






马上快到暑假了,想不想监视最实惠,最便宜的机票呢?对于我这个囊中羞涩的学生党来说肯定是的,所以今天突发奇想写了一小部分爬取携程机票的脚本。后续可以接入同程旅行,飞猪等平台的监视模块。有待更新
一,准备安装需要的包
from selenium.webdriver.edge.options import Options
from bs4 import BeautifulSoup
from selenium import webdriver
import time可以使用pip指令安装,本人是用pycharm终端的pip指令安装的。
pip install selenium
pip install beautifulsoup4
#time是python内置库,所以不需要安装二,分析网页
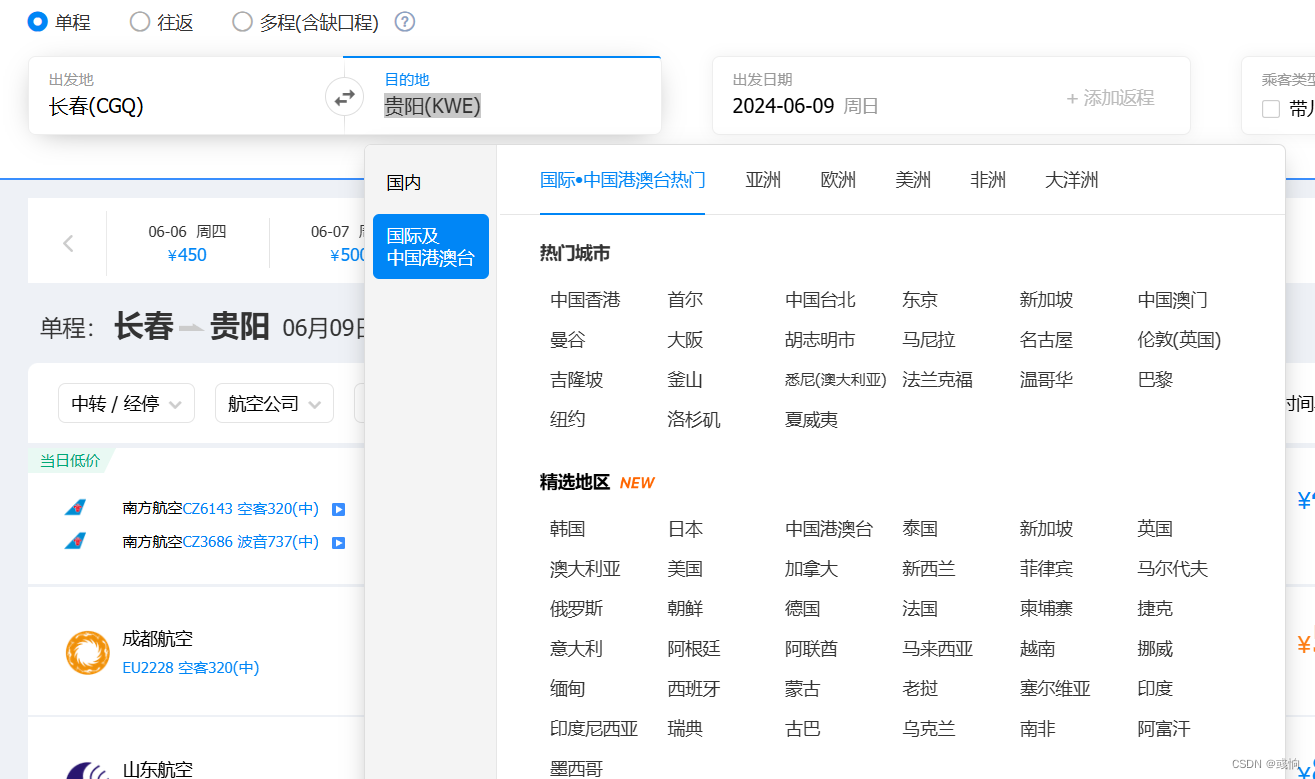
这里的url分析以长春到贵阳机票查询预订-长春飞贵阳特价机票价格-携程飞机票 (ctrip.com)为例
https://flights.ctrip.com/online/list/oneway-cgq-kwe?depdate=2024-06-09&cabin=y_s_c_f&adult=1&child=0&infant=0
#其中可以看到cgq和kwe分别代表地区的一个编号,2024-06-09则是代表日期,所以我们可以通过改变日期来进入不同页面。
通过查看请求发现在请求里抓不到包,(我之前记得我好像用请求获取信息过一次,不知道为什么找不到了,可能记错了,也有可能是我菜)所以我选择用selenium。
三,获取源代码
def get_data(date):
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
# 打开目标网页
driver.get(f'https://flights.ctrip.com/online/list/oneway-cgq-kwe?_=1&depdate={date}&cabin=Y_S_C_F&containstax=1')
# 等待页面加载完成
time.sleep(2) # 根据需要调整等待时间
# 获取页面高度
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# 模拟用户滚动页面
driver.execute_script("window.scrollBy(0, 600);") # 每次向下滚动 1000 像素
# 等待加载新内容
time.sleep(5) # 根据需要调整等待时间
# 计算新的页面高度并与之前的页面高度进行比较
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 获取加载后的页面源代码
page_source = driver.page_source
return page_source这里模拟了一下用户下拉页面加载网页前端代码。所以整体速度就没有请求那种速度。
四,分析网页,获取对应信息。
这里大家可以通过浏览器的F12的开发者工具来分析html结构,去获取对应的标签信息
for i in text_data:
price = i.find_all("span", class_="price", id="travelPackage_price_undefined")
for i in perice:
print("价格:"+i.text)
#获取价格五,整合代码
from selenium.webdriver.edge.options import Options
from bs4 import BeautifulSoup
from selenium import webdriver
import time
def get_data(date,begin,end):
options = Options()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options) #隐藏标头
# 打开目标网页
driver.get(f'https://flights.ctrip.com/online/list/oneway-{begin}-{end}?_=1&depdate={date}&cabin=Y_S_C_F&containstax=1')
# 等待页面加载完成
time.sleep(2) # 根据需要调整等待时间
# 获取页面高度
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# 模拟用户滚动页面
driver.execute_script("window.scrollBy(0, 600);") # 每次向下滚动 1000 像素
# 等待加载新内容
time.sleep(5) # 根据需要调整等待时间
# 计算新的页面高度并与之前的页面高度进行比较
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 获取加载后的页面源代码
page_source = driver.page_source
return page_source
data=get_data("2024-06-25",CGQ,KWE)
data1=BeautifulSoup(data,"html.parser")
try:
for n in range(0,15):
text_data=data1.find_all("div",attrs={'index':{n}})
id = text_data[0].find_all("div", class_="flight-airline")
for i in id:
print(i.text)
time=text_data[0].find_all("div",class_="depart-box")
for i in time:
print("起飞:"+i.text)
time_end=text_data[0].find_all("div",class_="arrive-box")
for i in time_end:
print("到达:"+i.text)
perice=text_data[0].find_all("span",class_="price",id="travelPackage_price_undefined")
for i in perice:
print("价格:"+i.text)
print("--------------------------------------------------------------------------------------------------------------")
except:
print("error")城市的编号可以去查 ,(下次更新我可以用他的编号在代码中用字典来储存,这样能方便很多。)
六,结果展示
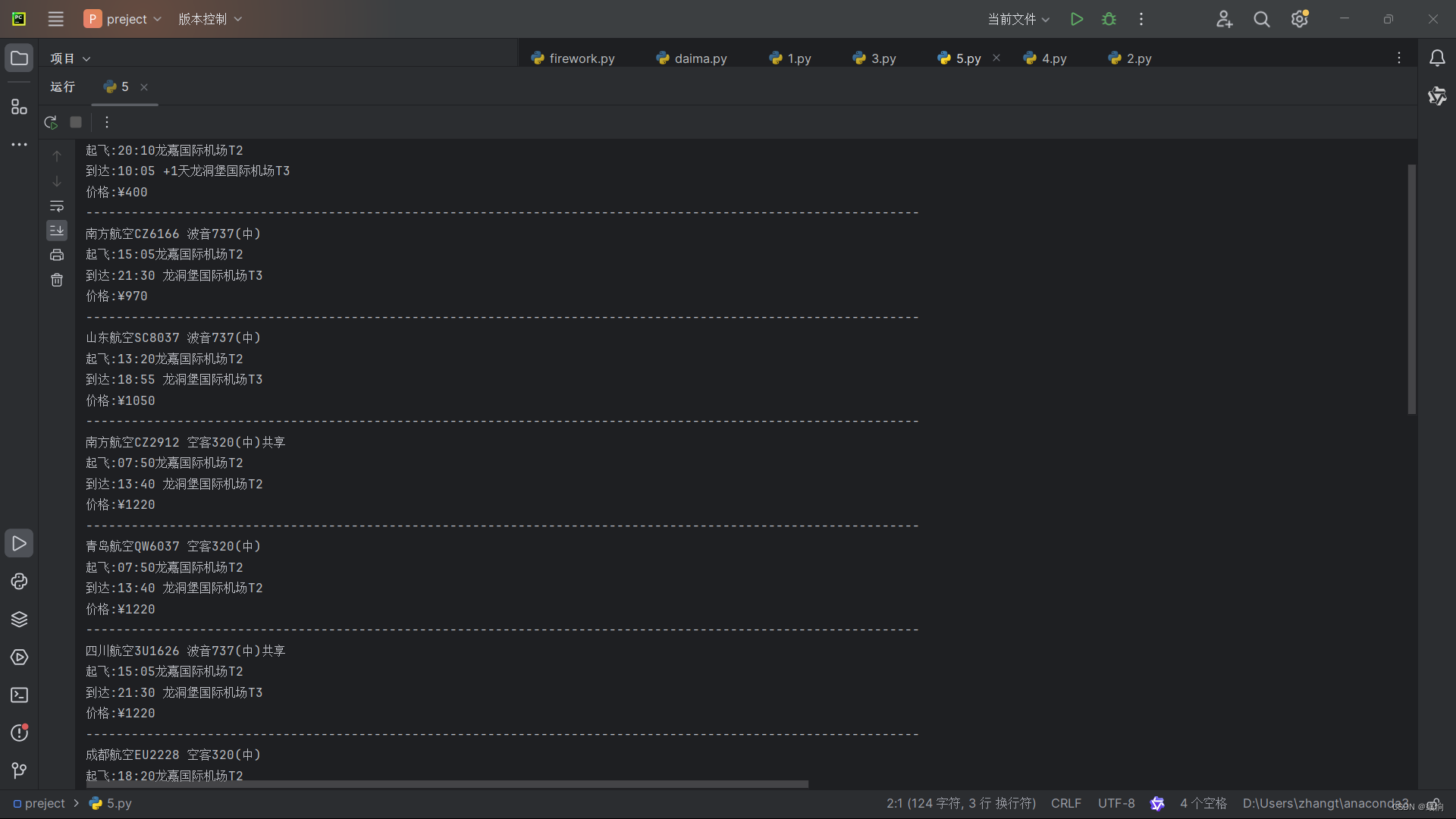
后面可以通过爬到的数据做可视化分析,也可以增加多个平台的线程爬虫来进行平台价格比对。都可以做扩展,在日期中加上for循环,可以获取一个月内的机票价格等。















 2434
2434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









