






1.引言

你终于来辣!
<1>概念:
数据分析是利用数学、统计学理论与实践相结合的科学统计分析方法,对Excel数据、数据库中的数据、收集的大量数据、网页抓取的数据进行分析,从中提取有价值的信息并形成结论进行展示的过程。广义数据分析包括狭义数据分析和数据挖掘。狭义的数据分析通过数据的统计分析发现数据中的信息,分析数据结果背后的原因。数据挖掘则是通过习学算法和模型挖掘数据潜在规律,还可以预测数据的未来的走向。Python数据分析就是数据分析之中的方法之一,简单易学,上手快,兼容性强等多个优点。
<2>excel和python处理结构化数据的差异:
在excel中,我们可以通过选中一列数据来对其进行数据类型修改、查看列平均值、计数、求和等统计信息、排序等等操作,excel中也可以通过选中所有表格数据来构建一个【数据透视表】,进而统计表格中各个维度的统计数据;在python中,我们不能像excel一样用鼠标对结构化数据进行自由的选择。python是通过类和对象的思想将结构化数据中的【列】和【表格】封装成了【对象】,再通过该【对象】的【属性】和【方法】来对其进行操作,实现各类数据分析需求,“python的数据处理工具”是一个宽泛的词,这里我们特指【DataFrame类】和【Series类】这两个python中专门用来处理【结构化数据】的类。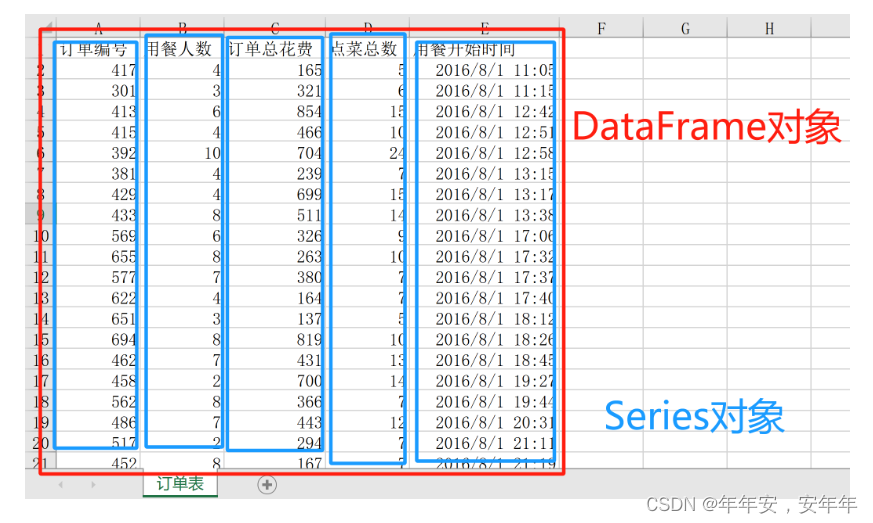
下面由我介绍一些python数据分析的方法和知识点。
2.基础数据处理
<1>导入数据:
(1)导入库:
python做数据分析是要用到库,而前面说到【DataFrame类】和【Series类】都是来自数据分析核心库【pandas】,以下是关于pandas库的一些介绍和用法:
导入方法是:import pandas as pd(一般将pandas库重命名为pd方便之后的调用);
Pandas库主要用来处理结构化数据,结构化数据可以理解为表格化数据;
Pandas库可以用来做数据处理和数据分析,如图:

(2)导入数据:
导入库后就可以导入数据用作处理,不同的格式用不同的语句导入。用于存储的结构化数据是Python中读取excel文件的方法:调用pandas库的read_excel函数,如图:

用于读取文本数据(csv文件为列),CSV文件是一种逗号分隔的文本文件,可以用excel和记事本打开,Python中读取CSV格式文件的方法:调用pandas库的read_csv函数,如图:

以上就是数据的导入,接下来介绍的是数据基础使用方法。
<2>数据结构化:
(1)Series序列对象:
对数据进行二次排列的是为Series序列对象,Series序列对象即DataFrame表格对象中的某一列数据,Series序列对象简称序列对象,其数据类型是Series。
从表格对象中提取序列对象:表格对象['列名称'];手动生成一个序列对象:pd.Series(列表对象)类生成,如图:

(2)DataFrame表格对象:
说完Series序列对象,就要说DataFrame表格对象,导入数据库表格或者excel数据时形成的数据
对象就是表格对象,表格对象的类型:DataFrame。
将数据表格化后会更容易对自己的数据进行处理,创建表格对象的方法可以通过pandas库中的DataFrame()类来创建一个表格对象;通过DataFrame()类的参数columns来设置表格对象的列名称,如图:

<3>数据处理:
(1)表格对象的增删:
通过序列对象查询数据后再对对象进行处理,对序列对象查询数据有两种方法:
loc方法,调用语法:表格对象.loc[n,'列名称'];n表示行索引,表示访问第n行;‘列名称’表示列索引,表示访问相应的列。
iloc方法,调用语法:表格对象.iloc[n,m],n表示行索引,表示访问第n行,m表示列索引,表示访问第m列。


对数据读取后,就可以进行增删,首先是增加,概念:表格对象数据新增一般指新增一列;思路:将一个序列对象赋值给表格对象新的一列;语法:表格对象['新的列名']=某个序列对象;注意:新的列名不能和表格对象中已有的列名重复。

其次是删除,概念:表格对象行或列数据的删除;语法:表格对象.drop(n,axis=0),参数n表示行或列的索引,axis默认为0,表示删除行,axis=1时删除列。

(2)分组统计分析:
多变量分组聚合:多变量分组 -- 交叉分析:

多变量聚合,语法:表格对象.groupby('分组变量')[['聚合变量1','聚合变量2']].聚合函数(),用案例:计算每辆车的总行驶时长和总行驶里程来演示。

多聚合函数,语法:表格对象.groupby('分组变量')['聚合变量'].agg([聚合函数1,聚合函数2]),用案例:计算每辆车的总行驶时长、平均行驶时长、总行驶里程、平均行驶里程来演示。
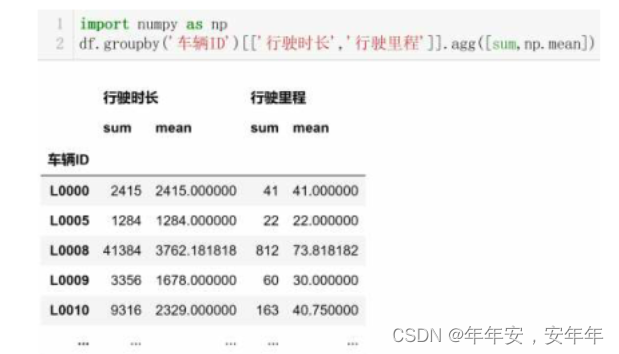
注意!由于Python没有自带平均值mean函数,故需要从numpy库引入np.mean函数用于求平均值。
3.数据预处理:
有时我们需要基于表中某个字段去匹配另一个表中的信息,从初始数据到得出分析或挖掘结果的整个过程中对数据经过的一系列操作称为数据预处理。 它主要通过一系列的方法来清理脏数据、抽取精准的数据、调整数据的格式,从而得到一组符合准确、完整、简洁等标准的高质量数据,保证该数据能更好地服务于数据分析或数据挖掘工作,通俗点来讲,就是将两个不同的表进行连接,使它们有关联。
<1>数据合并:
(1)拼接合并:
我们用一张图来概述一下拼接合并,

拼接合并的实现方法:pd.concat()函数;语法结构:pd.concat([表格对象1,表格对象2],axis=0或1));axis默认为0,表示横向拼接,axis=1时表示纵向拼接。

(2)主键合并:
主键合并的概念,基于两个表共有的主键(即某列数据)将两个表的数据根据主键相同原则进行拼接(匹配)。 同理于SQL语言中的join语句、Excel中的VLOOKUP函数。主键合并的方式:根据合并后显示数据的逻辑不同,将主键合并分为:左连接、右连接、内连接、外连接。


对不同表但有关联的数据进行合并后,可以:
-
提高数据质量:数据融合方法可以通过整合多个数据源的信息,消除噪声和错误数据,提高数据的准确性和质量。
-
增加数据价值:通过将不同来源的数据进行融合,可以获得更全面、全局的信息,从而提高数据的价值和可用性。
-
提供更准确的分析结果:数据融合方法可以将不同数据源的信息进行综合分析,从而得出更准确、可靠的分析结果,帮助决策者做出更明智的决策。
<2>数据清洗:
数据的收集不是百分百的,我们收集好数据后,有时候会出现沉余、重复、空值、缺失值(在现实的数据的产生场景中,由于人为原因或系统原因导致的数据缺失问题)等错误数值,这时就需要我们对数据进行清洗。
(1)去除重复值:
去重方法drop_duplicates();去重的概念:删除某个序列或是表格中某个序列中的重复数据;去重方法:DataFrame表格和Series序列对象内置方法drop_duplicates();语法结构:表格/序列对象.drop_duplicates(subset=None,keep='first',inplace=False)。下面是去重语句的作用,
参数 作用
subset 当去重对象是表格对象时使用,指定去重依据的字段
keep 指定去重后保留哪一行,first表示第一行,last表示最后一行
inplace 表示去重是否对在原始数据对象上进行
接下来试着用语句对Dataframe表格对象去重,如图:

(2)处理缺失值(异常值):
处理缺失值,首先要查看缺失值,查看缺失值有以下两种方法:表格对象.isnull()方法返回数据是否缺失的布尔值矩阵;表格对象.isnull().sum()返回各列的缺失值数量。

处理缺失值(异常值)可以用删除法,删除法:删除某个缺失数据(异常值)所在的行的所有数据;语法结构:表格对象.dropna(axis=0,how='any',subset=None,inplace=False),下面是删除法语句的作用,
参数 作用
axis 指定删除行或者列,默认为0,表示删除行
how 对表格对象多个字段的缺失值进行删除时使用
‘any'表示任何一个字段有缺失就删除
‘all'表示所有字段都缺失才删除
subset 指定要删除的缺失值来自哪一(几)列
inplace 表示是否对原数据生效,默认为False
除此之外,处理缺失值(异常值)还可以用替换法,替换法:使用某个数据去替换缺失值的处理方法,又叫填充法。语法结构:序列对象.fillna(values=需要替换的值,inplace=False)。
替换法又可以细分为:平均值法、众数法、特殊值法。
平均值法:一般对数值型序列使用。
众数法:一般对类别型序列使用。
特殊值法:一般在能够判断缺失数据和其他数据有不同特征时使用。
4.尾言:
以上是我在python数据分析方面的总结和经验,希望对python数据分析初学者和爱好者有所帮助,而我的总结可能还不够完善,也希望大家能够包容,自己在不足处去学习完善部分知识,从而使得自己更加灵活运用python去应对大数据时代的挑战。















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









