






一. 项目背景:
根据历史房价数据和收集的特征建立回归模型,预测波士顿不同类型房屋的价格。这次比赛我们用两种线性回归方法来求解,分别是正规方程求解和梯度下降求解。
kaggle比赛地址:Boston housing dataset (kaggle.com)
每个特征的中文含义如下:
CRIM: 城镇人均犯罪率
ZN: 住宅用地所占比例
INDUS: 城镇中非商业用地所占比例
CHAS: 查尔斯河虚拟变量,用于回归分析
NOX: 环保指数
RM: 每栋住宅的房间数
AGE: 1940 年以前建成的自住单位的比例
DIS: 距离 5 个波士顿的就业中心的加权距离
RAD: 距离高速公路的便利指数
TAX: 每一万美元的不动产税率
PTRATIO: 城镇中的教师学生比例
B: 城镇中的黑人比例
LSTAT: 地区中有多少房东属于低收入人群
二. 思路分析:
- 1.获取数据
- 2.数据清洗
- 3.特征工程
- 4.模型训练
- 5.模型评估
三. 代码实现
3.1 正规方程求解
首先导入相应的模块:
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression # 线性回归
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.preprocessing import StandardScaler # 标准化
from sklearn.linear_model import SGDRegressor # 梯度下降
from sklearn.metrics import mean_squared_error # 均方误差获取数据并查看一下数据的基本情况:
boston = pd.read_csv(r"E:\AI课程笔记\机器学习\HousingData.csv")
print(boston.head(5))
print(boston.info())
print(boston.describe())输出结果如下:
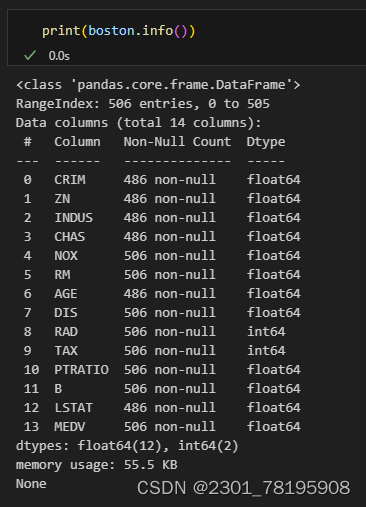
可以看到有些列有缺失值,我们用缺失值所在列的平均值去填充缺失值:
mean_values = boston.mean() #计算每列平均值
boston = boston.fillna(mean_values) # 将缺失值填充为对应列的平均值再查看一下:
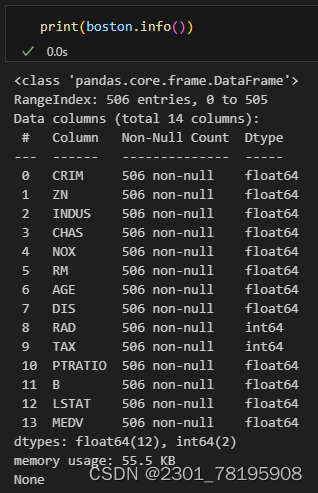
发现已经没有缺失值了。
接下来我们将数据集分割为特征值和目标值:
# 分割数据集
X = boston.drop(['MEDV'], axis=1)
y = boston['MEDV'] # 标签-房价
x_train, x_test, y_train, y_test = train_test_split(X, y, random_state=22, test_size=0.2)分割完成后我们再进行特征工程,将训练集和测试集的特征值和目标值的数据都进行标准化:
# 特征工程 -- 特征值和目标值都进行标准化
# 实例化两个转换器类
std_x = StandardScaler()
std_y = StandardScaler()
# 调用fit_transform
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
y_train = std_y.fit_transform(y_train.values.reshape(-1, 1)) # 一维数组转二维数组
y_test = std_y.transform(y_test.values.reshape(-1, 1)) # 一维数组转二维数组(注意:这里要用values.reshape()将一维数组转换成二维数组后再进行标准化)
接下来创建一个线性回归的估计器:
# 估计器
lr = LinearRegression()
lr.fit(x_train, y_train)
print(lr.coef_) # 各特征的权重系数输出结果如下所示:

接下来我们用构建好的模型来预测一下房价。我们需要被标准化的预测值做个逆转换:
# 模型预测
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
print("房子预测价格为:", y_lr_predict)输出结果为:
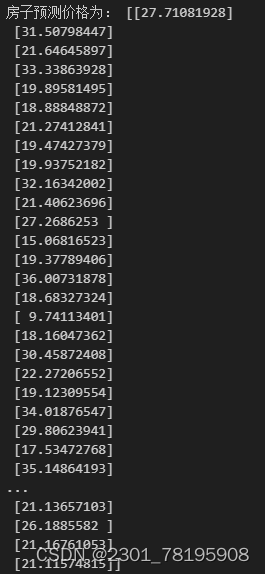
再计算一下准确率:
# 模型评估
score = lr.score(x_test, y_test)
print("模型评估:", score)结果为:

3.2 梯度下降求解
流程和方法和上面的一样,只是把估计器换成梯度下降的估计器,也就是SGDRegressor()。我们直接从估计器实例化那里开始做:
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print(sgd.coef_)模型训练好后,我们拿模型去做预测:
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test).reshape(-1, 1)) # 预测值
print("房子预测价格为:", y_sgd_predict)输出结果是:
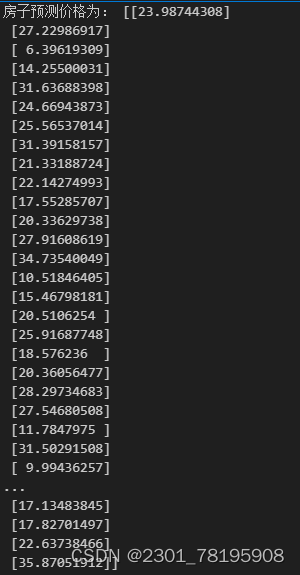
最后用准确率和均方误差评估一下模型:
# 模型评估
score = sgd.score(x_test, y_test)
print("模型评估:", score)
error = mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict) # 均方误差
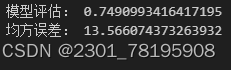
print("均方误差:", error)输出结果是:
3.3 岭回归
岭回归是一种用于线性回归问题的正则化技术。它通过引入L2正则化项来改进普通最小二乘线性回归,以解决线性回归中可能存在的过拟合问题。以下是使用岭回归分类器来预测波士顿房价的代码:
#解决过拟合 -- 岭回归 L2正则化 -- 通过调整alpha值来控制正则化的强度 -- alpha越大,正则化强度越大,模型越简单,越不容易过拟合
from sklearn.linear_model import Ridge
rd = Ridge(alpha=1.0) # 实例化岭回归类 -- alpha默认为1.0 -- 通过调整alpha值来控制正则化的强度
rd.fit(x_train, y_train) # 训练模型
print(rd.coef_) # 回归系数
y_rd_predict = std_y.inverse_transform(rd.predict(x_test)) # 预测值
print("房子预测价格为:", y_rd_predict)
score = rd.score(x_test, y_test) # 模型评估
print("模型评估:", score)
error = mean_squared_error(std_y.inverse_transform(y_test), y_rd_predict) # 均方误差
print("均方误差:", error)输出结果为:

最后我们对模型进行一个加载和保存:
#保存和加载模型
from sklearn.externals import joblib
joblib.dump(rd, "rd.pkl(文档位置)") # 保存岭回归模型
rd = joblib.load("rd.pkl(文档位置)") # 加载模型















 2139
2139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











