







博主介绍:✌Java老徐、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
2025年Java毕业设计选题推荐
Python基于Django的微博热搜、微博舆论可视化系统(V3.0)
基于Python Django的北极星招聘数据可视化系统感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
文章目录
第一章 项目简介
Python基于Django的反爬虫技术的设计,借助Python技术、django框架来搭建一个简易网站,并选用MySQL数据库进行搭建。同时运用Python编写一个爬虫程序,用来爬取该网站的内容,以此率先实现爬虫的功能。在爬取成功之后,再对网站进行反爬虫的内容设计,从而实现实现网站数据的反爬虫功能。
第二章 系统演示视频
第三章 技术栈
前端:html、css、js
后端:Python Diango
MySQL数据库
第四章 系统设计与实现
4.1 系统应用架构
此次在网站的搭建上,是基于了B/S进行了整体网站的搭建工作,在整体的搭建过程中按照B/S结构是有服务器与浏览器的护工操作过程,具体的操作如下图所示:

4.2 系统总体功能设计
此次的总体设计包括了网站的设计,在网站的设计中运用了django来进行内容设计工作。通过python进行爬虫的设计以及反爬虫的设计,整体的设计最终的目的是达到完成反爬虫功能。
4.3 数据库数据结构设计
4.3.1 数据库的概念
在此次的系统以及爬虫程序的设计过程中均需要用到数据库。网站的搭建不用多说,所以的信息内容均需要数据库进行处理,而此次设计的爬虫程序中也需要对通过爬虫来存储数据,因此此次的数据库是设计的关键内容。数据库就是数据的仓库,能够将前端程序内的信息转化为数据存储在数据库中,并且在前端发出请求调取数据时,数据库能够及时的将数据从服务器端拷贝再反馈回用户端。所以数据库是整个系统中最为重要的一项工具。
4.3.2 数据库的概念设计
数据库是可以自顶而下、自下而上进行设计的,通过数据库的概念设计是方便数据的传输,可以通过用户到数据库、也可以通过数据库传递给用户。
4.3.3 关系型数据表设计
此次的数据库表设计主要是以简单的网站内容进行设计的,包括了管理员的设定以及信息的设定,具体的展示如下。
(1)管理员信息表
表4.1管理员用户信息表
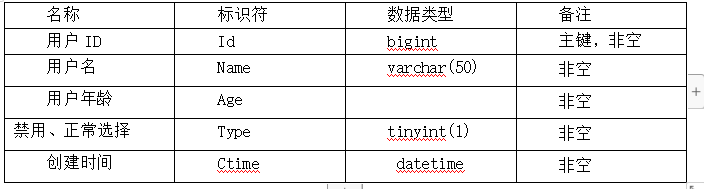
(2)新闻信息表
表4.2直播信息表

4.4 核心功能模块设计与实现
4.4.1 模块实现
通过此次的开发设计最终可以正常进行爬虫操作,当此次爬取天气信息时,可以看到,爬虫程序能够爬取到近十天的天气信息,并且能够很好的进行信息的展示,当爬取新闻信息时,也能够正常的爬取到相关的新闻资讯内容,具体如下图所示:


图4.2爬取数据图
当加入了反爬虫的程序之后,在此通过爬虫进行数据的爬取,以天气为例,在第二次爬取时,天气数据已无法进行爬取,但新闻信息仍然可以获取,在保证天气数据反爬虫成功后,在此对信息数据进行反爬虫的设计,最终使得天气、新闻等等信息都完全实现反爬操作。最终实现的反爬虫结果界面如下:

图4.2反爬虫结果图
第五章 推荐阅读
基于Python的循环神经网络的情感分类系统设计与实现,附源码
Python基于人脸识别的实验室智能门禁系统的设计与实现,附源码
Python基于深度学习的电影评论情感分析可视化系统(全新升级版)
Java基于微信小程序的校园订餐系统
Java基于SpringBoot的在线学习平台
Python基于django框架的Boss直聘数据分析与可视化系统
基于Python的机器学习的文本分类系统
Python基于Flask的人脸识别上课考勤签到系统,可准确识别人脸
Java 基于 SpringBoot+Vue 的公司人事管理系统的研究与实现(V2.0)
第六章 源码获取:
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及文档编写等相关问题都可以给我留言咨询,希望帮助更多的人


















 1234
1234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











