






1.学习率(Learning Rate)
1)定义
深度学习中的学习率(Learning Rate)是一个至关重要的超参数,它决定了模型在训练过程中更新权重参数的速度与方向。在使用梯度下降法(Gradient Descent)或其变种(如随机梯度下降,Stochastic Gradient Descent, SGD)优化模型时,学习率扮演着核心角色。
具体来说,在每次迭代过程中,模型计算损失函数关于各个参数的梯度,这个梯度指示了参数应当朝着哪个方向调整以最小化损失。学习率就是这个调整过 程中的“步伐”大小,即参数更新的量。
如果学习率设置得过大,那么在每一步迭代中,模型参数可能会跨过最优解,导致震荡或者发散,这被称为“振荡现象”或“不稳定性”。相反,如果学习率设置得太小,模型收敛到最优解的速度将会非常慢,而且可能会陷入局部极小点,而不是全局最优解。
2)常见的影响因素
a.问题的复杂度:问题的复杂度反映了模型在训练过程中需要调整的参数数量和模型的复杂度。通常情况下,更复杂的问题需要更小的学习率来确保模型的稳定性和收敛性。
b.数据集的大小:数据集的大小直接影响了模型训练的稳定性和泛化能力。对于较大的数据集,通常可以使用较大的学习率来加快收敛速度;而对于较小的数据集,则需要使用较小的学习率以避免过拟合。
c.学习率的初始值:学习率的初始值对模型的训练过程和性能有重要影响。选择合适的初始学习率是一个关键的调参过程,通常需要进行实验和调整来找到最佳的初始学习率。d.优化算法的选择:不同的优化算法对学习率的敏感度不同。一些优化算法(如 Adam、Adagrad 等)具有自适应学习率调整的能力,可以在训练过程中动态地调整学习率,而另一些算法(如 SGD)则需要手动调整学习率。
e.学习率衰减策略:学习率衰减策略决定了学习率在训练过程中的变化方式。合适的学习率衰减策略可以提高模型的训练稳定性和泛化能力,对于长时间的训练任务尤为重要。
f.初始参数值:初始参数值对于模型的训练过程和学习率的选择也有影响。不同的初始参数值可能会导致模型在训练过程中出现不同的收敛速度和性能。
g.训练数据的分布:训练数据的分布对模型的训练过程和学习率的选择有直接影响。如果训练数据是非平稳的或者存在类别不平衡的情况,可能需要采用不同的学习率调整策略来保证模型的训练效果。
h.模型架构的选择:不同的模型架构对于学习率的选择和训练过程的稳定性有不同的要求。一些复杂的模型架构可能需要更小的学习率和更复杂的优化算法来进行训练。
3) 常见的调整方法
固定学习率:
这是最简单的学习率调整方法,即在整个训练过程中保持学习率不变。这种方法的优点是简单直观,但缺点是可能无法很好地适应不同阶段的训练过程,导致训练过程不稳定或收敛速度过慢。 如 0.1、0.01、0.001 等。
学习率衰减(Learning Rate Decay):
学习率衰减是一种常用的学习率调整方法,它随着训练的进行逐渐减小学习率,以提高模型训练的稳定性和泛化能力。
常见的学习率衰减方法包括:
指数衰减(Exponential Decay):学习率按指数函数衰减
余 弦 衰 减 ( Cosine Decay ) : 学 习 率 按 余 弦 函 数 衰 减
线性衰减(Linear Decay):学习率按线性函数衰减
自适应学习率算法
自适应学习率算法是一类可以自动调整学习率的优化算法,它们根据参数的梯度信息动态地调整学习率。常见的自适应学习率算法包括:
Adam(Adaptive Moment Estimation)
Adagrad(Adaptive Gradient Algorithm)
RMSProp(Root Mean Square Propagation)
Adadelta(Adaptive Delta)
这些算法通过考虑历史梯度信息或者自适应地调整学习率的大小来提高模型训练的效率和性能。
多项式衰减(Polynomial Decay)
是一种学习率调整策略,通过多项式函数对学习率进行衰减,从而在训练过程中逐渐降低学习率。多项式衰减通常用于训练过程中的学习率衰减策略之一,可以帮助模型在训练后期更好地收敛,并提高模型的泛化能力。
多项式衰减策略通过调整指数 p 的大小来控制学习率的衰减速率。当 P>1时,学习率将以多项式函数形式缓慢衰减;当 p=1 时,学习率以线性方式衰减;当 0<p<1 时,学习率将以多项式函数形式快速衰减。
2.学习率调整(Learning Rate Scheduling)
1)重要性
防止过拟合:适当的学习率可以帮助模型更好地泛化到新的数据集上,减少过拟合现象。
提高收敛速度:合理的学习率设置可以加快模型收敛到最优解的速度,节省训练时间。
优化模型性能:学习率的调整直接影响模型的训练效果和最终性能。
2)常见的学习率调度策略
PyTorch 学习率调整策略通过 torch.optim.lr_scheduler 接口实现。PyTorch 提供的学习率调整策略分为三大类,分别是
a. 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和 余弦退火 CosineAnnealing。
b. 自适应调整:自适应调整学习率 ReduceLROnPlateau。
c. 自定义调整:自定义调整学习率 LambdaLR。
等间隔调整学习率 StepLR
等间隔调整学习率,调整倍数为 gamma 倍,调整间隔为 step_size。间隔单位是 step。需要注意的是, step 通常是指 epoch,不要弄成 iteration 了。
参数:
step_size(int)- 学习率下降间隔数,若为 30,则会在 30、 60、 90…个step 时,将学习率调整为 lr*gamma。gamma(float)- 学习率调整倍数,默认为 0.1 倍,即下降 10 倍。last_epoch(int)- 上一个 epoch 数,这个变量用来指示学习率是否需要调整。当 last_epoch 符合设定的间隔时,就会对学习率进行调整。当为-1 时,学习率设置为初始值
按需调整学习率 MultiStepLR
按设定的间隔调整学习率。这个方法适合后期调试使用,观察 loss 曲线,为每个实验定制学习率调整时机。
参数:
milestones(list)- 一个 list,每一个元素代表何时调整学习率,list 元素必须是递增的。如 milestones=[30,80,120]gamma(float)- 学习率调整倍数,默认为 0.1 倍,即下降 10 倍。
指数衰减调整学习率 ExponentialLR
按指数衰减调整学习率,调整公式: lr=lr*gamma**epoch
参数:
gamma- 学习率调整倍数的底,指数为 epoch,即 gamma**epoch
余弦退火调整学习率 CosineAnnealingLR
以余弦函数为周期,并在每个周期最大值时重新设置学习率。以初始学习率为最大学习率,以 2 ∗
Tmax2*Tmax2
∗
Tmax 为周期,在一个周期内先下降,后上升。
参数:
T_max(int)- 一次学习率周期的迭代次数,即 T_max 个 epoch 之后重新设置学习率。eta_min(float)- 最小学习率,即在一个周期中,学习率最小会下降到eta_min,默认值为 0。
自适应调整学习率 ReduceLROnPlateau
当某指标不再变化(下降或升高),调整学习率,这是非常实用的学习率调整策略。
例如,当验证集的 loss 不再下降时,进行学习率调整;或者监测验证集的accuracy,当 accuracy 不再上升时,则调整学习率。
参数:
mode(str)- 模式选择,有 min 和 max 两种模式,min 表示当指标不再降低(如监测 loss), max 表示当指标不再升高(如监测 accuracy)。factor(float)- 学习率调整倍数(等同于其它方法的 gamma),即学习率更新为 lr=lr * factorpatience(int)- 忍受该指标多少个 step 不变化,当忍无可忍时,调整学习率。
verbose(bool)- 是否打印学习率信息,print(‘Epoch {:5d}: reducing learning rate of group {} to {:.4e}.’.format(epoch, i, new_lr))
threshold_mode(str)- 选择判断指标是否达最优的模式,有两种模式,rel 和 abs。
当 threshold_mode == rel,并且 mode==max 时,dynamic_threshold = best *(1+threshold);
当 threshold_mode == rel,并且 mode==min 时,dynamic_threshold = best *(1-threshold);
当 threshold_mode == abs,并且 mode==max 时,dynamic_threshold = best +threshold ;
当 threshold_mode == rel,并且 mode==max 时,dynamic_threshold = best -threshold;
threshold(float)- 配合 threshold_mode 使用。 cooldown(int)- “冷却时间”,当调整学习率之后,让学习率调整策略冷 静一下,让模型再训练一段时间,再重启监测模式。
min_lr(float or list)- 学习率下限,可为 float,或者 list,当有多参数组时,可用 list 进行设置。 eps(float)- 学习率衰减的最小值,当学习率变化小于 eps 时,则不调整 学习率。
自定义调整学习率 LambdaLR
为不同参数组设定不同学习率调整策略。调整规则为, lr = base_lr*lmbda(self.last_epoch) fine-tune 中十分有用,我们不仅可为不同的层设定不同的学习率,还可以为其设定不同的学习率调整策略。
参数:
lr_lambda(function or list)- 一个计算学习率调整倍数的函数,输入通常为 step,当有多个参数组时,设为 list。
3.不同学习率策略的对比
(1)下面是一些常见的学习率调度器的优缺点:
1)StepLR:
优点:简单易用,可以按照指定的步数调整学习率。
缺点:可能不够灵活,无法根据训练过程中的表现自动调整学习率。
2)MultiStepLR:
优点:在指定的 milestones 上调整学习率,相对于 StepLR 更灵活。
缺点:需要手动指定 milestones,不够自适应。
3)ExponentialLR:
优点:按指数衰减调整学习率,可以更快地降低学习率。
缺点:学习率下降速度过快,可能导致训练不稳定。
4)ReduceLROnPlateau:
优点:根据验证集表现自动调整学习率,能够更好地应对训练过程中的波动。
缺点:可能在某些情况下过于保守,导致学习率调整不够及时。
5)CosineAnnealingLR:
优点:使用余弦函数调整学习率,可以更平滑地调整学习率,在一定程度上避免震荡。
缺点:可能需要调整 T_max 参数来平衡学习率变化的速度和频率。
( 2 ) 在 MINIST 数 据 集 中 比 较
StepLR 、 CosineAnnealingLR 和 ReduceLROnPlateau 的训练效果。
1)参数:epochs=25,训练集 batch_size=64,测试集 batch_size=1000
损失值和准确率如下图所示:
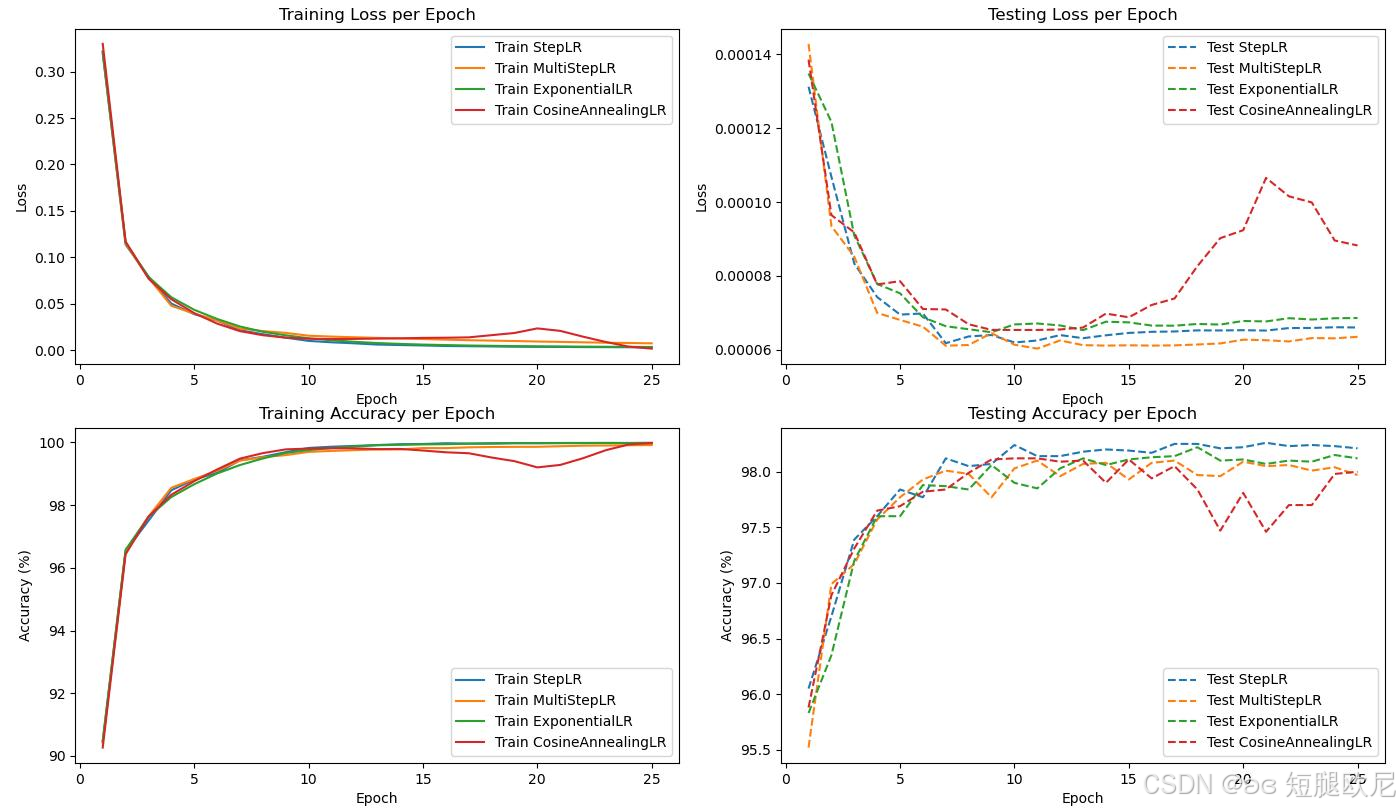
由上述图像可知:
该实验过程中可能出现
过拟合
:如果在训练过程中过度优化了特定数据集的特征,那么当面对新的、未见过的数据时(即测试集),模型的性能可能会显著下降。这种情况下,即使训练集上的表现很好,测试集上的结果也可能不尽人意。
2)参数:epochs=50,训练集 batch_size=1000,测试集 batch_size=2000
损失值和准确率如下图所示:
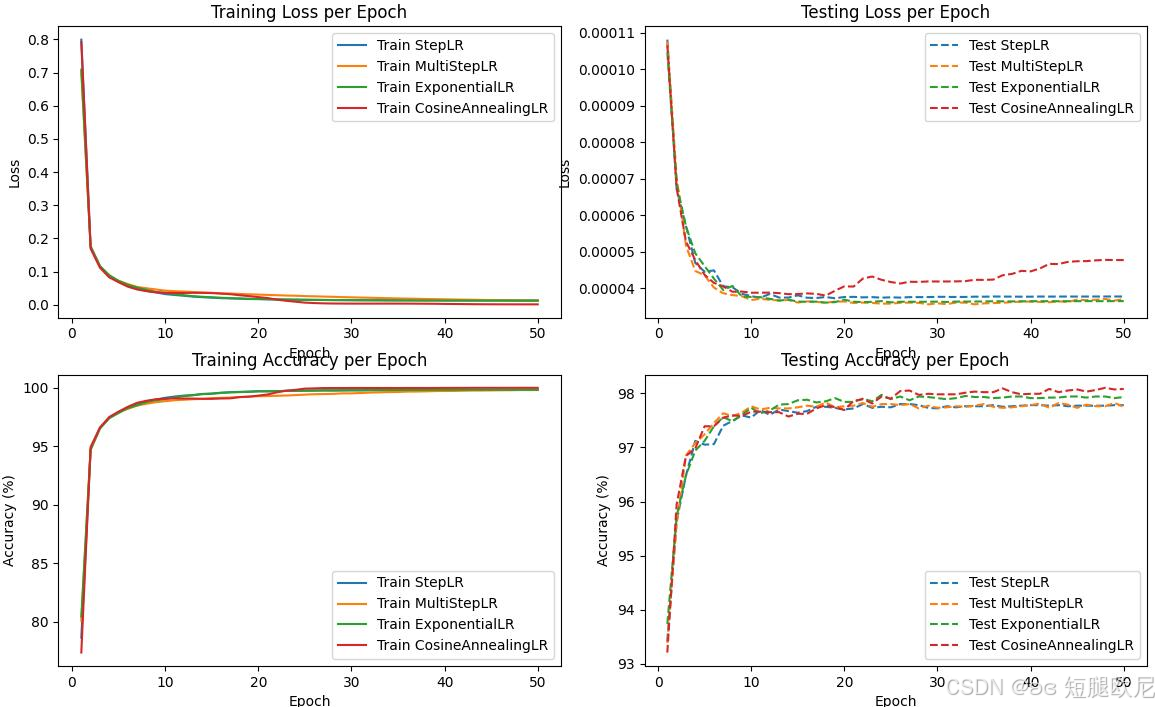

















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









