







目标检测


语义分割


核心特性
-
全面的任务支持:直接支持多种检测相关的任务,包括但不限于目标检测(bounding box预测)、实例分割(像素级对象分割)、全景分割(结合实例分割与语义分割),以及半监督对象检测,适应于不同的应用场景需求。
-
模型丰富:它集成了大量的主流和最先进的检测模型,例如Faster R-CNN、Mask R-CNN、RetinaNet、YOLO系列、Cascaded R-CNN、HTC(Hybrid Task Cascade)、Sparse R-CNN等,以及用于实例分割和全景分割的专用模型,如Panoptic FPN。这些模型覆盖了从基础到前沿的研究成果,且持续更新。

-
模块化设计:采用了高度模块化的架构,使得模型的组件(如backbone、neck、head等)可以灵活替换,方便研究人员快速实验新的想法和模型变体。
-
数据集兼容性:项目支持多种常用的数据集,包括COCO、PASCAL VOC、Cityscapes等,并提供了方便的数据加载和预处理接口,简化了数据准备流程。
-
训练与调优工具:提供了丰富的训练脚本和配置文件,用户可以通过简单的修改配置即可启动训练和评估。同时,支持多GPU训练、分布式训练、混合精度训练等优化策略,以提高训练效率。
-
模型部署:还关注模型的落地应用,提供了模型导出到ONNX、TensorRT等格式的支持,以便于在生产环境中部署。
-
社区与文档:拥有活跃的开发者社区和完善的文档资源,包括详细的安装指南、模型教程、API文档以及丰富的示例代码,降低了新手入门门槛。
旋转物体检测:
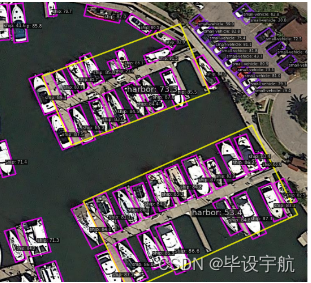
应用场景
应用场景广泛,涵盖了安全监控、自动驾驶、医疗影像分析、无人机巡检、增强现实等多个领域,是进行对象检测研究和应用开发的强大工具。
综上所述,凭借其强大的功能集、高度的灵活性和优秀的社区支持,成为了进行对象检测及相关计算机视觉任务研究和开发的首选平台之一。
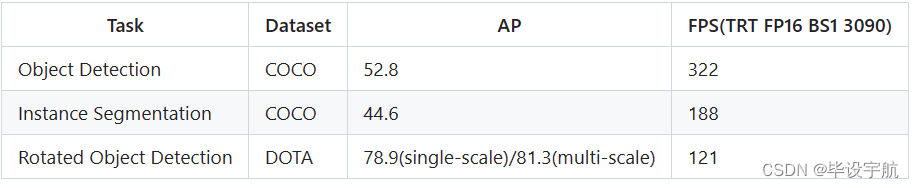

1. 准备数据集
假设你已经按照MMDetection的指导准备好了COCO数据集,并配置好了相应路径。
2. 配置文件准备
MMDetection通过修改配置文件来定义模型、训练参数等。你可以基于默认配置文件进行修改以适应你的需求。比如,创建或修改一个配置文件(如configs/faster_rcnn_r50_fpn_1x_coco.py),根据实际情况调整模型参数、训练参数等。
3. 开始训练
在命令行中,你可以使用如下命令开始训练:
# 进入MMDetection的根目录
cd path/to/mmdetection
# 开始训练
python tools/train.py configs/faster_rcnn_r50_fpn_1x_coco.py 这里的configs/faster_rcnn_r50_fpn_1x_coco.py是配置文件的路径,指定了使用的模型、训练数据集、训练周期等信息。
4. 测试与评估
训练完成后,你可以使用以下命令对模型进行测试和评估:
# 测试模型并生成结果
python tools/test.py configs/faster_rcnn_r50_fpn_1x_coco.py checkpoints/latest.pth --out results.pkl
# 使用官方COCO API评估结果
python tools/eval.py configs/faster_rcnn_r50_fpn_1x_coco.py results.pkl其中,checkpoints/latest.pth是训练过程中保存的模型权重文件,results.pkl是测试产生的结果文件。
请注意,以上代码仅为示例,实际使用时请根据自己的数据集路径、配置文件名等进行适当调整。
















 9178
9178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









