






目录
摘要
注意力机制是一种模仿人类注意力机制的方法,它允许神经网络在处理序列数据时重点关注相关元素,并忽略不相关的部分。这一思想在自然语言处理中得到了广泛应用,它使得模型能够更好地理解语言结构和语义关系。
Transformer 是一种深度学习模型,引入了自注意力机制,它是处理序列数据的重要工具。Transformer 的创新之一是自注意力机制,它允许模型同时处理输入序列的不同位置,从而更好地捕捉长距离的依赖关系。这一模型在机器翻译、文本生成和语言理解等任务中表现出色。
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的语言模型,它利用 Transformer 架构来学习文本的上下文相关表示。BERT 在多项自然语言处理任务中刷新了记录,因为它不仅能够预训练大规模文本数据,还可以微调以适应特定任务。
Abstract
Attentional mechanisms are an approach that mimics human attention mechanisms by allowing neural networks to focus on relevant elements and ignore irrelevant parts when processing sequential data. This idea is widely used in natural language processing, where it allows models to better understand linguistic structures and semantic relationships.
Transformer is a deep learning model that introduces the self-attention mechanism, which is an important tool for processing sequence data.One of the innovations of Transformer is the self-attention mechanism, which allows the model to process different positions of the input sequence at the same time, thus better capturing long-distance dependencies. This model excels in tasks such as machine translation, text generation and language understanding.
BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained language model that utilizes the Transformer architecture to learn context-sensitive representations of text.BERT has set records in a number of natural language processing tasks because it can not only pre trained on large-scale textual data, but also fine-tuned to fit specific tasks.
一、 self-attention
1.首先计算输入的向量之中,如a1,是否有其他向量与之相关。相关度记为
α
\alpha
α。计算过程如下。
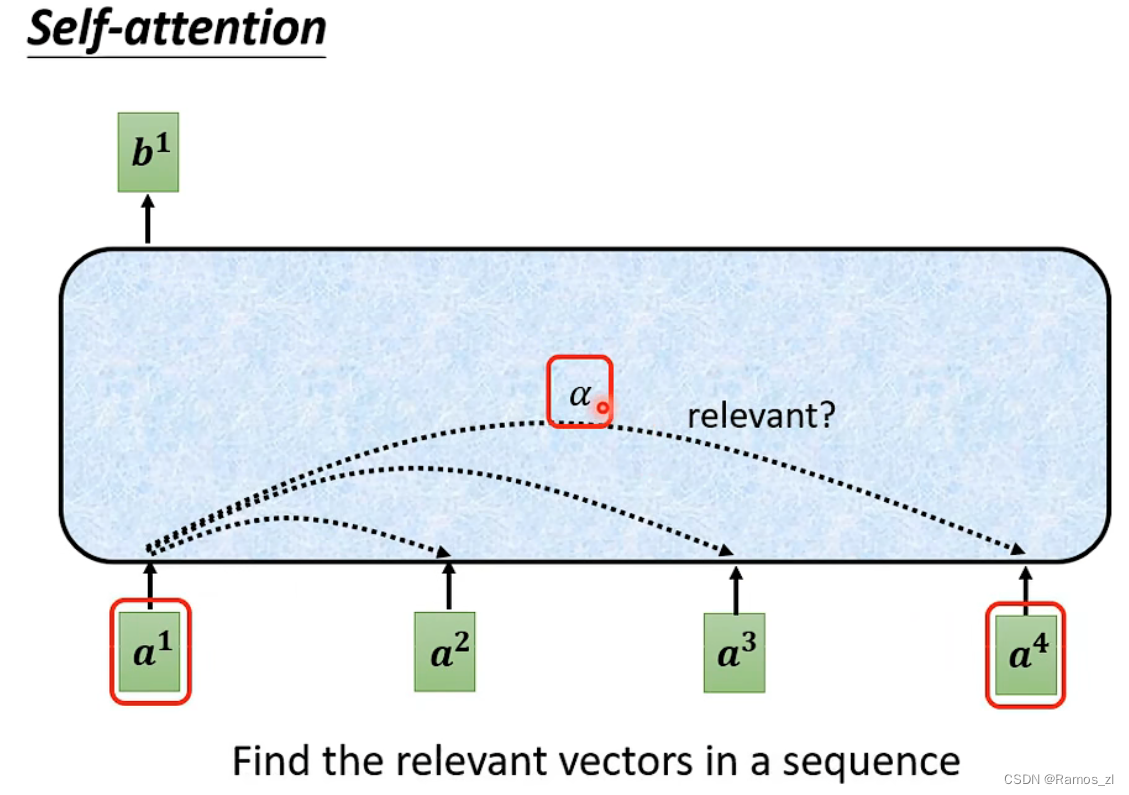
计算过程如图所示。将输入的向量分别乘上不同的矩阵Wq和Wk得到q和k,再将q和k进行点乘。
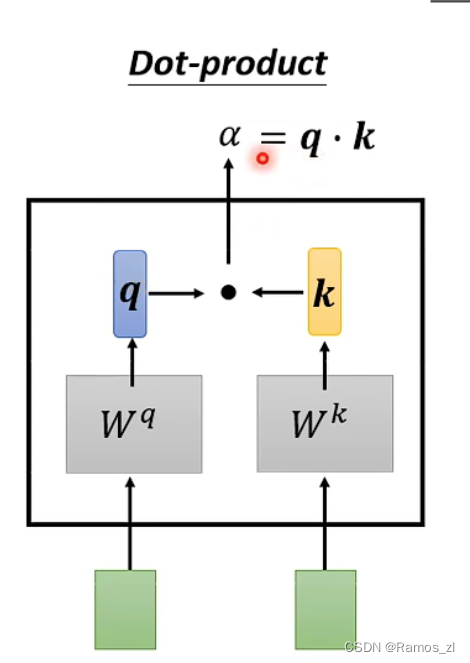
以a1为例,计算与其他向量的相似度时,将a1乘上Wq,其余的向量乘上Wk,再将得到的qi和ki进行点乘。得到的
α
\alpha
α再经过一层softmax得到最后的输出预测值。
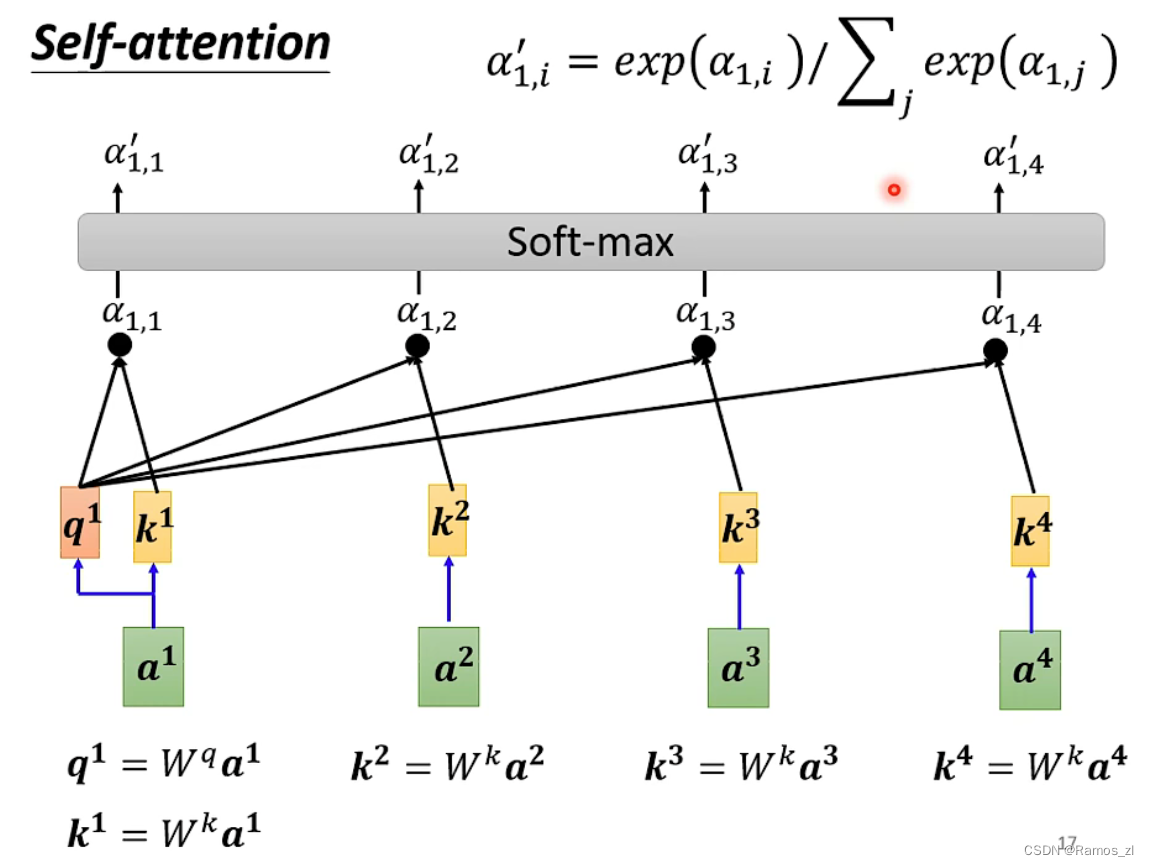
最后,将经过softmax的
α
\alpha
α与v相乘,再将其累加,则得到对应的输出b值。
对于注意力机制的理解,假如我们有一个问题:给出一段文本,使用一些关键词对它进行描述。
为了方便统一正确答案,这道题可能预先已经给大家写出了一些关键词作为提示,其中这些给出的提示就可以看作为key。而整个的文本信息就相当于是query。value的含义则更抽象,可以比作是你看到这段文本信息后,脑子里浮现的答案信息。这里我们又假设大家最开始都不是很聪明,第一次看到这段文本后脑子里基本上浮现的信息就只有提示这些信息因此key与value基本是相同的,但是随着我们对这个问题的深入理解,通过我们的思考脑子里想起来的东西越来越多。并且能够开始对我们query也就是这段文本,提取关键信息进行表示,这就是注意力作用的过程,通过这个过我们最终脑子里的value发生了变化,
根据提示key生成了query的关键词表示方法,也就是另外一种特征表示方法.
刚刚我们说到key和value一般情况下默认是相同,与query是不同的,这种是我们一般的注意力输入形式,但有一种特殊情况,就是我们query与key和value相同,这种情况我们称为自注意力机制,就如同我们的刚刚的使用一般注意力机制,是使用不同于给定文本的关键词表示它。
二、transformer
2.1 基本结构
encoder的结构如下图所示。其中一个block没有算作一层,是因为一个block中可能含有很多层。
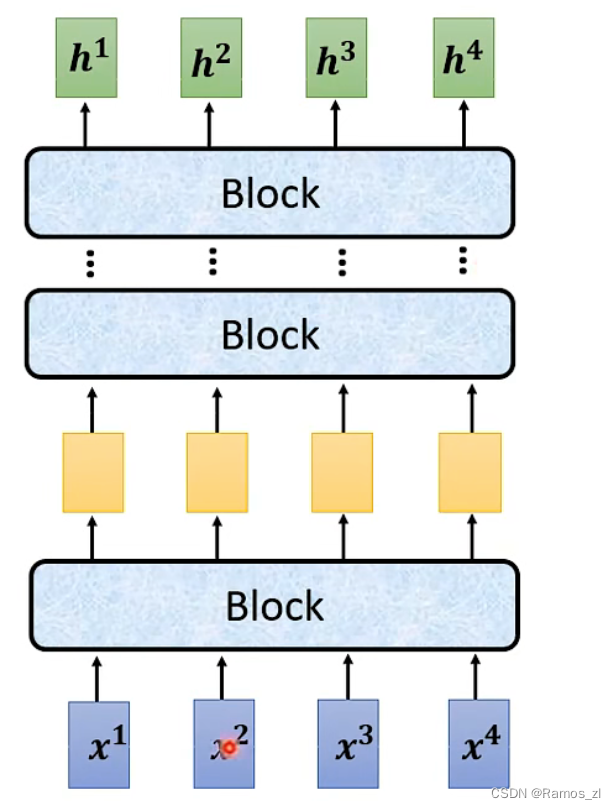
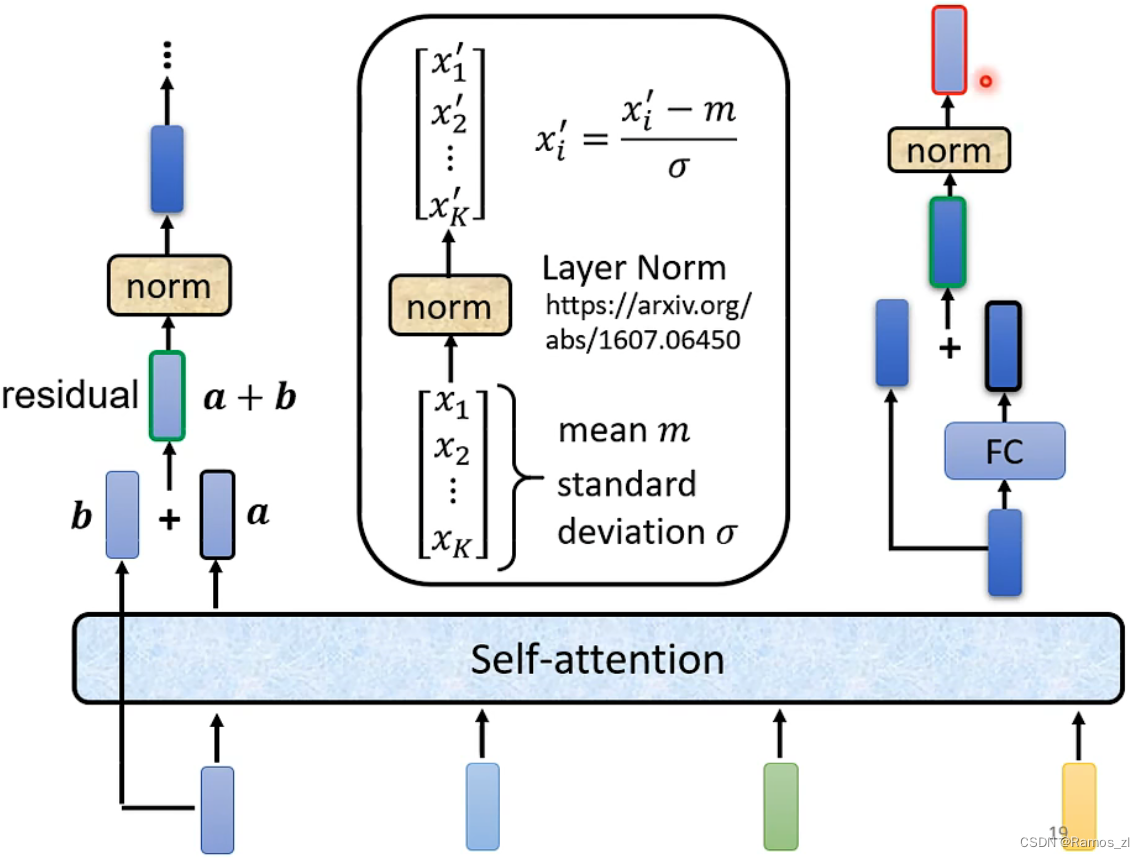
在transformer中,一个block的内部结构如下图所示。将输入向量输入到一层self-attention之后,得到的输出还要加上输入,才得到下一层的输入。将这种形式叫做residual connection。将其进行layer norm。将计算出的值放入
FC后再经过一层layer norm即可得到encoder的输出值。
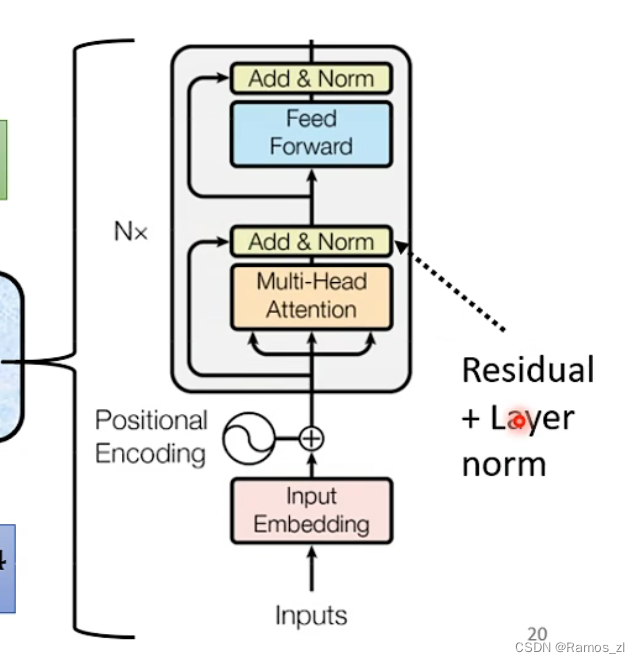
简化图如下图所示。
decoder示意图如下图所示。根据图片看出,encoder和decoder的区别在于decoder的中间部分,以及第一层的masked multi-head attention。其他部分基本类似。
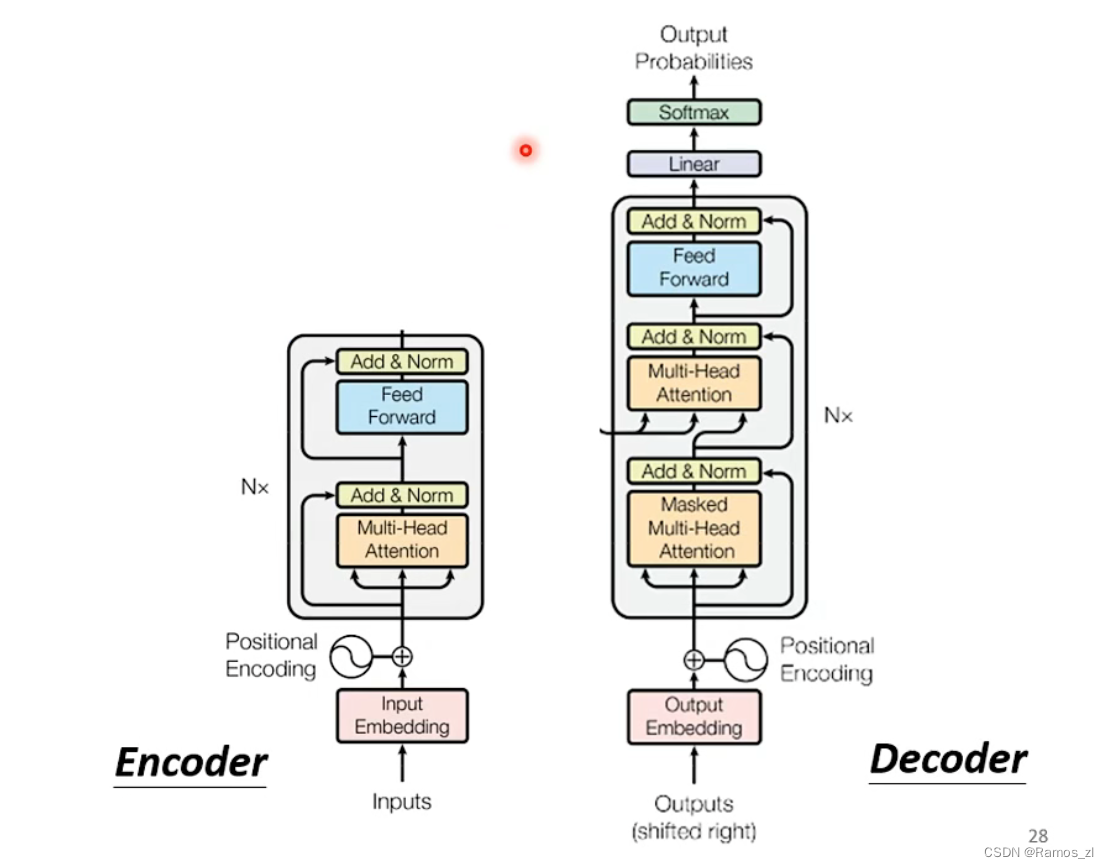
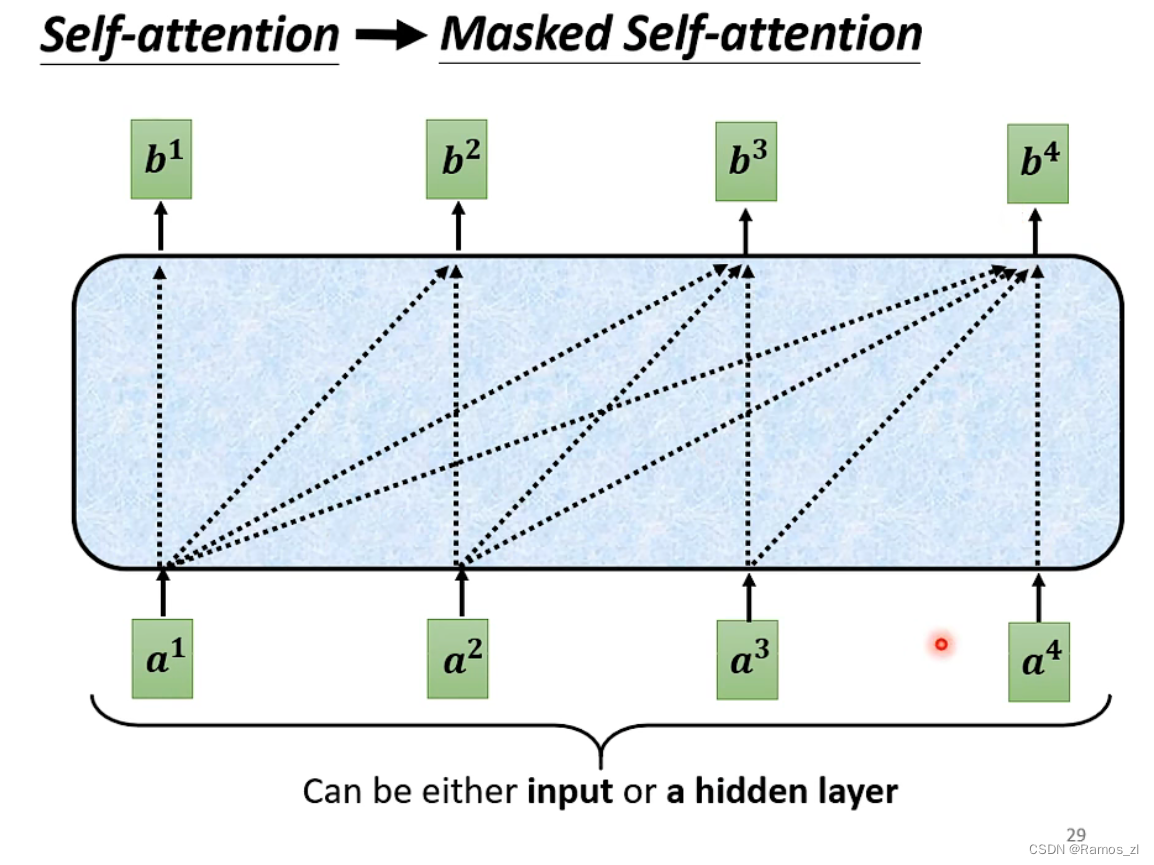
self-attention和masked self-attention的区别在于,masked self-attention不再关心后面的信息。比如计算向量b1,它就不会计算后面的a2,a3,a4。
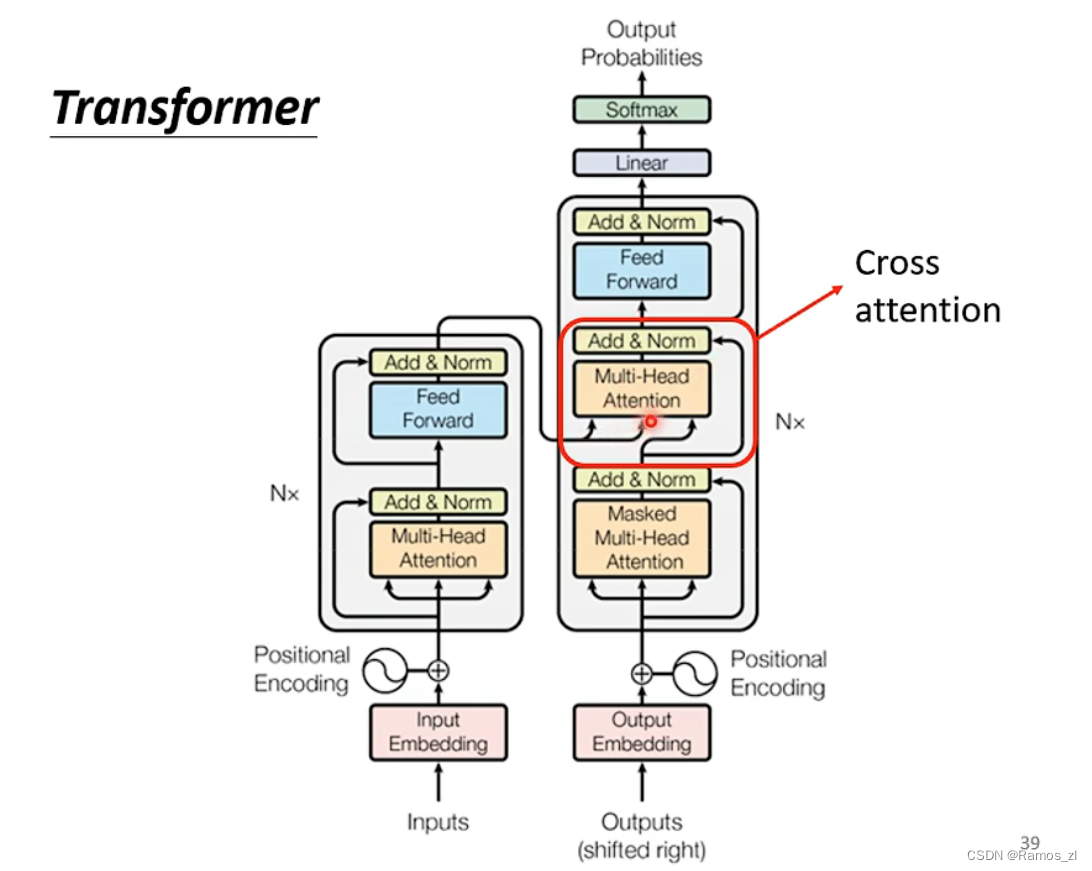
decoder的中间部分被叫做cross attention,它是连接encoder和decoder的桥梁。其中,encoder提供两个输入,decoder提供一个输入。
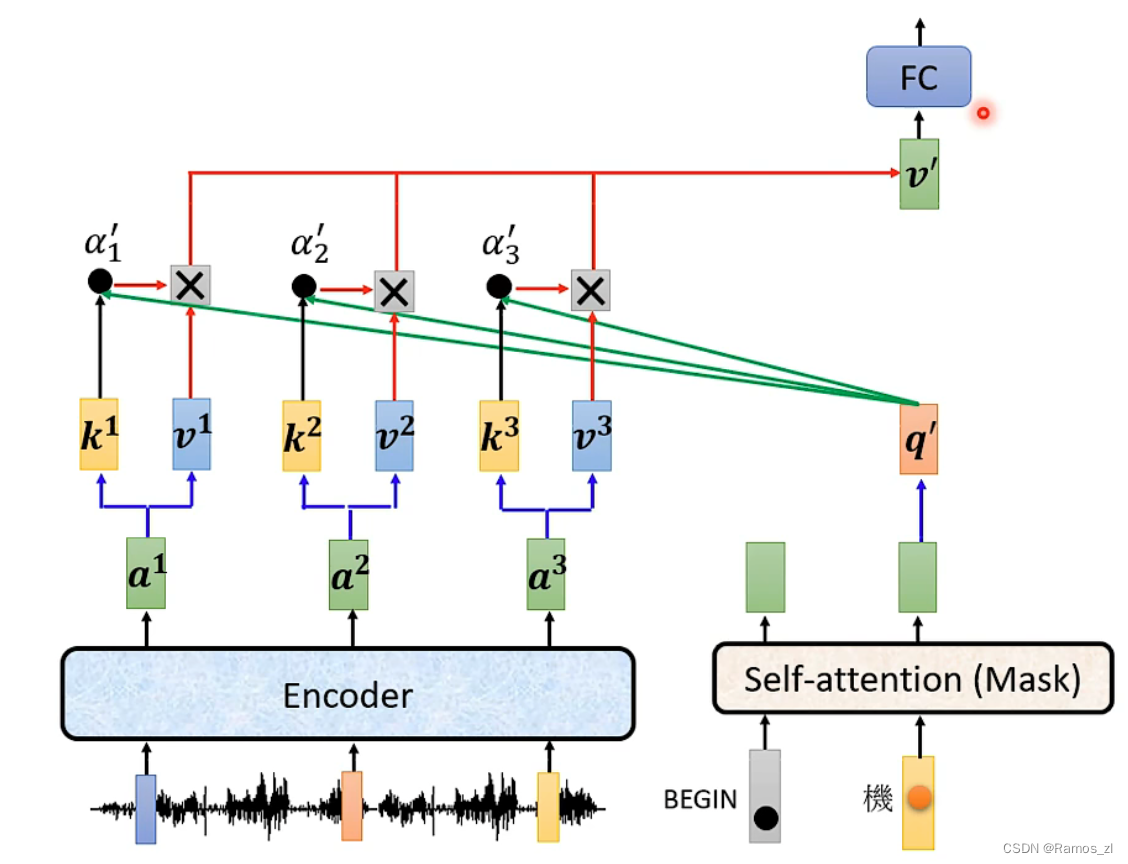
cross attention的结构如下图所示。
2.2 encoder代码实现
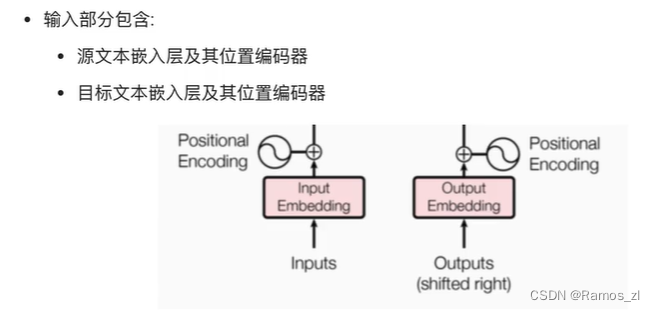
transformer的输入结构如下图所示。需要经过一层文本嵌入层和位置编码器。文本嵌入层使用了词嵌入。即设计一个可学习的权重矩阵 W,将词向量与这个矩阵进行点乘,即得到新的表示结果。假设 “爱” 和 “喜欢” 这两个词经过 one-hot 后分别表示为 10000 和 00001,权重矩阵设计如下:
[ w00, w01, w02
w10, w11, w12
w20, w21, w22
w30, w31, w32
w40, w41, w42 ]
那么两个词点乘后的结果分别是 [w00, w01, w02] 和 [w40, w41, w42],在网络学习过程中(这两个词后面通常都是接主语,如“你”,“他”等,或者在翻译场景,它们被翻译的目标意思也相近,它们要学习的目标一致或相近),权重矩阵的参数会不断进行更新,从而使得 [w00, w01, w02] 和 [w40, w41, w42] 的值越来越接近。
另一方面,对于以上这个例子,我们还把向量的维度从5维压缩到了3维。因此,word embedding 还可以起到降维的效果。
在 Pytorch 框架下,可以使用 torch.nn.Embedding来实现 word embedding:
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
其中,vocab 代表词汇表中的单词量,one-hot 编码后词向量的长度就是这个值;d_model代表权重矩阵的列数,通常为512,就是要将词向量的维度从 vocab 编码到 d_model。
输入部分的另外一部分就是位置编码器。因为在transformer的编码器结构中,并没有针对词汇位置信息的处理,因此需要在Embedding层后加入位置编码器。将词汇位置不同可能产生不同语义的信息加入到词嵌入张量中,以弥补位置信息的缺失。
import os
os.environ['CUDA_VISIBLE_DEVICES']='2,3,4,5'
import torch
print('CUDA_VISIBLE_DEVICES Count:',torch.cuda.device_count())
import torch
import numpy
import torch.nn as nn
import torch.nn.functional as F
# 关于word embedding, 以序列建模为例
src = ['I have a hd ,','but it is a big dog .']
tgt = ['wo you yi ge hd ,','dan shi ta shi yi zhi gou .']
src_len = 8 # for pad and position embedding
tgt_len = 10 # for pad and position embedding
max_pos_len = 20
# word_pad = ['P', 'S', 'E']
import numpy as np
# 从原始的句子生成字典和序号输入
def sentence2input(sentence):
'''
input: sentence
output: sequence, word2idx, idx2word
'''
source_split_words = [s.split(' ') for s in sentence]
word = []
for i in [j.split(' ') for j in sentence]:
word.extend(i)
# generate vocabulary =================
vocab = np.array(word)
vocab = np.unique(vocab)
idx2word = dict(enumerate(vocab,start=1)) # 从1开始因为pad填充0
word2idx = {v: k for k, v in idx2word.items()}
# word2idx = {w:i for i, w in enumerate(vocab)}
sequence = []
for n in source_split_words:
bs = [word2idx[w] for w in n]
sequence.append(bs)
return sequence, word2idx, idx2word
def pad(input,max_len,pad_value=0):
'''
input: sentence
output: sequence, word2idx, idx2word
'''
import copy
pad_ = []
for i in input:
# print(i)
ii = copy.deepcopy(i)
if len(i)<max_len:
error_len = max_len - len(i)
for _ in range(error_len):
ii.append(pad_value)
pad_.append(ii[:max_len])
pad_ = torch.IntTensor(pad_)
return pad_
src_input, src_vocab_word2idx, enc_vocab_idx2word = sentence2input(src)
tgt_input, tgt_vocab_word2idx, tgt_vocab_idx2word = sentence2input(tgt)
src_vocab_len = len(src_vocab_word2idx) # 后面会用到
tgt_vocab_len = len(tgt_vocab_word2idx) # 后面会用到
print(src_input)
print(tgt_input)
print('end!')
src_input_T = pad(src_input,src_len,pad_value=0)
tgt_input_T = pad(tgt_input,tgt_len,pad_value=0)
print(src_input_T)
print(tgt_input_T)
# 构造word embedding
model_dim = 8 # 512
src_embedding_table = nn.Embedding(src_vocab_len+1,model_dim) # 初始化一个embedding类,shape:num_embeddings: int, embedding_dim: int
tgt_embedding_table = nn.Embedding(tgt_vocab_len+1,model_dim) # 调用的是nn.Embedding类的forword方法,直接调用类后面一个括号就是调用该类中的forward方法
print(src_embedding_table.weight)
print(src_input_T)
src_embedding = src_embedding_table(src_input_T)
tgt_embedding = tgt_embedding_table(tgt_input_T)
print(src_embedding)
# 构造position embeddings
# src_len = 8 是input长度
# 构造全长 position embedding table
# max_pos_len = 20
pos_mat = torch.arange(max_pos_len).reshape(-1,1) # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19])
i_mat = torch.pow(1000, torch.arange(0,model_dim,2).reshape(1,-1)/model_dim) # tensor([[ 1.0000, 5.6234, 31.6228, 177.8279]])
pos_emb_table = torch.zeros(max_pos_len,model_dim)
pos_emb_table[:,0::2] = torch.sin(pos_mat/i_mat)
pos_emb_table[:,1::2] = torch.cos(pos_mat/i_mat)
pos_embedding = nn.Embedding(max_pos_len,model_dim)
# pos_embedding.weight # nn.Embedding.weight随机初始化方式是标准正态分布,即均值μ=0,方差σ=1的正态分布。
pos_embedding.weight = nn.Parameter(pos_emb_table,requires_grad=False) # 这里是修改nn.Embedding类的初始化权重.weight,改为计算出的pos_emb_table
# torch.nn.Parameter是继承自torch.Tensor的子类,其主要作用是作为nn.Module中的可训练参数使用。它与torch.Tensor的区别就是nn.Parameter会自动被认为是module的可训练参数,即加入到parameter()这个迭代器中去;而module中非nn.Parameter()的普通tensor是不在parameter中的。
# 获取 position count
src_pos = [list(range(src_len)) for _ in src] # 遍历样本src,src_len=8
src_pos = torch.IntTensor(src_pos)
print(src_pos)
tgt_pos = [list(range(tgt_len)) for _ in src] # 遍历样本src,tgt_len=10
tgt_pos = torch.IntTensor(tgt_pos)
print(tgt_pos)
src_pos_embedding = pos_embedding(src_pos) # src 和tgt 输入到一个全长的 position embedding table中
tgt_pos_embedding = pos_embedding(tgt_pos)
src_pos_embedding.size(), tgt_pos_embedding.size()
三、自监督学习
Bert属于self-surprised learning,或者semi-surprised learning。因为数据无标签,需要自己想办法打标签,然后做监督学习。也就是说,x既是输入,也用来打标签。
BERT内部,是transformer的encoder,也就是self-attention——norm——FC——norm的基础上加上residual和muti-head,输入多长,输出也多长。
3.1 BERT可以解决的两类任务
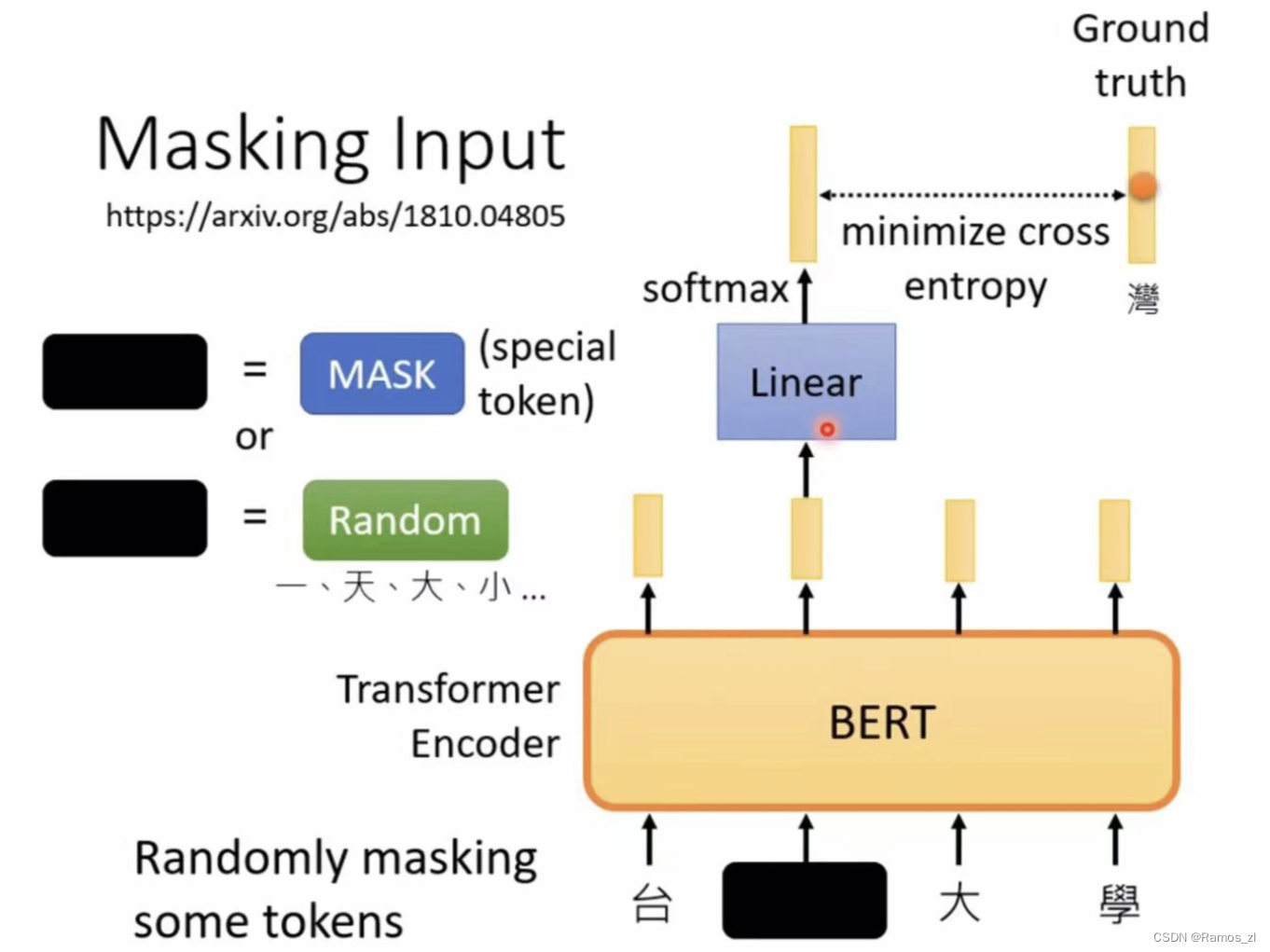
填空题
用mask或者random的方法把输入的seq的每个vec遮住或者转化。mask是把vec遮成special token;random是随机盖住vec。
BERT之后输出的向量,将被遮住的那个输出的向量,做linear transform,再经过softmax评分得出输出的向量。
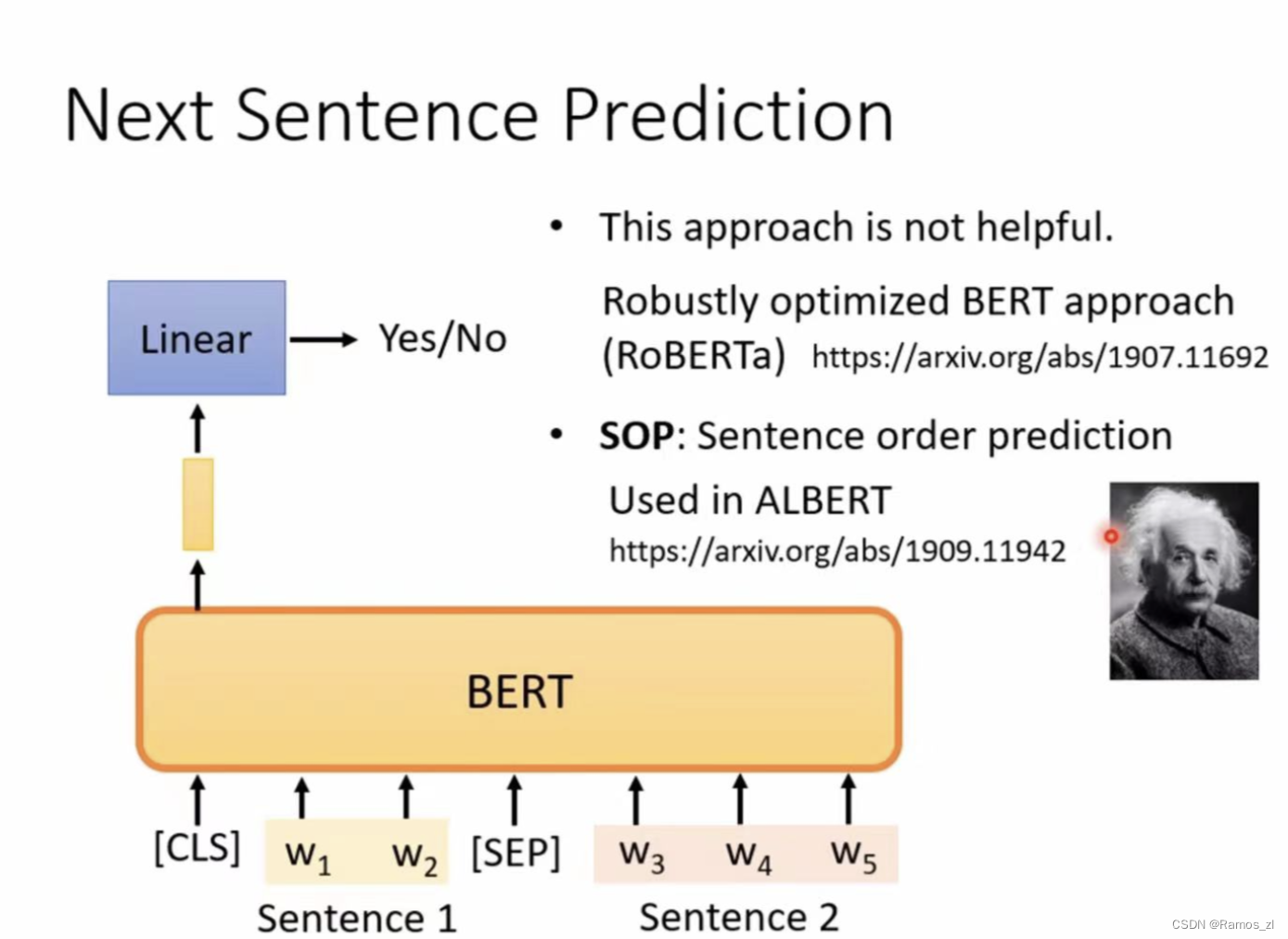
判断两个句子是否是连接的
在第一个句子前设置一个向量,经过BERT,输出向量后再做linear regression,仅用一个向量判断两个句子是否是连在一起的。
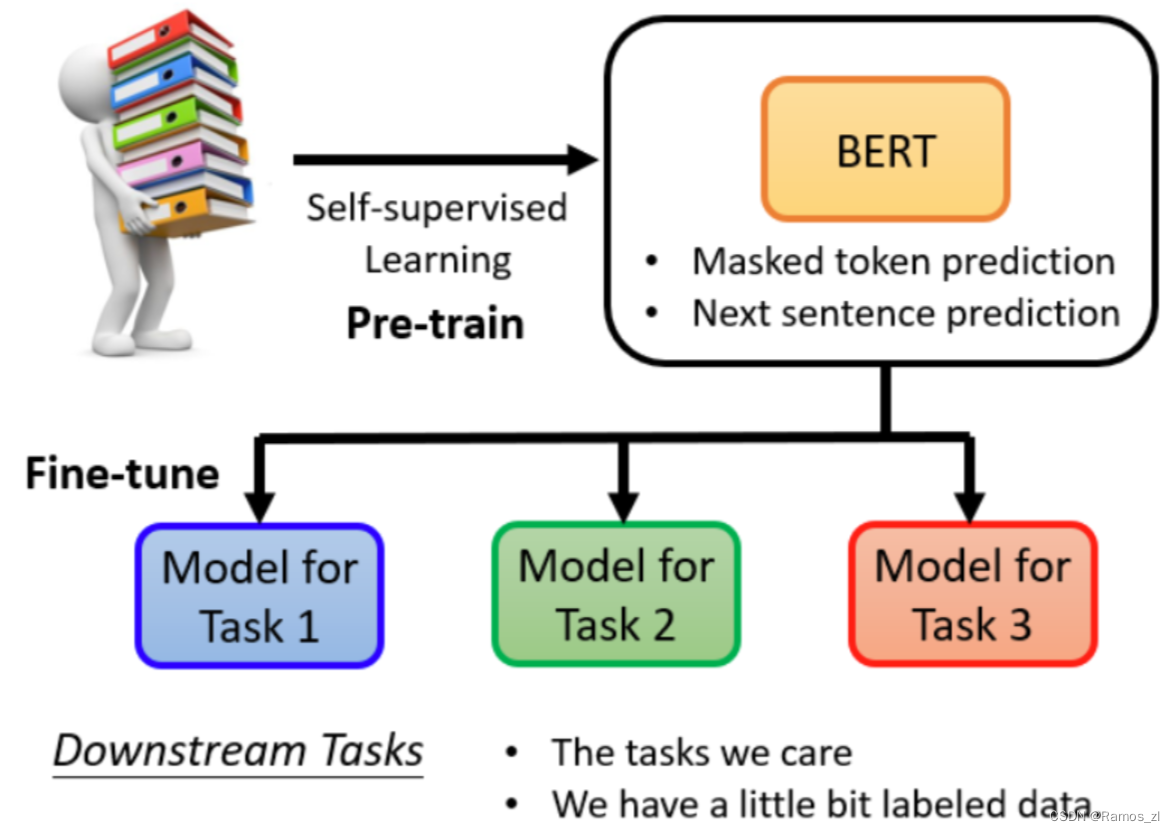
3.2 使用训练好的BERT模型
实际应用中,一般使用 BERT 作为预训练模型(GPT),然后对其进行微调(fine-tune) 以适应解决某种特殊或具体的问题。评估 BERT 模型的好坏通常使用 GLUE(General Language Understanding Evaluation) 方法:将BERT分别做微调放于GLUE的九个任务中,得到的分数再取平均值即为评价指标。生成BERT的过程就是Self-supervised学习(资料来源于自身),fine-tune过程是supervised learning(有标注的资料),所以整个过程是semi-supervised。所谓的 "半监督 "是指有大量的无标签数据和少量的有标签数据。
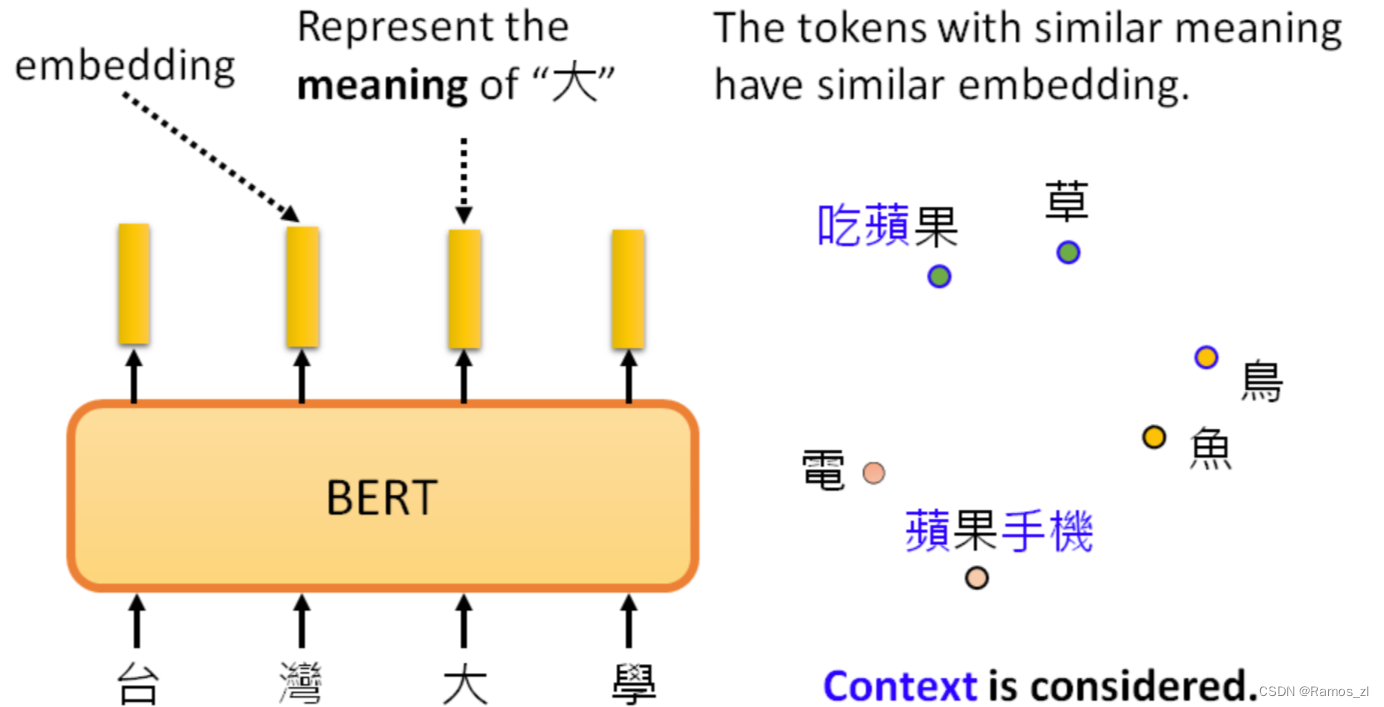
3.4 为什么做填空题的BERT有用
pre-train的BERT会做填空题,那为什么微调一下就能用作其他的应用呢?
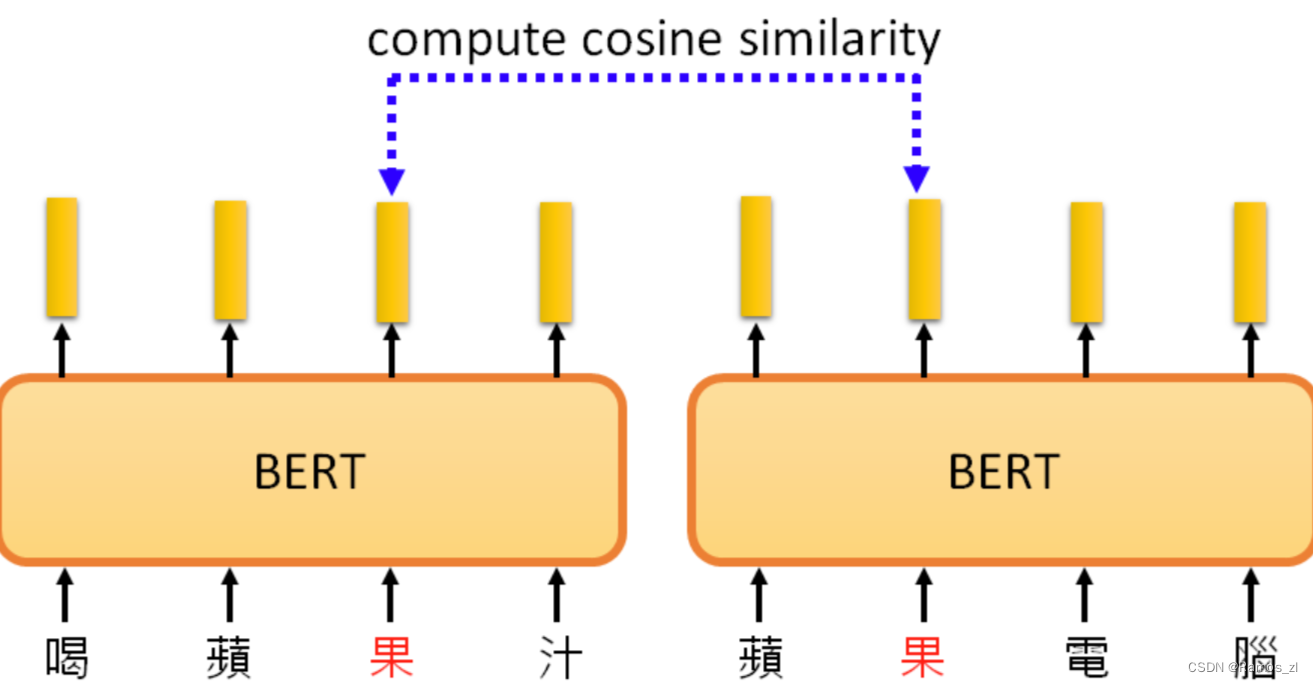
输入一串文本,每个文本都有一个对应的输出向量,这个向量称之为embedding,代表了输入词的含义。意思越相近的字产生的向量越接近,如图右部分。同时,BERT会根据上下文,不同语义的同一个字产生不同的向量(例如“果”字)。
下图中,根据 "苹果 "一词的不同语境,得到的向量会有所不同。计算这些结果之间的cosine similarity,即计算它们的相似度。计算每一对之间的相似度,得到一个10×10的矩阵。相似度越高,这个颜色就越浅。前五个 "苹果 "和后五个 "苹果 "之间的相似度相对较低。BERT知道,前五个 "苹果 "是指可食用的苹果,所以它们比较接近。最后五个 "苹果 "指的是苹果公司,所以它们比较接近。所以BERT知道,上下两堆 "苹果 "的含义不同
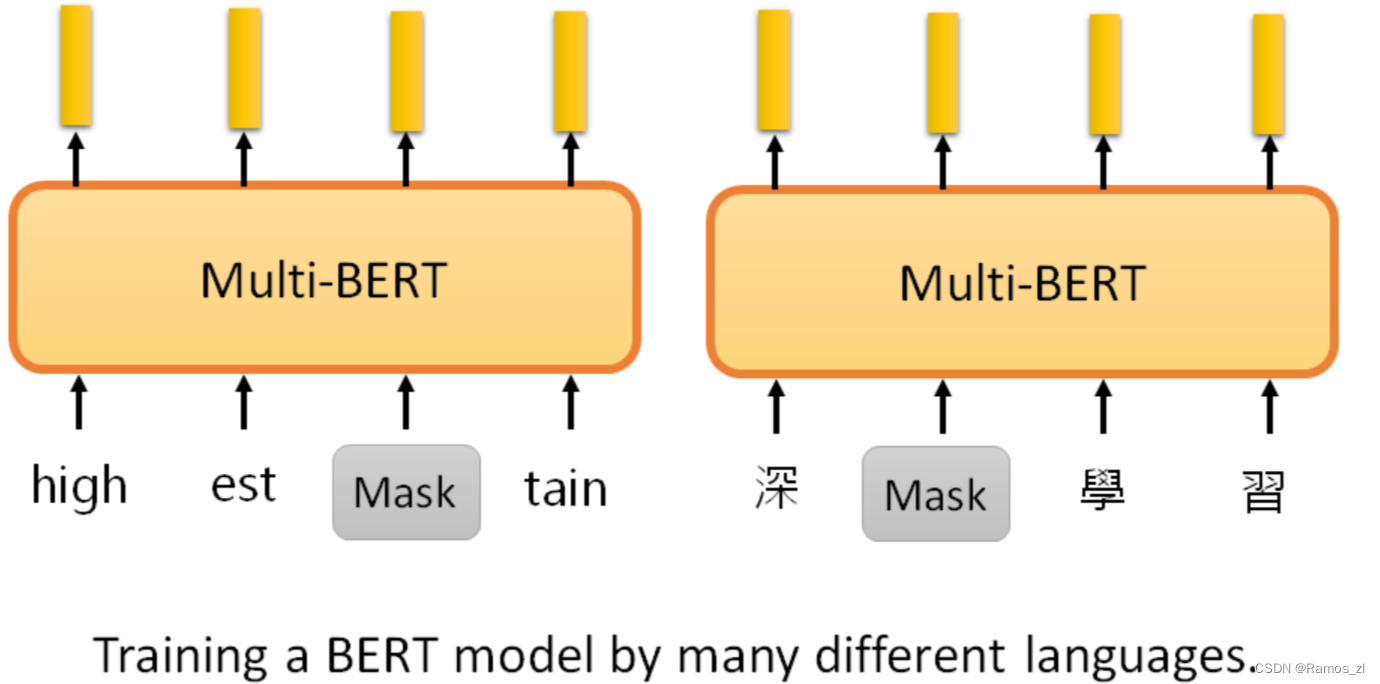
3.5 Multi-lingual BERT(多语言BERT)
Multi-lingual BERT是用许多不同的语言预训练的BERT。如果把一个Multi-lingual的BERT用英文问答数据进行微调,它就会自动学习如何做中文问答,有78%的正确率。fine-tune是训练时输入的语言,test是测试时输入问题和文章的语言。
它从未接受过中文和英文之间的翻译训练,也从未阅读过中文Q&A的数据收集,在预训练中,学习的目标是填空,它用中文只能填空。有了这些知识,再加上做英文问答的能力,不知不觉中,它就自动学会了做中文问答。
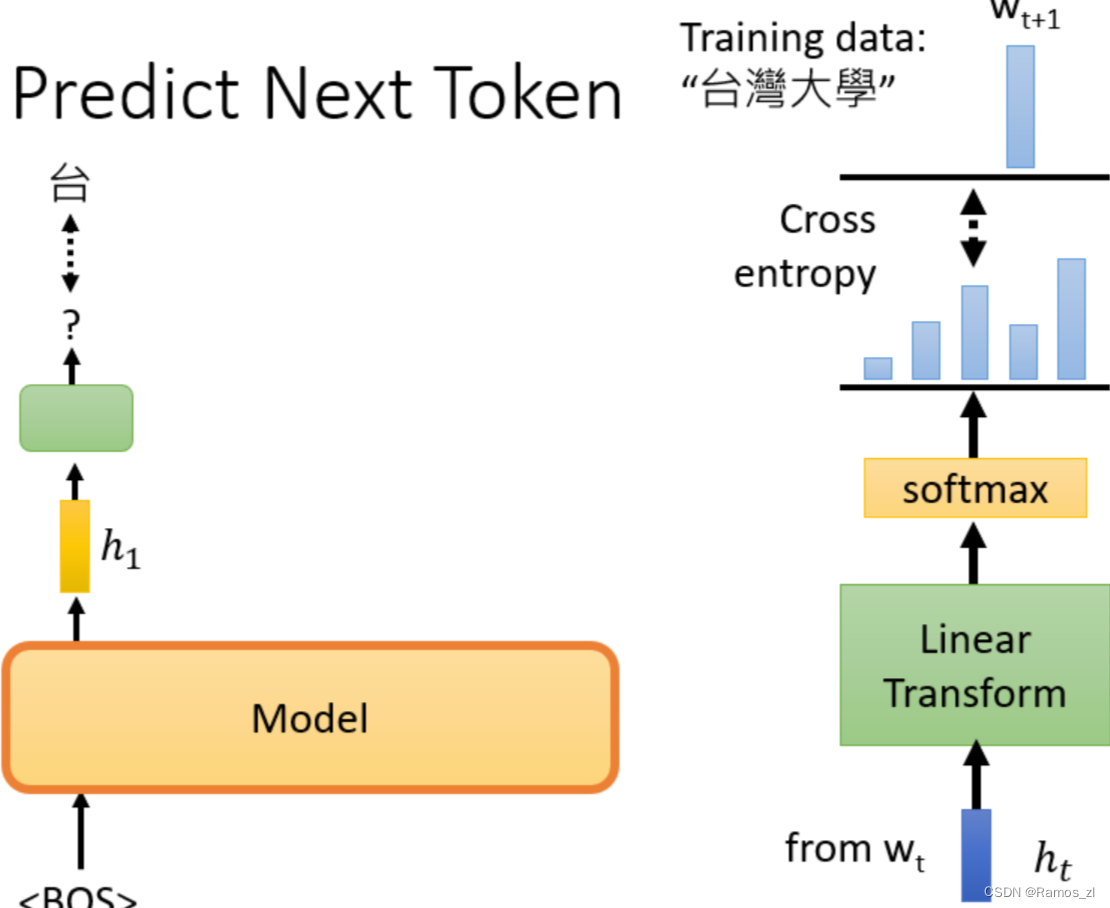
3.6 GPT
BERT模型能够做填空题,GPT模型则能预测下一个token(单位)。
例如有笔训练资料是“台湾大学”,那么输入BOS后训练输出是台,再将BOS和"台"作为输入训练输出是湾,给它BOS “台"和"湾”,然后它应该要预测"大",以此类推。模型输出embedding h,h再经过linear transform和softmax后,计算输出分布与正确答案之间的cross entropy,希望它越小越好(与一般的分类问题是一样的)。
和普通的学习不一样,它不需要用到gradient descent(梯度下降),完全没有要去调GPT那个模型参数的意思,所以在GPT的文献裡面把这种训练给了一个特殊的名字,叫做In-context Learning,代表说它不是一般的learning,它连gradient descent都没有做。但是它的准确率不是太高。
总结
注意力机制、Transformer 和 BERT 代表了深度学习和自然语言处理领域的重要进展。它们提供了强大的工具,用于处理序列数据、理解文本,并在各种自然语言处理任务中取得卓越的成就。这些技术的不断发展将进一步推动自然语言处理领域的创新和进步。















 827
827











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









