






机器学习-聚类算法
小白如何从0到1逆袭成为算法工程师
目录
1.有监督和无监督
1)有监督:有x值 有y值
2)无监督:没有y值 只有x(都是坐标) 聚几个类别
2.聚类算法

3.聚类算法核心思想

4.k_means算法及其优缺点
k:中心点(表示你想聚几个类别)
means:均值
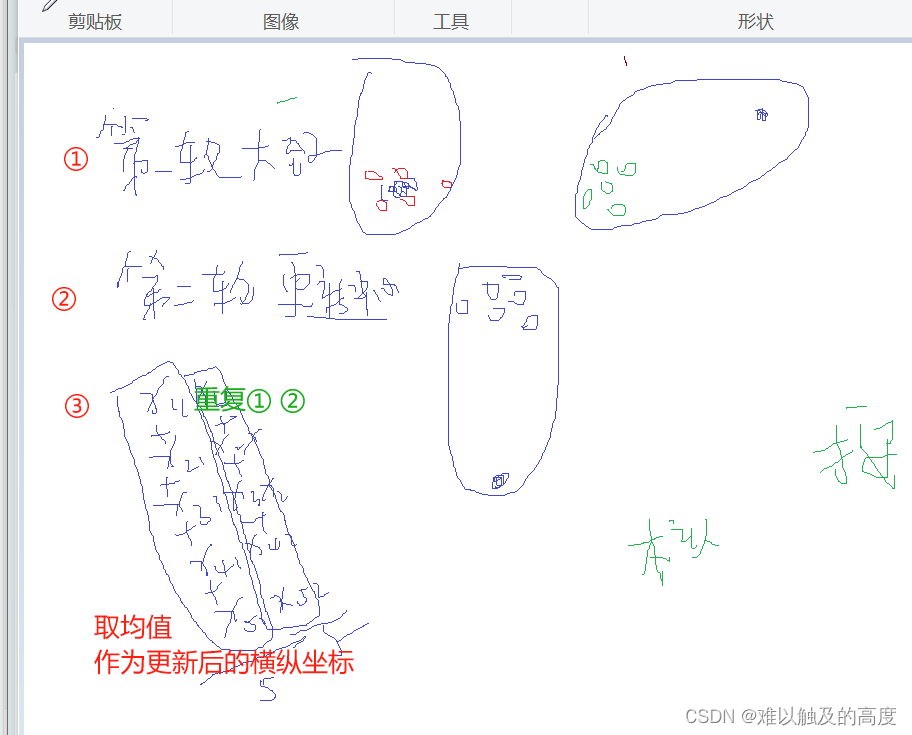
当所有的中心点都不再变化时 我们的聚类就结束了
K-means算法是一种常用的聚类算法,用于将数据集划分为K个不同的类别。这个算法的目标是将数据分成K个簇,使得每个数据点都属于距离最近的簇中心,同时使得各个簇内的数据点尽可能相似,而各个簇之间的差异尽可能大。
具体来说,K-means算法的工作流程如下:
1. 随机选择K个中心点作为初始的簇中心。
2. 将每个数据点分配到距离其最近的簇中心所在的簇。
3. 根据每个簇中的数据点重新计算该簇的中心点。
4. 重复步骤2和步骤3,直到簇中心不再发生变化或者达到预定的迭代次数。
K-means算法的优点:
包括简单易理解、计算效率高,适用于大规模数据集的聚类任务。
然而,K-means算法也有一些缺点:
比如对初始簇中心的选择敏感、对噪声和异常值敏感等。

在实际应用中,可以通过调整簇的数量K、选择合适的距离度量方法、采用加权K-means算法等方式来改进K-means算法的性能。此外,在处理高维稀疏数据时,可以考虑使用Mini-batch K-means算法或者K-means++算法来提高算法的效率和收敛性。
总的来说,K-means算法是一种强大而常用的聚类算法,可以帮助我们对数据进行有效的分组和聚类,进而揭示数据之间的潜在模式和关系,为数据分析和挖掘提供重要支持。
5.距离公式
欧氏距离
余弦夹角距离(相似度)
6.K-means算法中为什么中心点的值是所有坐标的均值
在K-means算法中,将簇中心点的值设定为该簇中所有数据点坐标的均值有其合理性和数学基础。这样做的主要原因包括以下几点:
1. 最小化方差:K-means算法的优化目标是最小化每个簇内数据点与该簇中心点之间的距离(通常采用欧氏距离)。而使用均值作为中心点的值可以确保使得所有数据点到中心点的距离之和最小。因为均值是一种使得数据点分布最集中的值,当簇中心点值设定为所有坐标的均值时,可以有效地减小簇内数据点与簇中心点之间的总距离,从而使得簇更加紧凑。
2. 减小误差:将簇中心点设定为簇内数据点坐标的均值可以减少误差,即最小化每个数据点与簇中心点之间的距离平方。通过计算每个数据点到中心点的距离差的平方的和,可以更好地表示簇内数据点与簇中心点之间的整体偏差程度,从而使得簇的划分更加准确。
3. 数学原理支持:在K-means算法的更新过程中,通过计算每个簇中所有数据点坐标的均值来更新簇中心点的值,实质上是通过最小化簇内数据点与簇中心点之间的距禮来确定簇中心的值,从而实现簇的优化和聚类。
综上所述,K-means算法中将簇中心点的值设定为该簇中所有数据点坐标的均值,是为了最小化簇内数据点与簇中心点之间的距离,减小误差,提高聚类的准确性和效率。通过使用均值作为中心点值,可以更好地优化簇的形成过程,使得簇之间的分布更加紧凑,从而更好地实现数据聚类的目标。

7.实例
1)代码展示
#coding=UTF-8
import pandas as pd
defaultencoding = 'utf-8'
import matplotlib as mpl
import matplotlib.pyplot as plt
import sys
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
import sklearn.datasets as ds#导入sklearn数据集
#1.加载数据
N=1500
#make_blobs生成团状数据,1500个样本 n_features=2列数等于2
x1,y1=ds.make_blobs(n_samples=N,n_features=2,centers=4,cluster_std=1,random_state=2)#
from sklearn.cluster import KMeans
#2.创建模型和训练模型
kmeans=KMeans(n_clusters=4,init="k-means++")
kmeans.fit(x1)#用第一份数据进行训练 求中心点及每个样本的类别
y1_hat=kmeans.predict(x1)#预测y值
#3.评估
print(kmeans.score(x1)) #所有样本到各中心点距离和相反数 越大越好
plt.figure()
plt.subplot(2,1,1)
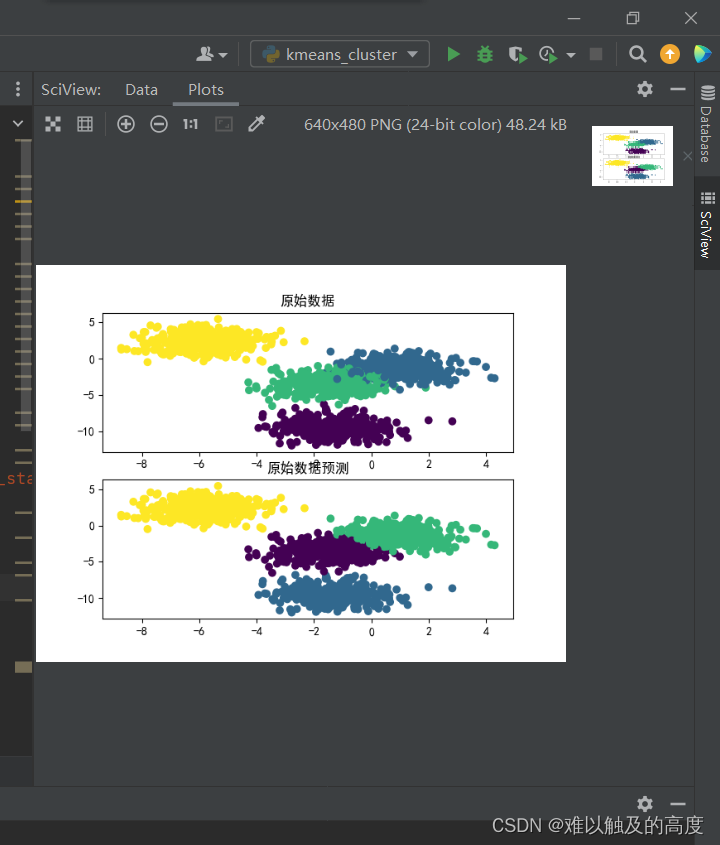
plt.scatter(x1[:,0],x1[:,1],c=y1,label="原始数据")
plt.title("原始数据")
plt.subplot(2,1,2)
plt.scatter(x1[:,0],x1[:,1],c=y1_hat,label="预测数据")
plt.title("原始数据预测")
plt.show()
#对不同方差预测不准 对旋转数据预测不准
print("样本到所有中心点距离和", kmeans.inertia_)
print("clf_KMeans聚类中心\n", (kmeans.cluster_centers_))
quantity = pd.Series(kmeans.labels_).value_counts()
print ("cluster2聚类数量\n", (quantity))
#获取聚类之后每个聚类中心的数据
# print kmeans.labels_
print(x1[kmeans.labels_==0])#打0类别样本
# print"类别为1的数据\n",(df.iloc[res0.index])
2)运行效果















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









