







- 首先客户机与服务器需要建立连接,只要单击某个超级链接,HTTP的工作开始。
- 建立连接后,客户机发送一个请求给服务器;请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可能的内容。
- 服务器接到请求后,给予相应的响应信息;其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是MIME信息包括服务器信息、实体信息和可能的内容。
- 客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
如果在以上过程中的某一步出现错误,那么产生错误的信息将返回到客户端,有显示屏输出。
这些过程由HTTP自己完成,我们等待信息显示就可以了。
二、Urllib、Requests库
这两个库都建议新手能够熟练掌握,在Python爬虫中使用频率非常高。
下方也有分享安装教程资源,有需要的点击进群找群管理获取即可↓↓
<Python学习交流群 安装教程资源获取>
Urllib库
Urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了urllib。
1)主要包含以下4个模块
- urllib.request:用于打开和阅读URL
- urllib.error:包含由引发的异常urllib.request
- urllib.parse:用于解析URL
- urllib.robotparser:用于解析robot.txt文件
2)urllib.request.urlopen()
模块定义了有助于在复杂环境中打开URL(主要是HTTP)的函数和类-基本身份验证和摘要身份验证,重构定向,Cookie等。
语法结构
urllib.request.urlopen(url,data = None,[ timeout,] *,cafile = None,capath = None,cadefault = False,context = None)
语法详解
- url:传入的对象可以是url也可以是一个request的对象;
- data:data必须是一个直接要发送搭服务器的其他数据的对象,如果没有data数据的话可以为None,也可以不写。
- timeout:以秒为单位制定用于组织链接尝试之类的操作超时;
3)urllib.openurl:返回对象的方法
设置一个url对象
url = “百度一下,你就知道”
#发送请求,打开url
up = urllib.request.urlopen(url)
print(type(up))
#返回对象
<class ‘http.client.HTTPResponse’>
上面我们可以看出返回的对象是HTTPResponse类型的,下面一起来看一下HTTPResponse类的方法
发送GET请求:
from urllib import request
response = request.urlopen(‘百度一下,你就知道’)
print(response.read().decode())
发送post请求:
from urllib import reuqest
response = request.urlopen(‘Method Not Allowed’, data=b’word=hello’)
print(response.read().decode()) #decode()解码
我们已经知道在讲urlopen中传入一个网址的时候他就会主动的去访问目标的网址,会返回一个HTTPResponse类型的对象,那么我们是怎么知道我们发送的get请求和post请求呢?
def get_method(self):
“”“Return a string indicating the HTTP request method.”“”
default_method = “POST” if self.data is not None else “GET”
return getattr(self, ‘method’, default_method)
这个是源码中的一个方法,根据代码我们得知如果data是不为空的话,就是post请求,否则就是get请求。
4)urllib.request.Request
上面的urllib是可对网页发起请求,在我们实际的爬虫应用中,如果频繁的访问一个网页,网站就会识别我们是不是爬虫,这个时候我们就要利用Request来伪装我们的请求头。
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
推荐使用request()来进行访问的,因为使用request()来进行访问有两点好处:
- 可以直接进行post请求,不需要将 data参数转换成JSON格式
- 直接进行GET请求,不需要自己拼接url参数

如果只进行基本的爬虫网页抓取,那么urllib足够用了。
Requests库
requests库是一个常用于http请求的模块,可以方便的对网页进行爬取,是学习python爬虫比较好的http请求模块,比urllib库更加简洁,并且自带json解析器。
掌握了它,Cookies、登录验证、代理设置等操作都不是事儿。
1)request提供的方法

get(url,params,**kwargs)
- url: 需要爬取的网站地址。
- params: url中的额外参数,字典或者字节流格式,可选。
- **kwargs : 控制访问的参数
post(url, data=None, json=None, **kwargs):
- url: 需要爬取的网站地址。
- data:传递的内容。
- json:json格式传递的内容
- **kwargs : 控制访问的参数
request(method, url, **kwargs):
- method:需要使用的方法
- url:爬行的路径
- **kwargs : 控制访问的参数
2)控制访问的参数

通过上面方法返回的是一个Response对象,该对象有以下这些属性和方法:

requests的优势在于使用简单,相同一个功能,用requests实现起来代码量要少很多。
戳这里可获取相关的Python基础学习资料哦↓↓↓
下面的所有资料我全部打包好了并且上传至CSDN官方,需要的点击👇获取!

三、开发工具的掌握
- PyCharm – 交互很好的Python一款IDE;
- Fiddler – 网页请求监控工具,我们可以使用它来了解用户触发网页请求后发生的详细步骤;
(1)PyCharm
PyCharm是一款著名的Python IDE开发工具,拥有一整套可以帮助用户在使用Python语言开发时提高其效率的工具。
具备基本的调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。
此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
pycharm官网分为两个版本:
第一个版本是Professional(专业版本),这个版本功能更加强大,主要是为Python和web开发者而准备,是需要付费的。
第二个版本是社区版,一个专业版的阉割版,比较轻量级,主要是为Python和数据专家而准备的。
一般我们做开发,下载专业版本比较合适。

(2)Fiddler
Fiddler是一个http调试代理,它能够记录所有的你电脑和互联网之间的http通讯。
Fiddler 可以也可以让你检查所有的http通讯,设置断点,以及Fiddle 所有的“进出”的数据(指cookie,html,js,css等文件,这些都可以让你胡乱修改的意思)。
要比其他的网络调试器要更加简单,因为它仅仅暴露http通讯还有提供一个用户友好的格式。
1)基本工作原理

会话的概念:一次请求和一次响应就是一个会话。
2)fiddler主界面

工具栏

- 1:给会话添加备注信息
- 2:重新加载当前会话
- 3:删除会话选项
- 4:放行,和断点对应
- 5:响应模式。也即是,当Fiddler拿到远程的response后是缓存起来一次响应给客户端还是以stream的方式直接响应。
- 6:解码,有些请求是被编码的,点击这个按钮后可以根据响应的编码格式自动解码。
- 7:查找会话
- 8:保存会话
- 9:截屏。截屏后,会以会话的方式返回一个截图
判断get和post请求
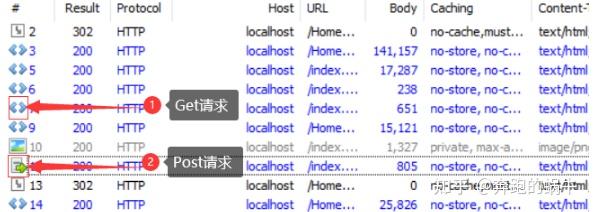
会话列表属性说明

查看请求头和请求体

3)Fiddler设置过滤(抓取指定服务器地址的数据)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)


感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的:
① 2000多本Python电子书(主流和经典的书籍应该都有了)
② Python标准库资料(最全中文版)
③ 项目源码(四五十个有趣且经典的练手项目及源码)
④ Python基础入门、爬虫、web开发、大数据分析方面的视频(适合小白学习)
⑤ Python学习路线图(告别不入流的学习)
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-L81Fh9lK-1712709592547)]















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









