






 本文介绍了如何使用Python的sklearn库实现随机森林算法,包括数据预处理、特征工程、参数设置(如n_estimators和max_depth)、以及通过GridSearchCV进行模型调优。最终结果显示,300棵深度为25的决策树模型在测试集上的准确率为0.78。
本文介绍了如何使用Python的sklearn库实现随机森林算法,包括数据预处理、特征工程、参数设置(如n_estimators和max_depth)、以及通过GridSearchCV进行模型调优。最终结果显示,300棵深度为25的决策树模型在测试集上的准确率为0.78。
随机森林是一种强大的集成学习算法,它在决策树的基础上引入了样本抽样和特征抽样两种随机性,通过组合多个决策树来提高模型的性能和泛化能力。接下来我们来实现这种算法:
首先导入模块:
from sklearn.model_selection import train_test_split # 数据集划分
from sklearn.ensemble import RandomForestClassifier # 导入随机森林模型
from sklearn.model_selection import GridSearchCV # 导入网格搜索模型
from sklearn.feature_extraction import DictVectorizer #字典特征抽取再进行数据导入和清洗:
titan = pd.read_csv(r'E:\AI课程笔记\机器学习\titanic_train copy.csv')
x = titan[["Pclass","Age","Sex"]] # 特征值
y = titan["Survived"] # 目标值
x['Age'].fillna(x['Age'].mean(), inplace=True)进行特征工程:
vect_1 = DictVectorizer(sparse=False) # 实例化
x_train = vect_1.fit_transform(x_train.to_dict(orient="records")) # 对字典数据进行one-hot编码
x_test = vect_1.transform(x_test.to_dict(orient="records"))(注意:在这里不需要对y_train进行onehot编码,因为他的数据类型本身可以被计算机识别)
接下来进行模型训练前参数设置:
rf = RandomForestClassifier() # 实例化一个随机森林模型
param = {"n_estimators":[120,200,300,500,800,1200], "max_depth":[5,8,15,25,30]} # 设置超参数 n_estimators表示决策树的个数 max_depth表示决策树的深度
gc = GridSearchCV(rf, param_grid=param, cv=4) # 实例化网格搜索模型
接下来开始训练模型:
gc.fit(x_train, y_train) # 训练模型计算并输出准确率和最优参数:
print(gc.score(x_test, y_test)) # 准确率
print(gc.best_params_) # 最优参数最后得到的结果是:
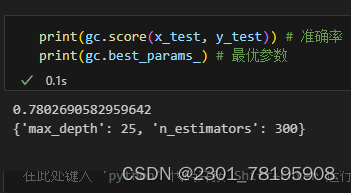
这个结果说明建立300棵决策树,每颗决策树的深度是25的时候,效果最好,准确率为0.78。这比用决策树构造的模型准确率提高了0.01。


















 1708
1708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











