







一、前言
今天我要给大家分享的是如何爬取中农网产品报价数据,并分别用普通的单线程、多线程和协程来爬取,从而对比单线程、多线程和协程在网络爬虫中的性能。
目标URL:
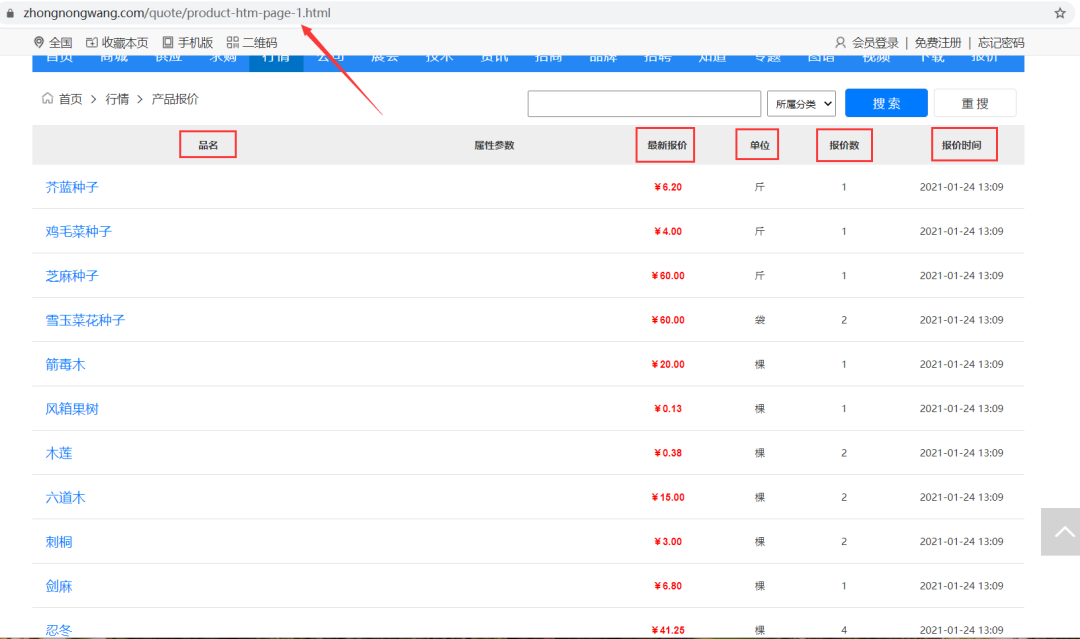
爬取产品品名、最新报价、单位、报价数、报价时间等信息,保存到本地Excel。
二、爬取测试
翻页查看 URL 变化规律:
https://www.zhongnongwang.com/quote/product-htm-page-1.html
https://www.zhongnongwang.com/quote/product-htm-page-2.html
https://www.zhongnongwang.com/quote/product-htm-page-3.html
https://www.zhongnongwang.com/quote/product-htm-page-4.html
https://www.zhongnongwang.com/quote/product-htm-page-5.html
https://www.zhongnongwang.com/quote/product-htm-page-6.html
检查网页,可以发现网页结构简单,容易解析和提取数据。

思路:每一条产品报价信息在 class 为 tb 的 table 标签下的 tbody 下的 tr 标签里,获取到所有 tr 标签的内容,然后遍历,从中提取出每一个产品品名、最新报价、单位、报价数、报价时间等信息。
# -*- coding: UTF-8 -*-
"""
@File :demo.py
@Author :
@CSDN :https://yetingyun.blog.csdn.net/
"""
import requests
import logging
from fake_useragent import UserAgent
from lxml import etree
# 日志输出的基本配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 随机产生请求头
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
url = 'https://www.zhongnongwang.com/quote/product-htm-page-1.html'
# 伪装请求头
headers = {
"Accept-Encoding": "gzip", # 使用gzip压缩传输数据让访问更快
"User-Agent": ua.random
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
print(rep.status_code) # 200
# Xpath定位提取数据
html = etree.HTML(rep.text)
items = html.xpath('/html/body/div[10]/table/tr[@align="center"]')
logging.info(f'该页有多少条信息:{len(items)}') # 一页有20条信息
# 遍历提取出数据
for item in items:
name = ''.join(item.xpath('.//td[1]/a/text()')) # 品名
price = ''.join(item.xpath('.//td[3]/text()')) # 最新报价
unit = ''.join(item.xpath('.//td[4]/text()')) # 单位
nums = ''.join(item.xpath('.//td[5]/text()')) # 报价数
time_ = ''.join(item.xpath('.//td[6]/text()')) # 报价时间
logging.info([name, price, unit, nums, time_])
运行结果如下:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









