






1.什么是Hadoop?
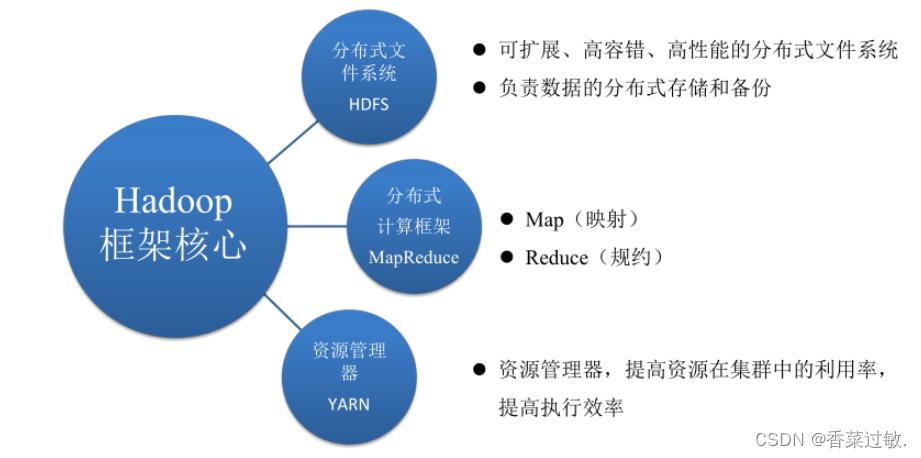
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
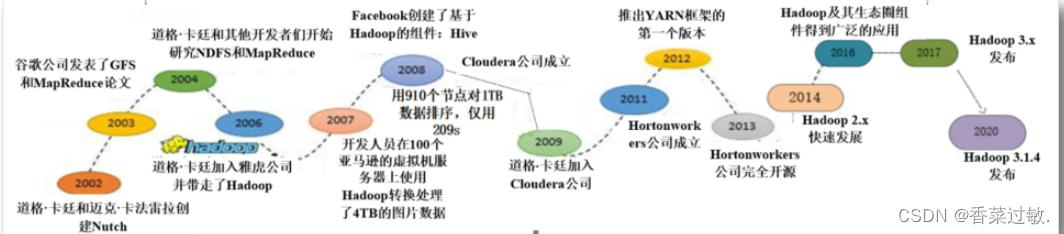
2.了解Hadoop发展历史
3.了解Hadoop特点
Hadoop 是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸 缩的方式进行处理的,它具有以下几个方面的特性。
a.高可靠性,采用冗余数据存储方式,即使一个副本发生故障,其他副本也可以保证正常对 外提供服务
b.高效性,作为并行分布式计算平台,Hadoop 采用分布式存储和分布式处理两大核心技术,能够高效地处理 PB 级
数据。
c.高可扩展性。Hadoop 的设计目标是可以高效稳定地运行在廉价的计算机集群上,可以扩 展到数以千计的计算机
节点上。
d.高容错性。采用冗余数据存储方式,自动保存数据的多个副本,并且能够自动将失败的任 务进行重新分配
e.成本低。Hadoop 采用廉价的计算机集群,成本比较低,普通用户也很容易用自己的 PC 搭建 Hadoop 运行环境,
运行在 Linux 平台上。Hadoop 是基于 Java 语言开发的,可以较好地运行在 Linux 平台上。
支持多种编程语言。Hadoop 上的应用程序也可以使用其他语言编写,如C。
4.Hadoop生态系统
简介:
Hadoop生态系统是一个开源的分布式计算平台,由Apache软件基金会开发并维护。其核心组件主要包括HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)、MapReduce以及YARN(Yet Another Resource Negotiator,另一种资源协调者)。这些组件共同构成了Hadoop分布式计算框架的核心,为用户提供底层细节透明的基础框架。
* HDFS是Hadoop的分布式文件系统,旨在在廉价硬件上存储大型文件。它创建数据块的多个副本,并将它们分布在群集中的计算节点上,这种分布方式既可靠又快速。HDFS最适合那些拥有非常大数据集的应用程序,并且具有高容错性和高吞吐量的特点,适合部署在低廉的硬件上。
* MapReduce是用于编写在Hadoop上运行的应用程序的计算模型和软件框架。这些MapReduce程序能够在大型计算节点群集上并行处理大量数据。
* YARN则是另一个关键组件,负责资源管理和作业调度,使得Hadoop能够更有效地处理各种大数据任务。
除了这些核心组件外,Hadoop生态系统还包括许多其他重要的组件,如HBase(分布式数据库)、Hive(数据仓库)、Pig(一种流数据语言和运行环境)、Mahout(机器学习库)、ZooKeeper(分布式协调服务)等。这些组件各自具有独特的功能和用途,共同构成了强大的Hadoop生态系统,使得大数据处理和分析变得更加高效和灵活。
总的来说,Hadoop生态系统为大数据处理和分析提供了强大的支持和便利,使得用户可以更加轻松地处理和分析海量数据,从而挖掘出更多有价值的信息。
5.Hadoop应用场景





等以上场景。
2.Hadoop集群的搭建及配置
1.安装及配置虚拟机
a.创建Linux虚拟机
b.设置固定IP
c.远程连接虚拟机
d.配置本地YUM源及安装常用软件
2.搭建Hadoop完全分布式集群
a.在Linux虚拟机安装java
b.修改配置文件
c.了解分布式文件系统——HDFS
d.修改配置文件

e.克隆虚拟机
f.配置SSH免密码登录
g.配置时间同步服务
h.启动关闭集群


i.监控集群
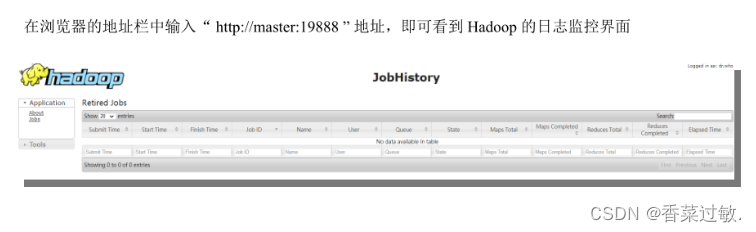
1.日志监控
3.Hadoop基础操作
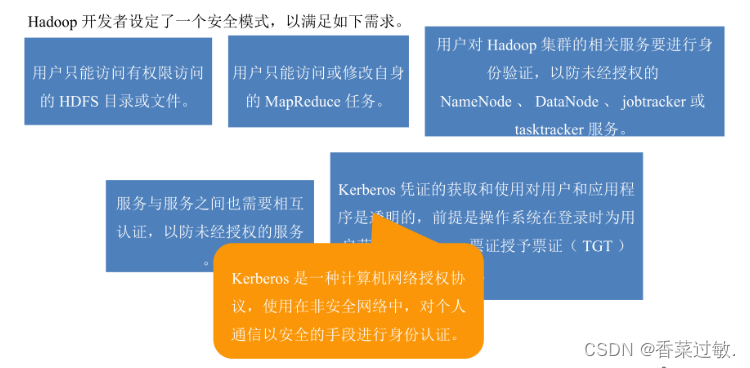
1.了解Hadoop安全模式

2.查看、解除与开启Hadoop安全模式
a.查看
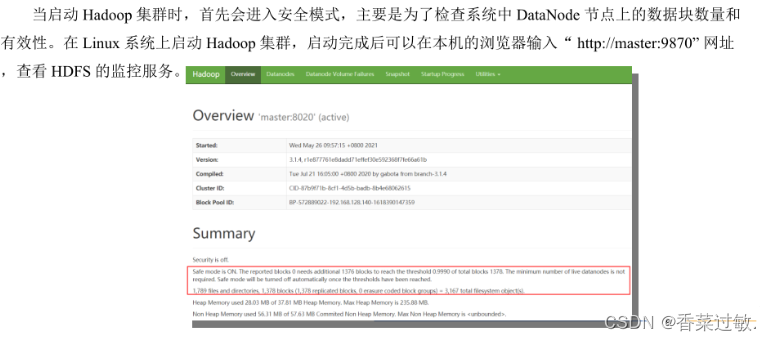
b.解除和开启安全模式

4.MapReduce编程入门
1.在Windows下安装Java
JDK是Java语言的软件开发工具包,主要用于移动设备、嵌入式设备上的Java应用程序。JDK是整个Java开发的核心,包含了Java的运行环境、Java工具和 Java基础的类库。本书后续章节的 Hadoop 开发是基于Java语言的,因此需要在 Windows下安装JDK,本书使用的JDK版本为JDK18,具体安装步骤如下。双击 JDK安装包 idk-8u281-windows-x64.exe,进入“Java SE 开发工具包”安装向导对话框,单击“下一步”按钮进入安装。等

2.下载与安装IDEA
在 IDEA 官网中下载 InteliJIDEA的安装包,安装包名称为ideaIC-2018.3.6.cxe
(Community版),mmunity 版即社区版,是免费开源的,读者也可以自行购买发行版。
双击下载好的IDEA 安装包,在弹出的安装向导界面中单击“Next”按钮,并设置IDEA 的安装目录
用户可根据本机系统的磁盘空间自定义IDEA的安装目录,并单击“Next”按钮。等。
3.新建MapReduce工程
安装好IntellJIDEA开发工具后,即可在IDEA中创建 MapReduce 工程。在进入IDEA后,单击“Create NewProfile”选项,弹出“New Project”对话框,在左侧列表栏中选择“Maven”选项,并单击界面右上方的“New……”按钮,在弹出的对话框中选择JDK的安装目录单击“OK”按钮后,再单击“Next”按钮。
4.配置MapReduce环境
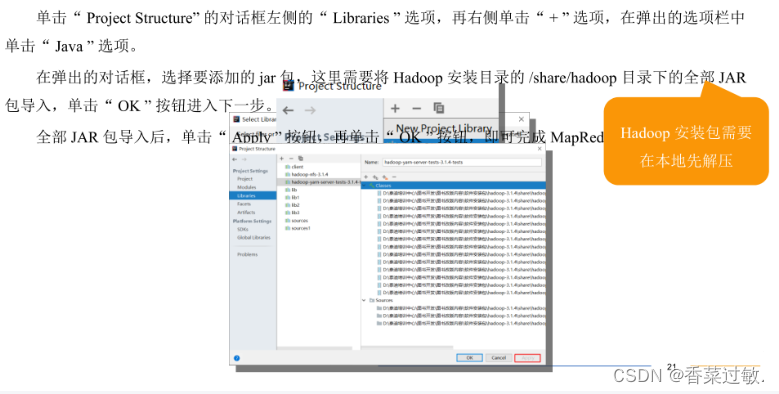
5.Hive数据仓库
1.什么是Hive
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
2.了解Hive与传统数据库的对比
a.索引。
Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。
Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。
由于数据的访问延迟较高,所以决定了Hive不适合在线数据查询。
数据库中,通常会针对一个或几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。执行引擎。在 Hive 中,大多数查询的执行是通过 Hadoop 提供的 MapReduce 实现的,而数据库通常有自己的执行引擎。
b.执行延迟
Hive 在查询数据时,由于没有索引,需要扫描整个表,因此延迟较高。
另外一个导致 Hive执行延迟高的因素是MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。
当数据规模较小时,传统数据库的执行延迟较低,但是当数据规模大到超过传统数据库的处理能力时,Hive的并行计算显然能体现出优势。可扩展性。
由于 Hive 是建立在 Hadoop之上的,因此 Hive 的可扩展性是和 Hadoop的可扩展性是一致的,而数据库由于语义的严格限制,扩展能力非常有限。处理数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据。
3.了解Hive系统架构
Hive是典型的客户端/服务器(Client/Server,C/S)模式,底层执行引擎使用的是Hadoop的MapReduce框架,因此 Hive 运行在 Hadoop基础上。Hive的系统架构组成如下图所示,主要包括5个部分:用户接口层、跨语言服务、元数据存储系统、底层的驱动引擎、底层存储。
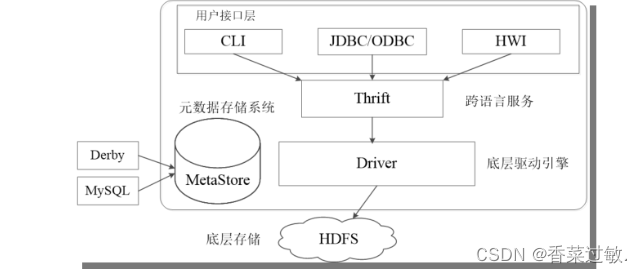
4.了解Hive数据模型
对于数据存储,Hive 没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由地组织 Hive中的表,只需要在创建表时设置数据的列分隔符和行分隔符,即可解析数据。
Hive 中所有的数据都存储在 HDFS中,存储结构主要包括数据库、表(内部表、外部表、带分区的表桶表)和视图。
5.了解Hive工作原理
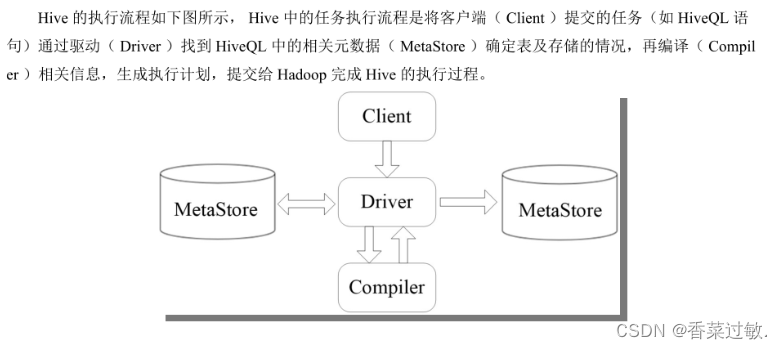
6.设置内嵌Derby模式

7.设置直连数据库模式

8.设置远程服务器模式

6.实现Hive表的创建与修改
1.数据库(DDL)基本语法
格式如下:
CREATE (DATABASE |SCHEMA) [IF NOTEXISTS] database_name
[COMNENTdatabase_comment
[LOCATION hdf_path]
[ WTTHDBPROPERTIES (property_name=property_value,..)];2.Hive创建基本语法格式
CREATE [EXTERNAL] TABLE IF NOTEXISTS]table_name
[(col_name data_tpe [COMMENTcol_comment], ..)
[COMMENTtable_comment]
[PARTITIONED BY(col_name data_ype [COMMENTcol_comment], ..)]
[CLUSTERED BY(col_name, col_name, ...)
[SORTED BY(col_name [ASC|DESC], .)」 INTO num_buckets BUCKETS]
[ROW FORMAT row_.format]
[STORED AS fle_.formatj
[LOCATION hdfs_path3.在编写ROWFORMAT选项参数时,可以如下
row_BYchar
SERDE serde_namformat :
:DELIMITED
[FIELDS TERMINATED BYchar
[COLLECTION ITEMS TERMINATED BYchar
[MAP KEYS TERMINATED BY char
ILINES TERMINATED e
IWITHSERDEPROPERTIES
(property_name=prperty_value,
property_name=property_value,...)]4.在编写STORED AS选项参数,如下
File format:
:SEOUENCEFILE
TEXTFILE
RCFILE
IORC
PARQUET
AVRO
JSONFILE
INPUTFORMATinput_namr_classname QUTPUFORMAT
Output_format_classname5.修改表格语法格式,通过ALTER TABLE 语法可以添加或删除表的分区
ALTER TABLE table name ADD [IF NOT EXISTS] PARTITION partition spec LOCATON "ocation"[, PARTITI
ON partition spec [LOCATION "ocation'",...];
partition spec.
(partition column = partition col value, partition column = partition col value, ...)
ALTER TABLE table name DROP [IF EXISTS] PARTITION partition spec, partition spec, ..
[IGNORE PROTECTIONJ [PURGE]:小结
Hadoop是一个开源的分布式系统基础架构,专为存储和处理海量数据而设计。它主要解决两个核心问题:海量数据的存储和海量数据的计算。Hadoop的核心组件包括HDFS(Hadoop Distributed File System)、MapReduce和YARN。以下是详细介绍:
- HDFS。这是一个分布式文件系统,旨在存储海量数据。它提供了高可靠性和高扩展性,数据以块的形式存储在多个节点上以保证容错性。
- MapReduce。这是一个分布式计算框架,它简化了分布式编程模型。MapReduce将任务分为两个阶段:Map(映射)和Reduce(归约),大大简化了大数据处理的过程。
- YARN。全称Yet Another Resource Negotiator,是一个集群资源管理系统,负责资源的调度和管理。
- Hadoop的其他常用组件包括HBase、Hive、Hadoop Streaming和Zookeeper,这些工具和数据库进一步扩展了Hadoop的功能,支持更复杂的数据处理和分析需求。例如,Hive提供了一个数据仓库工具,可以将数据摘要和查询任务运行在Hadoop上;Hadoop Streaming允许使用各种语言编写MapReduce作业;HBase是一个分布式、可扩展的列式数据库,适用于存储海量数据;Zookeeper是一个分布式协调服务,用于管理分布式系统中的元数据和配置。
Hadoop的不同版本(如1.x、2.x、3.x)在架构和功能上有所不同。特别是在Hadoop 2.x版本中,YARN的引入使得资源调度和计算任务的分离,提高了系统的灵活性和效率。总的来说,Hadoop提供了一个可靠、高效、可扩展的基础架构,用于存储和处理大数据,它的模块化设计允许用户根据需要选择和配置组件,从而构建高效的大数据处理系统。

















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









