






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
文献来源:

1.1 ARIMA 模型
ARIMA 模型由 Box 和 Jenkins 于 20 世纪 70 年代提出,是一种著名的时间序列预测方法,该模型的基本思想是将数据看成一个时间序列对象,再使用数学模型对该时间序列进行描述,训练完成的模型可以通过时间序列的过去值、现在值来预测未来的数据及趋势,在一些工业设备强度预测等问题中得到了广泛的应用。由于实际的水文序列具有非线性非平稳的特点,而 ARIMA 模型引入了差分,对于非线性非平稳的时间序列也具有良好的处理效果,并对水文序列中的线性关系具有良好的学习效果,故本文采用 ARIMA 模型对未来水位变化情况进行预测。
ARIMA 模型由自回归( AR) 模型、移动平均模型( MA) 和差分法( I) 组成,其表达式如下。
自回归( AR) 模型用来描述现值与过去值之间的关系,使用指标自身的数据对自身进行预测。

1.2 CNN - LSTM 模型
考虑到影响因素众多,故本文使用了一种基于 CNN - LSTM 的多变量预测模型,将数据的多个变量输入进神经网络模型中,通过 CNN 对数据进行特征提取,其中原理如下。
定义一段水位数据序列为




细胞状态Ct由输入门和遗忘门的变化决定,其表达式如下:

📚2 运行结果
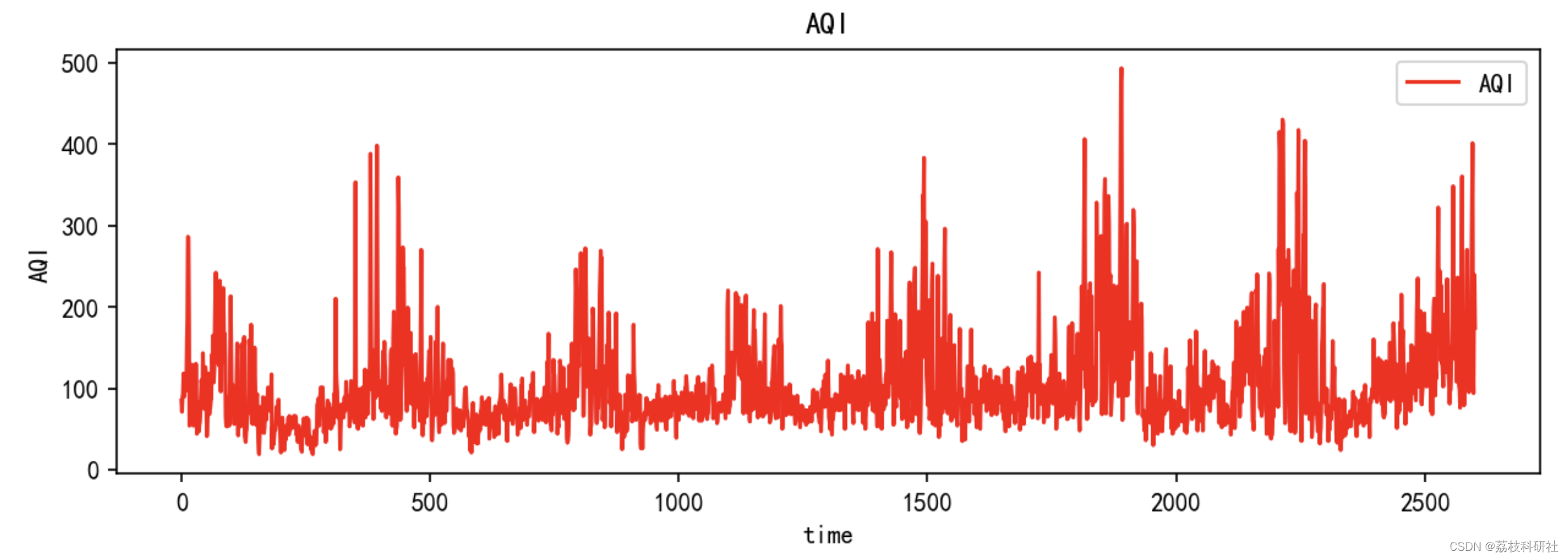
plt.figure(figsize=(10, 3),dpi=150)
plt.title('AQI')
plt.xlabel('time')
plt.ylabel('AQI')
plt.plot(data_raw, 'r', label='AQI')
plt.legend()
plt.show()
plt.figure(figsize=(9, 2),dpi=150)
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()

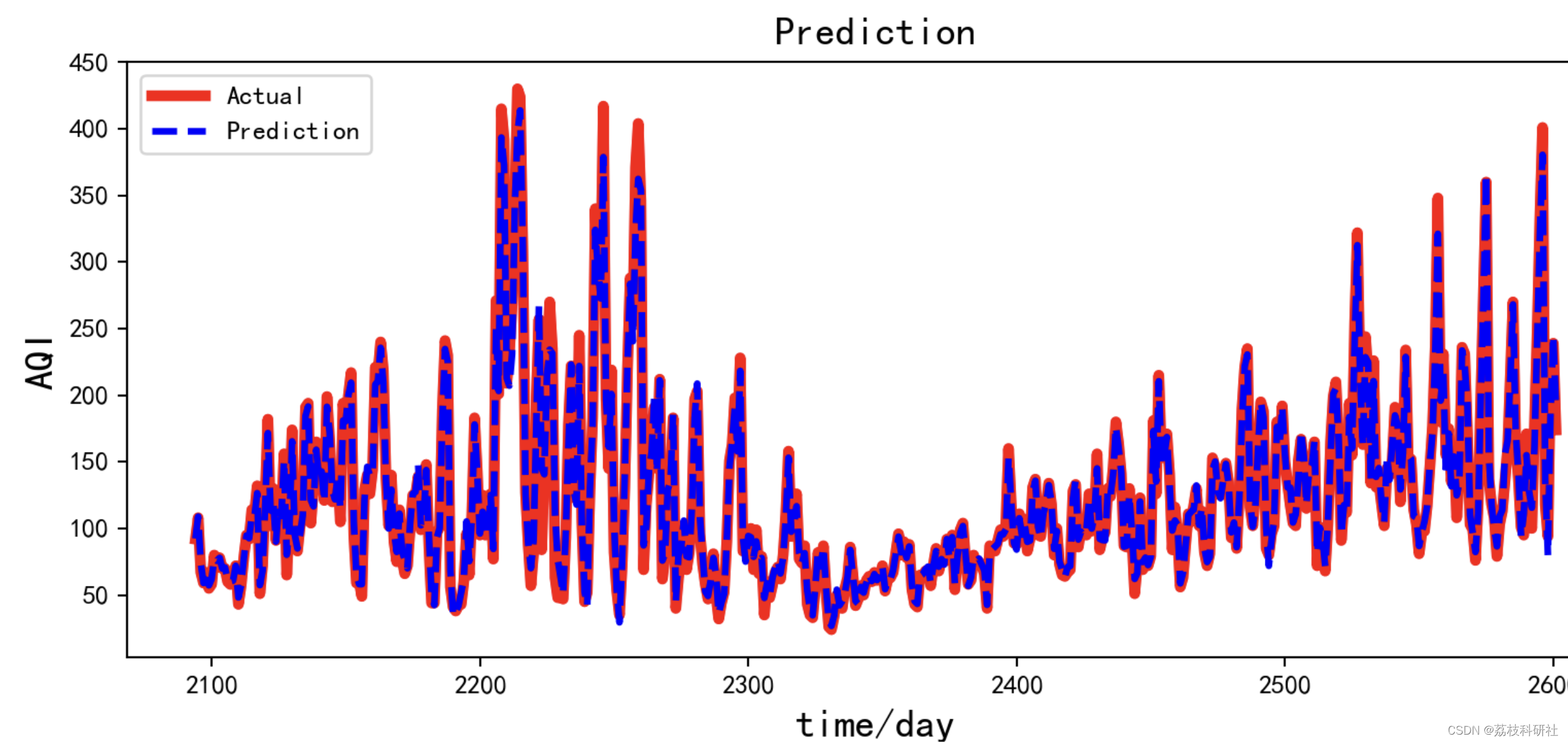
plt.figure(figsize=(10, 4),dpi=150)
plt.plot(test_data, label="Actual", color='red',linewidth=4)
plt.plot(range(len(x_train)+timestep+1,len(new_data)),draw_test, color='blue',label='Prediction',linewidth=2.5,linestyle="--")
plt.title('Prediction', size=15)
plt.ylabel('AQI',size=15)
plt.xlabel('time/day',size=15)
plt.legend()
plt.show()
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]陈帅宇,赵龑骧,蒋磊.基于ARIMA-CNN-LSTM模型的黄河开封段水位预测研究[J].水利水电快报,2023,44(01):15-22.DOI:10.15974/j.cnki.slsdkb.2023.01.002.















 6085
6085











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









