








Hadoop 分布式安装部署
Hadoop官网 Hadoop v3.3.0官方文档 Hadoop v3.3.0下载地址
1. 集群角色规划
| 主机 | 角色 |
|---|---|
| node01 | NN DN RM NM |
| node02 | SNN DN NM |
| node03 | DN NM |
2. 服务器基础环境准备
-
主机名规划(三台机器)
HostName node01 node02 node03 IPaddress 192.168.182.128/24 192.168.182.129/24 192.168.182.137/24 User/Pwd root / 218853 root / 218853 root / 218853 CONFIG 4核/4G+20GB 2核/2+20GB 2核/2+20GB [root@localhost ~]# hostnamectl set-hostname node01 [root@localhost ~]# hostnamectl set-hostname node02 [root@localhost ~]# hostnamectl set-hostname node03 -
host域名解析(三台机器)
[root@node01 ~]# echo "192.168.182.128 node01 " >> /etc/hosts [root@node01 ~]# echo "192.168.182.129 node02 " >> /etc/hosts [root@node01 ~]# echo "192.168.182.137 node03 " >> /etc/hosts [root@node01 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.182.128 node01 192.168.182.129 node02 192.168.182.137 node03[root@node01 ~]# scp /etc/hosts root@node02:/etc/hosts [root@node01 ~]# scp /etc/hosts root@node03:/etc/hosts -
关闭防火墙(三台机器)
[root@node01/02/03 ~]# systemctl stop firewalld.service # 关闭防火墙 [root@node01/02/03 ~]# systemctl disable firewalld.service # 禁止防火墙自启动 Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service. Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service. -
ssh免密登陆(从node01允许其余两台即可)
[root@node01 ~]# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Created directory '/root/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:wDO90eSaCduuDfucOib+ftZVU3vl3zctupEH6YeTryU root@node01 The key's randomart image is: +---[RSA 2048]----+ | . | | . . + o| | * o o oo| | B * .o.o| | . S o. .=| | . ..=..=| | . .. .E.+.o| | . o*o.. .O | | ..=**= oo. | +----[SHA256]-----+ [root@node01 ~]# ssh-copy-id node01 [root@node01 ~]# ssh-copy-id node02 [root@node01 ~]# ssh-copy-id node03# 测试(免密登录到node02或node03) [root@node01 ~]# ssh node02 Last login: Thu Aug 31 10:14:48 2023 from 192.168.182.1 [root@node02 ~]# exit 登出 Connection to node02 closed. -
集群时间同步(三台机器)
[root@node01 ~]# yum -y install ntpdate [root@node01 ~]# ntpdate pool.ntp.org 31 Aug 10:31:02 ntpdate[27407]: adjust time server 111.230.189.174 offset -0.000963 sec -
创建统一工作目录(三台机器)
[root@node01 ~]# mkdir -p /export/server # 软件安装路径 [root@node01 ~]# mkdir -p /export/data # 数据存储路径 [root@node01 ~]# mkdir -p /export/software # 安装包存放路径 [root@node01 export]# ll 总用量 0 drwxr-xr-x. 2 root root 6 8月 31 10:32 data drwxr-xr-x. 2 root root 6 8月 31 10:32 server drwxr-xr-x. 2 root root 6 8月 31 10:32 software -
上传JDK1.8安装包并解压(三台机器)
# 解压 jdk-8u241-linux-x64.tar.gz [root@node01 ~]# cd /export/server [root@node01 server]# ll 总用量 189988 -rw-r--r--. 1 root root 194545143 8月 31 10:41 jdk-8u241-linux-x64.tar.gz [root@node01 server]# tar -zxvf jdk-8u241-linux-x64.tar.gz [root@node01 server]# ll ./jdk1.8.0_241/ 总用量 25988 drwxr-xr-x. 2 10143 10143 4096 12月 11 2019 bin -r--r--r--. 1 10143 10143 3244 12月 11 2019 COPYRIGHT drwxr-xr-x. 3 10143 10143 132 12月 11 2019 include -rw-r--r--. 1 10143 10143 5217333 12月 11 2019 javafx-src.zip drwxr-xr-x. 5 10143 10143 185 12月 11 2019 jre drwxr-xr-x. 5 10143 10143 245 12月 11 2019 lib -r--r--r--. 1 10143 10143 44 12月 11 2019 LICENSE drwxr-xr-x. 4 10143 10143 47 12月 11 2019 man -r--r--r--. 1 10143 10143 159 12月 11 2019 README.html -rw-r--r--. 1 10143 10143 424 12月 11 2019 release -rw-r--r--. 1 10143 10143 21078837 12月 11 2019 src.zip -rw-r--r--. 1 10143 10143 116400 12月 11 2019 THIRDPARTYLICENSEREADME-JAVAFX.txt -r--r--r--. 1 10143 10143 169788 12月 11 2019 THIRDPARTYLICENSEREADME.txt# 配置环境变量 [root@node01 ~]# vim /etc/profile export JAVA_HOME=/export/server/jdk1.8.0_241 export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar# 重载环境变量 [root@node01 ~]# source /etc/profile# 检验安装 [root@node01 ~]# java -version java version "1.8.0_241" Java(TM) SE Runtime Environment (build 1.8.0_241-b07) Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)# 拷贝环境变量到剩余的两台机器 [root@node01 ~]# scp /etc/profile root@node02:/etc/profile profile 100% 1963 2.6MB/s 00:00 [root@node01 ~]# scp /etc/profile root@node03:/etc/profile profile 100% 1963 2.6MB/s 00:00 # 拷贝软件到剩余的两台机器 [root@node01 ~]# scp -r /export/server/jdk1.8.0_241 root@node02:/export/server [root@node01 ~]# scp -r /export/server/jdk1.8.0_241 root@node03:/export/server # 重载剩余两台机器的环境变量 [root@node02 ~]# source /etc/profile [root@node03 ~]# source /etc/profile # 检验安装 [root@node02 ~]# java -version [root@node03 ~]# java -version
3. 编译Hadoop安装包
-
安装编译相关的依赖
[root@node01 ~]# yum install gcc gcc-c++ make autoconf automake libtool curl lzo-devel zlib-devel openssl openssl-devel ncurses-devel snappy snappy-devel bzip2 bzip2-devel lzo lzo-devel lzop libXtst zlib -y [root@node01 ~]# yum install -y doxygen cyrus-sasl* saslwrapper-devel* -
手动安装cmake
# 1.卸载原有低版本的cmake [root@node01 ~]# yum erase cmake # 2.上传并解压安装cmake-3.19.4 [root@node01 server]# ll -rw-r--r--. 1 root root 9266976 8月 31 11:22 cmake-3.19.4.tar.gz [root@node01 server]# tar -zxvf cmake-3.19.4.tar.gz # 3.编译安装cmake [root@node01 server]# cd /export/server/cmake-3.19.4 [root@node01 cmake-3.19.4]# ./configure [root@node01 cmake-3.19.4]# make && make install # 4.验证(如果没有正确显示版本 请断开SSH连接 重新登录) [root@node01 cmake-3.19.4]# cmake -version cmake version 3.19.4 -
手动安装snappy
# 1.卸载旧版的snappy [root@node01 ~]# rm -rf /usr/local/lib/libsnappy* [root@node01 ~]# rm -rf /lib64/libsnappy* # 2.上传软件包并解压 [root@node01 server]# ll -rw-r--r--. 1 root root 1509026 8月 31 13:04 snappy-1.1.3.tar.gz [root@node01 server]# tar -zxvf snappy-1.1.3.tar.gz # 3.编译安装snappy [root@node01 server]# cd ./snappy-1.1.3/ [root@node01 snappy-1.1.3]# ./configure [root@node01 snappy-1.1.3]# make && make install # 4.检验是否安装 [root@node01 snappy-1.1.3]# ls -lh /usr/local/lib |grep snappy -rw-r--r--. 1 root root 511K 8月 31 13:10 libsnappy.a -rwxr-xr-x. 1 root root 955 8月 31 13:10 libsnappy.la lrwxrwxrwx. 1 root root 18 8月 31 13:10 libsnappy.so -> libsnappy.so.1.3.0 lrwxrwxrwx. 1 root root 18 8月 31 13:10 libsnappy.so.1 -> libsnappy.so.1.3.0 -rwxr-xr-x. 1 root root 253K 8月 31 13:10 libsnappy.so.1.3.0 -
检验JDK是否安装
[root@node01 ~]# java -version java version "1.8.0_241" Java(TM) SE Runtime Environment (build 1.8.0_241-b07) Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode) -
安装配置maven
Apache Maven Project官网 Maven-3
# 1.上传并解压 [root@node01 server]# ll -rw-r--r--. 1 root root 8842660 8月 31 13:22 apache-maven-3.5.4-bin.tar.gz [root@node01 server]# tar -zxvf apache-maven-3.5.4-bin.tar.gz # 2.配置并重载环境变量 [root@node01 ~]# vi /etc/profile export MAVEN_HOME=/export/server/apache-maven-3.5.4 export MAVEN_OPTS="-Xms4096m -Xmx4096m" export PATH=:$MAVEN_HOME/bin:$PATH [root@node01 server]# source /etc/profile # 检测是否安装成功 [root@node01 ~]# mvn -version Apache Maven 3.5.4 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-18T02:33:14+08:00) Maven home: /export/server/apache-maven-3.5.4 Java version: 1.8.0_241, vendor: Oracle Corporation, runtime: /export/server/jdk1.8.0_241/jre Default locale: zh_CN, platform encoding: UTF-8 OS name: "linux", version: "3.10.0-1160.el7.x86_64", arch: "amd64", family: "unix" # 添加maven 阿里云仓库地址 加快国内编译速度 [root@node01 ~]# vi /export/server/apache-maven-3.5.4/conf/settings.xml <mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> <mirrorOf>central</mirrorOf> </mirror> </mirrors> -
安装ProtocolBuffer 3.7.1
ProtocolBuffer官网 GitHub ProtocolBuffer V3.7.1
# 卸载旧版 [root@node01 ~]# yum erase protobuf # 上传并解压 [root@node01 server]# ll -rw-r--r--. 1 root root 7018070 8月 31 14:18 protobuf-all-3.7.1.tar.gz [root@node01 server]# tar -zxvf protobuf-all-3.7.1.tar.gz # 编译安装 [root@node01 server]# cd ./protobuf-3.7.1/ [root@node01 protobuf-3.7.1]# ./autogen.sh [root@node01 protobuf-3.7.1]# ./configure [root@node01 protobuf-3.7.1]# make && make install # 检验 [root@node01 protobuf-3.7.1]# protoc --version libprotoc 3.7.1 -
配置安装node
# 1.上传并解压 [root@node01 server]# tar -zxvf node-v8.11.3-linux-x64.tar.gz # 2.配置环境变量 [root@node01 node-v8.11.3-linux-x64]# vi /etc/profile export PATH=/export/server/node-v8.11.3-linux-x64/bin:$PATH [root@node01 node-v8.11.3-linux-x64]# source /etc/profile # 4.检验 [root@node01 node-v8.11.3-linux-x64]# node -v v8.11.3 -
编译Hadoop
[root@node01 server]# tar -xzvf hadoop-3.3.0-src.tar.gz [root@node01 server]# vi /etc/profile export HADOOP_HOME=/export/server/hadoop-3.3.0-src export PATH=$HADOOP_HOME/bin:$PATH [root@node01 server]# source /etc/profile [root@node01 server]# cd hadoop-3.3.0-src [root@node01 hadoop-3.3.0-src]# mvn clean install -Pnative -Pdist -DskipTests# 1.上传并解压源码包 [root@node01 ~]# ll -rw-r--r--. 1 root root 33629319 8月 31 14:42 hadoop-3.3.0-src.tar.gz [root@node01 ~]# tar -zxvf hadoop-3.3.0-src.tar.gz
2.编译安装
[root@node01 ~]# cd ./hadoop-3.3.0-src/
[root@node01 hadoop-3.3.0-src]# mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
——————————————————————————————————————————————
参数说明
Pdist,native :把重新编译生成的hadoop动态库;
DskipTests :跳过测试
Dtar :最后把文件以tar打包
Dbundle.snappy :添加snappy压缩支持【默认官网下载的是不支持的】
Dsnappy.lib=/usr/local/lib :指snappy在编译机器上安装后的库路径
编译之后的安装包路径:/root/hadoop-3.3.0-src/hadoop-dist/target
4. 上传Hadoop安装包并解压(node01)
— 以下使用已编译好的Hadoop安装包进行实验
[root@node01 ~]# cd /export/server
[root@node01 server]# tar zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
Hadoop 安装包目录结构
目录 说明 bin Hadoop 最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用Hadoop。 etc Hadoop配置文件所在的目录 include 对外提供编程库头文件(具体动态库和静态库在lib目录中),这些头文件均是C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序。 lib 包含了Hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。 libexec Hadoop管理脚本所在的目录,主要包含HDSF和YARN中各类服务的启动/关闭脚本。 share Hadoop各个模块编译后的jar包所在的目录 配置文件概述
Hadoop官网:https://hadoop.apache.org/docs/r3.3.0/
所有的配置文件目录:/export/server/hadoop-3.3.0/etc/hadoop
- 第一类(1个):hadoop-env.sh
- 第二类(4个):xxx-site.xml core-site hdfs-site.xml mapred-site.xml yarn-site.xml
- 第三类(1个):workers
-
修改配置文件(hadoop-3.3.0/etc/hadoop)
[root@node01 server]# cd ./hadoop-3.3.0/etc/hadoop/ [root@node01 hadoop]# ls capacity-scheduler.xml hadoop-user-functions.sh.example kms-log4j.properties ssl-client.xml.example configuration.xsl hdfs-rbf-site.xml kms-site.xml ssl-server.xml.example container-executor.cfg hdfs-site.xml log4j.properties user_ec_policies.xml.template core-site.xml httpfs-env.sh mapred-env.cmd workers hadoop-env.cmd httpfs-log4j.properties mapred-env.sh yarn-env.cmd hadoop-env.sh httpfs-site.xml mapred-queues.xml.template yarn-env.sh hadoop-metrics2.properties kms-acls.xml mapred-site.xml yarnservice-log4j.properties hadoop-policy.xml kms-env.sh shellprofile.d yarn-site.xml-
hadoop-env.sh
# 指定jdk位置 export JAVA_HOME=/export/server/jdk1.8.0_241 # 指定各个进程运行的用户名 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root -
core-site.xml
写入<configuration>标签中
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 --> <property> <name>fs.defaultFS</name> <value>hdfs://node01:8020</value> </property> <!-- 设置Hadoop本地保存数据路径 --> <property> <name>hadoop.tmp.dir</name> <value>/export/data/hadoop-3.3.0</value> </property> <!-- 设置HDFS web UI用户身份 --> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <!-- 整合hive 用户代理设置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 文件系统垃圾桶保存时间 --> <property> <name>fs.trash.interval</name> <value>1440</value> </property> -
hdfs-site.xml
写入<configuration>标签中
<!-- 设置SNN进程运行机器位置信息 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>node02:9868</value> </property> -
mapred-site.xml
写入<configuration>标签中
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- MR程序历史服务地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node01:10020</value> </property> <!-- MR程序历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node01:19888</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value> </property> -
yarn-site.xml
写入<configuration>标签中
<!-- 设置YARN集群主角色运行机器位置 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 是否将对容器实施物理内存限制 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <!-- 是否将对容器实施虚拟内存限制。 --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 开启日志聚集 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置yarn历史服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node01:19888/jobhistory/logs</value> </property> <!-- 历史日志保存的时间 7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> -
workers(工作集群机器的地址信息)
node01 node02 node03
-
-
分发同步Hadoop安装包
[root@node01 hadoop]# cd /export/server [root@node01 server]# scp -r hadoop-3.3.0 root@node02:$PWD [root@node01 server]# scp -r hadoop-3.3.0 root@node03:$PWD -
将Hadoop添加到环境变量(三台机器)
[root@node01 ~]# vi /etc/profilevim /etc/profile export HADOOP_HOME=/export/server/hadoop-3.3.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin[root@node01 server]# scp /etc/profile root@node03:/etc/profile profile 100% 2251 2.2MB/s 00:00 [root@node01 server]# scp /etc/profile root@node02:/etc/profile profilesource /etc/profile# 验证Hadoop环境变量是否生效 hadoop
3. NameNode format(格式化操作)
- 首次启动HDFS时,必须对其进行格式化操作(三台机器)
- format 本质上是初始化操作,进行HDFS清理和准备工作
hdfs namenode -format
原则上fomat只能执行一次,某些情况下因为多次执行fomat导致hdfs集群主从角色之间互不识别,可以通过删除所有机器的
hdoop.tmp.dir目录后重新执行format来解决。
初始化成功标识
4. Hadoop集群启停命令
-
手动逐个进程启停(每台机器上每次手动启动关闭一个角色进程,可以精准控制每个进程启停,避免群起群停)
-
HDFS集群
# hadoop2.x版本命令 hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode # hadoop3.x版本命令 hdfs --daemon start|stop namenode|datanode|secondarynamenode -
YARN集群
# hadoop2.x版本命令 yarn-daemon.sh start|stop resourcemanager|nodemanager # hadoop3.x版本命令 yarn --daemon start|stop resourcemanager|nodemanager
-
-
Shell 脚本一键启停
-
HDFS集群
start-dsf.sh stop-dsf.sh -
YARN集群
start-yarn.sh stop-yarn.sh -
Hadoop集群
start-all.sh stop-all.sh
-
5. 进程状态、日志查看
-
Hadoop 启动日志路径
/export/server/hadoop-3.3.0/log/ -
启动完毕之后使用
jsp查看进程是否启动成功(查看各个节点角色是否正常)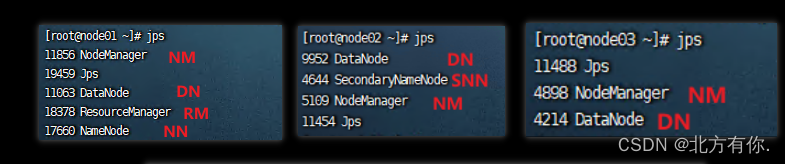
6.Web UI
-
HDFS 集群jsp
-
地址:http://namenode_host:9870
namenode_host是指namenode运行所在机器的主机名或IP地址若使用主机名访问需要在访问端设置hosts
-
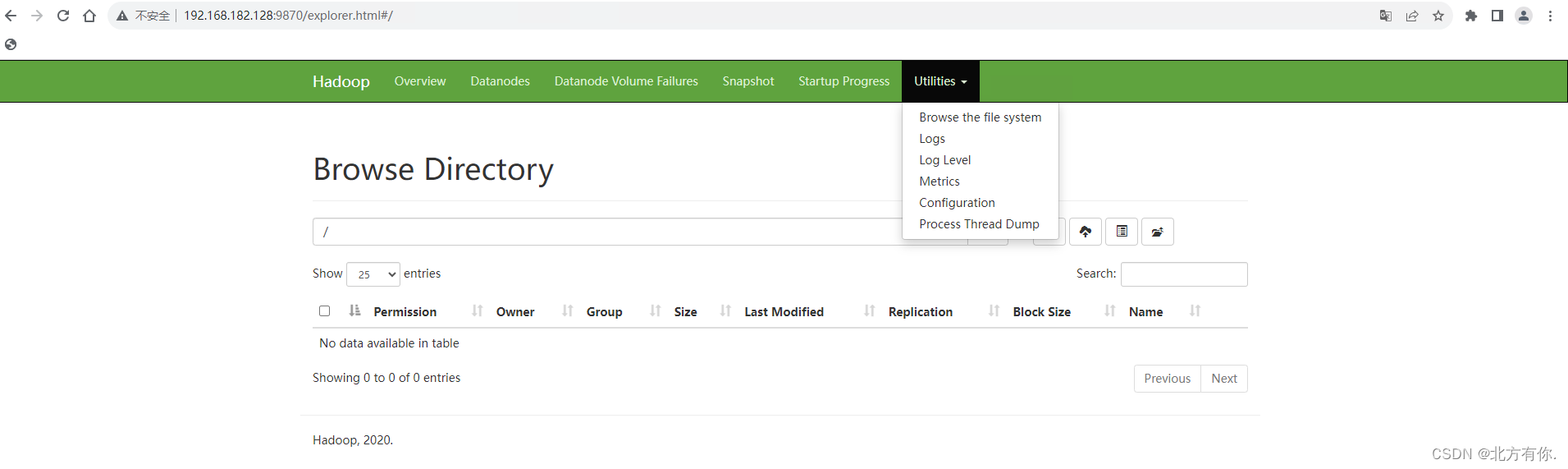
常用操作:浏览HDFS文件系统
【Utilities】-> 【Browse the file system】
-
-
YARN
-
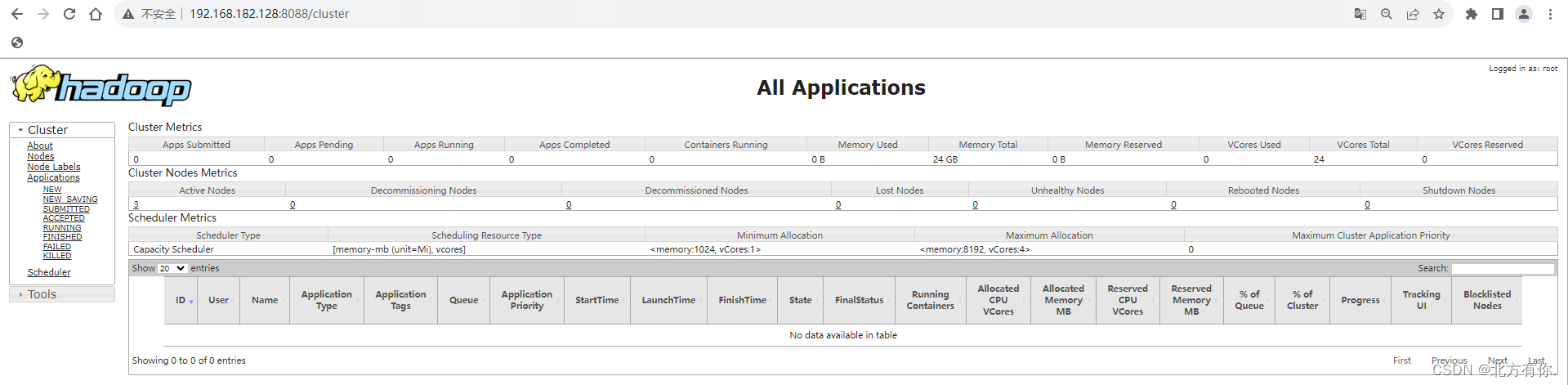
地址:http://resourcemanger_host:8088
resourcemanger_host是指resourcemanger运行所在机器的主机名或IP地址若使用主机名访问需要在访问端设置hosts
-
7. HDFS 初体验
- Shell操作
hadoop fs -mkdir /XXX # 创建文件夹
hadoop fs -put XXX # 上传XXX文件到HDFS
hadoop fs ls / # 列出 / 下的所有文件
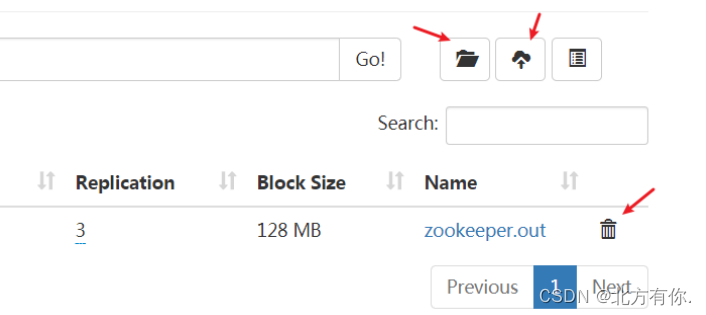
- Web UI 操作
8. MapReduce + YARN 初体验
-
执行Hadoop官方自带的MapReduce案例,评估圆周率Π的值
[root@node01 ~]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce/ [root@node01 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 4
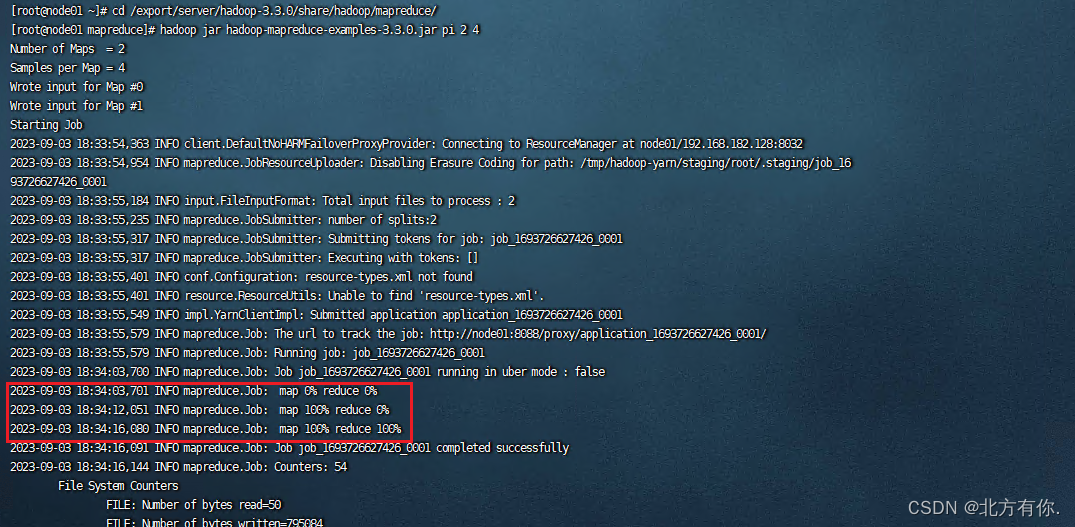
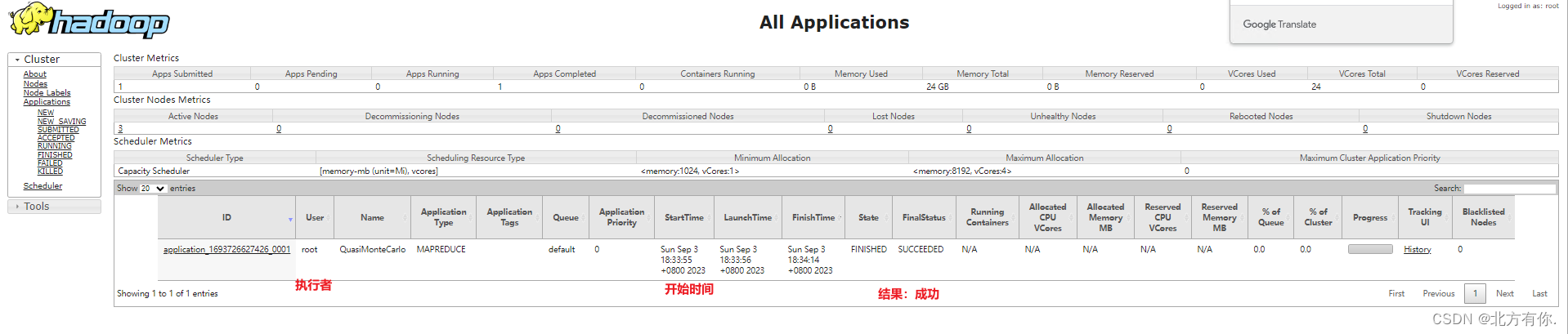
[root@node01 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
8. Bug记录
8.1 上传文件报错:Couldn’t upload the file

解决办法:打开Windos的C:\Windows\System32\drivers\etc\hosts文件写入本地域名解析或关闭科学上网环境
192.168.182.128 node01
192.168.182.129 node02
192.168.182.137 node03
















 2913
2913











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











