集中学习出一个函数,当未标记数据到来时,可以根据这个函数预测结果。在数据挖掘领域,分类可以看成是从一个数据集到一组预先定义的、非交叠的类别的映射过程。分类找出描述和区分数据类或概念的模型(或函数),以便能够使用模型预测类标号未知的对象的类标号,导出的模型是基于对训练数据集(即类标号已知的数据对象)的分析。该模型用来预测类标号未知的对象的类标号。导出模型的表示形式有分类规则、决策树、数学公式、神经网络等。
聚类:
聚类:聚类分析(Cluster Analysis)又称群分析,是根据“物以类聚”的道理,对样品或指标进行划分的一种多元统计分析方法,讨论的对象是大量的样品,要求能合理地按各自的特性来进行合理的划分。聚类是在没有先验知识的情况下进行的。
一个类簇是测试空间中点的汇聚,同一类簇的任意两个点间的距离小于不同类簇的任意两个点间的距离。类簇可以描述为一个包含密度相对较高的点集的多维空间中的连通区域。
在机器学习中,聚类归纳为非监督式学习。
预测:即回归分析(regression analysis):在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量来预测研究者感兴趣的变量,主要包括线性回归分析和非线性回归分析。
分类与回归具有许多不同的研究内容,它们都是研究输入输出变量之间的关系问题,不同之处在于分类的输出是离散的类别值,而回归的输出是连续的数值,即回归分析用来预测缺失的或难以获得的数值数据,而不是(离散的)类标号。
关联规则(Association rules):挖掘发现大量数据中项集之间有趣的关联或相关联系。
即在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构,是数据挖掘中一个重要的课题。关联规则研究有助于发现交易数据库中不同商品(项)之间的联系,找出顾客购买行为模式,如购买了某一商品对购买其他商品的影响。分析结果可以应用于商品货架布局、货存安排等。
1.2 数据基础
1.2.1 数据概述
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









