






复现过程不像其他代码包一样流畅,有些忐忑,,,,,原作者的根本无法复现,,,,,有些麻木,于是在此做个记录,记录成功过程。
一、OW-DETR简介
代码链接: https://gitcode.com/akshitac8/OW-DETR?tab=readme-ov-file#training-on-slurm-cluster&utm_source=csdn_github_accelerator&isLogin=1
论文链接:https://arxiv.org/abs/2112.01513
说实话,,,论文内容写的也有点模糊,,靠代码看懂,,,,,,必须得记录tnnd
摘要:开放世界目标检测(OWOD)是一个富有挑战性的计算机视觉问题,其任务是在同时识别未知物体的情况下,检测一组已知的目标类别。此外,模型还必须在接下来的训练周期中学习新的类。与标准目标检测不同的是,OWOD 的设置对生成可能未知对象的质量候选提议、从背景中分离未知对象以及检测各种未知对象提出了重大挑战。在这里,我们引入了一种新颖的端到端基于 Transformer 的框架 OW-DETR,用于开放世界目标检测。所提出的 OW-DETR 包括三个专门组件,即注意力驱动的伪标记、新颖分类和对象性评分,以显式地解决上述 OWOD 挑战。我们的 OW-DETR 显式编码多尺度上下文信息,具有较少的归纳偏见,能够从已知类推断出未知类,并且可以更好地区分未知对象和背景。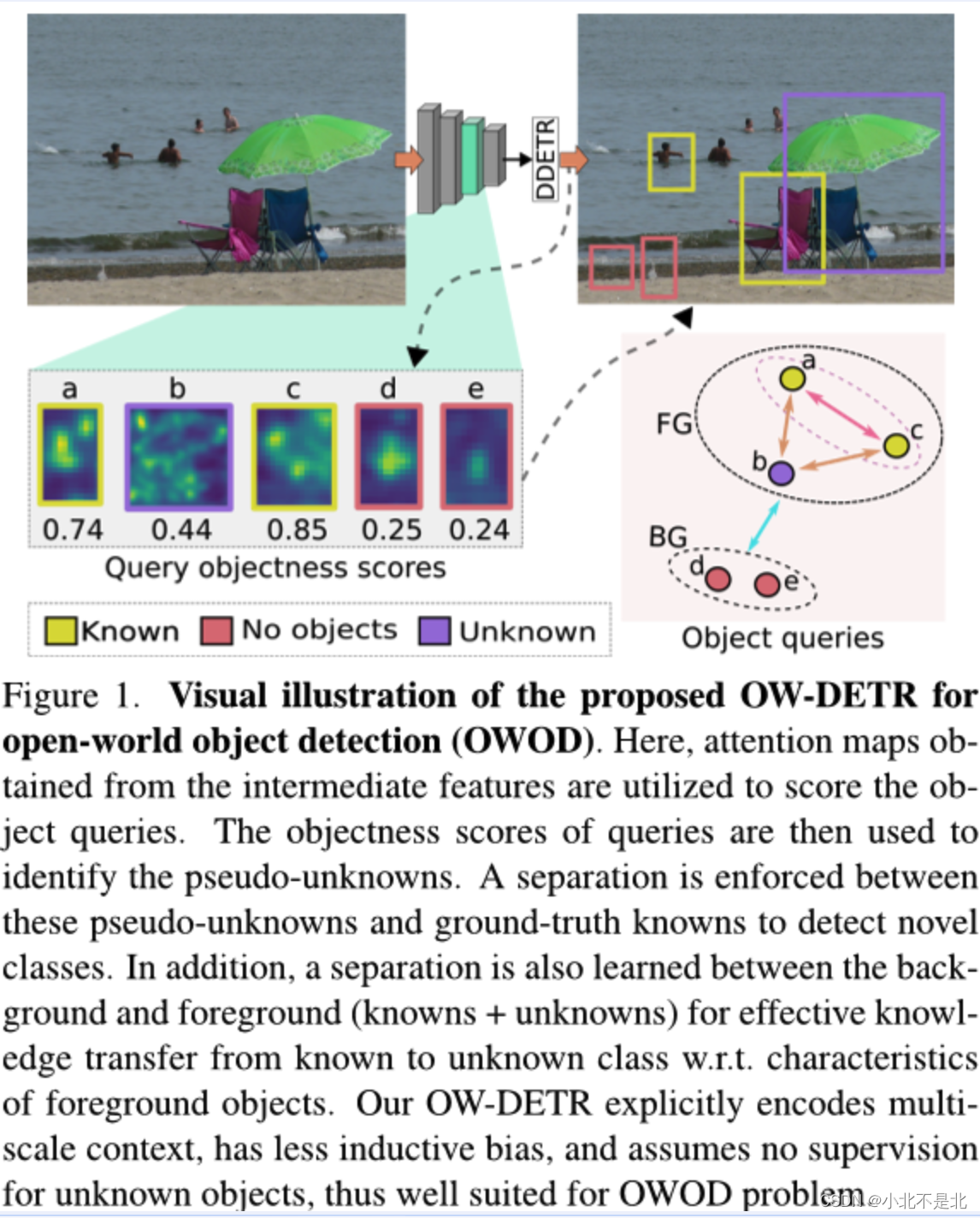 图一就是简单展示了一下作者是咋做的?实现思路是啥?
图一就是简单展示了一下作者是咋做的?实现思路是啥?
其实很简单,就是把图上物体分为三类:已知、未知、非物体(背景);其实区分最关键的是保证已知查全率,未知查准率,前景背景区分三部分
该作者就使用了最简单直接的思路——伪标签在训练的时候进行梳理并学习,就这样吧啦吧啦~流程见下图
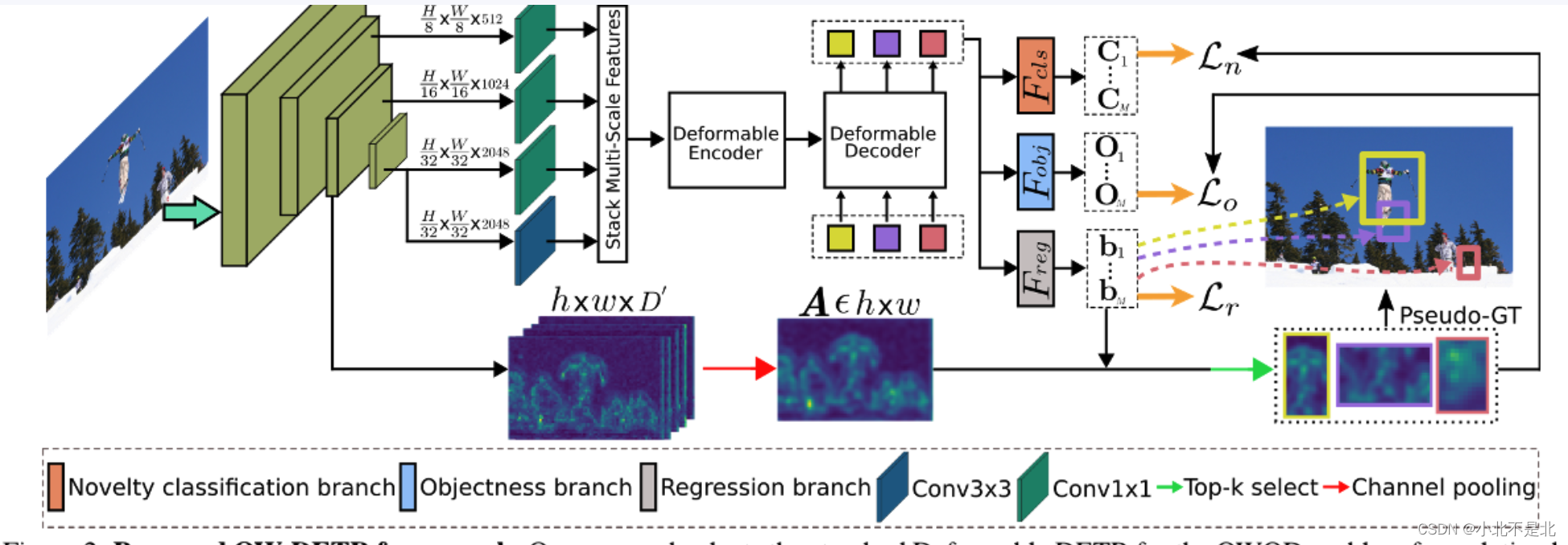 所提出的 OW-DETR 通过引入 (i) 一个基于注意力机制的伪标记机制,用于选择可能未知的查询候选者(建议这部分看代码吧~~~);(ii) 一个新颖性分类分支,用于学习将对象查询分为许多已知类别或未知类别的其中一种;以及 (iii) 一个“物体性”分支,用于学习将前景对象(ground-truth 知道且伪标记为未知实例)与背景区分开来。在所提出的 OW-DETR 中,输入图像 I 具有 H×W 的空间大小和一组对象实例 Y,由特征提取器提供支持。在不同的分辨率下获得 D 维多尺度特征,并将其馈入包含多尺度可变形注意模块的变换器编解码器。解码器使用交错的交叉注意和自注意模块对辅助 M 个可学习的对象查询进行转换,生成一组 M 个对象查询嵌入 qe∈ RD ,这些嵌入捕获了图像中的潜在对象实例。然后将qe馈入三个分支:边界框回归、新颖性分类和物体性。
所提出的 OW-DETR 通过引入 (i) 一个基于注意力机制的伪标记机制,用于选择可能未知的查询候选者(建议这部分看代码吧~~~);(ii) 一个新颖性分类分支,用于学习将对象查询分为许多已知类别或未知类别的其中一种;以及 (iii) 一个“物体性”分支,用于学习将前景对象(ground-truth 知道且伪标记为未知实例)与背景区分开来。在所提出的 OW-DETR 中,输入图像 I 具有 H×W 的空间大小和一组对象实例 Y,由特征提取器提供支持。在不同的分辨率下获得 D 维多尺度特征,并将其馈入包含多尺度可变形注意模块的变换器编解码器。解码器使用交错的交叉注意和自注意模块对辅助 M 个可学习的对象查询进行转换,生成一组 M 个对象查询嵌入 qe∈ RD ,这些嵌入捕获了图像中的潜在对象实例。然后将qe馈入三个分支:边界框回归、新颖性分类和物体性。
简介就到此~~~
二、OW-DETR复现
tnnd,恶心人的时候到了
按照源码流程复现一大堆错误——预训练权重问题、依赖包问题、pytorch问题吧啦吧啦一堆
完美复现流程为:
1、首先检查自己的CUDA与Pytorch是否是合理对应
nvcc -V :检查CUDA版本,如果不行就重新装吧,装的流程看官网:
CUDA Toolkit Archive | NVIDIA Developer
然后创建虚拟环境:
conda create -n owdetr python=3.8 -y
激活环境:
conda activate owdetr
安装torch:
Previous PyTorch Versions | PyTorch
torch这里可能会出问题,如果出现torchversion的问题把util下的misc.py换成下面代码:
# ------------------------------------------------------------------------
# Deformable DETR
# Copyright (c) 2020 SenseTime. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
# ------------------------------------------------------------------------
# Modified from DETR (https://github.com/facebookresearch/detr)
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
# ------------------------------------------------------------------------
"""
Misc functions, including distributed helpers.
Mostly copy-paste from torchvision references.
"""
import os
import subprocess
import time
from collections import defaultdict, deque
import datetime
import pickle
from typing import Optional, List
import torch
import torch.nn as nn
import torch.distributed as dist
from torch import Tensor
# needed due to empty tensor bug in pytorch and torchvision 0.5
import torchvision
class SmoothedValue(object):
"""Track a series of values and provide access to smoothed values over a
window or the global series average.
"""
def __init__(self, window_size=20, fmt=None):
if fmt is None:
fmt = "{median:.4f} ({global_avg:.4f})"
self.deque = deque(maxlen=window_size)
self.total = 0.0
self.count = 0
self.fmt = fmt
def update(self, value, n=1):
self.deque.append(value)
self.count += n
self.total += value * n
def synchronize_between_processes(self):
"""
Warning: does not synchronize the deque!
"""
if not is_dist_avail_and_initialized():
return
t = torch.tensor([self.count, self.total], dtype=torch.float64, device='cuda')
dist.barrier()
dist.all_reduce(t)
t = t.tolist()
self.count = int(t[0])
self.total = t[1]
@property
def median(self):
d = torch.tensor(list(self.deque))
return d.median().item()
@property
def avg(self):
d = torch.tensor(list(self.deque), dtype=torch.float32)
return d.mean().item()
@property
def global_avg(self):
return self.total / self.count
@property
def max(self):
return max(self.deque)
@property
def value(self):
return self.deque[-1]
def __str__(self):
return self.fmt.format(
median=self.median,
avg=self.avg,
global_avg=self.global_avg,
max=self.max,
value=self.value)
def all_gather(data):
"""
Run all_gather on arbitrary picklable data (not necessarily tensors)
Args:
data: any picklable object
Returns:
list[data]: list of data gathered from each rank
"""
world_size = get_world_size()
if world_size == 1:
return [data]
# serialized to a Tensor
buffer = pickle.dumps(data)
storage = torch.ByteStorage.from_buffer(buffer)
tensor = torch.ByteTensor(storage).to("cuda")
# obtain Tensor size of each rank
local_size = torch.tensor([tensor.numel()], device="cuda")
size_list = [torch.tensor([0], device="cuda") for _ in range(world_size)]
dist.all_gather(size_list, local_size)
size_list = [int(size.item()) for size in size_list]
max_size = max(size_list)
# receiving Tensor from all ranks
# we pad the tensor because torch all_gather does not support
# gathering tensors of different shapes
tensor_list = []
for _ in size_list:
tensor_list.append(torch.empty((max_size,), dtype=torch.uint8, device="cuda"))
if local_size != max_size:
padding = torch.empty(size=(max_size - local_size,), dtype=torch.uint8, device="cuda")
tensor = torch.cat((tensor, padding), dim=0)
dist.all_gather(tensor_list, tensor)
data_list = []
for size, tensor in zip(size_list, tensor_list):
buffer = tensor.cpu().numpy().tobytes()[:size]
data_list.append(pickle.loads(buffer))
return data_list
def reduce_dict(input_dict, average=True):
"""
Args:
input_dict (dict): all the values will be reduced
average (bool): whether to do average or sum
Reduce the values in the dictionary from all processes so that all processes
have the averaged results. Returns a dict with the same fields as
input_dict, after reduction.
"""
world_size = get_world_size()
if world_size < 2:
return input_dict
with torch.no_grad():
names = []
values = []
# sort the keys so that they are consistent across processes
for k in sorted(input_dict.keys()):
names.append(k)
values.append(input_dict[k])
values = torch.stack(values, dim=0)
dist.all_reduce(values)
if average:
values /= world_size
reduced_dict = {k: v for k, v in zip(names, values)}
return reduced_dict
class MetricLogger(object):
def __init__(self, delimiter="\t"):
self.meters = defaultdict(SmoothedValue)
self.delimiter = delimiter
def update(self, **kwargs):
for k, v in kwargs.items():
if isinstance(v, torch.Tensor):
v = v.item()
assert isinstance(v, (float, int))
self.meters[k].update(v)
def __getattr__(self, attr):
if attr in self.meters:
return self.meters[attr]
if attr in self.__dict__:
return self.__dict__[attr]
raise AttributeError("'{}' object has no attribute '{}'".format(
type(self).__name__, attr))
def __str__(self):
loss_str = []
for name, meter in self.meters.items():
loss_str.append(
"{}: {}".format(name, str(meter))
)
return self.delimiter.join(loss_str)
def synchronize_between_processes(self):
for meter in self.meters.values():
meter.synchronize_between_processes()
def add_meter(self, name, meter):
self.meters[name] = meter
def log_every(self, iterable, print_freq, header=None):
i = 0
if not header:
header = ''
start_time = time.time()
end = time.time()
iter_time = SmoothedValue(fmt='{avg:.4f}')
data_time = SmoothedValue(fmt='{avg:.4f}')
space_fmt = ':' + str(len(str(len(iterable)))) + 'd'
if torch.cuda.is_available():
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}',
'max mem: {memory:.0f}'
])
else:
log_msg = self.delimiter.join([
header,
'[{0' + space_fmt + '}/{1}]',
'eta: {eta}',
'{meters}',
'time: {time}',
'data: {data}'
])
MB = 1024.0 * 1024.0
for obj in iterable:
data_time.update(time.time() - end)
yield obj
iter_time.update(time.time() - end)
if i % print_freq == 0 or i == len(iterable) - 1:
eta_seconds = iter_time.global_avg * (len(iterable) - i)
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
if torch.cuda.is_available():
print(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time),
memory=torch.cuda.max_memory_allocated() / MB))
else:
print(log_msg.format(
i, len(iterable), eta=eta_string,
meters=str(self),
time=str(iter_time), data=str(data_time)))
i += 1
end = time.time()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('{} Total time: {} ({:.4f} s / it)'.format(
header, total_time_str, total_time / len(iterable)))
def get_sha():
cwd = os.path.dirname(os.path.abspath(__file__))
def _run(command):
return subprocess.check_output(command, cwd=cwd).decode('ascii').strip()
sha = 'N/A'
diff = "clean"
branch = 'N/A'
try:
sha = _run(['git', 'rev-parse', 'HEAD'])
subprocess.check_output(['git', 'diff'], cwd=cwd)
diff = _run(['git', 'diff-index', 'HEAD'])
diff = "has uncommited changes" if diff else "clean"
branch = _run(['git', 'rev-parse', '--abbrev-ref', 'HEAD'])
except Exception:
pass
message = f"sha: {sha}, status: {diff}, branch: {branch}"
return message
def collate_fn(batch):
batch = list(zip(*batch))
batch[0] = nested_tensor_from_tensor_list(batch[0])
return tuple(batch)
def _max_by_axis(the_list):
# type: (List[List[int]]) -> List[int]
maxes = the_list[0]
for sublist in the_list[1:]:
for index, item in enumerate(sublist):
maxes[index] = max(maxes[index], item)
return maxes
def nested_tensor_from_tensor_list(tensor_list: List[Tensor]):
# TODO make this more general
if tensor_list[0].ndim == 3:
# TODO make it support different-sized images
max_size = _max_by_axis([list(img.shape) for img in tensor_list])
# min_size = tuple(min(s) for s in zip(*[img.shape for img in tensor_list]))
batch_shape = [len(tensor_list)] + max_size
b, c, h, w = batch_shape
dtype = tensor_list[0].dtype
device = tensor_list[0].device
tensor = torch.zeros(batch_shape, dtype=dtype, device=device)
mask = torch.ones((b, h, w), dtype=torch.bool, device=device)
for img, pad_img, m in zip(tensor_list, tensor, mask):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
m[: img.shape[1], :img.shape[2]] = False
else:
raise ValueError('not supported')
return NestedTensor(tensor, mask)
class NestedTensor(object):
def __init__(self, tensors, mask: Optional[Tensor]):
self.tensors = tensors
self.mask = mask
def to(self, device, non_blocking=False):
cast_tensor = self.tensors.to(device, non_blocking=non_blocking)
mask = self.mask
if mask is not None:
assert mask is not None
cast_mask = mask.to(device, non_blocking=non_blocking)
else:
cast_mask = None
return NestedTensor(cast_tensor, cast_mask)
def record_stream(self, *args, **kwargs):
self.tensors.record_stream(*args, **kwargs)
if self.mask is not None:
self.mask.record_stream(*args, **kwargs)
def decompose(self):
return self.tensors, self.mask
def __repr__(self):
return str(self.tensors)
def setup_for_distributed(is_master):
"""
This function disables printing when not in master process
"""
import builtins as __builtin__
builtin_print = __builtin__.print
def print(*args, **kwargs):
force = kwargs.pop('force', False)
if is_master or force:
builtin_print(*args, **kwargs)
__builtin__.print = print
def is_dist_avail_and_initialized():
if not dist.is_available():
return False
if not dist.is_initialized():
return False
return True
def get_world_size():
if not is_dist_avail_and_initialized():
return 1
return dist.get_world_size()
def get_rank():
if not is_dist_avail_and_initialized():
return 0
return dist.get_rank()
def get_local_size():
if not is_dist_avail_and_initialized():
return 1
return int(os.environ['LOCAL_SIZE'])
def get_local_rank():
if not is_dist_avail_and_initialized():
return 0
return int(os.environ['LOCAL_RANK'])
def is_main_process():
return get_rank() == 0
def save_on_master(*args, **kwargs):
if is_main_process():
torch.save(*args, **kwargs)
def init_distributed_mode(args):
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
args.dist_url = 'env://'
os.environ['LOCAL_SIZE'] = str(torch.cuda.device_count())
elif 'SLURM_PROCID' in os.environ:
proc_id = int(os.environ['SLURM_PROCID'])
ntasks = int(os.environ['SLURM_NTASKS'])
node_list = os.environ['SLURM_NODELIST']
num_gpus = torch.cuda.device_count()
addr = subprocess.getoutput(
'scontrol show hostname {} | head -n1'.format(node_list))
os.environ['MASTER_PORT'] = os.environ.get('MASTER_PORT', '29500')
os.environ['MASTER_ADDR'] = addr
os.environ['WORLD_SIZE'] = str(ntasks)
os.environ['RANK'] = str(proc_id)
os.environ['LOCAL_RANK'] = str(proc_id % num_gpus)
os.environ['LOCAL_SIZE'] = str(num_gpus)
args.dist_url = 'env://'
args.world_size = ntasks
args.rank = proc_id
args.gpu = proc_id % num_gpus
else:
print('Not using distributed mode')
args.distributed = False
return
args.distributed = True
torch.cuda.set_device(args.gpu)
args.dist_backend = 'nccl'
print('| distributed init (rank {}): {}'.format(
args.rank, args.dist_url), flush=True)
torch.distributed.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
torch.distributed.barrier()
setup_for_distributed(args.rank == 0)
@torch.no_grad()
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
if target.numel() == 0:
return [torch.zeros([], device=output.device)]
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def interpolate(input, size=None, scale_factor=None, mode="nearest", align_corners=None):
# type: (Tensor, Optional[List[int]], Optional[float], str, Optional[bool]) -> Tensor
"""
Equivalent to nn.functional.interpolate, but with support for empty batch sizes.
This will eventually be supported natively by PyTorch, and this
class can go away.
"""
if float(torchvision.__version__[:3]) < 0.7:
if input.numel() > 0:
return torch.nn.functional.interpolate(
input, size, scale_factor, mode, align_corners
)
output_shape = _output_size(2, input, size, scale_factor)
output_shape = list(input.shape[:-2]) + list(output_shape)
if float(torchvision.__version__[:3]) < 0.5:
return _NewEmptyTensorOp.apply(input, output_shape)
return _new_empty_tensor(input, output_shape)
else:
return torchvision.ops.misc.interpolate(input, size, scale_factor, mode, align_corners)
def get_total_grad_norm(parameters, norm_type=2):
parameters = list(filter(lambda p: p.grad is not None, parameters))
norm_type = float(norm_type)
device = parameters[0].grad.device
total_norm = torch.norm(torch.stack([torch.norm(p.grad.detach(), norm_type).to(device) for p in parameters]),
norm_type)
return total_norm
def inverse_sigmoid(x, eps=1e-5):
x = x.clamp(min=0, max=1)
x1 = x.clamp(min=eps)
x2 = (1 - x).clamp(min=eps)
return torch.log(x1/x2)
安装依赖包:
pip install -r requiments.txt
这里很多包没有在里面,如pandas,,,,,(自行根据提示安装吧,这里很简单)
之后就会出现多尺度注意力机制的问题了,前面torch问题解决这里才能使用:
cd ./models/ops
sh ./make.sh
对了,如果运行有问题的话可以考虑把setup.py换成我改之后的:
import os
import glob
import torch
from torch.utils.cpp_extension import CUDA_HOME
from torch.utils.cpp_extension import CppExtension
from torch.utils.cpp_extension import CUDAExtension
from setuptools import find_packages
from setuptools import setup
requirements = ["torch", "torchvision"]
def get_extensions():
this_dir = os.path.dirname(os.path.abspath(__file__))
extensions_dir = os.path.join(this_dir, "src")
main_file = glob.glob(os.path.join(extensions_dir, "*.cpp"))
source_cpu = glob.glob(os.path.join(extensions_dir, "cpu", "*.cpp"))
source_cuda = glob.glob(os.path.join(extensions_dir, "cuda", "*.cu"))
sources = main_file + source_cpu
extension = CppExtension
extra_compile_args = {"cxx": []}
define_macros = []
include_dirs = [extensions_dir]
if torch.cuda.is_available() and CUDA_HOME is not None:
extension = CUDAExtension
sources += source_cuda
define_macros += [("WITH_CUDA", None)]
extra_compile_args["nvcc"] = [
"-DCUDA_HAS_FP16=1",
"-D__CUDA_NO_HALF_OPERATORS__",
"-D__CUDA_NO_HALF_CONVERSIONS__",
"-D__CUDA_NO_HALF2_OPERATORS__",
]
# 添加 CUDA 头文件路径
include_dirs.append(os.path.join(CUDA_HOME, "include"))
else:
raise NotImplementedError('Cuda is not available')
sources = [os.path.join(extensions_dir, s) for s in sources]
ext_modules = [
extension(
"MultiScaleDeformableAttention",
sources,
include_dirs=include_dirs,
define_macros=define_macros,
extra_compile_args=extra_compile_args,
library_dirs=[os.path.join(CUDA_HOME, 'lib64')], # 添加 CUDA 库路径
libraries=['cudart'] # 链接 CUDA 运行时库
)
]
return ext_modules
setup(
name="MultiScaleDeformableAttention",
version="1.0",
author="Weijie Su",
url="https://github.com/fundamentalvision/Deformable-DETR",
description="PyTorch Wrapper for CUDA Functions of Multi-Scale Deformable Attention",
packages=find_packages(exclude=("configs", "tests",)),
ext_modules=get_extensions(),
cmdclass={"build_ext": torch.utils.cpp_extension.BuildExtension},
)
下载预训练权重:
接下来是下载预训练权重部分,原作者使用了Deformable-DETR主干预训练权重
dino_resnet50_pretrain.pth:https://dl.fbaipublicfiles.com/dino/dino_resnet50_pretrain/dino_resnet50_pretrain.pth
接下来就按照原作者的就OK了
三、运行成功截图
还改了一堆代码才运行起来自己的数据集,但是性能暂时还在跑,先放个运行成功截图



















 3523
3523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











