






如何用python Request发送请求
import requests
response=requests.get("http://books.toscrape.com/')
print(response)
print(response.status_code)
图片: 
如果状态码等于200,说明请求成功
如果是404则要检查传入的URL是否存在问题。
import requests
response=requests.get("http://books.toscrape.com/")
if response.ok:
print(response.text) #获取响应内容
else:
print("请求失败")
请求成功则打印text网页结果
传入head进行修改
想指定某些信息进行更改可传入head进行修改
如:可以帮我们把爬虫程序伪装成正常浏览器
用python requests拿到豆瓣源码
import requests
response=requests.get("https://movie.douban.com/top250")
print(response.status_code)
获取失败,如下图所示
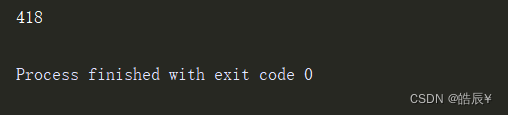
豆瓣回应爬虫,它希望服务正常的浏览器,忽略所有爬虫的请求
可以通过定义请求头,把程序伪装成浏览器
新建一个headers的字典变量
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36"
}
user-Agent 里面的值可随便查看一个浏览器审查元素->查看网络->复制一个user-Agent的值
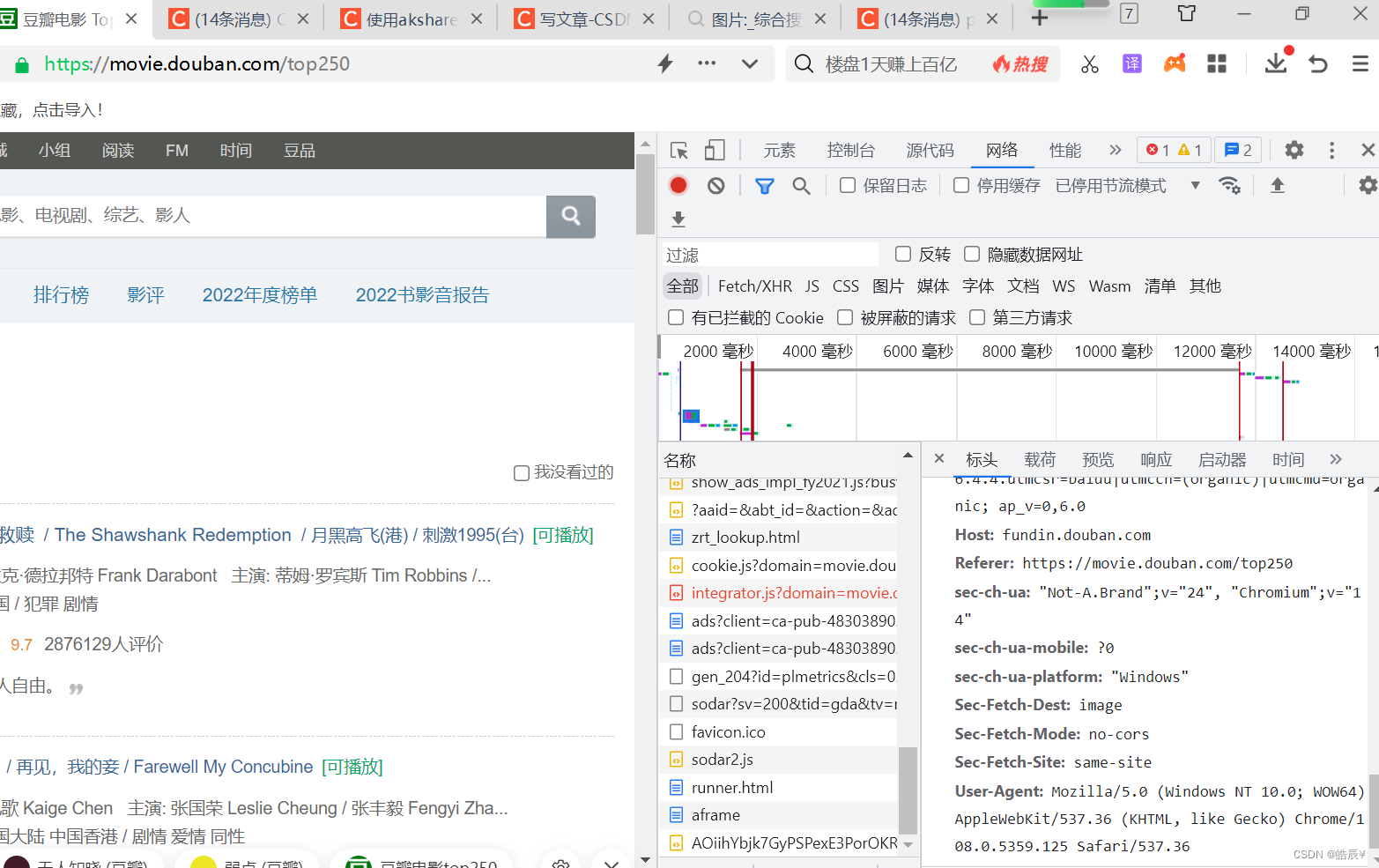
运行后状态码为200,说明正常
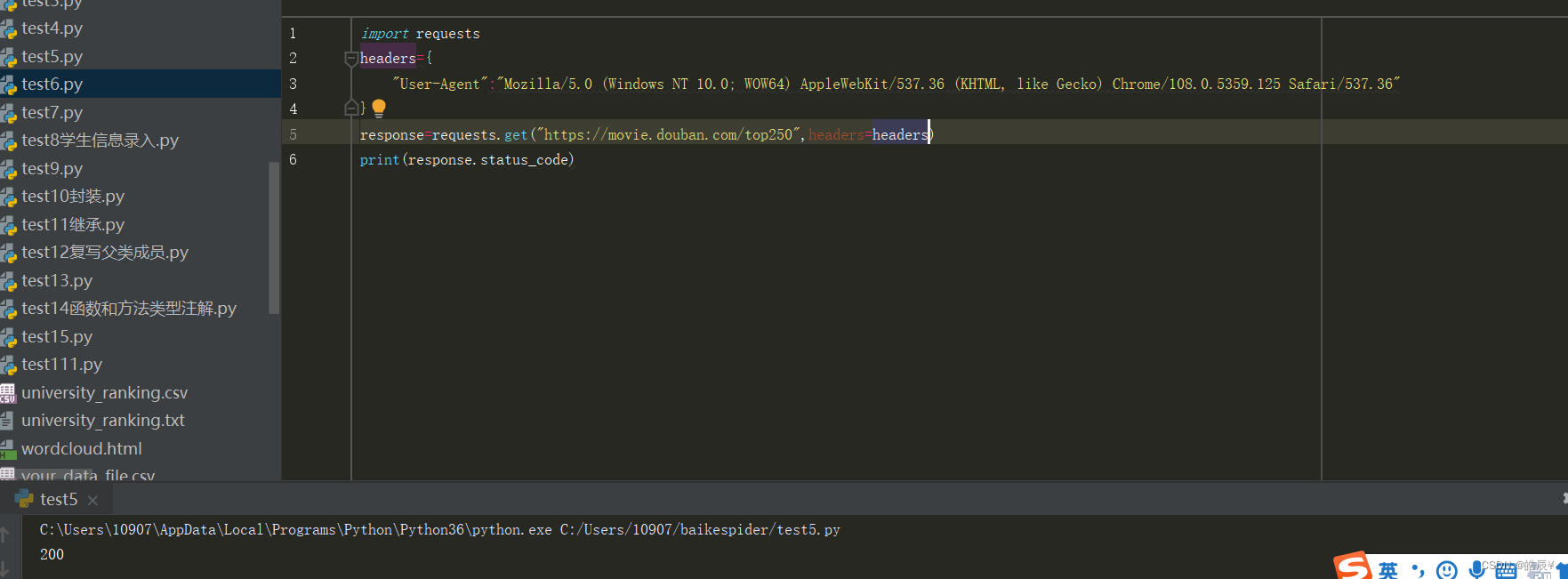
同时打印反馈的文本内容,成功获取豆瓣的网页内容,如下图:
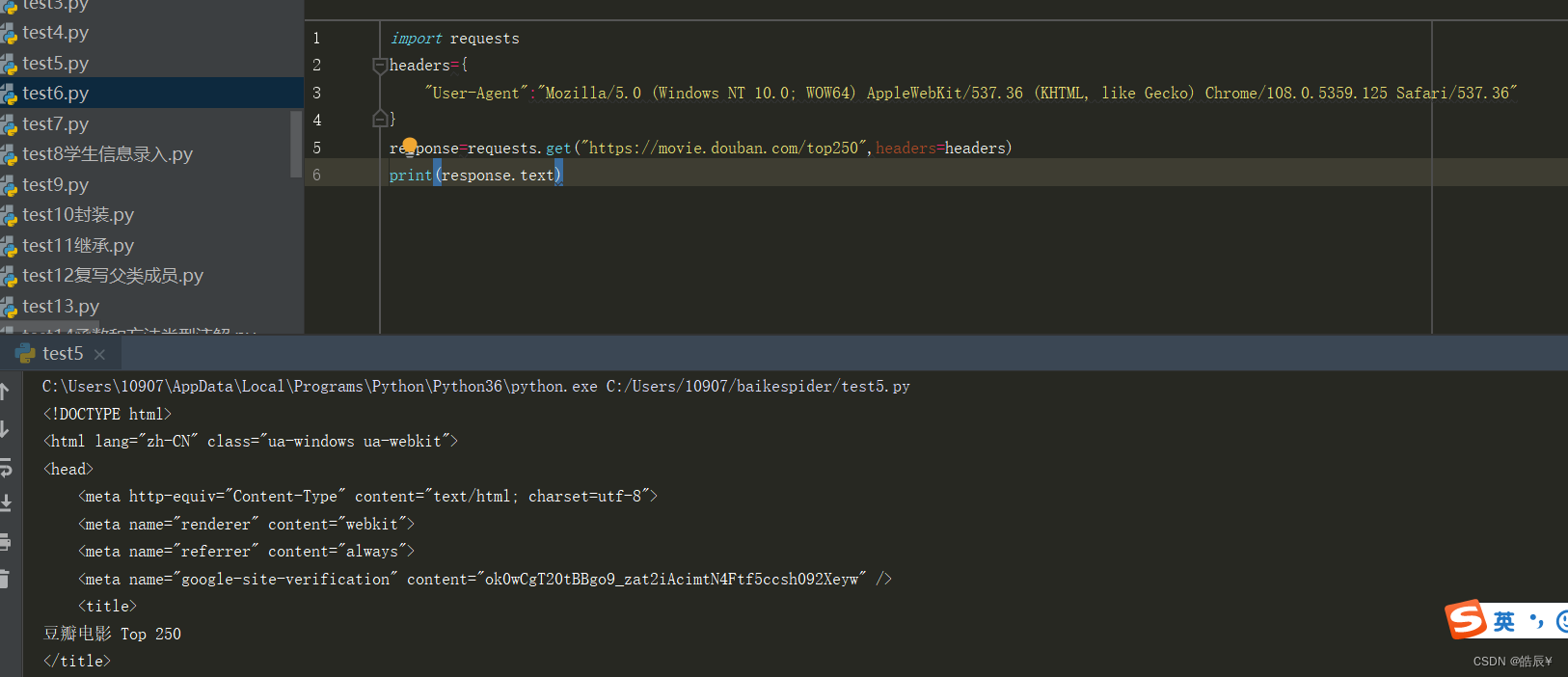
但是html内容看的一头雾水,还需要进一步操作
html常见标签
h1一级标题
h2二级标题
p文本标签
img图片
href链接
ol有序列表,里面每个元素用li 标签
table 表格
class定义属性
Beautiful Soup库用于解析网页内容
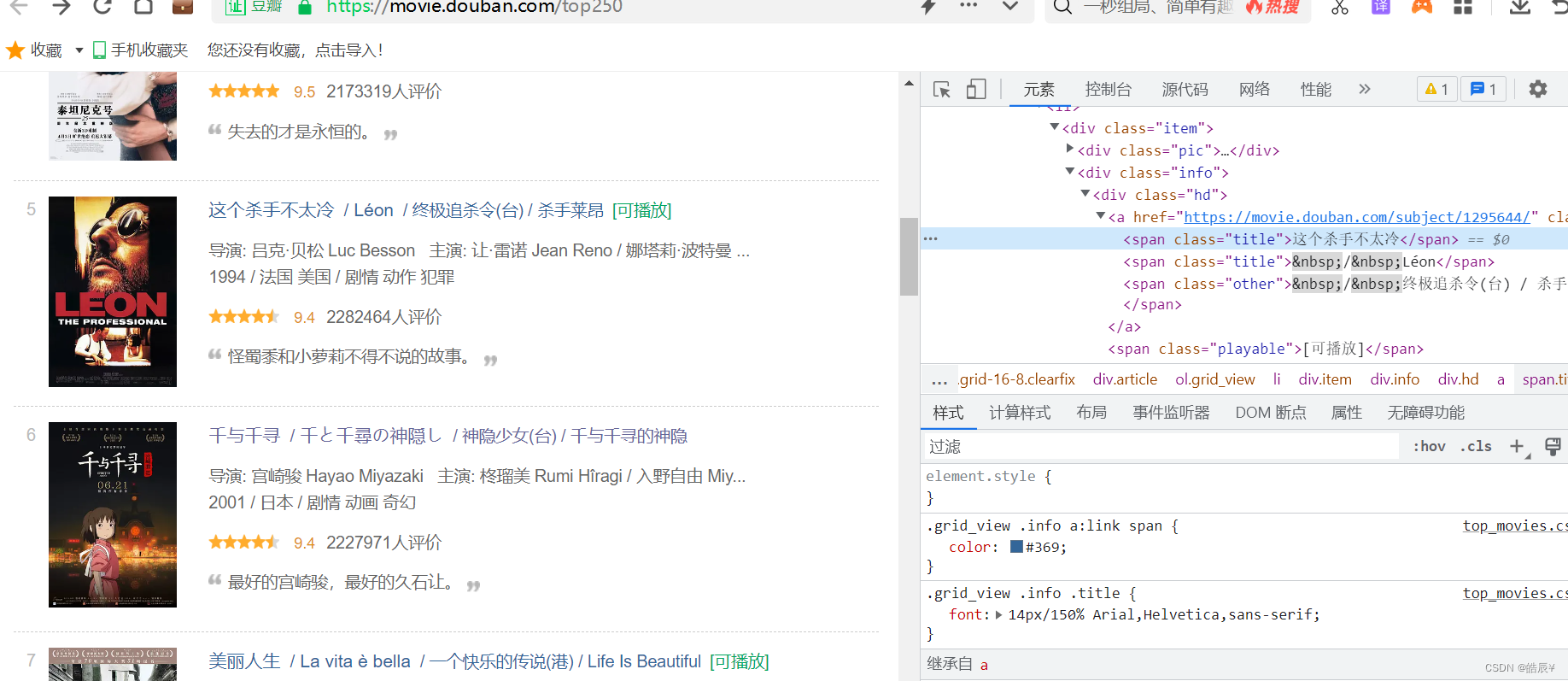
审查电影名的元素,发现名字都是在span里面,属性class都是title
因此构造解析的代码如下:
from bs4 import BeautifulSoup
import requests
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36"
}
response=requests.get("https://movie.douban.com/top250",headers=headers)
html=response.text
soup=BeautifulSoup(html,"html.parser")
all_titles=soup.findAll("span",attrs={"class":"title"})
for title in all_titles:
print(title)
解析后如下图
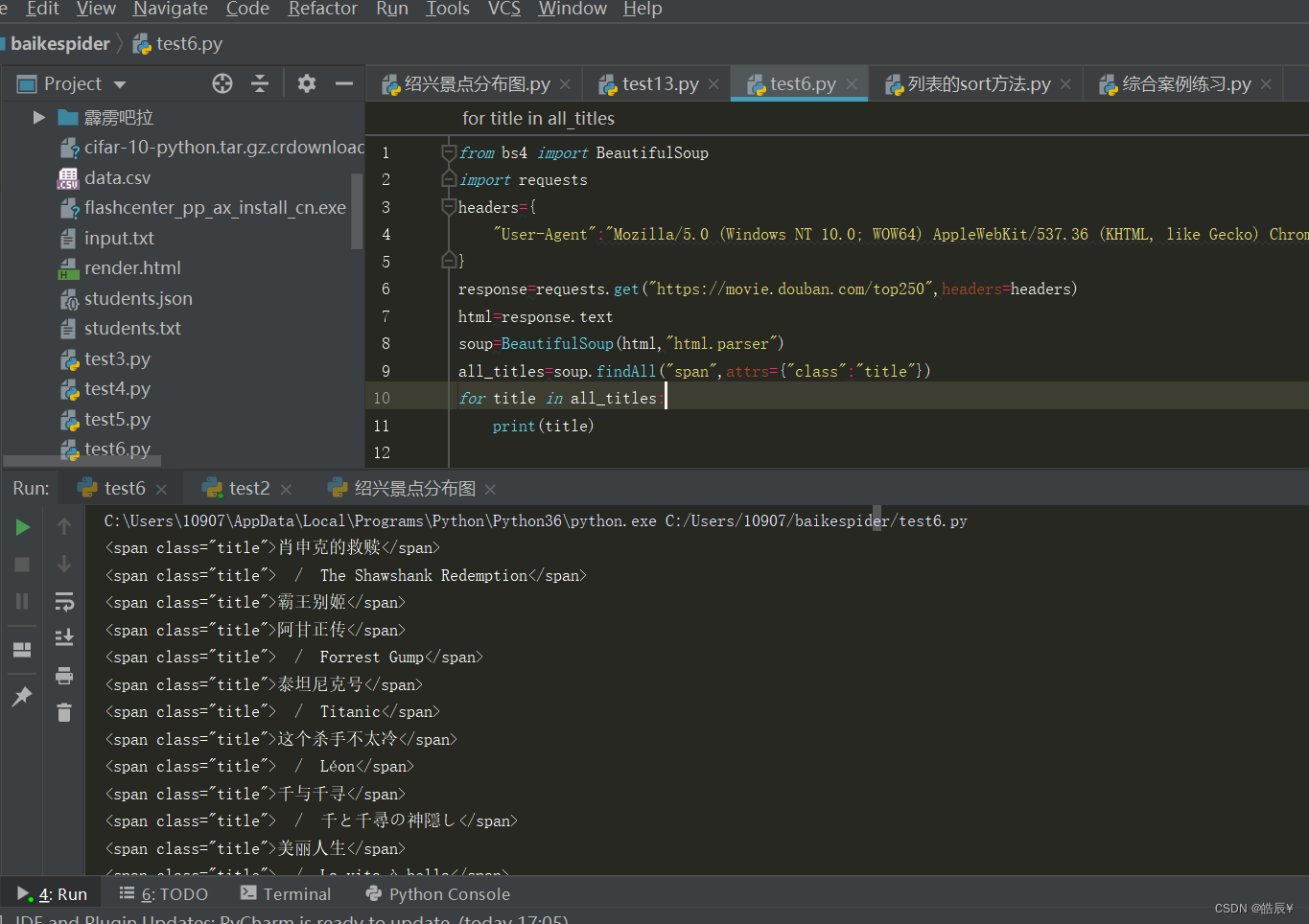
通过string属性可以把span标签剔除,通过选择不含“/”的获得中文电影名
from bs4 import BeautifulSoup
import requests
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36"
}
response=requests.get("https://movie.douban.com/top250",headers=headers)
html=response.text
soup=BeautifulSoup(html,"html.parser")
all_titles=soup.findAll("span",attrs={"class":"title"})
for title in all_titles:
title_string=title.string
if "/" not in title_string:
print(title_string)
如下图,可知获取排行榜成功。
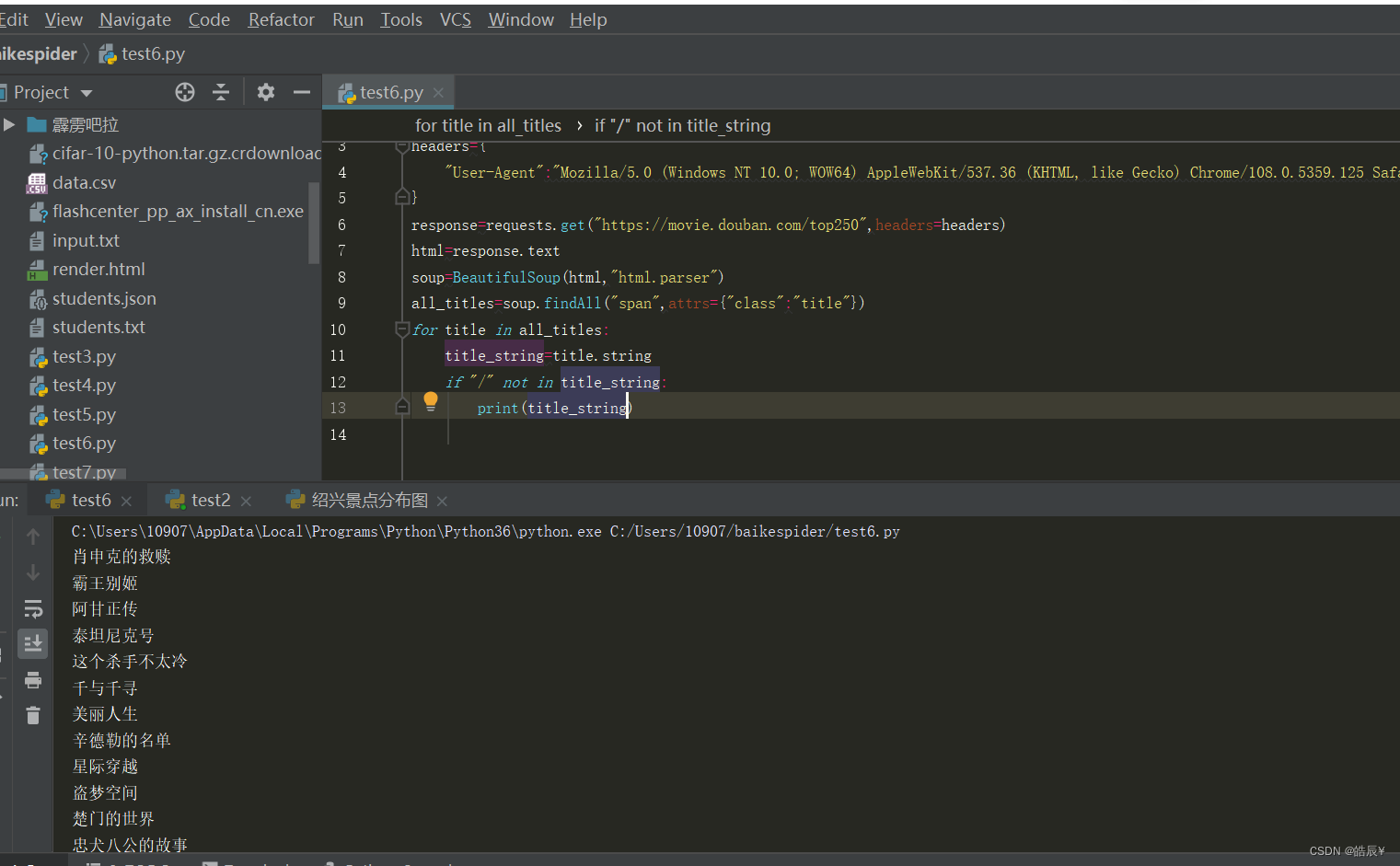
但是只获取到一页,如何获取多页呢?
如何获取多页排行榜?
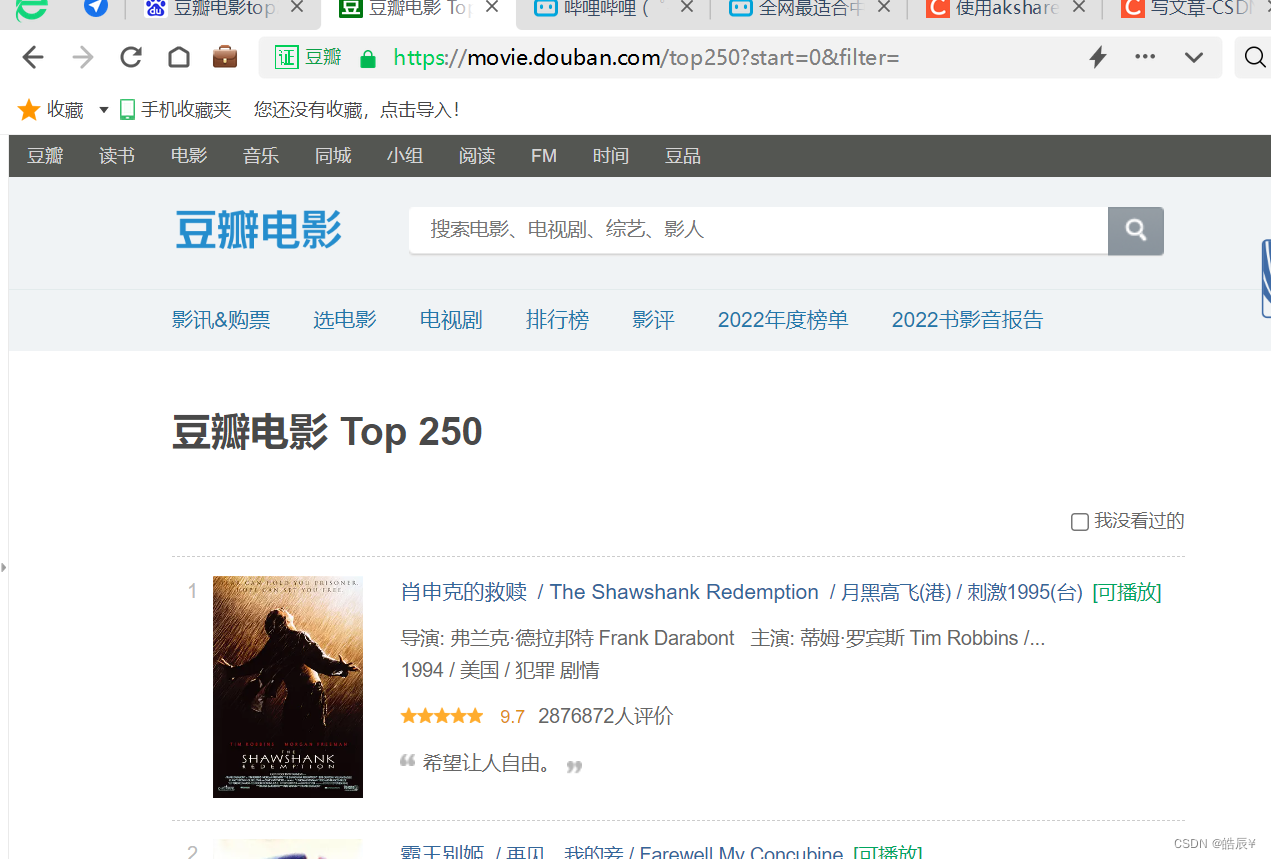
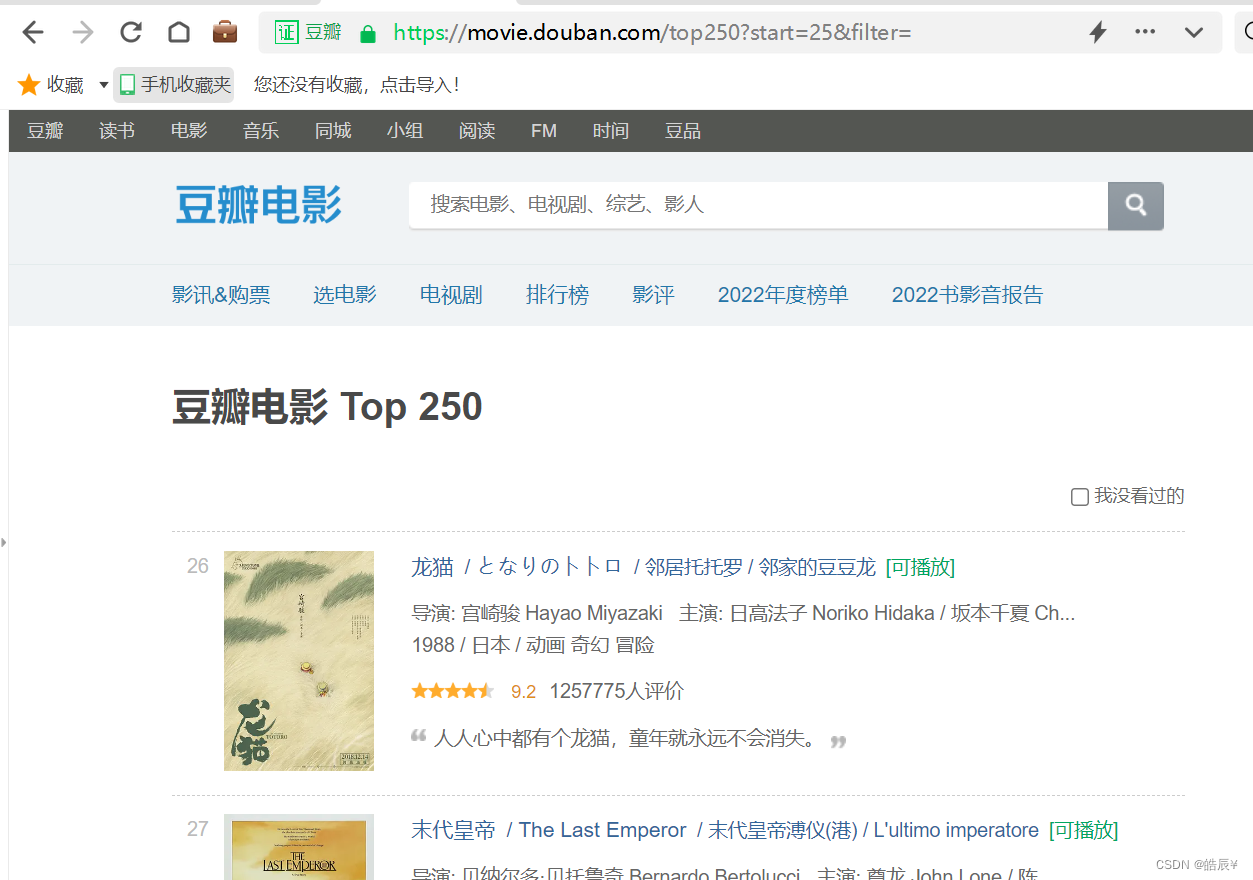
通过观察第一页和第二页,只有在start上有变化 由0变成了25
同理第三页start变成了50
所以要创建一个变量使其可以从0,25,50一直到250
from bs4 import BeautifulSoup
import requests
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.125 Safari/537.36"
}
for start_num in range(0,250,25):
response=requests.get(f"https://movie.douban.com/top250?start={start_num}",headers=headers)
html=response.text
soup=BeautifulSoup(html,"html.parser")
all_titles=soup.findAll("span",attrs={"class":"title"})
for title in all_titles:
title_string=title.string
if "/" not in title_string:
print(title_string)
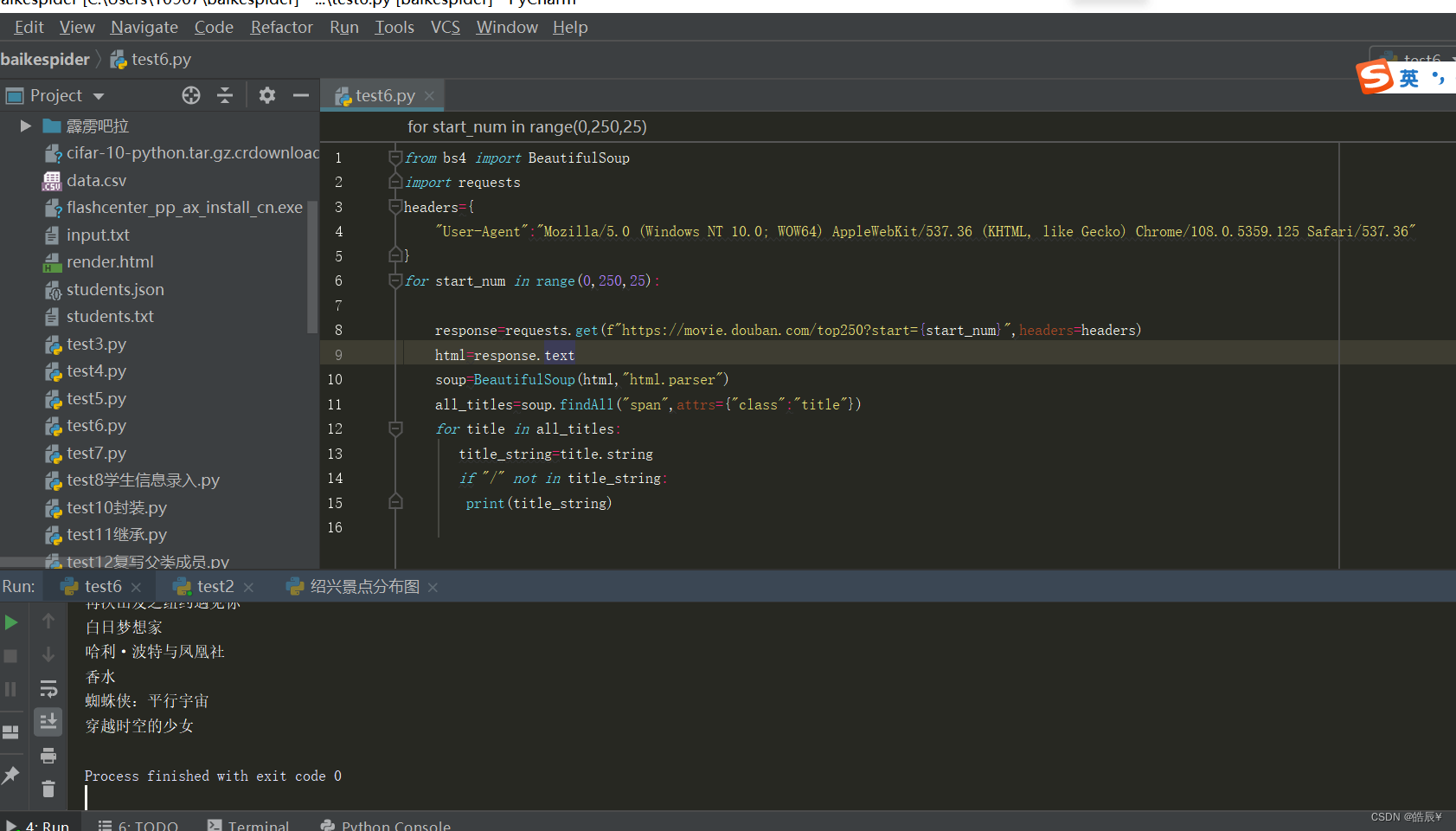
如下图可知成功获取了豆瓣电影top250















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









