







预测泰坦尼克号沉船事件中哪些人员会获救?
目录
1. 背景
1912年4月15日,泰坦尼克号第一次远航,装上冰山后沉没,导致2224名人员中有1502名人员死亡。对于这些获救人员,是因为幸运获救还是因为有其他的因素影响?我们选择使用随机森林来对这个问题进行分析和预测。
随机森林就是通过集成学习的Bagging思想将多棵树集成的一种算法:它的基本单元就是决策树。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,其实这也是随机森林的主要思想--集成思想的体现。
我们要将一个输入样本进行分类,就需要将它输入到每棵树中进行分类。将若干个弱分类器的分类结果进行投票选择,从而组成一个强分类器,这就是随机森林bagging的思想。
2. 数据集
2.1 训练集(train.csv)
文件包括891条记录,11个特征,1个标签(0,1)。
2.2 测试集(test.csv)
文件包括418个待预测样本,11个特征。
3. 特征解读
| Passengeld | 乘客ID |
| Survived | 获救或死亡 |
| Pclass | 船舱等级 |
| Name | 姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 兄弟配偶 |
| Parch | 父母孩子 |
| Ticket | 船票信息 |
| Fare | 票价 |
| Cabin | 船舱信息 |
| Embarked | 港口 |
4. 解决思路
4.1.定义问题
4.2.收集数据
4.3.数据清洗
4.3.1 纠正:异常值
4.3.2 完整:补足缺失值
4.3.3构建:新的特征
4.3.4转换:字段格式替换
4.4.探索分析
4.5.数据建模
4.6.模型验证
4.7.模型优化
5. 实际操作
工具:anaconda
5.1 导入需要的库
5.2 收集数据
源数据集加载之后可以查看下数据:
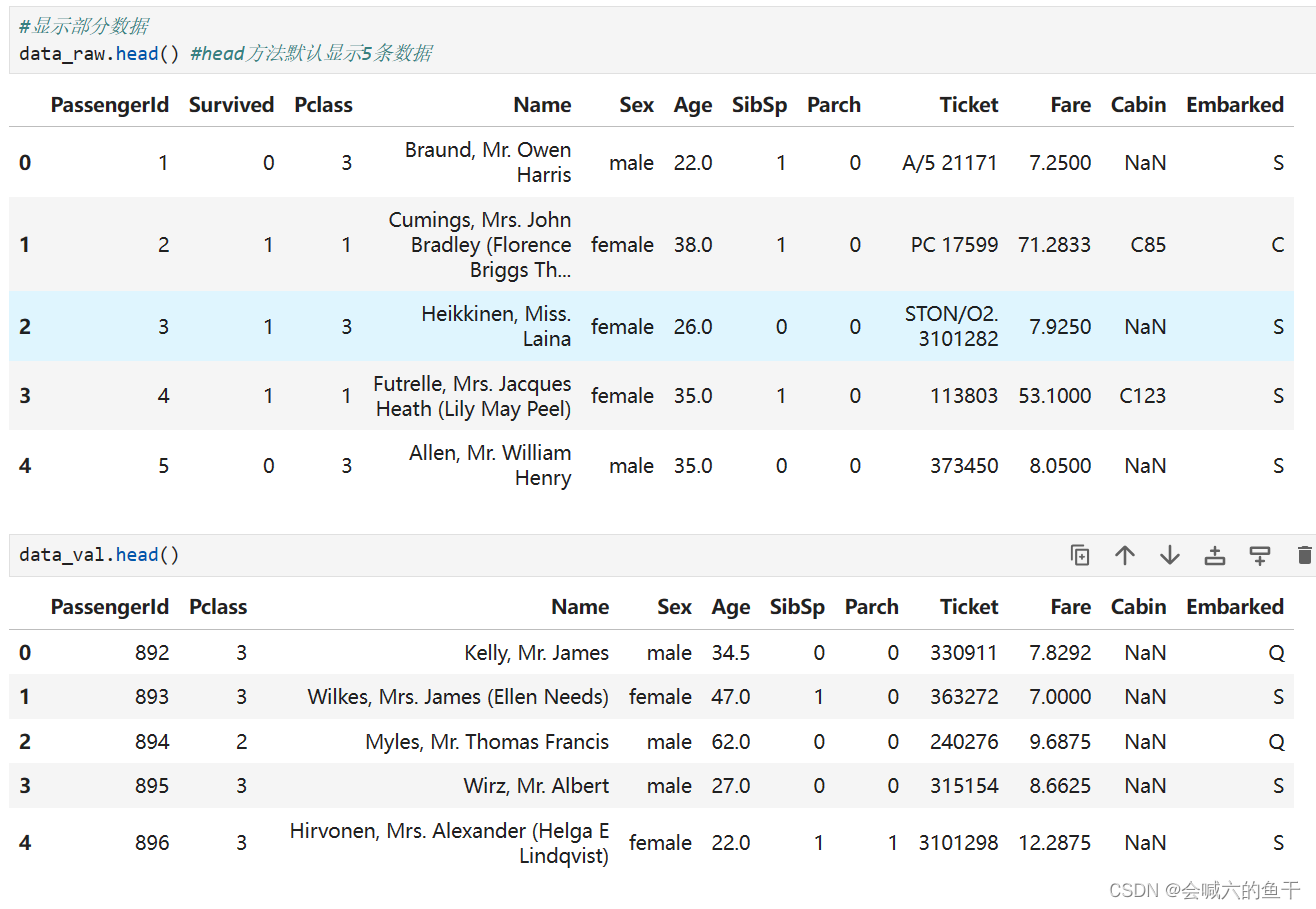
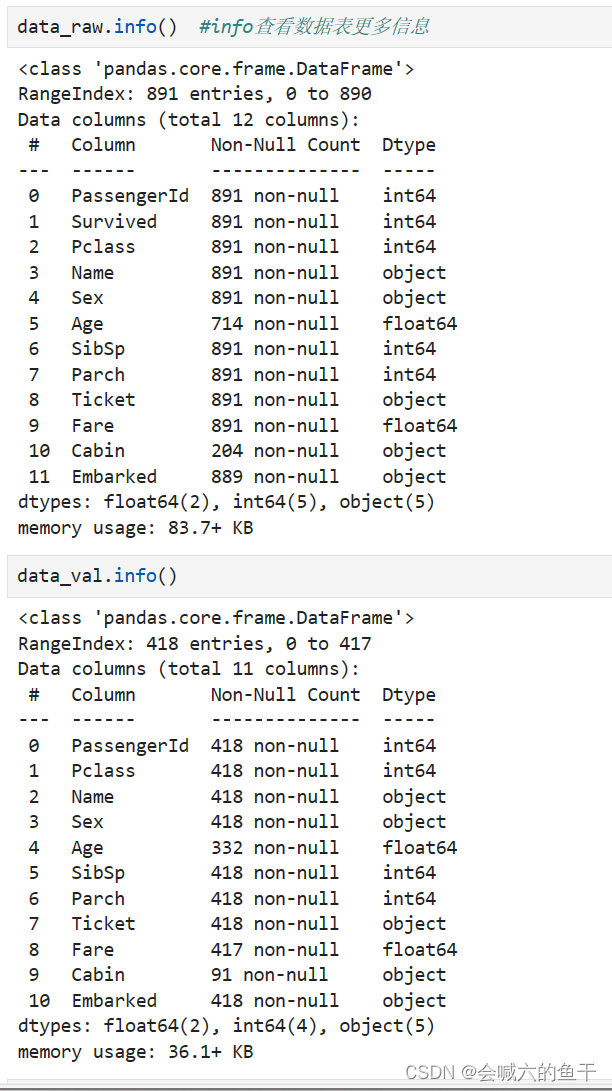
训练集的数据相比测试集的数据多出的Survived字段是生还结果,我们的目的就是预测出测试集的Survive。此外我们还可以查看下数据表的其他信息,例如每个字段有多少条数据,数据是什么类型等等。
为了之后处理数据方便,可以将列名称转换成小写(看个人喜好)
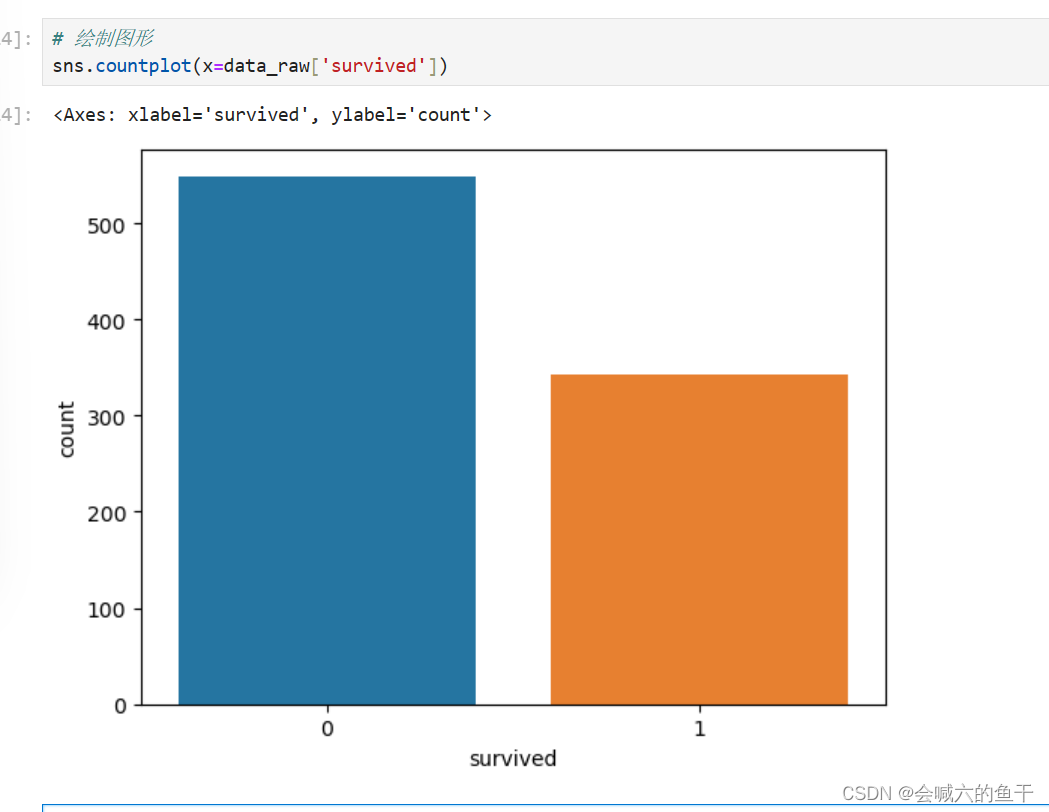
针对训练集的survived字段绘制图表查看生还情况,0表示死亡,1表示存活。
5.3 数据清洗
先将两个数据集合并在一起,方便后续进行统一数据清洗
首先查看训练集和验证集是否有空值
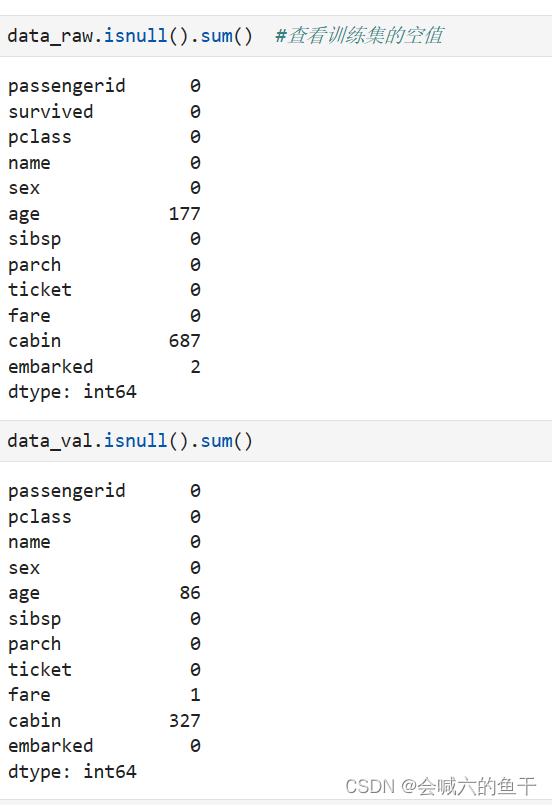
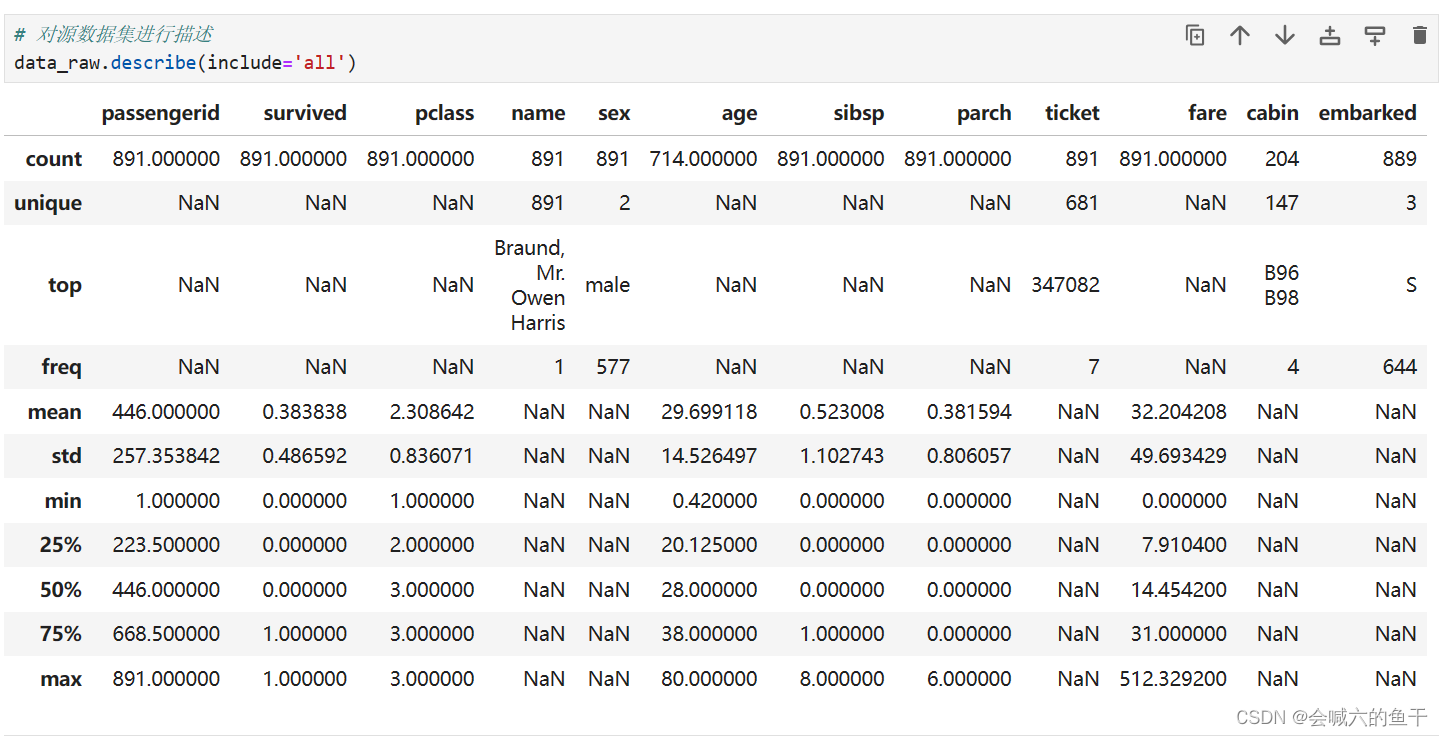
可以看到训练集的age有177个空值,cabin有2个空值,embarked有2个空值;验证集的age有86个空值,fare有2个空值,cabin有327个空值。还可以对源数据集进行描述查看更多的信息,例如每个字段的均值、最大值等等。
对原始数据集(训练集和验证集)进行清理
之前我们通过查看空值发现age、fare、embarked、cabin存在空值,因此首先要补全空值。
一般我们会用均值来表示一个群体的平均水
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7570
7570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









