






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
2、大数据三种数据类型
结构化数据:关系型数据。
半结构化数据:XML数据。
非结构化数据:Word文档、PDF文档、文本、媒体日志。
大量性(volume): 一般在大数据里,单个文件的级别至少为几十,几百GB以上
快速性(velocity): 反映在数据的快速产生及数据变更的频率上
多样性(variety): 泛指数据类型及其来源的多样化,进一步可以把数据结构归纳为结构化(structured),半结构化(semi-structured),和非结构化(unstructured)
易变性: 伴随数据快速性的特征,数据流还呈现一种波动的特征。不稳定的数据流会随着日,季节,特定事件的触发出现周期性峰值
准确性: 又称为数据保证(data assurance)。不同方式,渠道收集到的数据在质量上会有很大差异。数据分析和输出结果的错误程度和可信度在很大程度上取决于收集到的数据质量的高低
复杂性: 体现在数据的管理和操作上。如何抽取,转换,加载,连接,关联以把握数据内蕴的有用信息已经变得越来越有挑战性
===================================================================================
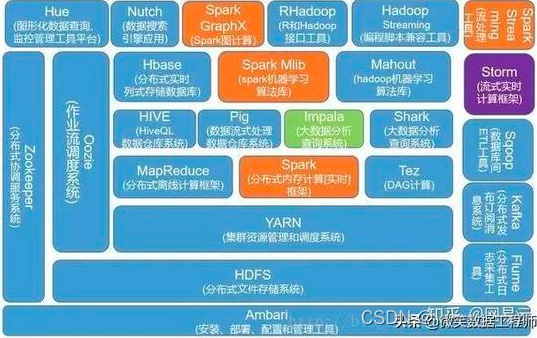
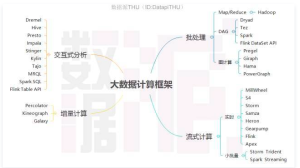
基础的技术包含数据的采集、数据预处理、分布式存储、NoSQL数据库、数据仓库、机器学习、并行计算、可视化等各种技术范畴和不同的技术层面。首先给出一个通用化的大数据处理框架,
主要分为下面几个方面:数据采集与预处理、数据存储、数据清洗、数据查询分析和数据可视化。
详细:参考
根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层。
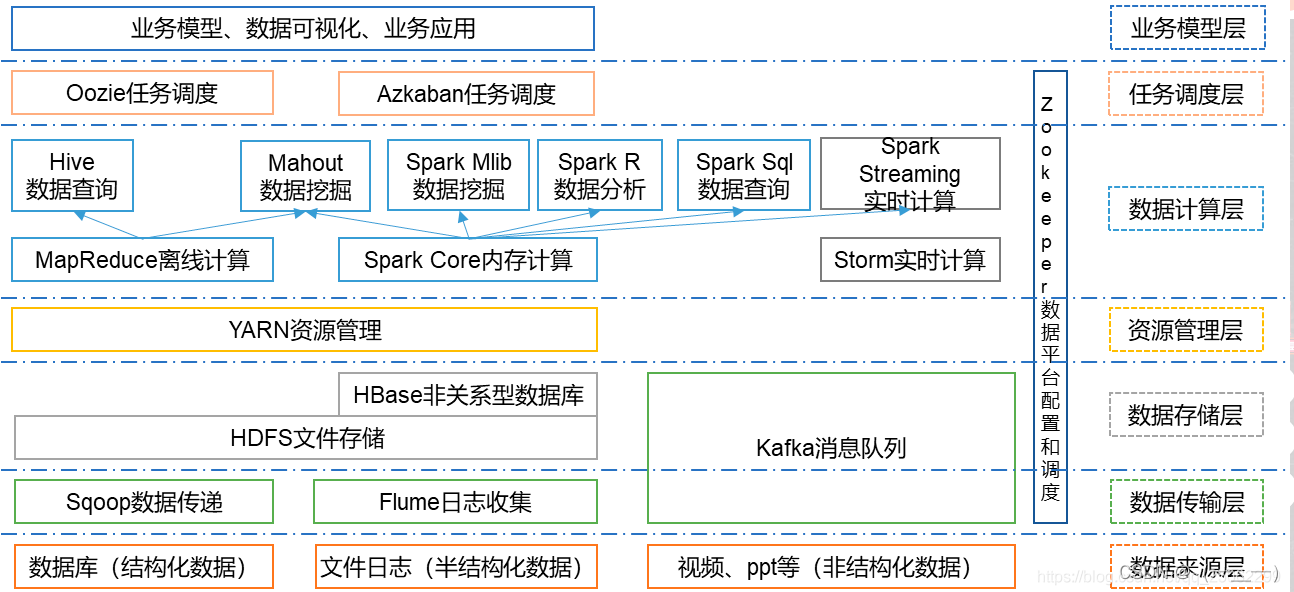
Flume 作为实时日志收集系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时,对数据进行简单处理,并写到各种数据接收方(比如文本,HDFS,Hbase等)。
Logstash 、filebeat 是开源的服务器端数据处理管道,能够同时从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。一般常用的存储库是Elasticsearch。
Sqoop用来将关系型数据库和Hadoop中的数据进行相互转移的工具,可以将一个关系型数据库(例如Mysql、Oracle)中的数据导入到Hadoop(例如HDFS、Hive、Hbase)中,也可以将Hadoop(例如HDFS、Hive、Hbase)中的数据导入到关系型数据库(例如Mysql、Oracle)中。
Hadoop作为一个开源的框架,专为离线和大规模数据分析而设计,
HDFS 作为其核心的存储引擎,已被广泛用于数据存储。
HBase,是一个分布式的、面向列的开源数据库,可以认为是hdfs的封装,本质是数据存储、NoSQL数据库。HBase是一种Key/Value系统,部署在hdfs上,克服了hdfs在随机读写这个方面的缺点,与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
Phoenix,相当于一个Java中间件,帮助开发工程师能够像使用JDBC访问关系型数据库一样访问NoSQL数据库HBase。
Redis 是一种速度非常快的非关系数据库,可以存储键与5种不同类型的值之间的映射,可以将存储在内存的键值对数据持久化到硬盘中,使用复制特性来扩展性能,还可以使用客户端分片来扩展写性能。
Kudu 是围绕Hadoop生态圈建立的存储引擎,提供低延迟的随机读写和高效的数据分析能力。
大数据存储技术: Hdfs、Hbase、Hive、S3、Kudu、MongoDB、Neo4J 、Redis、Alluxio(Tachyon)、Lucene、Solr、ElasticSearch
MapReduce作为Hadoop的查询引擎,用于大规模数据集的并行计算,”Map(映射)”和”Reduce(归约)”,是它的主要思想。它极大的方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统中。
Oozie是用于Hadoop平台的一种工作流调度引擎,提供了RESTful API接口来接受用户的提交请求(提交工作流作业),当提交了workflow后,由工作流引擎负责workflow的执行以及状态的转换。
Azkaban也是一种工作流的控制引擎,可以用来解决有多个hadoop或者spark等离线计算任务之间的依赖关系问题。
Hive的核心工作就是把SQL语句翻译成MR程序,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能。
Impala是对Hive的一个补充,可以实现高效的SQL查询。使用Impala来实现SQL on Hadoop,用来进行大数据实时查询分析。
Spark拥有Hadoop MapReduce所具有的特点,它将Job中间输出结果保存在内存中,从而不需要读取HDFS。
大数据分析与挖掘技术: MapReduce、Hive、Pig、Spark、Flink、Impala、Kylin、Tez、Akka、Storm、S4、Mahout、MLlib
1、大数据展现
图化展示(散点图、折线图、柱状图、地图、饼图、雷达图、K线图、箱线图、热力图、关系图、矩形树图、平行坐标、桑基图、漏斗图、仪表盘),文字展示;
2、大数据展现技术
Echarts、Tableau
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3952
3952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









