






7.01
赛题背景:
蛋白质降解能力的分类模型
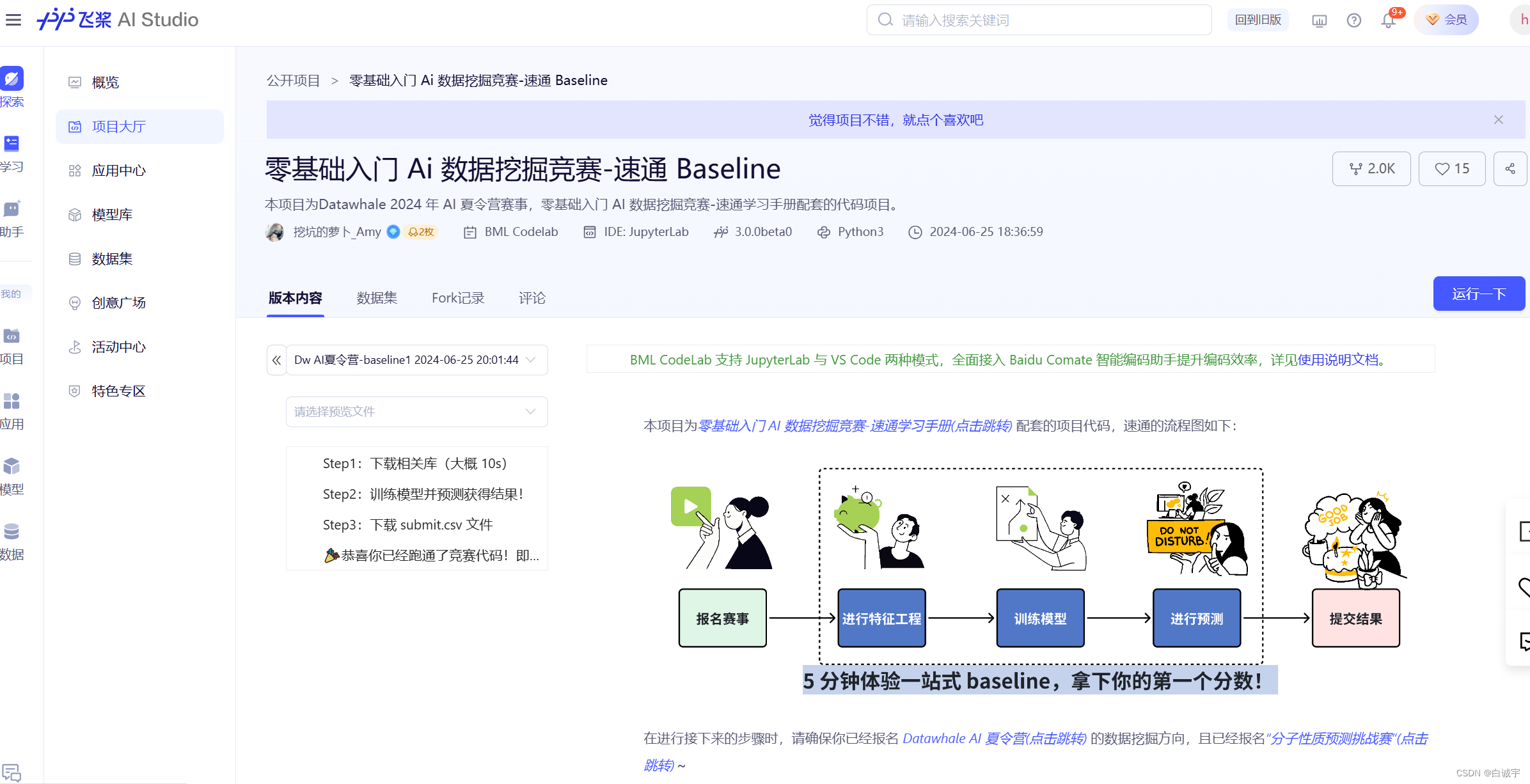
分子性质ai预测挑战赛,提交csv文件,每天最多三次提交
基础代码baseline:
大赛报名,实名认证(个人/学校)
进入飞浆AI studio
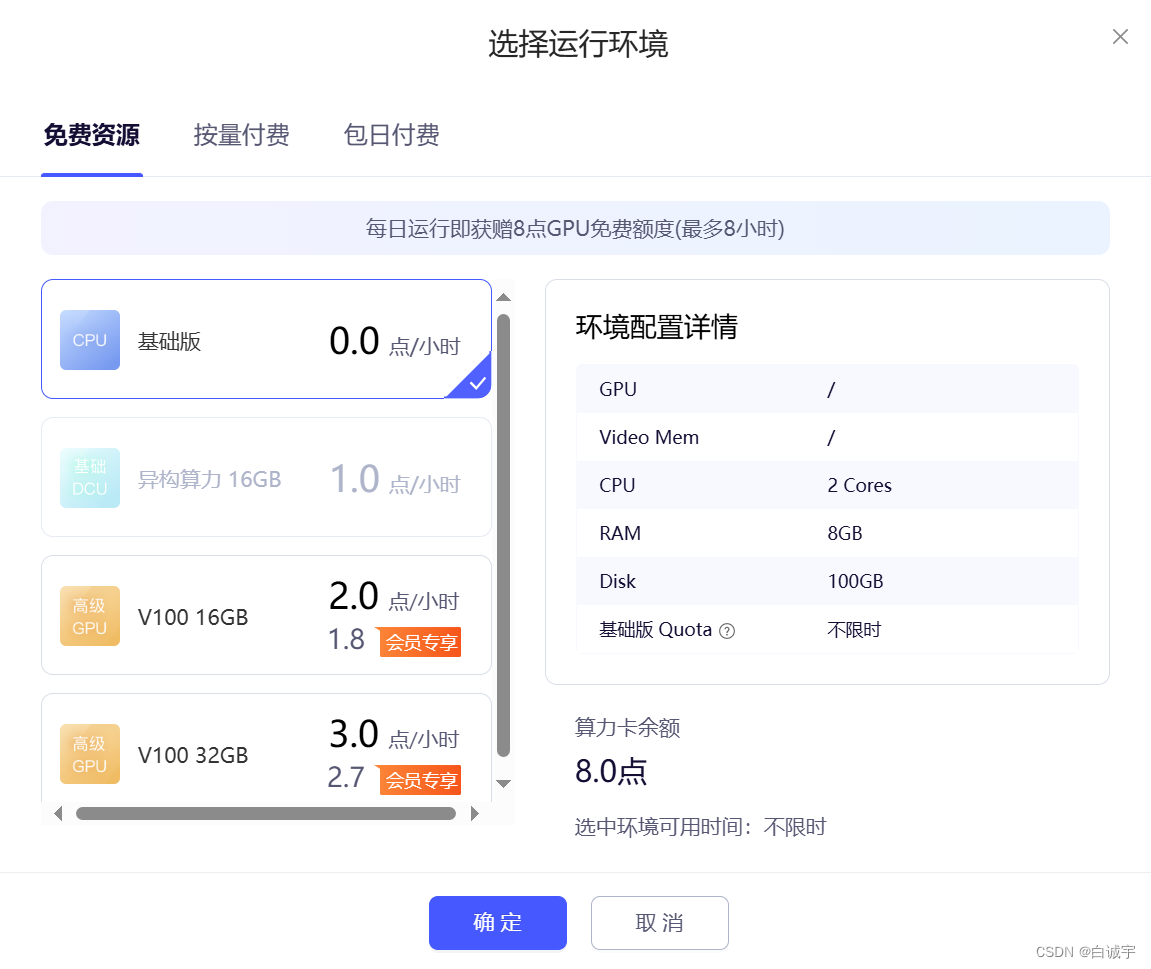
选择CPU版本的环境
lightgbm(轻量化,自动处理缺失值)
训练模型获得结果。(后期会精讲)
将训练好后得出的csv文件下载到本地然后上传到比赛提交结果。

QA环节
Tag学习笔记:各种平台发布datawhale的学习笔记。
打卡:参与接龙和表单填写。
代码运行:各种编译器都行。根据自己情况而定,可以改代码。
数据增强(我建议可以尝试用k折交叉检验),(用pandas查看,数据是有限的。做特征的筛选(选择强相关特征)。)可以尝试随机森林,svm,不推荐神经网络(需要大量数据支持)。
优化调参:优化算法(模型,集成方法),最重要的是数据的处理,将数据做的好,决定上限,模型决定下限。
记得打卡
聚沙成塔,聚水成川















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









