






睡眠占据人生三分之一的时间,关于睡眠健康方向的研究数不胜数,今天海文集团教研团队带来的是一项通过数据分析研究睡眠质量与生活习惯间的关联的研究内容。
一、项目背景
1、背景描述
本数据集涵盖了与睡眠和日常习惯有关的诸多变量。如性别、年龄、职业、睡眠时间、睡眠质量、身体 活动水平、压力水平、BMI类别、血压、心率、每日步数、以及是否有睡眠障碍等细节。
2、数据说明
解释说明:睡眠障碍
| 类型 | 说明 |
| 无 | 没有表现出任何特定的睡眠障碍 |
| 失眠 | 有入睡或保持睡眠的困难,导致睡眠不足或质量差 |
| 睡眠呼吸暂停 | 在睡眠过程中出现呼吸暂停,导致睡眠模式紊乱和潜在的健康风险 |
3、数据来源
https://www.kaggle.com/datasets/uom190346a/sleep-health-and-lifestyle-dataset
4、问题描述
全面的睡眠指标:探索睡眠时间、质量和影响睡眠模式的因素。
生活方式因素:分析身体活动水平、压力水平和BMI类别。
心血管健康:检查血压和心率测量。
睡眠障碍分析:识别睡眠障碍的发生,如失眠和睡眠呼吸暂停。
二、数据清洗及概览
In [21] :
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
from pyecharts import options as opts
from pyecharts.charts import Bar,Tab,HeatMap
#Tab报错可以用新的pyecharts版本,我这个pyecharts的版本为1.9In [22] :
data =
pd.read_csv('/home/mw/input/data1581/Sleep_health_and_lifestyle_dataset.csv',enc oding='gbk')
print(data.shape)
data.head()(374, 13)
Out [22]:
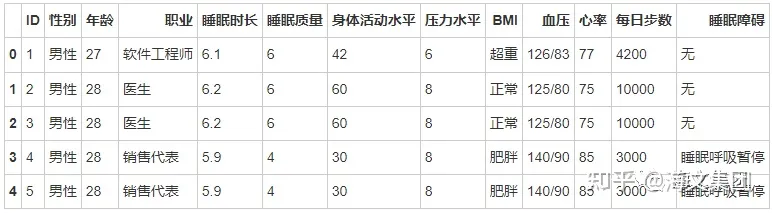
In [23] :
data['收缩压'] = data['血压'].apply(lambda x:int(x[:3]))
data['舒张压'] = data['血压'].apply(lambda x:int(x[4:]))
data['性别'] = data['性别'].apply(lambda x:1 if x=='男性' else 0)Out [24] :
data.describe()
#根据结果可以看出,无缺失值,且暂无异常值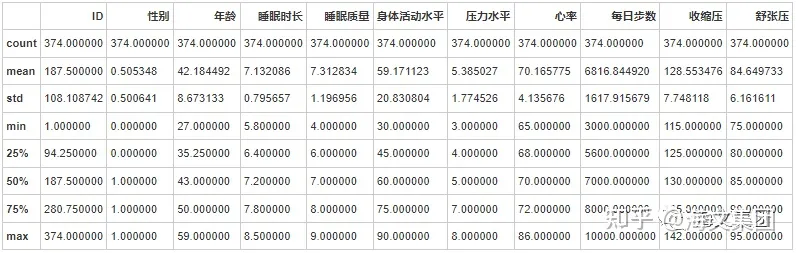
PS :2022年11月13日,首部《中国高血压临床实践指南》发布。推荐将我国成人高血压诊断界值下调为收缩压大于等于130毫米汞柱和/或舒张压大于等于80毫米汞柱,一般称血压低于90/60 mmHg的情形为低血压
根据上方表格来看,受访者中没有低血压患者,但存在高血压的患者,因此新找一列区分 。
In [25] :
data['是否高血压'] = 0
data.loc[(data['收缩压']>130)&(data['舒张压']>80),'是否高血压'] = 1
data['是否高血压'].mean()
#可以看出有28%的人有高血压Out [25] :
0.28609625668449196
#查看各类离散值的取值类型有哪些
from sklearn.preprocessing import OrdinalEncoder
OrdinalEncoder().fit(data.iloc[:,[1,3,8,12]]).categories_Out [26] :
[array([0, 1]),
array(['主管', '会计师', '医生', '工程师', '律师', '护士', '科学家', '老师', '营业员', '软件工程师', '销售代表'], dtype=object),
array(['正常', '肥胖', '超重'], dtype=object),
array(['失眠', '无', '睡眠呼吸暂停'], dtype=object)]In [27] :
data['睡眠障碍'].value_counts()/data.shape[0]Out [27] :
无 0.585561
睡眠呼吸暂停 0.208556
失眠 0.205882
Name: 睡眠障碍, dtype: float64
三、数据分析
In [28] :
getTab(data[~data['职业'].isin(['主管 ','科学家 ','销售代表','软件工程师'])],'职业'Out [28] :

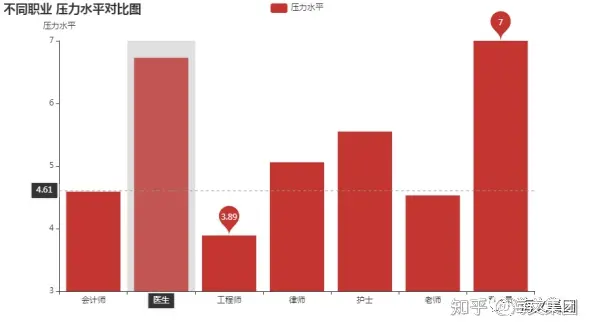
不同职业各指标的对比图,由于部分职业人数很少不太具有代表性 ,因此把【'主管','科学家','销售代表','软件工程师'】的记录进行剔除,根据结果可以得出以下结论:
- 在性别中,除了工程师性别比为49%外,其余职业基本偏向一边 ,如医生、律师、营业员基本全为男生,会计师、护士和老师则基本为女生;
- 在是否高血压中,可以发现,医生里高血压占比仅6% ,而同为医疗职业的护士则高达92%。
- 工程师的压力水平最小,平均心率最低,睡眠时长和睡眠质量最高
- 而营业员的压力水平最大,平均心率最高,全为男性且有高血压,睡眠时长及质量都最差,身体活动水平最低...
珍爱生命,远离营业员...(仅针对本数据得出此结果/(ㄒoㄒ)/~~ )
不同BMI 各指标 的对比图,可以看出:
- 正常体重的受访者压力水平明显低于其余受访者;
- 超重的受访者平均年龄较高,为47.89 ;
- 超重的女性占比明显高于男性,达到72% ;
- BMI正常的受访者的人基本没有高血压;
- 超重和肥胖的受访者睡眠时长和睡眠质量均明显低于BMI正常的;
- 超重和正常的受访者平均步数基本一致,但身体活动水平明显高于其他(那为什么会超重???)
是否睡眠障碍的各指标对比图,可以看出:
- 没有睡眠障碍的受访者平均的压力水平、年龄、心率、收缩压、舒张压、高血压比例均低于其他失眠或睡眠呼吸暂停的患者
- 而男性占比、睡眠时长及睡眠质量高于其余患者,且每日步数和身体活动水平处于中间
- 高血压患者在失眠和睡眠呼吸暂停的患者里占比高达 96% 明显大于无睡眠障碍的受访者中高血压的占比( 32% )
- 从性别上看,失眠患者中性别比例接近1 :1 ,但是在睡眠呼吸暂停的患者里, 女生明显多于男性
初步结论是,每日的适当运动有助于睡眠,而过多的运动可能会导致睡眠呼吸暂停
四、模型预测
In [29] :
data['BMI_'] = OrdinalEncoder().fit_transform(data['BMI'].values.reshape(-1, 1))
X = data.loc[:,~data.columns.isin(['ID','血压','睡眠障碍','职业','BMI'])] Y = data['睡眠障碍'].ravel()
xtrain,xtest,ytrain,ytest = train_test_split(X,Y,test_size=0.3)In [30] :
score_modellist = []
#存储各个模型的准确度1、决策树
In [31] :
from sklearn.tree import DecisionTreeClassifier as DTC
tr = []
te = []
for i in range(10):
clf = DTC(random_state=1,max_depth=i+1)
clf = clf.fit(xtrain,ytrain)
score_tr = clf.score(xtrain,ytrain)
score_te = cross_val_score(clf,X,Y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color='red',label='train')
plt.plot(range(1,11),te,color='blue',label='test')
plt.xticks(range(1,11))
plt.legend()
plt.show()
score_modellist.append(max(te))0.8858463726884779
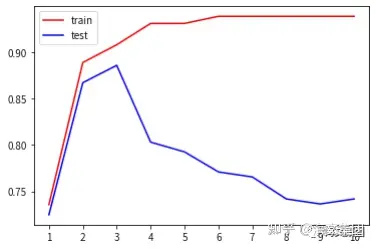
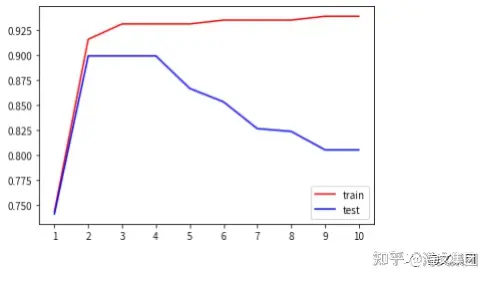
2、随机森林
In [32] :
from sklearn.tree import DecisionTreeClassifier as DTC
tr = []
te = []
for i in range(10):
clf = DTC(random_state=1,max_depth=i+1)
clf = clf.fit(xtrain,ytrain)
score_tr = clf.score(xtrain,ytrain)
score_te = cross_val_score(clf,X,Y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color='red',label='train')
plt.plot(range(1,11),te,color='blue',label='test')
plt.xticks(range(1,11))
plt.legend()
plt.show()
score_modellist.append(max(te))0.8990753911806543
3、SVM
In [33] :
from sklearn.svm import SVC
sv_clf = SVC(gamma='auto')
sv_clf.fit(xtrain, ytrain)
print(cross_val_score(sv_clf,X,Y,cv=10).mean())
score_modellist.append(cross_val_score(sv_clf,X,Y,cv=10).mean())0.8184210526315789
4、 KNN
In [34] :
from sklearn.neighbors import KNeighborsClassifier
kn_clf = KNeighborsClassifier(n_neighbors=6)
kn_clf.fit(xtrain, ytrain)
print(cross_val_score(kn_clf,X,Y,cv=10).mean())
score_modellist.append(cross_val_score(kn_clf,X,Y,cv=10).mean())0.8615220483641537
5、模型对比
Out [29] :
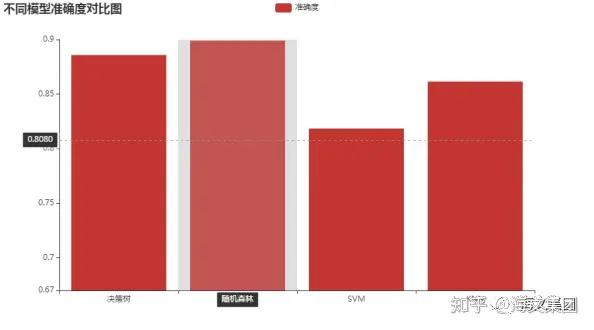
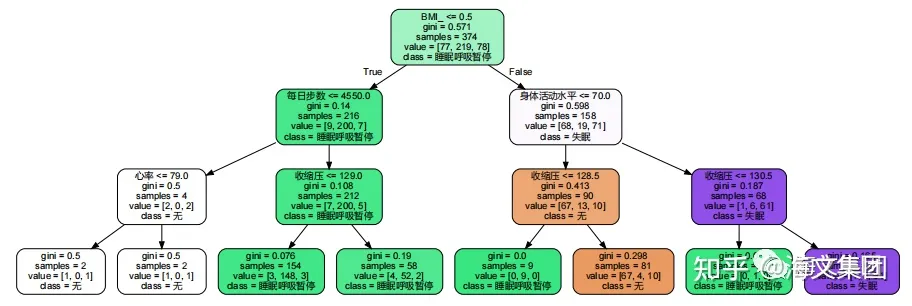
由于决策树与随机森林结果接近,因此对决策树进行可视化,查看影响睡眠的因素。
Out [30] :

















 1559
1559

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









