






目录
一、什么是PCA?
主成分分析(PCA)是一种常用的数据降维技术,它可以将高维数据集转换为低维数据集,同时保留数据集中的主要特征。
二、如何实现PCA?
PCA的核心思想是通过找到数据中的主成分或主要特征,来实现降维。
(一)数据标准化
对原始数据进行标准化处理,使每个特征的均值为0,标准差为1,以消除不同尺度带来的影响。
可参考如下方法实现:
# 标准化数据(均值为0,标准差为1)
data_mean = np.mean(data, axis=0) # 计算每列的均值
data_std = np.std(data, axis=0) # 计算每列的标准差
data_standardized = (data - data_mean) / data_std # 标准化数据(二)计算协方差矩阵
(1)协方差
协方差(covariance)是用来衡量两个随机变量之间的关联程度。协方差矩阵将所有变量两两之间的协方差组合成一个矩阵。如果有n个变量,那么协方差矩阵就是一个n×n的矩阵。
(2)协方差矩阵
协方差矩阵C的第i行第j列的元素表示第i个变量与第j个变量的协方差。
具体地,假设有变量X和Y,它们的样本数量为N,样本数据分别为(x₁, y₁), (x₂, y₂), ..., (xₙ, yₙ)。则协方差矩阵C的第i行第j列的元素可以通过以下公式计算得出:
Cᵢⱼ = cov(X, Y) = (Σ((xₖ - μₓ)(yₖ - μᵧ))) / (N - 1)
其中,μₓ和μᵧ分别为变量X和Y的样本均值。
协方差矩阵的对角线元素是各个变量的方差,非对角线元素是各个变量之间的协方差。
协方差矩阵在数据分析中具有重要的意义,它能够提供关于变量之间关系的信息。例如,在主成分分析(PCA)中,协方差矩阵用于计算特征向量和特征值,从而找到数据的主要成分。
# 计算协方差矩阵
cov_matrix = np.cov(data_standardized.T)(三)特征值分解
特征值分解就是对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
eig_values, eig_vectors = np.linalg.eig(cov_matrix)(四)选取主要成分
按照特征值从大到小的顺序,选择最大的k个特征值对应的特征向量作为主要成分。本次我们在四个特征中选取两个主要成分
# 按特征值从大到小排序特征向量
sorted_index = np.argsort(eig_values)[::-1] # 对特征值从大到小排序,并获取排序后的索引
sorted_eig_vectors = eig_vectors[:, sorted_index] # 按排序后的索引重新排列特征向量
# 选择前两个主要成分
n_components = 2 # 要选择的主成分个数
pca_components = sorted_eig_vectors[:, :n_components] # 获取前两个主成分
(五)数据投影
将原始数据投影到选定的主要成分上,得到降维后的数据集。
ransformed_data = np.dot(data_standardized, pca_components) # 投影到新的主成分空间
三、实验结果展示
plt.scatter(transformed_data[:, 0], transformed_data[:, 1]) # 绘制散点图
# 为每个点添加标签
for i, txt in enumerate(range(len(data))):
plt.annotate(txt, (transformed_data[i, 0], transformed_data[i, 1]))
# 添加标题和坐标轴标签
plt.title('PCA of Mammals')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.grid(True) # 显示网格
plt.show() # 显示图形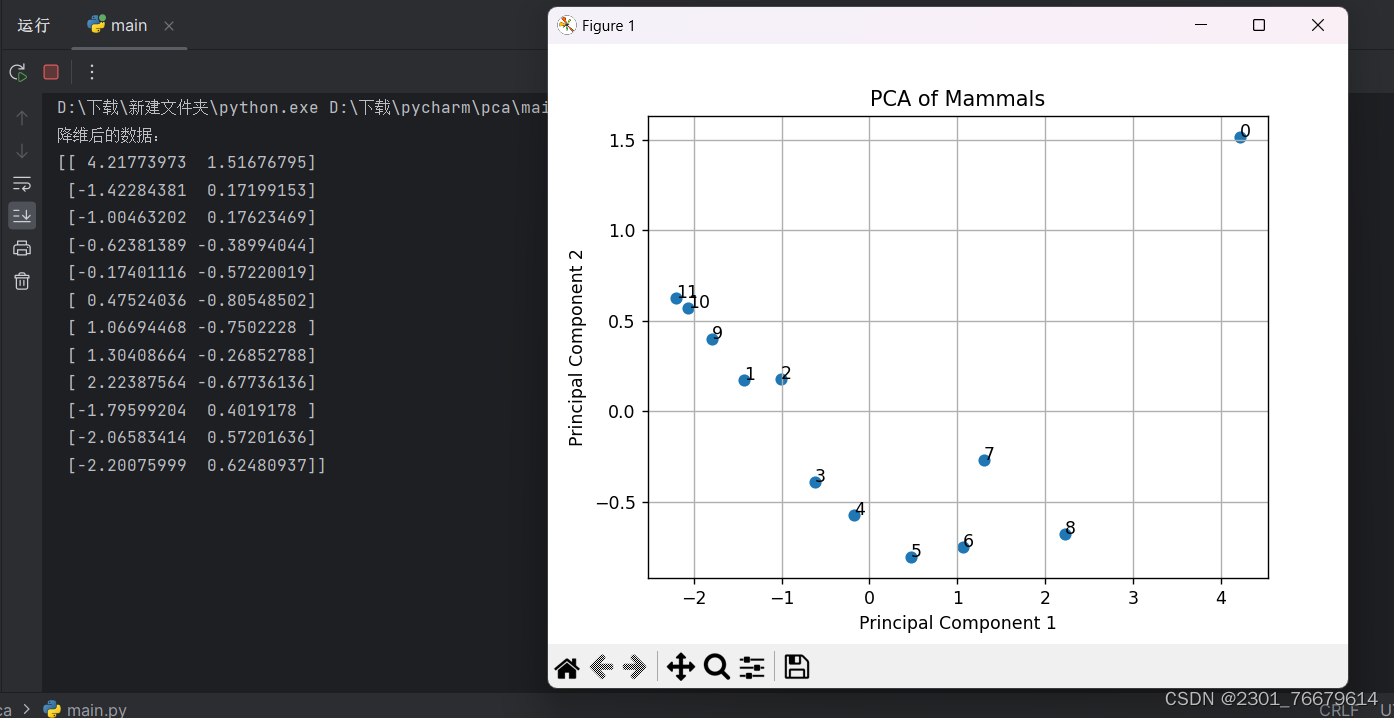
四、实验总结
优点
1.降维:PCA可以有效地将高维数据集转换为低维数据集,从而减少计算复杂度、存储需求和处理时间。
2.去除噪声:通过保留主要成分(即解释数据方差最大的方向),PCA可以帮助去除数据中的噪声,提升模型的性能。
3.提高可视化效果:PCA可以将高维数据投影到二维或三维空间,便于数据的可视化和理解。
4.特征选择:PCA可以识别出数据中最重要的特征,有助于特征选择和特征工程。
5.减少多重共线性:在回归分析中,PCA可以通过生成不相关的主成分来减少变量之间的多重共线性问题。
缺点
1.解释性较差:PCA生成的主成分是线性组合,可能难以解释这些新特征的实际意义,尤其是当原始特征具有明确物理或业务含义时。
2.假设线性关系:PCA假设数据中存在线性关系。因此,对于非线性数据,PCA的效果可能不佳,此时可能需要非线性降维方法如t-SNE或UMAP。
3.方差解释偏好:PCA关注的是最大化方差的方向,但这不一定等同于对任务最有用的特征。例如,在分类任务中,最能区分类别的特征不一定对应于方差最大的方向。
4.敏感性:PCA对数据的缩放很敏感,因此在应用PCA之前,需要标准化数据。如果不同特征有不同的量级,PCA的结果可能会受到较大影响。
5.信息损失:虽然PCA尽可能保留数据的主要信息,但不可避免地会丢失一些信息,特别是在降维幅度较大的情况下。
总的来说,PCA是一种功能强大的工具,但在使用它时必须考虑其局限性和适用条件,以确保其应用效果最佳。
五、总体代码展示
import numpy as np
import matplotlib.pyplot as plt
# 创建哺乳动物数据集
data = np.array([
[600, 150, 70, 60],
[20, 30, 5, 20],
[40, 40, 10, 25],
[50, 60, 6, 35],
[70, 80, 8, 40],
[100, 100, 12, 50],
[200, 110, 15, 55],
[300, 120, 18, 45],
[400, 130, 20, 65],
[10, 25, 3, 10],
[5, 15, 2, 5],
[3, 10, 1, 3]
])
# 标准化数据(均值为0,标准差为1)
data_mean = np.mean(data, axis=0)
data_std = np.std(data, axis=0)
data_standardized = (data - data_mean) / data_std
# 计算协方差矩阵
cov_matrix = np.cov(data_standardized.T)
# 计算特征值和特征向量
eig_values, eig_vectors = np.linalg.eig(cov_matrix)
# 按特征值从大到小排序特征向量
sorted_index = np.argsort(eig_values)[::-1]
sorted_eig_vectors = eig_vectors[:, sorted_index]
# 选择前两个主要成分
n_components = 2
pca_components = sorted_eig_vectors[:, :n_components]
# 将数据转换到新空间
transformed_data = np.dot(data_standardized, pca_components)
# 打印降维后的数据
print("降维后的数据:")
print(transformed_data)
# 将降维后的数据在二维坐标轴中打印出来
plt.scatter(transformed_data[:, 0], transformed_data[:, 1])
for i, txt in enumerate(range(len(data))):
plt.annotate(txt, (transformed_data[i, 0], transformed_data[i, 1]))
plt.title('PCA of Mammals')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.grid(True)
plt.show()

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









