






一、前言
网络原理
1 -> 应用层
打交道最多的协议层 经常要自定义协议层
a -> 明确需求
客户端和服务器之间要传递哪些信息
b -> 约定格式
网络上传输的是 字符串/二进制bit流
需要把结构化数据转成上述的 字符串/二进制bit流. 序列化/反序列化
2 -> 传输层
2.1 校验和
网络传输过程中,数据可能会坏掉.
光信号 / 电信号 传输的.收到外界环境的干扰,可能会发生 bit翻转.
UDP中,校验和,使用比较简单的方式,CRC算法来完成校验.循环冗余检验.
UDP数据报发送方,在发送之前,先计算一遍CRC,把算好的CRC值放到UDP数据报中.(设这个CRC值为value1)
接下来这个数据报通过网络传输到达接收端,接收端收到这个数据之后,也会按照同样的方法,再算一遍CRC的值,得到的结果就是value2,比较自己计算的value2和value1知否相同,如果是一致的,就说明数据是OK的,如果不一致,传输过程中出现了比特翻转了.
这种CRC算法中,如果只有一个bit发生了bit翻转,那一定能发现问题.
如果两个或多个bit位发生翻转,有可能恰好校验和与之前一致. ( 概率比较低,可以忽略不计 )
除了CRC之外,还有一些更高精度的校验和算法.
2.2 md5算法
接下来,我们来介绍一下md5的特点
1. 定长
无论原始数据多长,算出来的 md5 的最终值都是固定长度.
( 常见的md5 有16位版本(2字节),32位版本(4字节),64位版本(8字节)
2. 分散
计算 md5 的过程中,原始数据,只要变化一点点,算出来的 md5 值就会差异很大.
网络传输中,如果出现bit翻转,就意味着只是极少的bit翻转了.
即使是只翻转了1 bit,最终得到的 md5 的值都会差异很大.
这样的特性,也决定了 md5 也可以作为一个 字符串 hash 算法.
3. 不可逆
给你一个源字符串,计算 md5 的值非常简单
但是给你一个算好的 md5 的值,让你把他还原为原始的字符串,理论上是无法完成的.
原始的字符串 => md5 这个过程,有很多的信息损失了,直接还原不行.
二、TCP协议
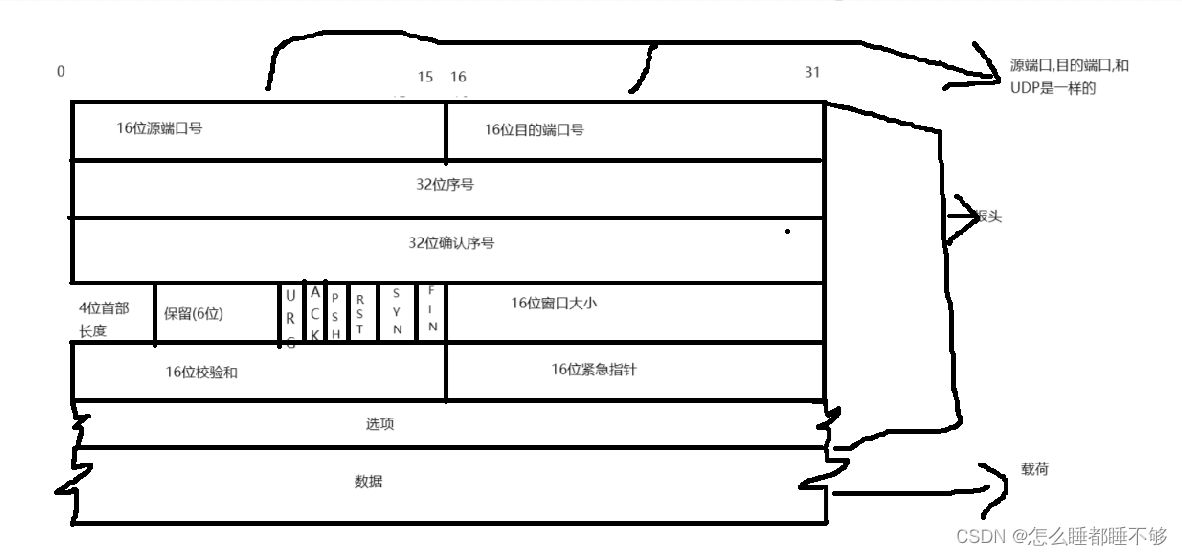
4位首部长度( 报头长度) :
TCP报头中的前 20 个字节是固定长度的.后面这里包含了 " 选项(optional)部分 -> 可选的,可有可无的.选项部分可以有,也可以没有,可以有一个也可以有多个.
保留(6位) reserved保留位:
TCP设定报头的时候,就提前准备了保留位,已备不时之需.
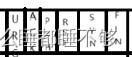
6个标志位,TCP非常核心的部分
16位检验和:
把报头和数据载荷放到一起计算校验和
TCP内部的机制是很多的,上述报头字段都是针对TCP的各个机制的支撑属性,需要了解TCP的其他机制,才能认识报头的含义.
三、可靠传输
TCP的初心就是为了解决"可靠传输"问题.
网络通信过程是复杂的,无法确保发送方发出去的数据,100%能到达接收方.
此处可靠性,只能"退而求其次",只要尽可能的去进行发送了,发送方能够知道,对方是否收到,就认为这个是可靠传输了.
1 -> 用来确保可靠性,最核心的机制,称为"确认应答"
对发送方发送的数据,会发送应答.
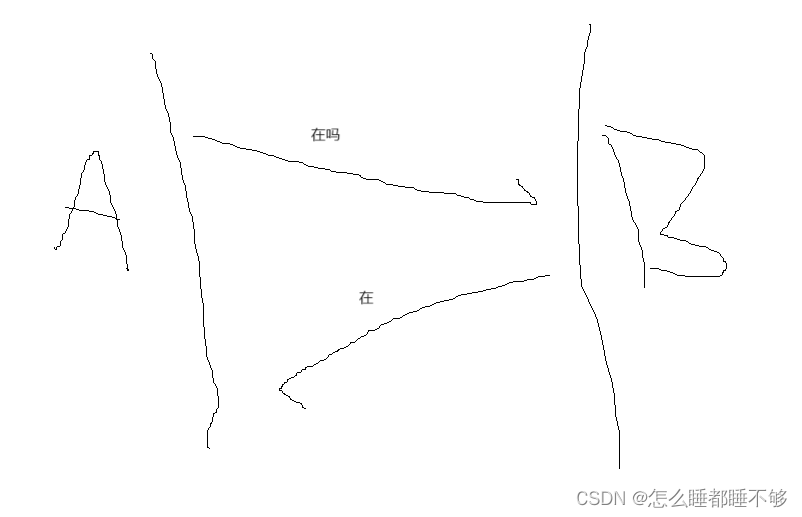
如上图,A在向B发送信息后,B会给与回应.
但是,网络传输的过程中是很复杂的.比如,我们预想的情况是这样对问题分别回答.
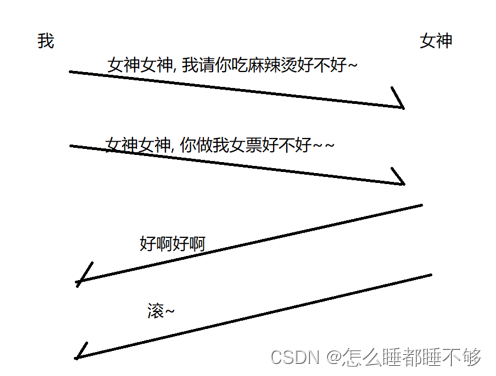
但是,网络传输的过程中可能会出现 " 后发先至 " 的情况.
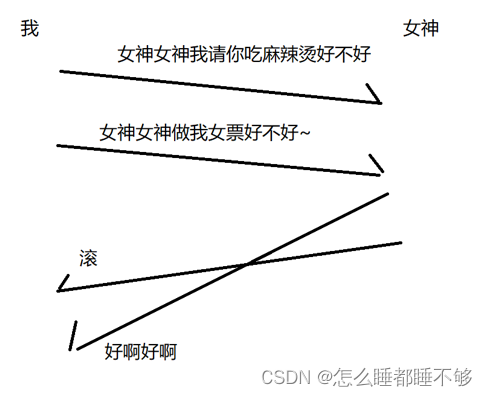
这就导致了我们看起来,女神拒绝了吃麻辣烫,同意了当我女票.
为了解决上述问题,引入了序号和确认序号,对于数据进行编号.
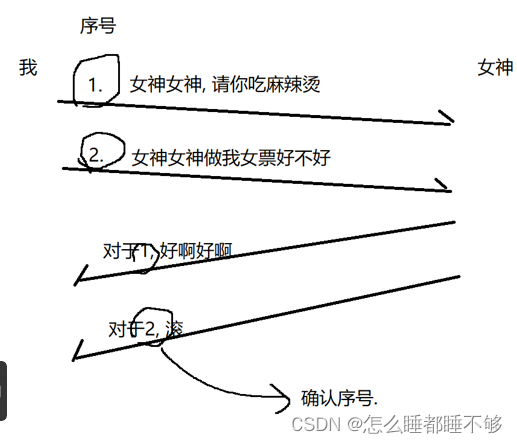
实际上,TCP的序号和确认序号都是以字节来进行编号的.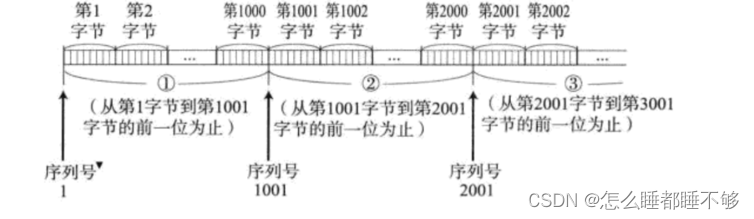
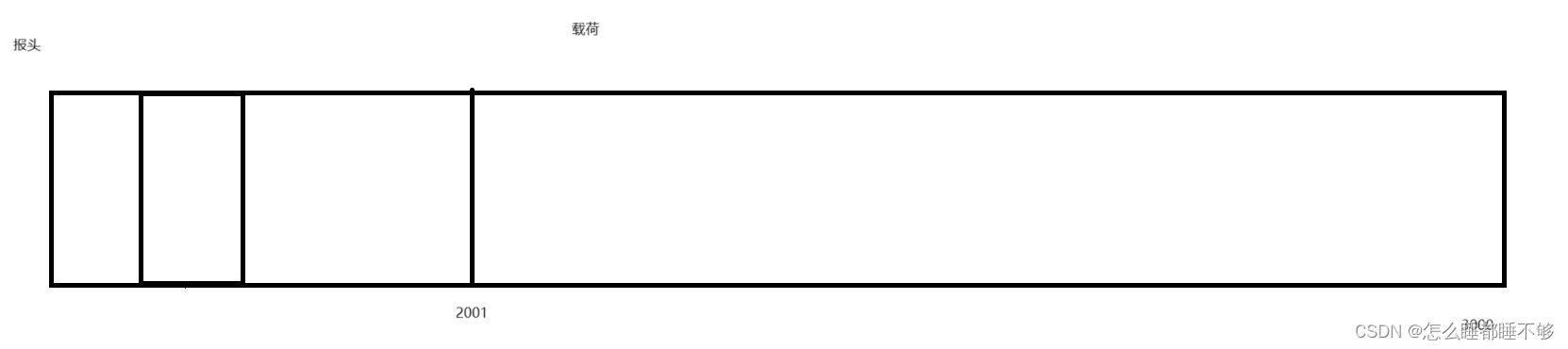
报头中的序号只能存一个
假设载荷有1000个,从2001到3000,
由于序号是连续的,只需要在报头中保存第一个字节的序号,即可后续字节的序号都是很容易计算得到的
应答报文中的确认序号,是按照发送过去的最后一个字节+1来进行设定的.
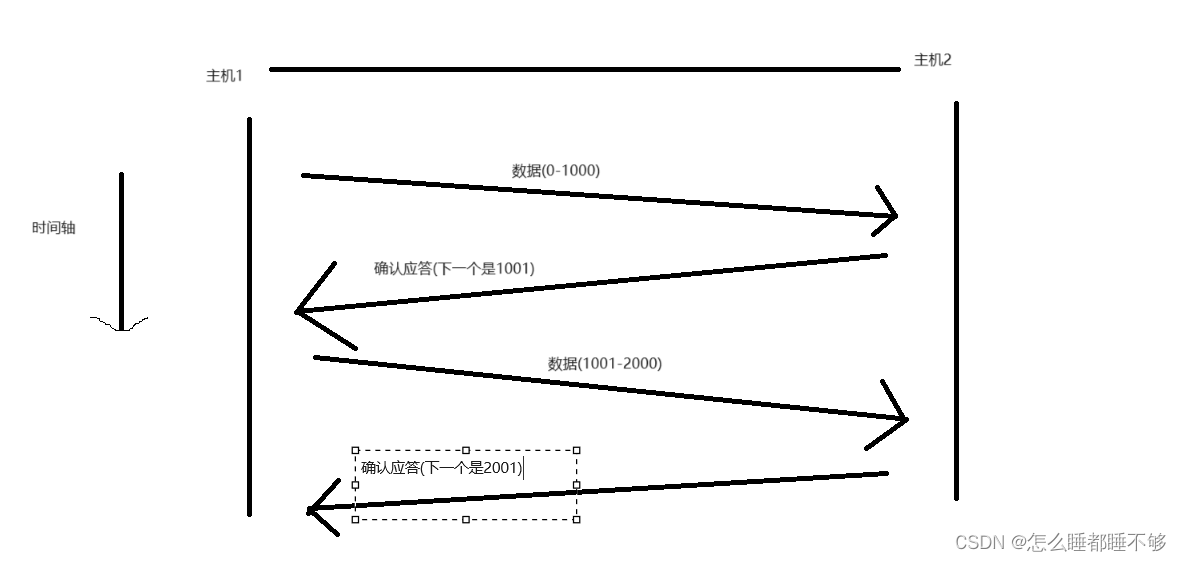
主机B收到了1-1000这些字节数据之后,反馈一个应答报文,应答报文中的确认序号的值就是1001.
1001的含义,有两种理解方式:
1. <1001的数据都收到了,
2. 发送方接下来要给我发 1001 开始的数据了.
TCP的确认应答是确保TCP可靠性的最核心机制.
确认应答中,通过应答报文来反馈给发送方,当前的数据正确收到了.
应答报文也叫ACK报文,acknowledge 单词的缩写.
![]()
ACK这个位置平时是0,如果当前报文时应答报文,这一位就是1.
2 -> 超时重传,是确认应答的补充.
如果一切顺利,通过应答报文就可以告诉发送方,当前数据是不是成功收到.
但是,网络上可能存在 " 丢包 " 情况,如果数据包丢了,没有到达对方,对方自然也没有ack报文了.
这个情况下,就需要超时重传了.
TCP的可靠性就是在对抗丢包.期望在丢包客观存在的背景下,也能够尽可能的把包给传过去.
发送方发送了数据之后,要等.
等的时间里,收到了ack(数据在网络上传输,需要时间)
如果等了好久,ack还没收到,此时发送方就认为数据的传输出现丢包了
当认为丢包了之后,就会把刚才的数据包再传输一次.就是(重传)
等待的过程有一个时间的阙值(上限),就是(超时)
上述的过程中,是认为没收到ack的数据包,但是也有可能是传输过去的数据丢了.
数据丢了还是ack丢了,发送方的角度来看,是区分不了的,都是ack没收到.
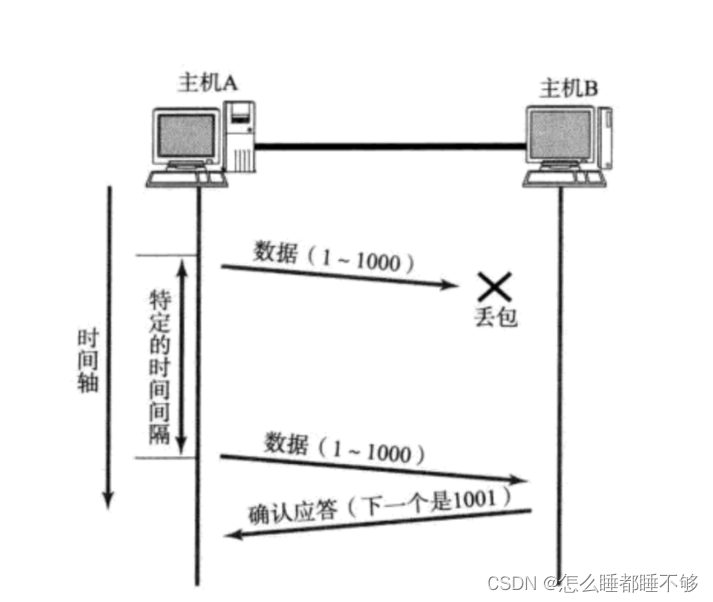
这种情况,接收方没收到数据,就应该再次发送.
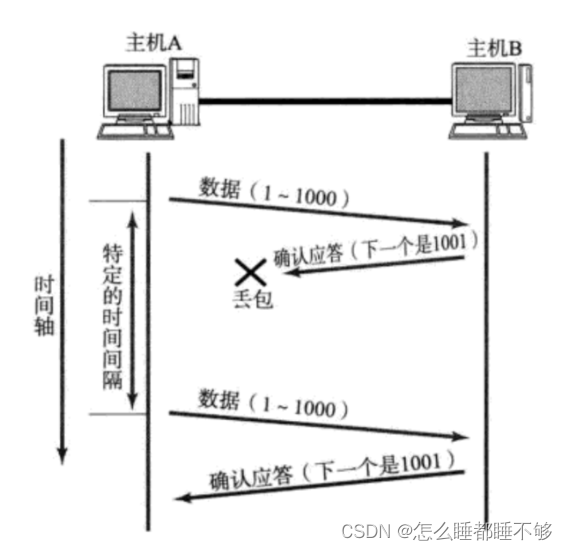
但是,这种情况的时候,是ack丢失,再传输一次,接收方就会收到两份相同的数据.
TCP socket 再内核中存在接收缓冲区(一块内存空间)
发送方发来的数据,是要先放到接收缓冲区中的.
然后应用程序调用 read / scanner.next 才能读到数据
这里的读操作其实是读接收缓冲区.
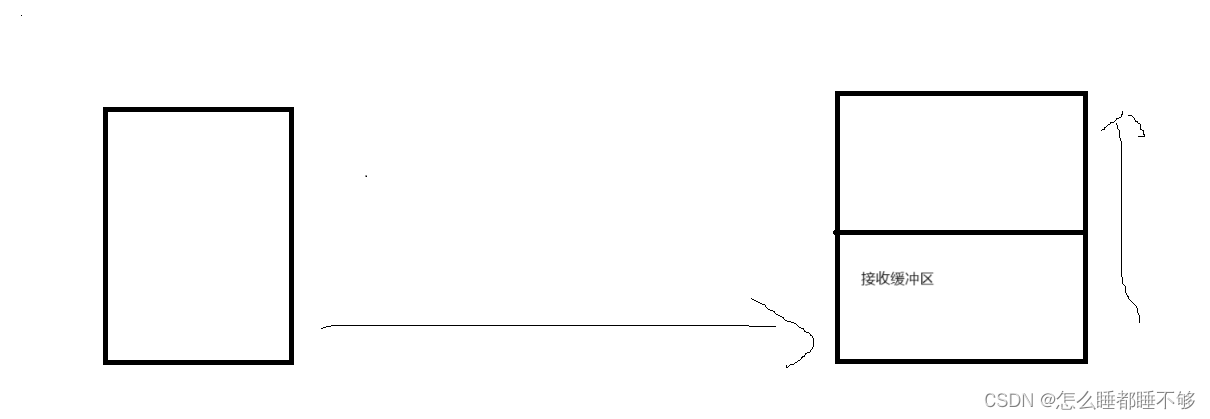
当数据到达接收缓冲区的时候,接收首先会先判定以下看当前缓冲区中是否已经有这个数据
(或者曾经有过)
如果已经存在或者存在过,就直接把重复发来的数据就丢弃了
就能确保应用程序,调用 read /scanner.next的时候,不会出现重复数据了.
接收方如何判定这个数据是否是" 重复数据"
可信判断依据: 数据的序号.
1. 数据还在接收缓冲区里,还没被read走
此时,拿着新收到的数据,和缓冲区的所有数据的序号比对一下,看看有没有一样的.
2. 数据在接收缓冲区中,已经被read走了,此时新来的数据序号无法直接在接收缓冲区中查到.
应用程序读走数据的时候,是按照序号的先后来的.
此时socket api 中就可以记录上次读走的最后一个字节的序号是多少
此时就可以把新收到的数据和这个记录对比.
接收缓冲区,除了能够帮助我们进行去重之外,还能够进行排序.
对收到的数据进行排序,按照序号来排序,确保应用程序读到的数据和发送的数据顺序是一样的.
上述的,ack重传,保证顺序,自动去重,都是TCP内置的,我们使用api的时候,outputStream.write()只需要调用这样一个简单的代码,上述功能就都自动生效了.
超时重传,超时是会重传,重传也不是无限的重传,重传的过程也是有一定策略的.
1. 重传的次数是有上限的,重传到一定程度,还没有ack,就尝试重置连接,如果重置也失败,就直接放弃链接.
2. 重传的超时时间阈值也不是固定不变的,随着重传次数的增加而增大.(重传频率越来越低)















 252
252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









