







前言
提示:以下是本篇文章正文内容,下面案例可供参考
一、hadoop是什么?
Hadoop 生态是指围绕 Hadoop 大数据处理平台形成的一系列开源软件和工具,用于支持大规模数据处理、存储、管理、分析和可视化等应用场景。暂时将其核心技术分为9类:
- 数据采集技术框架: Flume、Logstash、FileBeat;Sqoop和Datax; Cannal和Maxwell
- 数据存储技术框架: HDFS、HBase、Kudu、Kafka
- 分布式资源管理框架: YARN、Kubernetes和Mesos
- 数据计算技术框架
- 离线数据计算 : MapReduce、Tez、Spark
实时数据计算:Storm、Flink、Spark中的SparkStreaming
数据分析技术框架: Hive、Impala、Kylin、Clickhouse、Druid、Doris - 任务调度技术框架:Azkaban、Ooize、DolphinScheduler
- 大数据底层基础技术框架:Zookeeper
- 数据检索技术框架:Lucene、Solr和Elasticsearch
- 大数据集群安装管理框架:HDP、CDH、CDP

目前常用的Hadoop 生态包括:
- HDFS: Hadoop Distributed File System(HDFS)是 Hadoop 的分布式文件系统,用于存储大规模数据集,提供了高容错性、高吞吐量的数据访问。
- MapReduce: Hadoop 的分布式计算框架,用于处理大规模数据集,可实现分布式计算、数据清洗、批处理等任务。
- YARN:Yet Another Resource Negotiator(YARN)是 Hadoop 的资源管理框架,用于将计算和存储分离,实现集群资源的统一管理与调度。
- Hive:Hadoop 中的数据仓库工具,类似于传统的 SQL 数据库,可通过 HiveQL 进行数据存储、查询和分析等操作。
- HBase:Hadoop 中的分布式数据库,基于 HDFS 构建,支持高速查询和随机读写。
- Pig:Pig 是基于 Hadoop 的数据流语言,用于在 Hadoop 平台上执行复杂的数据处理任务。
- Sqoop:Hadoop 的数据导入和导出工具,用于在 Hadoop 平台和关系型数据库之间进行数据传输。
- Flume:Hadoop 的数据收集和汇聚工具,用于将数据从多个源收集到 Hadoop 中进行处理。
- Spark: Spark虽然不是Hadoop的一部分,但与Hadoop生态系统紧密集成。Spark提供了更快的数据处理和分析能力,具备批处理、流处理、机器学习和图计算等功能。
- Zeppelin: Hadoop 的数据分析和可视化工具,将数据存储、查询、分析、展示等功能都聚合在一个交互式的笔记本中。
二、安装步骤(Win10)
1.系统环境
JDK1.8
hadoop-2.8.0
Windows102.相关约定
存放目录:D:\soft\RunTools\BigData
3.下载解压
Hadoop的安装包:https://archive.apache.org/dist/hadoop/common/
解决到D:\soft\RunTools\BigData目录下
4.配置环境变量
1、配置Hadoop环境变量 :
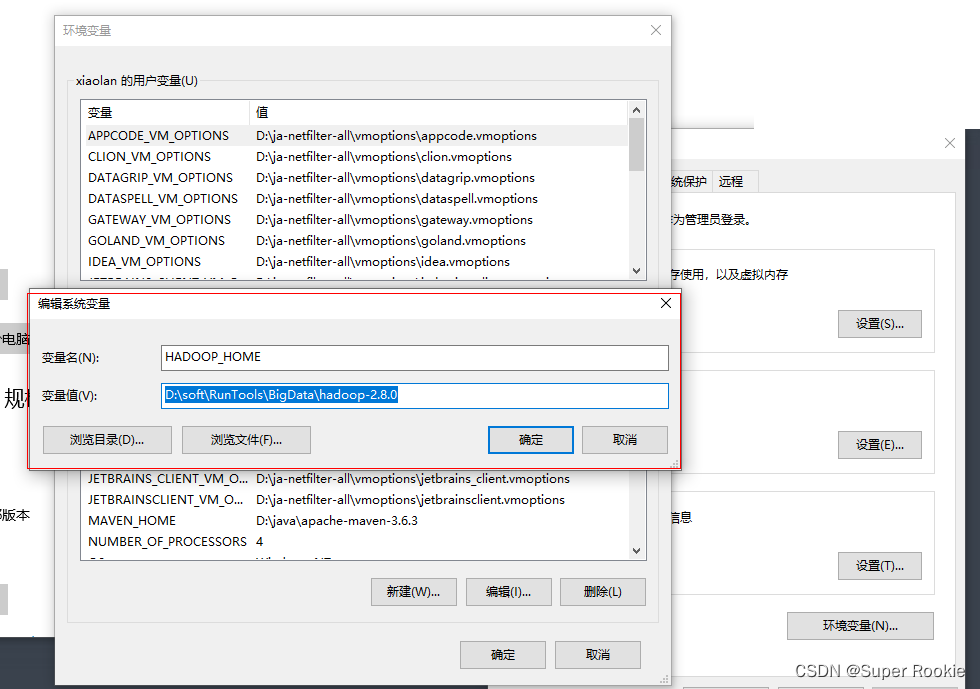
点击“电脑”–>“属性”–>“高级系统设置”–>“环境变量”–>“新建系统变量”;
变量名:HADOOP_HOME,变量值:Hadoop的解压路径(如 D:\soft\RunTools\BigData\hadoop-2.8.0),如下图:
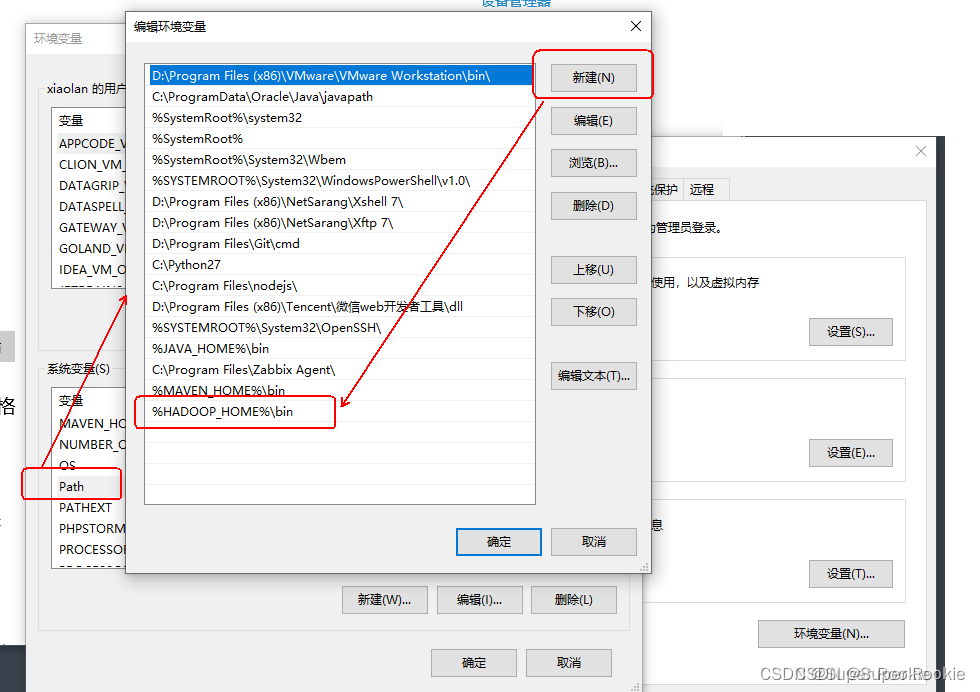
2、Path变量编辑:
编辑Path变量,新增 %HADOOP_HOME%\bin;
5.验证环境变量
验证正确:配置好环境变量后,打开CMD命令提示符,然后输入命令hadoop version,回车,如果显示出版本号,则说明安装成功。如下图所示:

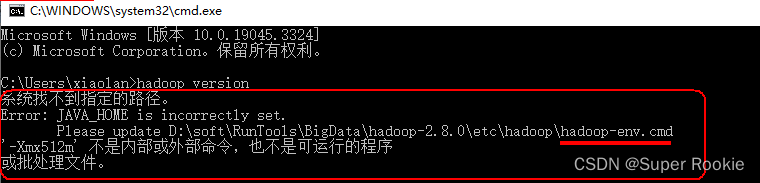
验证错误:第一次验证会提示失败,如下图所示:
错误解决:
错误分析
JAVA_HOME目录是:C:\Program Files\Java\jdk1.8.0_121
因为Program Files中间存在空格,所以出现错误,只需要用PROGRA~1代替Program Files即可。
解决方案
打开目录:D:\soft\RunTools\BigData\hadoop-2.8.0\etc\hadoop找到hadoop-env.cmd编辑打开
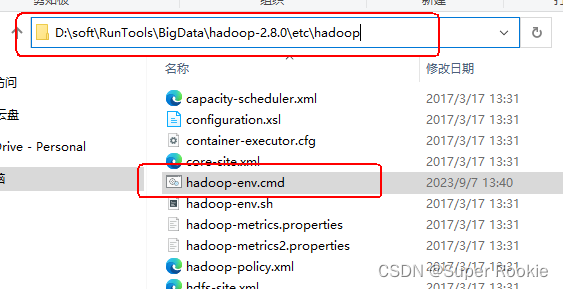
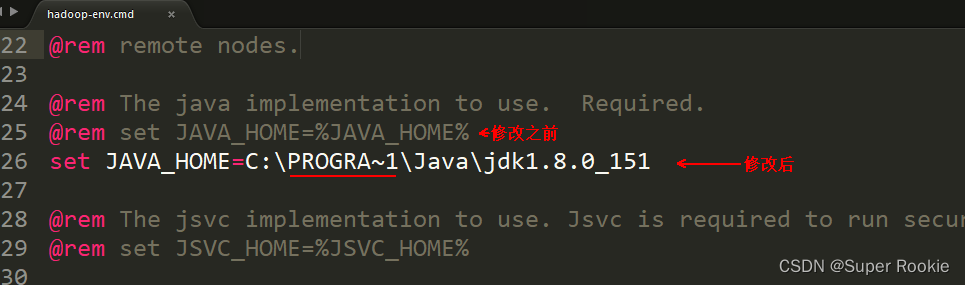
将JAVA_HOME目录改为:
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_121 【注意Program Files 替换为PROGRA~1】
以上完成之后 再次输入命令hadoop version 进行验证 就可以看到版本号问题解决。
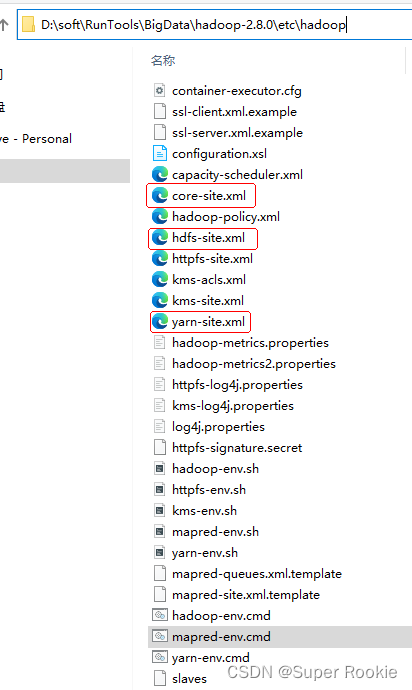
6.配置文件配置
Hadoop常用的一些配置文件:
core-site.xml
hdfs-site.xml
yarn-site.xml
mapred-site.xml
- 配置 core-site.xml 文件
先在 D:\DataBasehadoopDB\ 目录下建 tmp 文件夹
文件路径:\etc\hadoop\core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/DataBase/hadoopDB/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>- 配置 yarn-site.xml 文件
文件路径:\etc\hadoop\yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hahoop.mapred.ShuffleHandler</value>
</property>
</configuration>- 配置 hdfs-site.xml 文件
文件路径:\etc\hadoop\hdfs-site.xml
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/DataBase/hadoopDB/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/DataBase/hadoopDB/datanode</value>
</property>
</configuration>- 配置 mapred-site.xml 文件
7.启动/停止
- namenode格式化
D:\soft\RunTools\BigData\hadoop-2.8.0\bin 目录下,打开cmd,
执行 hdfs namenode -format
- 启动
D:\soft\RunTools\BigData\hadoop-2.8.0\sbin 目录下
执行 start-all.cmd
然后回车,此时会弹出4个cmd窗口,分别是NameNode、ResourceManager、NodeManager、DataNode。检查4个窗口有没有报错。
- 查看Hadoop运行的进程:jps
在CMD执行jps看到这4个进程,启动成功
- 关闭
D:\soft\RunTools\BigData\hadoop-2.8.0\sbin 执行 stop-all.cmd















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









