






注:我使用的编写运行软件是Jupyter Notebook (anaconda3)
目录
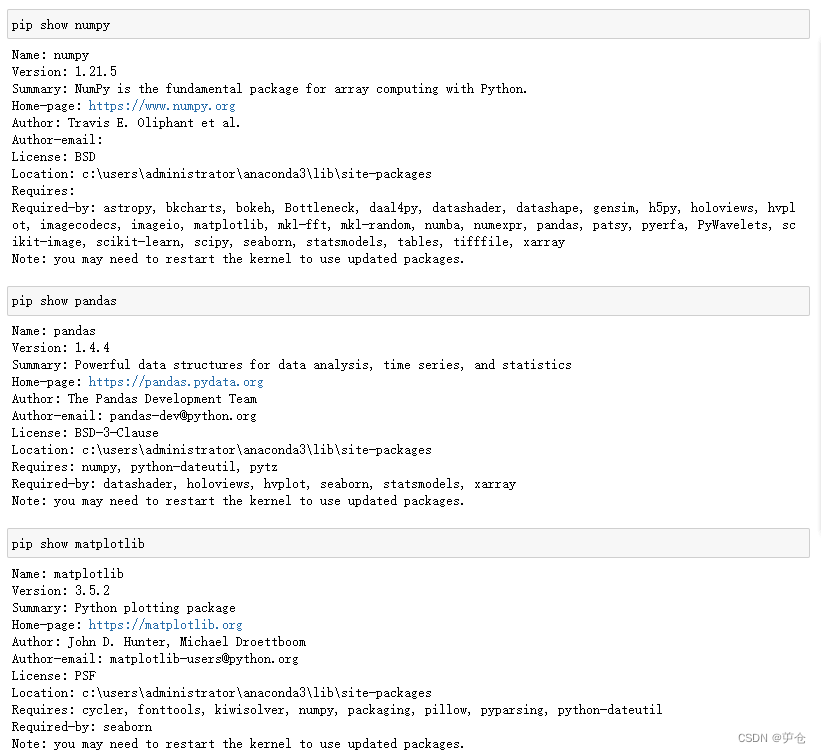
一、检测配置环境:检测所要使用的第三方库是否安装(未安装需先安装)
例题:(注:例题来源为个人课内书本例题,无附带材料链接,可作学习讨论参考)
一、检测配置环境:检测所要使用的第三方库是否安装(未安装需先安装)
一、pandas数据分析
Pandas 是一种基于MunPy的开源的威数据分析工具包,提供了高性能、简单易用的数据结构和数据分析函数。
1.Series对象
(1)定义和创建
(2)数据访问
(3)常用方法
(1)定义和创建
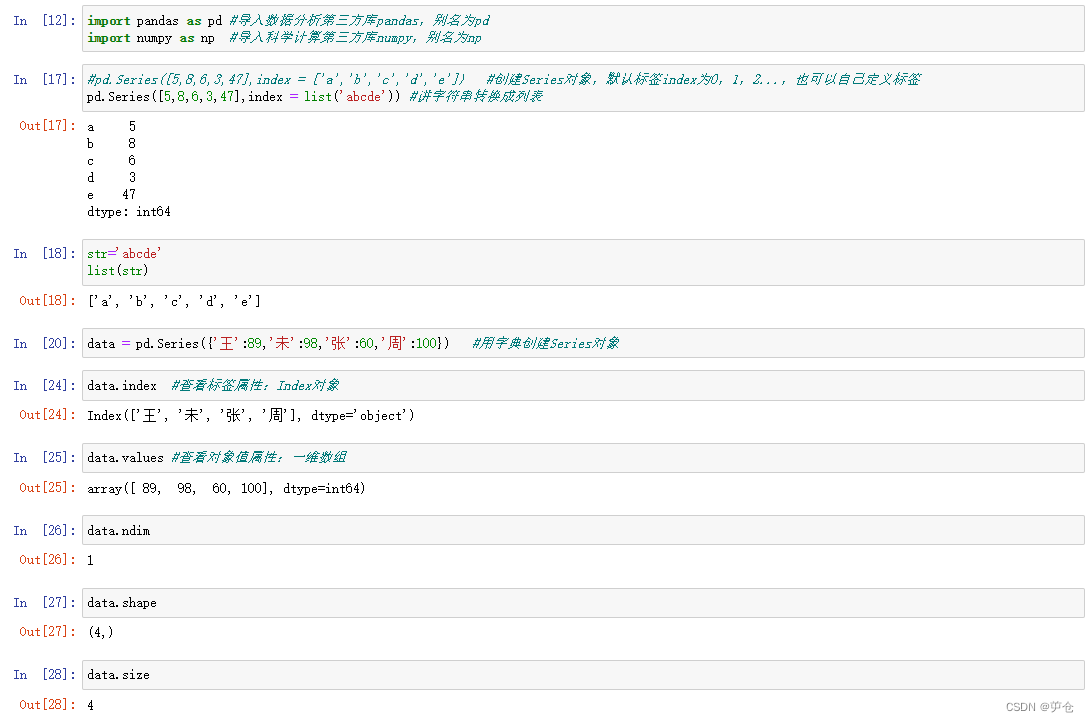
Series对象是一种带有标签数据的一维数组,标签在Pandas中有对应的数据类型“Index”,Series类似于一维数组与字典的结合。
(2)数据访问

(3)常用方法

2.DataFrame对象
(1)定义和创建
(2)数据访问
(3)常用方法
(4)常见操作
(1)定义和创建
DataFrane可以看作是一种既有行索引,又有列索引的二维数组,类似于Excel表或关系型数据库中的二维表,是Pandas中最常用的基本结构。

(2)数据访问


(3)常用方法
(4)常见操作
(1)Pandas中的缺失值处理
(2)Pandas中的分组操作
(3)Pandas中的数据合并操作
例题:(注:例题来源为个人课内书本例题,无附带材料链接,可作学习讨论参考)
P287_288_12.10:已知两个Excel表格:学生信息表exer_1.xlsx、期末考试成绩表exer_2.xsx分别用于存放学生的基本信息(包括姓名、性别、班级)和学生的期末成绩(包括姓名、语文、数学、英语、总分),如下图所示,完成以下操作。
1.使用Pandas读取两个表格数据,并将其根据姓名进行合并;
⒉实现按总分或语文、数学、英语单科从高到低排序功能;
3.打印所有存在不及格科目(单科<60分)的学生记录;
4.获取指定科目的最高分、最低分以及平均分;
5计算出3班女生语文成绩的平均分;
6.求出各班级数学的最高分、最低分以及平均分;
7.根据性别分组,获取男生所有科目的最高分、最低分以及平均分;
(首选.导入库
import numpy as np
import pandas as pd1.使用Pandas读取两个表格数据,并将其根据姓名进行合并
data_1 = pd.read_excel('../Stu_pack/pandas/exer_1.xlsx',skiprows =1) #读取文件数据
print(data_1)
data_2 = pd.read_excel('../Stu_pack/pandas/exer_2.xlsx',skiprows =1)
data_2data_3 = pd.merge(data_1,data_2) #根据相同的列表合并数据
#data_3 = data_1.join(data_2.set_index('姓名'),on = '姓名') #用join()方法合并
data_3⒉实现按总分或语文、数学、英语单科从高到低排序功能
def sort(df,col):
ss = df.sort_values(by = col,ascending = False)
return ss
col = input('请输入您要排序的列名:')
sort(data_3,col) #调用函数3.打印所有存在不及格科目(单科<60分)的学生记录
data_3[(data_3['语文']<60)|(data_3['数学']<60)|(data_3['英语']<60)] #对列表索引
data_3[(data_3.语文<60)|(data_3.数学<60)|(data_3.英语<60)] #对属性索引















 1401
1401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









