






一、为什么要学习自研RPC框架这套课程?

其实,很多大厂都有一套自研的RPC框架,这无形当中会增加对面试者的要求,那就是要掌握RPC的基础知识,基本原理,具备一定的开发经验,这样,你才能更快的掌握大厂的核心业务系统,甚至参与大厂核心RPC框架的研发工作,并且你掌握的越深入,你的薪资基本上也会越高。众所周知,大厂无论是在用户体量还是在业务规模上,体量都是比较大的,并且一整套系统中都会拆分成很多的服务,甚至不同的业务线之间的系统也会存在数据之间的交互。这就需要有一套成熟、稳定,并且性能高效的RPC框架作为多个服务、甚至是不同业务线的多套系统之间的底层通信设施。
所以,一般大厂都会基于自身业务的特点,自研符合自身发展需求的RPC框架。比如阿里的Dubbo、微博的Motan、腾讯的Tars、谷歌的gRPC、Facebook的Thrift都是业界比较出名的RPC框架。就拿阿里的Dubbo来说,被广泛应用于整个集团内部众多服务之间的底层通信上。如果你想进阿里、微博、腾讯、谷歌、Facebook等这些大厂,如果你已经深度掌握了像Dubbo、Motan、Tars、gRPC和Thrift等RPC框架,并且你还能从0到1自研一套RPC框架,这无疑会是你的加分项,因为从招聘者角度上来讲,大厂还是比较倾向于招聘已经深度掌握自身公司开源框架的候选人,如果你还能自研,那说明你的技术能力绝对是没有问题的,同学们要知道一点,中间件这块的人才是很稀缺的。
深入理解RPC原理和实现
自研RPC框架要求开发者从头开始设计和实现一个RPC系统,这包括通信协议的设计、服务注册与发现、负载均衡、容错处理等。通过这个过程,同学们可以深入理解RPC的基本原理和实现细节,从而掌握RPC框架的核心技术。
提升编程和架构能力
自研RPC框架需要开发者具备扎实的编程基础和良好的系统设计能力。在实现过程中,开发者需要设计合理的接口、处理各种边界情况、优化性能,这有助于提升个人的编程技能和系统设计能力。
增强解决问题的能力
在自研过程中,开发者会遇到各种技术问题和挑战,如网络通信问题、并发控制、安全性等。通过解决这些问题,可以锻炼和提高解决问题的能力,积累宝贵的经验。拓宽技术视野
自研RPC框架不仅要求掌握RPC技术本身,还需要了解相关的技术趋势和发展方向,如微服务架构、容器化部署等。这有助于拓宽技术视野,为未来的技术选择和发展方向提供参考。
增加就业竞争力
具备自研RPC框架经验的开发者在求职市场上具有较高的竞争力。许多大厂在招聘时倾向于选择有自研经验的人才,因为这表明候选人具备独立解决问题和创新能力。
二、自研RPC这门课程你能学到什么?
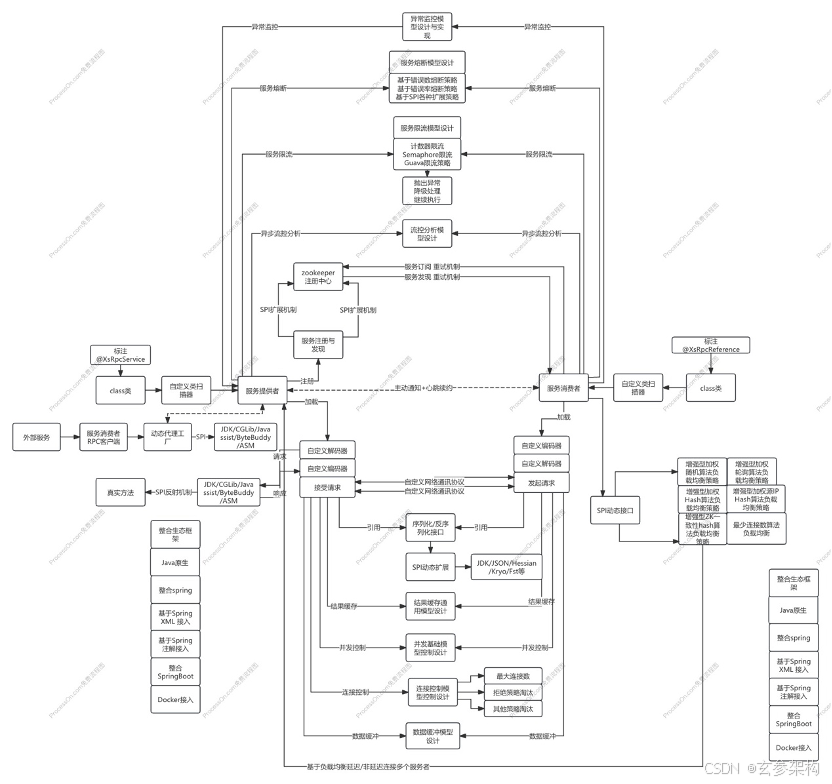
在分布式或微服务环境中,不同服务之间如何进行通信,这是个值得思考的问题。在早期的分布式系统中,一般是通过在服务消费者一端手动配置服务提供者的地址列表,如果服务提供者的地址列表发生变化之后,还要手动修改服务消费者中配置的服务提供者的地址,之后要重启服务消费者才能使配置生效。后来可以通过服务消费者HTTP请求调用、保存服务提供者的地址列表,由程序开发人员在服务消费者中主动感知服务提供者暴露的服务信息,这就造成了服务消费者与服务提供者之间严重的耦合问题。正式由于分布式系统中存在着这些问题,注册中心诞生了。在RPC框架中,主要使用注册中心实现服务的注册与发现。服务提供者上线后将自身的服务列表注册到注册中心,当服务提供者下线时,从注册中心中移除自身的服务列表。服务消费者上线后,向注册中心订阅服务提供和的服务列表,然后通过负载均衡算法选择其中一个服务节点进行调用。涉及功能点:自定义注解、自定义包扫描类、自定义协议、自定义请求与响应协议的封装、自定义服务提供者、自定义服务消费者、整合注册中心
RPC框架最主要的功能就是实现RPC远程过程调用,涉及到远程过程调用,那就一定是通过网络进行的,此时就必须通过某种网络通信协议进行数据交互,需要考虑采用哪些方式实现数据的编解码。由于在分布式系统中,对RPC框架有着极高的性能要求,所以,在RPC框架中,网络通信协议的实现越简单越好,尽可能减少数据编解码和在网络传输过程中的性能损耗。通用的网络协议有HTTP、TPC、UDP等,RPC框架可以基于这些通用的网络通信协议实现,也可以根据实际需求,实现自定义的网路通信协议。涉及功能点:自定义网络通讯协议,自定义网络传输编码,自定义网络传输解码器
说到RPC的调用方式,可能很多小伙伴不是很了解,RPC不就是远程过程调用吗?还能有什么调用方式啊?其实一个成熟的RPC框架,例如Dubbo等会提供四种不同的调用方式,我们自研集成:同步调用(Sync)、异步调用(Future)、回调(Callback)、单向调用(Oneway)。在我们的课程当中都会全部去实现
RPC框架能够使得开发人员像调用本地服务一样调用远程服务,这得益于动态代理技术。可以这么说,几乎每一款成熟并且完善的RPC框架都离不开动态代理技术。利用动态代理技术创建一个代理对象,在代理对象中完成数据的编码操作,发起远程调用,将数据发送给服务提供者,接收从服务提供者返回的数据,进行解码等操作。代理对象屏蔽了RPC框架底层的调用细节。
RPC框架离不开动态代理技术,并且代理对象是在程序运行时动态生成的,所以生成代理类的速度和字节码大小都会影响到RPC框架的整体性能以及对系统资源的消耗程度,所以,选择动态代理技术时需要综合考虑生成代理类的速度和生成的字节码大小。自研集成JDK 动态代理、集成Cglib、集成Javassist、集成ASM、集成Byte Buddy。
在分布式系统中,往往服务提供者和服务消费者都不会存在单点的情况,二者在实现上都会存在多个节点,那服务消费者如何从多个服务提供者节点中选择一个进行远程调用呢?这就要求RPC框架在实现上支持负载均衡。在我们自研RPC框架的实现中,负载均衡策略和算法也是影响RPC框架吞吐量的一个重要因素。常用的负载均衡算法包括:轮询(Round-Robin)、加权轮询(Weighted Round-Robin)、最少连接数(Least Connections)、一致性Hash(Consistent Hash)。
为防止由于断网、系统宕机、程序崩溃等问题造成的注册中心一直残留无效服务列表的问题,在引入注册中心时,要采取 主动通知+心跳检测 的方案。具体实现的方案就是 :当服务提供者上线时,主动将自身提供的服务列表注册到注册中心;当服务提供者下线时,主动自身注册到注册中心的服务列表。除此之外,需要实现心跳检测的方案,心跳检测可以在服务提供者实现,也可以由注册中心实现。例如,注册中心可以每隔30秒向服务提供者发送一次心跳检测,如果连续3次未收到服务提供者的响应,则认为该服务提供者已经下线,将其注册到注册中心的服务列表移除,并通知服务消费者服务列表发生了变化。采用主动通知+心跳检测的方案,当服务提供者或者服务消费者发生变化时,无需重启任何服务即可快速实现服务的注册与发现功能。
服务消费者在启动时,会连接注册中心,从注册中心中获取服务提供者元数据列表,再根据一定的负载均衡策略从服务提供者元数据列表中获取一个服务提供者元数据,进而与服务提供者建立连接进行数据交互。
当服务消费者启动时,由于网络问题或者注册中心宕机,以及服务提供者宕机或者未启动服务提供者时,服务消费者无法正常从注册中心获取服务提供者元数据。此时就需要服务消费者去重试连接注册中心来获取服务提供者元数据。所以,对于RPC框架来说,服务消费者需要实现服务订阅的重试机制。
RPC框架一个最基本的规则就是:服务消费者从注册中心获取到多个服务提供者列表时,能够根据一定的负载均衡规则从多个服务提供者列表中获取某个服务提供者,与其建立连接进行数据通信。
试想这样一种场景:有个系统使用了我们自己手写的RPC框架,需要进行灰度发布,服务消费者需要定向连接某个服务提供者进行数据通信,那这种场景怎么实现呢?此时,就需要我们自己手写的RPC框架要支持服务消费者直连服务提供者的功能。同时,RPC框架只支持服务消费者直连一个服务提供者是远远不够的,这样不但限制了直连的服务提供者的扩展性,在高并发场景下,服务消费者发起的调用量过大时,还有可能压垮服务提供者。所以,在服务消费者端需要支持直连多个服务提供者。当服务消费者直连多个服务提供者时,可以根据一定的负载均衡策略,从直连的多个服务提供者中,选择一个服务提供者,与其建立网络连接进行数据交互。
服务消费者延迟连接服务提供者,也就是说,当服务消费者启动时,服务消费者并不会连接服务提供者。而是当服务消费者向服务提供者首次发起请求时,服务消费者才会连接对应的服务提供者,这样做的目的是为了防止服务消费者启动后就与服务提供者建立了连接,但是服务消费者和服务提供者之间很长时间都没有数据交互,这就白白浪费了系统的连接资源。
比较成熟和完善的RPC框架,在设计上会将耗时的方法调用和远程通信放到一个单独的线程中执行,但也不是每次调用方法时都会创建一个线程。如果每次调用方法都创建一个线程,在高并发大流量的场景下,就会导致创建大量的线程,线程之前会频繁的切换,极大的影响RPC框架的性能,同时,也会耗费大量的系统资源。所以,在设计上会将耗时的方法调用和远程通信放到一个线程池中执行,并且出于扩展性的考虑,也为了后续能够方便对RPC框架的性能调试,可以将线程池中创建的线程数进行控制,进而控制RPC框架的并发性能。
为了更好的设计连接控制的基础模型,我们将整个连接控制模型分为两个部分,第一个部分就是连接的拒绝策略,也就是连接数过多时,我们使用什么样的策略对连接进行处理。第二部分就是连接管理,在连接管理部分会对淘汰策略进行封装,对外统一提供连接管理的方法进行调用。同时,为了使RPC框架支持更好的扩展性,另外,在整体对外配置上,会提供最大连接数和淘汰策略两个基础配置。
自研RPC框架必须要能扛得住流量的洪峰,如果在高并发、大流量的业务场景下,服务提供者会并发收到大量的请求,如果同时调用的请求量过大,就会造成服务提供者卡顿,有时甚至会出现丢失请求的情况。服务消费者也是如此,当并发接收到大量服务提供者返回的结果数据时,也可以使用数据缓冲增强稳定性。
用最直白的话说,服务容错就是服务具备一定的错误兼容能力,能够对一些异常情况进行兼容处理。例如,自研RPC框架如果在高并发、大流量的业务场景下,难免会出现由于网络故障或者业务异常导致的调用失败的情况。但是,在真实的业务场景下,往往又需要对这些异常情况进行处理,需要RPC框架具备一定的服务容错能力。
限流是指在使用缓存和降级无效的场景。比如当达到阈值后限制接口调用频率,访问次数,库存个数等,在出现服务不可用之前,提前把服务降级。只服务好一部分用户。可以这么说,任何一个系统都不可能无限制承载任何流量,总有一个上限,当系统的承载能力超过一定的上限(阈值)时,往往就会出现性能下降,甚至是宕机的风险。所以,在实际生产环境中,往往需要对系统进行限流等高可用措施。同时,我们会基于SPI扩展Semaphore,Guava限流策略,同时,服务提供者和服务消费者都实现了服务限流,当触发服务限流时,如果服务没有获取到对应的资源,那此时就需要触发一种规则来继续执行当前的处理逻辑,比如:是继续向下执行逻辑?抛出异常?还是进行降级处理?这些都是需要在RPC框架中进行处理的。
第十五阶段:自研服务熔断设计与实现
服务熔断是自研RPC必不可少的功能,一般是指调用方访问服务时通过断路器做代理进行访问,断路器在一段时间内会持续观察服务返回的成功、失败的状态,当失败的次数或者百分比超过设置的阈值时断路器打开,请求就不能真正地访问到服务了,而是通过降级的方式直接返回本地方法或者缓存中的数据。
我们自己写的RPC框架也可以实现流控分析,可以整合第三方分析系统,也能够显示到流量大屏。由于我们写的RPC框架是一个通用型、底层网络传输框架,我们并不会将流控分析的具体逻辑写死到代码中。而是会借鉴Spring的后置处理器思想,将流控分析作为一个重要的扩展点,将流控分析的功能高度抽象为一个后置处理器接口,并且只要实现了这个后置处理器接口的方法,就能够自动获取到每次RPC调用的流量信息和请求信息。同时,后置处理器的实现类自动获取到调用的流量信息后,具体的实现逻辑可根据具体业务场景而定,比如:投放到流量大屏、接入第三方流控系统、结合流量分析进行限流、熔断和系统降级等等,都可以作为流控分析后置处理器的实现逻辑。
一个成熟的RPC框架,肯定需要设计与实现集成各种常见的生态框架,比如常见的Spring、SpringBoot、Docker、SpringCloud Alibaba。我们这个自研RPC框架都会去完善,并且后面会基于SpringCloud Alibaba整合一个小型的电商demo出来,最终目的,还是让大家知道,整合RPC生态框架是怎么玩的
我们在设计与实现会提前埋一些坑进去,使各位同学在调试代码的过程中,能够自己去发现问题,并且分析问题,最好也能够自己解决问题。经过自己发现问题->分析问题->解决问题的过程,能够提升大家对于RPC框架源码的参与过程,更重要的是,能够不断提升大家自己发现问题、分析问题和解决问题的能力,这种能够力才是程序员最核心的竞争力。
第十九阶段:课程总结

















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









