






背景
在这之前都是用ncbi的官方工具sratoolkit,使用prefetch下载,用着除了慢一点还挺简单方便的,但是在大批的sra文件下的话就显得力不从心了,之后为了快点就了解了Aspera,看着比http快得不是一点两点,简直是一个天上一个地下。后面了解到服务器用Aspera下载会出现连接服务器超时的问题,一直得不到解决。但是查阅了很多教程发现构造下载地址的只有linux系统的shell脚本,后面就想着弄一个脚本在Windows上用Aspera下载(基于python)。
下载Aspera
因为本文是针对于windows系统,所以直接Aspera - Connect | IBM直接下载就行了
配置环境
可以参考关于NCBI上传数据时在win10下采用aspera从安装到上传的详细操作 - 知乎 (zhihu.com)我就不叙述了
获取run
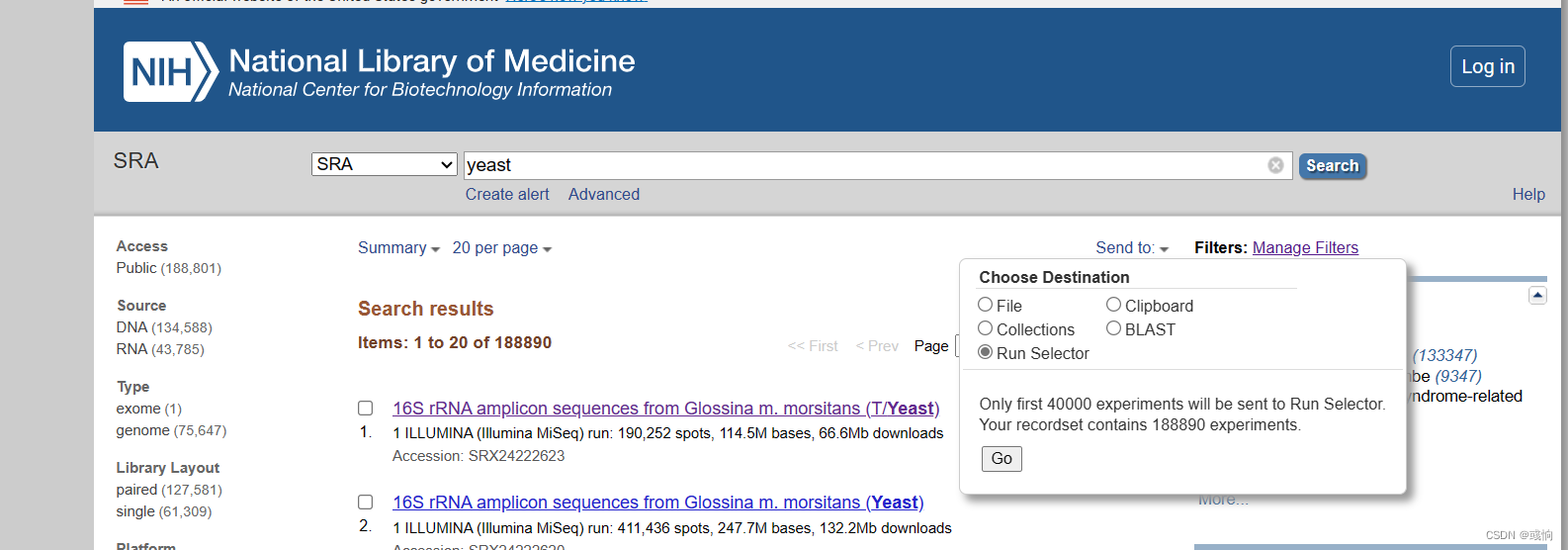
在运行选择器上获取run列表
通过run获取下载地址
当有了run列表后我们不可能一个一个的去ENA搜索他的sra下载地址。这里我有一个run列表txt文件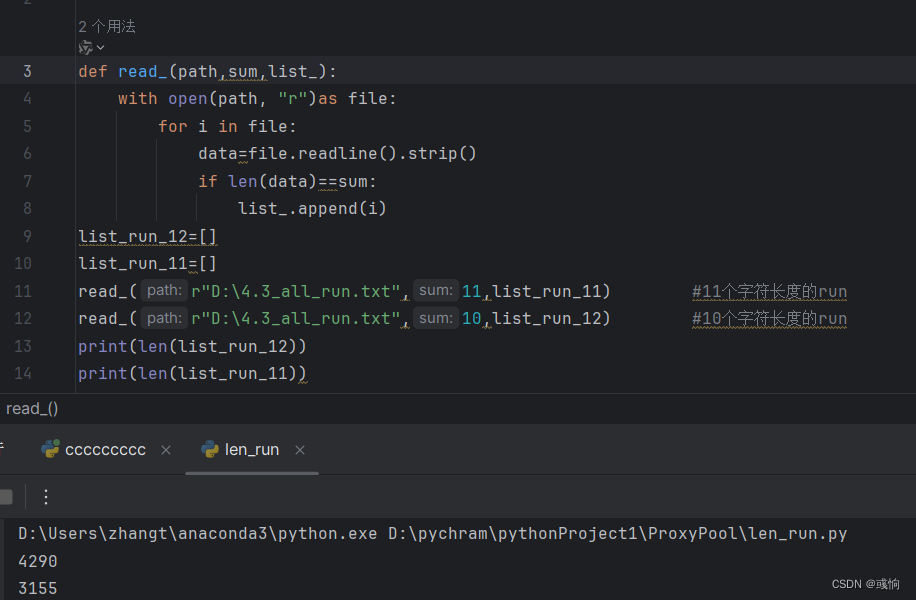
7000多个run如果去查他的bioproject的话得查到猴年马月。所以我们尝试构造一下他的下载地址
ascp -T -l 300m -P33001 -i [asperaweb_id_dsa.openssh所在路径] [ebi或ncbi数据下载地址] [文件保存路径]
fasp.sra.ebi.ac.uk:/vol1/fastq/SRR168/029/SRR16820629/SRR16820629_1.fastq.gz
fasp.sra.ebi.ac.uk:/vol1/fastq/SRR168/029/SRR16820629/SRR16820629_2.fastq.gz
fasp.sra.ebi.ac.uk:/vol1/fastq/SRR143/089/SRR14372089/SRR14372089_1.fastq.gz
fasp.sra.ebi.ac.uk:/vol1/fastq/SRR143/089/SRR14372089/SRR14372089_2.fastq.gz
#对于11位的观察上面两个run的下载地址会发现fasp.sraebi.ac.uk:/fastq/和.fastq.gz是固定不变的
所以我们通过run值来分析 /SRR168/是run的前6位,而/029/是0加上run的后两位,SRR16820629_1是因为该rna为双端测序。所以我们可以通过run值将11位数的run的下载地址拼凑出来
import os
openssh_path=""
save_path=""
i=r"era-fasp@fasp.sra.ebi.ac.uk:" #i值固定不变
with open(r"D:*****.txt", 'r') as file:
for id in file:
id = id.strip() # 移除行尾的换行符
num_chars = len(id)
print(f"SRRnum+1 is {num_chars}")
os.chdir(save_path)
# 根据SRR编号长度确定下载路径
if num_chars == 11:
print("SRR + 7")
x = id[:6]
y = id[-2:]
remote_path = f"/vol1/fastq/{x}/0{y}/{id}/{id}.fastq.gz"
try:
f = os.system(f"ascp -T -l 300m -P 33001 -i {openssh_path} {i}/vol1/fastq/{x}/0{y}/{id}/{id}_1.fastq.gz {save_path}")
if f==0:
f=os.system(f"ascp -T -l 300m -P 33001 -i {openssh_path} {i}/vol1/fastq/{x}/0{y}/{id}/{id}_2.fastq.gz {save_path}")
if f==0:
print("下载成功")
except Exception as e:
print(f"{id}是单端测序")这里我给他增加了一个try来判断该run是否是双端测序rna。
ERR2899769 fasp.sra.ebi.ac.uk:/vol1/fastq/ERR289/009/ERR2899769/ERR2899769.fastq.gz
ERR2898124 fasp.sra.ebi.ac.uk:/vol1/fastq/ERR289/004/ERR2898124/ERR2898124.fastq.gz
ERR6349255 fasp.sra.ebi.ac.uk:/vol1/fastq/ERR634/005/ERR6349255/ERR6349255_1.fastq.gz
fasp.sra.ebi.ac.uk:/vol1/fastq/ERR634/005/ERR6349255/ERR6349255_2.fastq.gz
SRR9929266 fasp.sra.ebi.ac.uk:/vol1/fastq/SRR992/006/SRR9929266/SRR9929266_1.fastq.gz
fasp.sra.ebi.ac.uk:/vol1/fastq/SRR992/006/SRR9929266/SRR9929266_2.fastq.gz
SRR6435041 fasp.sra.ebi.ac.uk:/vol1/fastq/SRR643/001/SRR6435041/SRR6435041_1.fastq.gz
fasp.sra.ebi.ac.uk:/vol1/fastq/SRR643/001/SRR6435041/SRR6435041_2.fastq.gz
ERR2898350 fasp.sra.ebi.ac.uk:/vol1/fastq/ERR289/000/ERR2898350/ERR2898350.fastq.gz
ERR2896754 fasp.sra.ebi.ac.uk:/vol1/fastq/ERR289/004/ERR2896754/ERR2896754.fastq.gz
#10位数的run同样的道理观察上面的10个字符的run,我们同样可以推导出构造方法
import os
openssh_path=""
save_path=""
i=r"era-fasp@fasp.sra.ebi.ac.uk:" #i值固定不变
with open(r"D:\*****.txt", 'r') as file:
for id in file:
id = id.strip() # 移除行尾的换行符
num_chars = len(id)
print(f"SRRnum+1 is {num_chars}")
os.chdir(save_path)
# 根据SRR编号长度确定下载路径
if num_chars == 10:
print("SRR + 6")
x = id[:6]
y=id[-1:]
remote_path = f"/vol1/fastq/{x}/00{y}/{id}/{id}_fastq.gz"
try:
f=os.system(f"ascp -T -l 300m -P 33001 -i {openssh_path} {i} /vol1/fastq/{x}/00{y}/{id}/{id}_1.fastq.gz {save_path}")
if f==0:
print(f"{id}是双端测序")
f=os.system(f"ascp -T -l 300m -P 33001 -i {openssh_path} {i} /vol1/fastq/{x}/00{y}/{id}/{id}_2.fastq.gz {save_path}")
if f==0:
print("反端下载成功")
except Exception as e:
print(f"{id}是单端测序")所以结合上述代码的我们就可以构造出一个通过run值来构造Aspera下载地址的脚本了,就不用去ENA一个一个查询了(至于12个字符的run,我目前下载的run值没有碰到过)。
总代码
import os
openssh_path=""
save_path=""
i = r"era-fasp@fasp.sra.ebi.ac.uk:"
with open(r"D:\*****.txt", 'r') as file:
for id in file:
id = id.strip() # 移除行尾的换行符
num_chars = len(id)
# 根据SRR编号长度确定下载路径
if num_chars == 11:
x = id[:6]
y = id[-2:]
remote_path = f"/vol1/fastq/{x}/0{y}/{id}/"
elif num_chars == 10:
x = id[:6]
y = id[-1:]
remote_path = f"/vol1/fastq/{x}/00{y}/{id}/"
else:
print(f"Unexpected SRR number format: {id}")
continue
try:
# 下载_1文件
result_1 = os.system(f"ascp -T -l 300m -P 33001 -i {openssh_path} {i}{remote_path}/{id}_1.fastq.gz {save_path}")
if result_1 == 0 :
print(f"{id}_1.fastq.gz 下载成功")
# 下载_2文件
result_2 = os.system(f"ascp -T -l 300m -P 33001 -i {openssh_path} {i}{remote_path}/{id}_2.fastq.gz {save_path}")
if result_2 == 0 :
print(f"{id}_2.fastq.gz 下载成功")
else:
print(f"{id}_2.fastq.gz 下载失败")
else:
a=os.system(
f"ascp -T -l 300m -P 33001 -i {openssh_path} {i}{remote_path}/.fastq.gz {save_path}")
if a==0:
print(f"{id}下载成功")
except Exception as e:
print("下载失败") #可以将id放入异常列表
with open("异常列表.txt", "w") as yc:
yc.write(id+"\n")在上述逻辑上加入错误处理后可以收集下载不了的run了。
参考:Aspera——利用SRR号批量高效下载FASTQ或SRA数据 - 知乎 (zhihu.com)















 645
645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









