






1. 什么是昇思MindSpore?
昇思MindSpore是一家一站式 AI 平台,为机器学习与深度学习提供海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期 AI 工作流。

2. 什么是昇思大模型平台?
昇思大模型平台旨在为AI学习者和开发者提供在线学习的项目、模型、大模型体验和数据集的平台。我们也添加了各领域的经典数据集来帮助学习者解决AI学习过程中的一系列难题, 如高质量的数据集不易获得,以及本地难以使用大体量数据集进行模型训练等。为用户提供多种业务场景的支持。

昇思MindSpore积极探索前沿技术,支撑大模型原生高效训练。通过原创的多副本、多流水交织等8种并行技术,使集群线性度达到90%(业界不足60%),通过整图优化及下沉执行等,使得算力利用率达到55%(业界不足40%);针对集群故障率高,恢复时间长的普遍问题,通过编译快照,确定性CKPT技术实现20分钟完成故障恢复。
在大模型部署上,昇思通过训推一体的架构升级实现脚本、分布式策略,运行时的统一,Baichuan2-13B的推理部署只需1天。在大模型推理上,通过LLMServing实现推理吞吐提升2倍多;升级模型压缩工具金箍棒2.0实现千亿大模型压缩至十倍。
3. 如何使用昇思MindSpore的API?
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。在本教程中,我们使用Mnist数据集,自动下载完成后,使用mindspore.dataset提供的数据变换进行预处理。
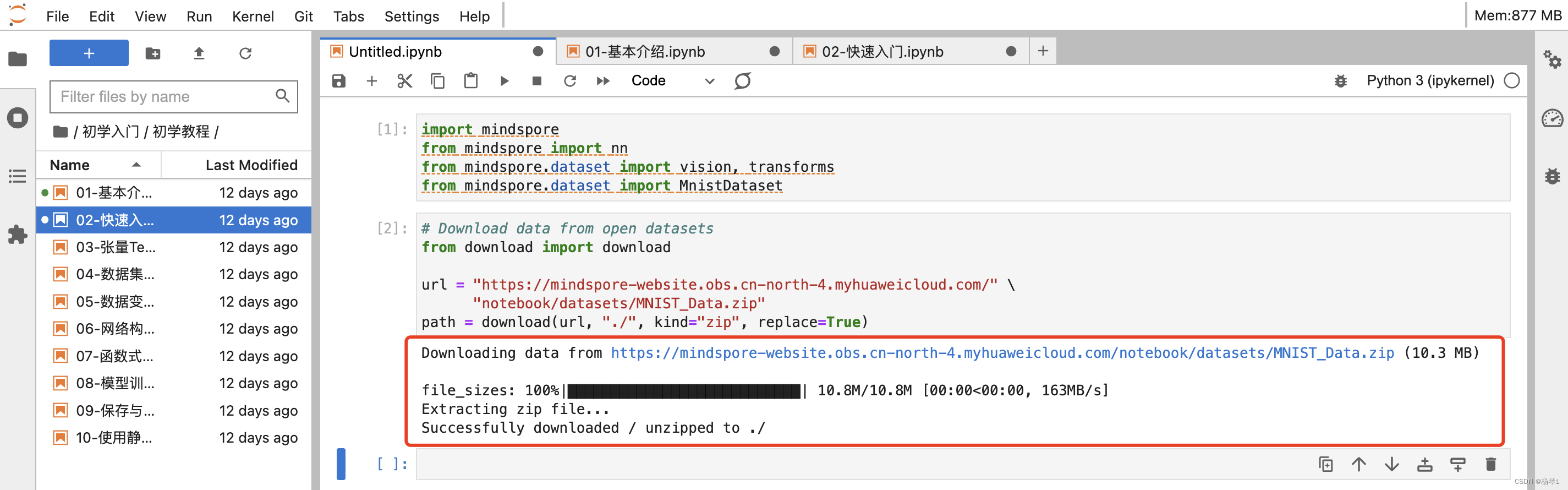
MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。这里我们使用map对图像数据及标签进行变换处理,将输入的图像缩放为1/255,根据均值0.1307和标准差值0.3081进行归一化处理,然后将处理好的数据集打包为大小为64的batch。
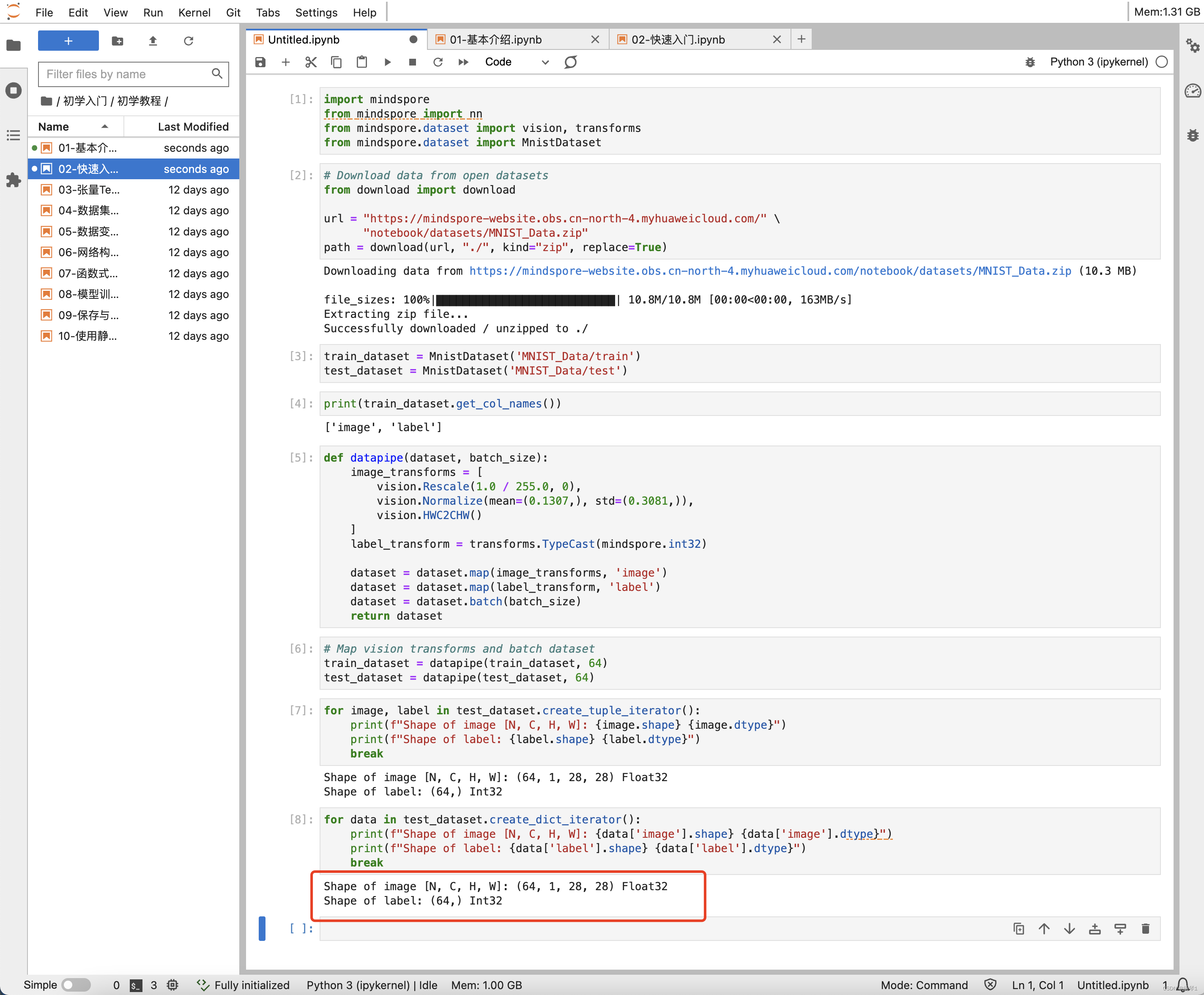
偶尔在实验中会报错,没有关系,再复制一次进行执行即可。
mindspore.nn类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承nn.Cell类,并重写__init__方法和construct方法。__init__包含所有网络层的定义,construct中包含数据(Tensor)的变换过程。
模型训练
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
- 正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
- 反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
- 参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
- 定义正向计算函数。
- 使用value_and_grad通过函数变换获得梯度计算函数。
- 定义训练函数,使用set_train设置为训练模式,执行正向计算、反向传播和参数优化。
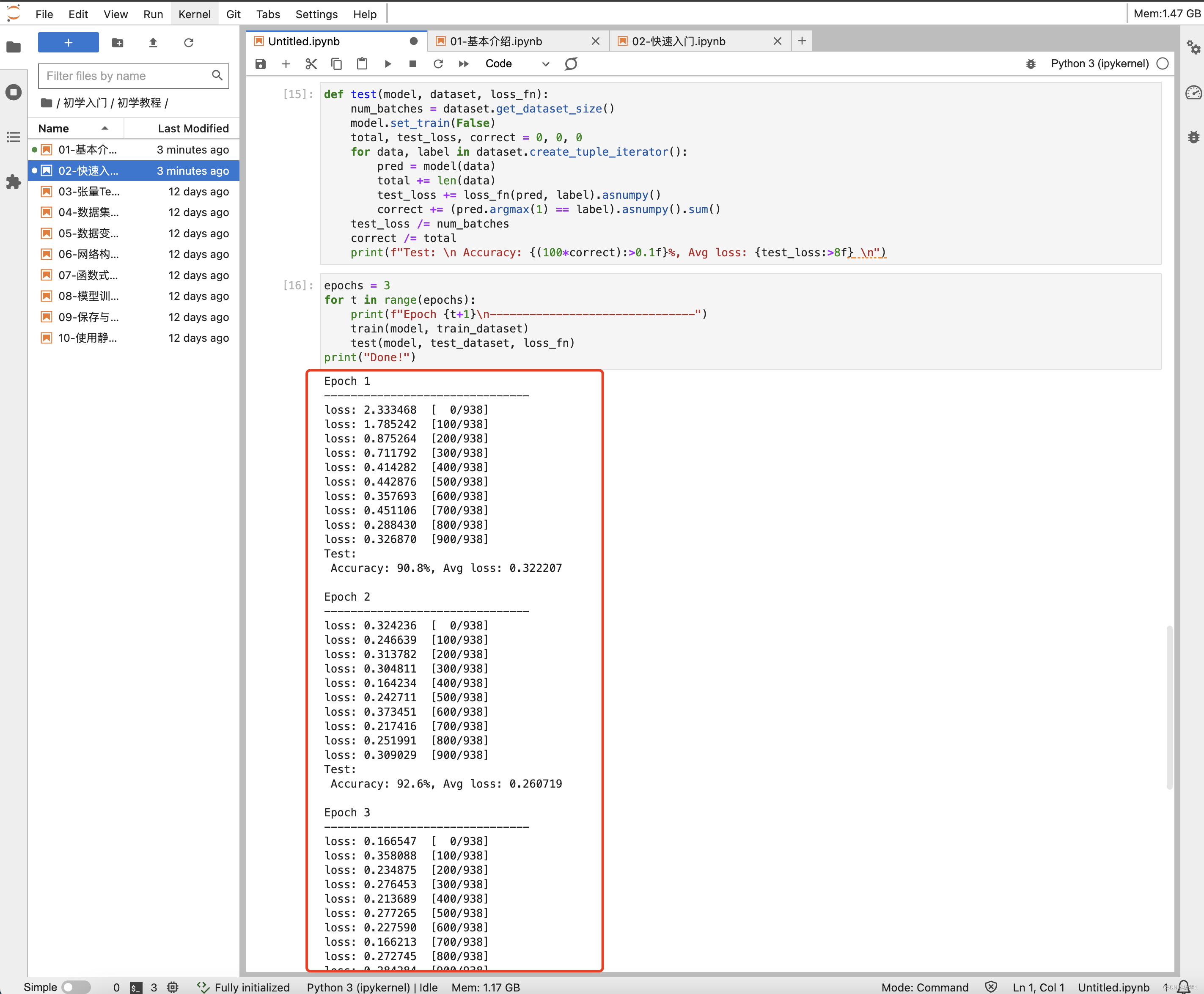
训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
4. 总结:
为降低开发门槛,昇思持续升级MindSporeTransFormers大模型套件,并提供MindSporeOne生成式套件,全流程开箱即用,一周即可完成大模型全流程的开发。
创新AI+科学计算范式,孵化科学领域基础大模型。MindSpore已在AI生物计算探索多年,联合顶级科研机构和伙伴打造了AI生物计算套件,包含蛋白质结构预测、生成等20多个SOTA模型,加速相关领域创新。
面向长远规划,昇思MindSpore深耕根技术,持续演进,助力大模型产业落地。















 607
607











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









