







一、字典
1、基本性质:
无序:与列表不同,字典中的元素没有固定顺序。每次迭代字典时,元素的顺序可能不同。因为字典是基于哈希表实现的,哈希表通过将键经过哈希函数转化为哈希值,从而确定值的存储位置。这使得字典在查找元素时非常高效,但也导致其存储和访问元素的方式并不依赖于插入顺序。
可变:字典在创建后可以修改,比如添加新的键值对、修改现有键对应的值或者删除键值对。
键值对表示:元素以 “键 (key): 值 (value)” 对的形式存在,使用冒号分隔键和值,所有键值对包含在大括号{}中,元素间用逗号分隔。例如{'name': 'Alice', 'age': 30}。
键唯一:在同一个字典中,键必须是唯一的。如果尝试使用相同的键多次插入键值对,后面的值会覆盖前面的值。
键不可变:为保证键的唯一性和哈希表的正常工作,键必须是不可变类型。常见的不可变类型如字符串、数字(整数、浮点数)、元组等都可以作为键。而列表、字典等可变类型不能作为键,因为可变对象在改变时其哈希值也会改变,会破坏字典基于哈希的查找逻辑。
值可重复:值可以重复,不同的键可以对应相同的值。
值任意性:值可以是任意数据类型,包括整数、字符串、列表、字典,甚至是函数、类等。
2、字典的创建
使用花括号 {} 直接创建:在花括号内直接定义键值对来创建字典,键和值之间用冒号 : 分隔,多个键值对之间用逗号 , 分隔。
# 创建一个字典
person = {'name': 'Alice', 'age': 30, 'city': 'New York'}
print(person)
# 创建空字典,逐步添加键值对
empty_dict = {}
empty_dict['key1'] = 'value1'
empty_dict['key2'] = 42
print(empty_dict)
# 输出:
{'name': 'Alice', 'age': 30, 'city': 'New York'}
{'key1': 'value1', 'key2': 42}使用 dict() 函数创建:dict() 函数可以通过多种方式来创建字典。
# 使用关键字参数创建字典
new_dict = dict(name='Bob', age=25, job='Engineer')
print(new_dict)
# 通过元组列表(可迭代对象)创建字典
items = [('fruit', 'apple'), ('quantity', 5), ('price', 2.5)]
product_dict = dict(items)
print(product_dict)
#输出:
{'name': 'Bob', 'age': 25, 'job': 'Engineer'}
{'fruit': 'apple', 'quantity': 5, 'price': 2.5}可迭代对象:
就是可以一个一个地返回其成员的对象。也就是说,可以使用像 for 循环这样的结构,按顺序获取它里面的元素。可迭代对象可以是列表、元组、字符串、字典、集合。
通过可迭代对象创建字典时,要求可迭代对象中每个元素的长度为 2,第一个元素作为键,第二个元素作为值。
在这个例子中,items 是一个包含三个元组的列表,每个元组包含两个元素,通过 dict() 函数将其转换为字典。
3、字典元素的访问
字典是无序的,因此不支持索引、切片等操作。主要通过字典对象[键]获取对应的值。如果访问一个不存在的“键”,此时将会抛出 KeyError 异常,如果对一个不存在的“键”赋值,将会在字典中添加一个“键值对”。
1. 通过键访问值
这是最常见的方法。如果知道字典中的键,直接使用方括号 [] 加上键,就可以获取对应的值。
my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'}
print(my_dict['name'])
print(my_dict['age'])
# 输出:
Alice
30如果使用不存在的键来访问值,会引发 KeyError 异常。例如:
my_dict = {'name': 'Alice'}
# print(my_dict['gender'])
# 输出: KeyError: 'gender'
2. 使用 get() 方法
get() 方法也可以通过键获取对应的值。与直接使用方括号不同的是,当键不存在时,get() 方法不会引发异常,而是返回 None 或者你指定的默认值。
语法为 dict.get(key, default=None),其中 default 是可选参数,即键不存在时返回的值。
my_dict = {'name': 'Alice'}
print(my_dict.get('name'))
print(my_dict.get('gender'))
print(my_dict.get('gender', 'Unknown'))
# 输出:
Alice
None
Unknown3. 访问所有键值对
可以使用 items() 方法获取字典中所有的键值对。该方法返回一个包含所有键值对的可迭代对象,每个键值对以元组形式呈现。通常结合 for 循环来遍历所有键值对。
my_dict = {'name': 'Alice', 'age': 30}
print(my_dict.items())
for key, value in my_dict.items():
print(f"Key: {key}, Value: {value}")
# 输出:
dict_items([('name', 'Alice'), ('age', 30)])
Key: name, Value: Alice
Key: age, Value: 30
4. 访问所有键
使用 keys() 方法可以获取字典中所有的键。它返回一个包含所有键的可迭代对象。例如:
my_dict = {'name': 'Alice', 'age': 30}
keys = my_dict.keys()
print(keys)
# 输出:dict_keys(['name', 'age'])
print(list(keys))
# 输出:['name', 'age']
这里将 keys 转换为列表是为了更直观地展示所有键,在实际应用中,很多时候可以直接对这个可迭代对象进行遍历等操作,无需转换为列表。
5. 访问所有值
通过 values() 方法可以获取字典中所有的值。它返回一个包含所有值的可迭代对象。
my_dict = {'name': 'Alice', 'age': 30}
values = my_dict.values()
print(list(values))
# 输出:['Alice', 30]4、字典对象常用方法
1、setdefault(键,默认值)
首先尝试获取指定键的值。若键存在,返回该键对应的值,且不改变字典;若键不存在,将该键添加到字典中,值设为默认值,并返回这个默认值。
my_dict = {'name': 'Tom', 'age': 25}
print(my_dict.setdefault('name', '默认名'))
print(my_dict.setdefault('city', '未知城市'))
print(my_dict)
# 输出:
Tom
未知城市
{'name': 'Tom', 'age': 25, 'city': '未知城市'}2、update(字典)
把传入字典的键值对添加到当前字典。若当前字典已有相同键,就用新字典中的值替换旧值。
dict1 = {'name': 'Tom', 'age': 25}
dict2 = {'age': 26, 'city': 'Beijing'}
dict1.update(dict2)
print(dict1)
# 输出:
{'name': 'Tom', 'age': 26, 'city': 'Beijing'}3、fromkeys(序列,默认值)
它以给定序列中的元素作为键,创建一个新字典,所有键对应的值都是默认值。若不指定默认值,所有键的值都是 None。
keys = ['name', 'age', 'city']
new_dict = dict.fromkeys(keys)
print(new_dict)
new_dict = dict.fromkeys(keys, '未设置')
print(new_dict)
# 输出:
{'name': None, 'age': None, 'city': None}
{'name': '未设置', 'age': '未设置', 'city': '未设置'}4、pop(键)
从字典中删除指定键,并返回该键对应的值。如果指定的键不存在,会报错,除非你设置了第二个参数,此时若键不存在就返回这个参数值。
my_dict = {'name': 'Tom', 'age': 25}
age = my_dict.pop('age')
print(age)
print(my_dict)
height = my_dict.pop('height', '无身高信息')
print(height)
# 输出:
25
{'name': 'Tom'}
无身高信息5、copy()
创建并返回当前字典的一个浅拷贝。浅拷贝意味着新字典和原字典中的嵌套对象(如列表、字典等)是共享的,修改嵌套对象会同时影响两个字典;而对于不可变对象(如字符串、数字),修改不会相互影响。
my_dict = {'name': 'Tom', 'hobbies': ['reading', 'running']}
new_dict = my_dict.copy()
new_dict['name'] = 'Jerry'
new_dict['hobbies'].append('swimming')
print(my_dict)
print(new_dict)
# 输出:
{'name': 'Tom', 'hobbies': ['reading', 'running', 'swimming']}
{'name': 'Jerry', 'hobbies': ['reading', 'running', 'swimming']}5、字典推导式
语法形式:{键表达式:值表达式 for 变量 in 可迭代对象 if 条件}
整个语法通过对可迭代对象中的元素进行迭代,根据条件筛选元素,再由键表达式和值表达式为每个符合条件的元素生成对应的键值对,最终构建出一个新的字典。
a_list = "aEBCdF"
b_list = [2, 5, 6, 7, 10]
a_dict = {key: value for key, value in zip(a_list, b_list)}
b_dict = {key.lower(): value for key, value in zip(a_list, b_list)}
c_dict = {key: value for key, value in zip(a_list, b_list) if value % 2 == 0}
d_dict = {key: 4 for key in "DEF"}
# 含义:
a_dict 的值为:{'a': 2, 'E': 5, 'B': 6, 'C': 7, 'd': 10}
b_dict 的值为:{'a': 2, 'e': 5, 'b': 6, 'c': 7, 'd': 10}
c_dict 的值为:{'a': 2, 'B': 6, 'd': 10}
d_dict 的值为:{'D': 4, 'E': 4, 'F': 4}zip()
是一个内置函数,它的主要作用是将多个可迭代对象(如列表、元组、字符串等)中的元素按顺序配对,返回一个由这些配对组成的可迭代对象。当参与 zip() 的可迭代对象长度不同时,zip() 会在最短的可迭代对象耗尽时停止。
list3 = [1, 2, 3]
list4 = ['a', 'b', 'c', 'd']
result2 = zip(list3, list4)
print(list(result2))
# 输出:[(1, 'a'), (2, 'b'), (3, 'c')]6、字典的排序
对字典进行排序,可使用系统中提供的 sorted() 函数,但需要指定是按照“键”进行排序还是按照“值”进行排序。通常通过 lambda 表达式来指定排序的规则。
# 按键排序:item[0] 表示取元组的第一个元素,也就是键
my_dict = {'banana': 3, 'apple': 4, 'cherry': 1}
sorted_dict_by_key = dict(sorted(my_dict.items(), key = lambda item: item[0]))
print(sorted_dict_by_key)
# 输出:{'apple': 4, 'banana': 3, 'cherry': 1}
# 按值降序排序:item[1] 表示取键值对元组中的第二个元素,即值
sorted_dict_by_value_desc = dict(sorted(my_dict.items(), key = lambda item: item[1], reverse = True))
print(sorted_dict_by_value)
# 输出:{'apple': 4, 'banana': 3, 'cherry': 1}二、标签编码
适用场景:如果类别之间存在自然的顺序关系,并且模型能够理解和利用这种顺序信息,标签编码是合适的选择。例如,在表示教育程度时,“小学”“中学”“大学” 等类别存在明显的顺序,标签编码可以让模型捕捉到这种顺序性。
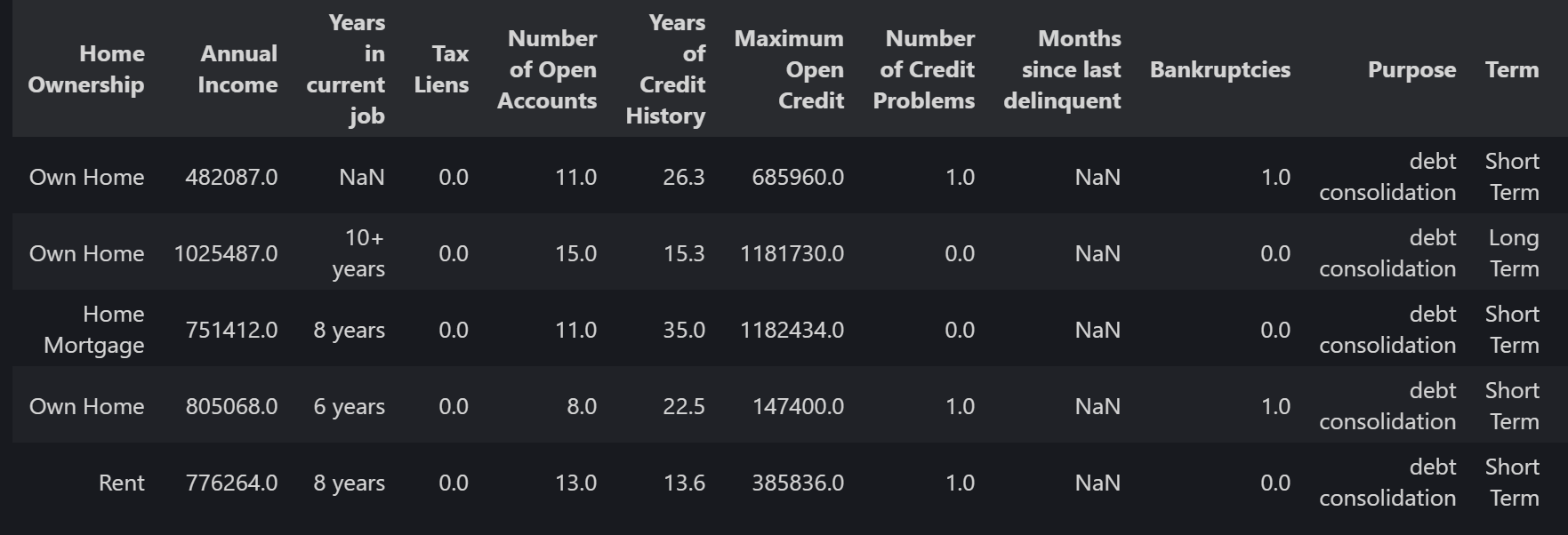
数据原始情况:
# 导库与读数据
import pandas as pd
data = pd.read_csv('data.csv')
data.head()
# 对列中类别计数
data["Home Ownership"].value_counts()
# 输出:
Home Mortgage 3637
Rent 3204
Own Home 647
Have Mortgage 12
Name: Home Ownership, dtype: int64
在 “Home Ownership”(房屋所有权)这个变量中,如果按照贷款严重程度(抗风险能力),依次是:自有住房 < 租房 < 有其他贷款 < 住房抵押贷款,这种情况下类别之间存在明确的顺序关系,我们可以为每个类别分配一个递增的整数编码。比如,“自有住房” 编码为 0,“租房” 编码为 1,“有其他贷款” 编码为 2,“住房抵押贷款” 编码为 3 。
# 定义映射字典
mapping = {
"Rent": 0,
"Own Home": 1,
"Have Mortgage ": 2,
"Home Mortgage": 3
}
data["Home Ownership"].head()
# 输出:
0 Own Home
1 Own Home
2 Home Mortgage
3 Own Home
4 Rent
Name: Home Ownership, dtype: object
# 使用map()方法根据 mapping 字典,对 data 数据框中 "Home Ownership" 列的每个值进行转换。
data["Home Ownership"] = data["Home Ownership"].map(mapping)
data["Home Ownership"].head()
# 输出:
0 1.0
1 1.0
2 3.0
3 1.0
4 0.0
Name: Home Ownership, dtype: float64字符串映射成整数:
和标签编码都旨在把非数值的类别数据(如字符串)转换为数值形式。这是因为许多机器学习算法和数据分析工具更擅长处理数值数据,这样的转换能让这些工具更好地对数据进行处理和建模。
!!!注意这里不是标签编码。当手动将字符串映射成整数时,常使用类似 map 的操作。比如前面例子中,通过自定义的映射字典,利用 map 方法把房屋所有权的字符串类别映射为整数。
# 对列值类别计数
data["Term"].value_counts()
# 输出:
Term
Short Term 5556
Long Term 1944
Name: count, dtype: int64
# 定义映射字典
mapping = {
"Short Term": 1,
"Long Term": 0
}
# 进行映射
data["Term"] = data["Term"].map(mapping)
data["Term"].head()
# 输出:
0 1
1 0
2 1
3 1
4 1
Name: Term, dtype: int64二分类问题通常不需要独热编码,三分类及以上通常需要独热编码
在二分类场景下,像性别(男 / 女)这样的特征,不必进行独热编码。因为用一个数值变量就足以表示这两种状态。例如,用 1 表示男性,0 表示女性,模型可以很好地理解这种二元表示。
从自由度角度来看,二分类只有一个自由度,即确定了一个类别,另一个类别也就随之确定。将其编码为一个特征,能准确反映类别信息,同时避免引入冗余。若对二分类特征进行独热编码,比如将性别编码为 “性别男” 和 “性别女” 两个特征,就会出现特征高度相关的情况。因为当 “性别男” 为 1 时,“性别女” 必然为 0,反之亦然。这两个特征携带的信息是等价的,只是以相反的方式呈现,对于模型训练并没有提供额外价值,反而增加了数据维度和计算复杂度。
对于三分类及以上的问题,简单的数值编码(如标签编码)可能会让模型错误地认为类别之间存在顺序关系。例如,将 “苹果”“香蕉”“橙子” 编码为 0、1、2,模型可能会认为 “苹果” 和 “香蕉” 的关系比 “苹果” 和 “橙子” 更紧密,这显然不符合实际情况。独热编码则可以避免这个问题,它为每个类别创建一个独立的特征维度,每个类别在其对应的维度上为 1,其他维度为 0。这样,类别之间是相互独立的,不存在顺序关系,模型能够准确地学习到每个类别各自的特征,提升分类的准确性。
用一个映射函数实现两次编码
import pandas as pd
# 重新读取数据
data = pd.read_csv("data.csv")
# 嵌套映射字典
mapping = {
"Term": {
"Short Term": 1,
"Long Term": 0
},
"Home Ownership": {
"Rent": 0,
"Own Home": 1,
"Have Mortgage ": 2,
"Home Mortgage": 3
}
}
# 对 Home Ownership 列进行映射
data["Home Ownership"] = data["Home Ownership"].map(mapping["Home Ownership"])
# 对 Term 列进行映射
data["Term"] = data["Term"].map(mapping["Term"])
data.head()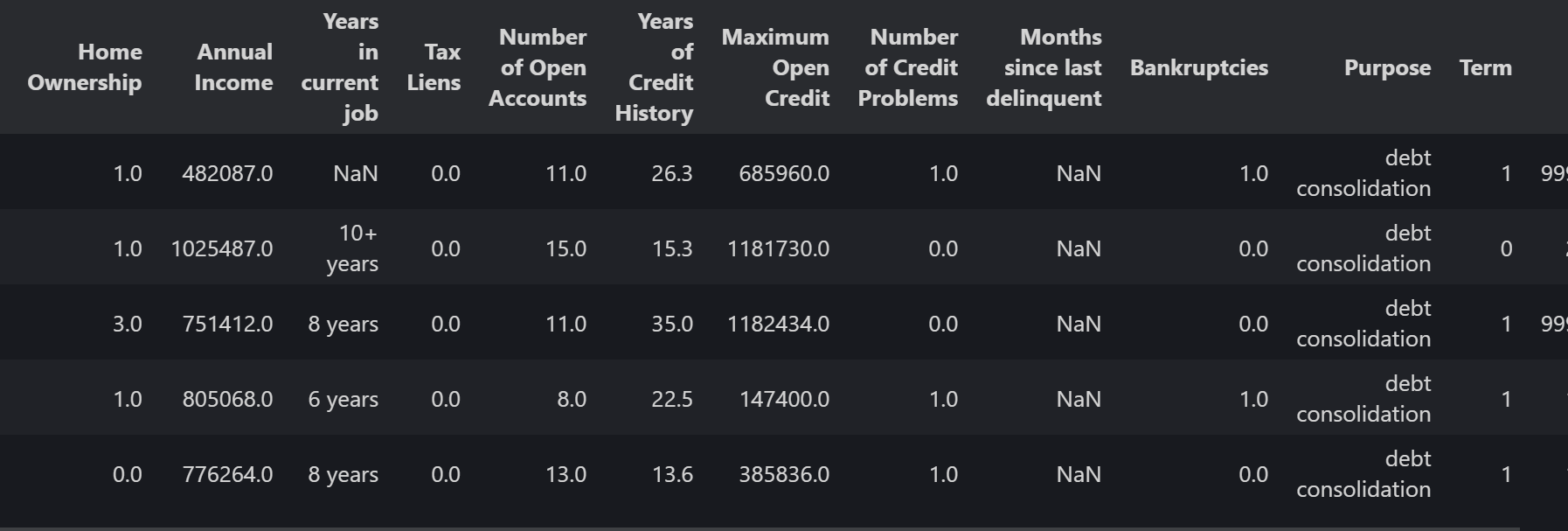
三、连续特征处理
归一化
归一化通常指的是将数据映射到一个固定的区间,常见的是 [0, 1] 区间。适用于需要将数据限制在一定范围的场景。
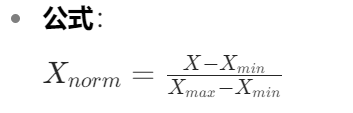
手写函数归一化:
# 对Annual Income列做归一化
def manual_normalize(data):
min_val = data.min()
max_val = data.max()
normalized_data = (data - min_val) / (max_val - min_val)
return normalized_data
data['Annual Income'] = manual_normalize(data['Annual Income'])
data['Annual Income'].head()
# 输出:
0 0.031798
1 0.086221
2 0.058771
3 0.064145
4 0.061260
Name: Annual Income, dtype: float64!!!为什么没有使用循环?
在 pandas 库中,Series 和 DataFrame 对象都设计为支持向量化操作。向量化操作允许对整个数据结构(如一列数据)同时进行数学运算,而不需要使用显式的循环逐个处理每个元素。例如,(data - min_val) / (max_val - min_val) 会将相减的结果除以 (max_val - min_val),对整个 Series 中的所有元素同时完成这些操作。相比传统的循环遍历每个元素进行计算,向量化操作在大数据集上能显著减少计算时间。
借助sklearn库进行归一化
from sklearn.preprocessing import StandardScaler, MinMaxScaler
data = pd.read_csv("data.csv")
# 实例化 MinMaxScaler类
min_max_scaler = MinMaxScaler()
data['Annual Income'] = min_max_scaler.fit_transform(data[['Annual Income']])
data['Annual Income'].head()
#输出:
0 0.031798
1 0.086221
2 0.058771
3 0.064145
4 0.061260
Name: Annual Income, dtype: float64-
fit部分:min_max_scaler会分析data[['Annual Income']]中的数据,计算出该列数据的最小值和最大值等统计信息,这些信息将用于后续的归一化转换。fit_transform方法期望接收一个二维数组形式的数据。因此这里传入的data[['Annual Income']]需要是二维的格式,即使只有一列数据,也要用双层方括号。 -
transform部分:根据fit阶段计算出的统计信息,对data[['Annual Income']]中的每个数据点进行归一化转换,将其缩放到默认的 [0, 1] 区间。然后将转换后的数据重新赋值给data中的'Annual Income'列,完成对该列数据的归一化。
标准化
将数据转换为均值为 0,标准差为 1 的分布,也称为 Z - score 标准化。它更关注数据的分布特性,使数据具有零均值和单位方差,适用于假设数据有特定分布或对数据分布较敏感的模型。
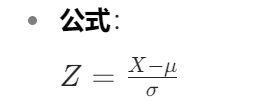
手写函数:
import pandas as pd
import numpy as np
def manual_standardize(data):
mean_val = np.mean(data)
std_val = np.std(data)
standardized_data = (data - mean_val) / std_val
return standardized_data
data = pd.read_csv("data.csv")
data['Annual Income'] = manual_standardize(data['Annual Income'])
data['Annual Income'].head()
# 输出:
0 -1.046183
1 -0.403310
2 -0.727556
3 -0.664078
4 -0.698155
Name: Annual Income, dtype: float64借助sklearn库
# 标准化处理
data = pd.read_csv("data.csv")
scaler = StandardScaler()
data['Annual Income'] = scaler.fit_transform(data[['Annual Income']])
data['Annual Income'].head()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









