






目录
摘要
本周初步学习了GAN的一些基本知识,包括如何将神经网络作为生成器来产生满足需要的分布的输出,以及为什么需要让神经网络按照需要的分布进行输出。同时还学习了GAN的一些基本概念和原理,了解了GAN实现的目标和算法过程。最后使用代码实现了一个GAN的应用。
本周还阅读了一篇关于水质预测的文章,该文章使用BiGRU作为基础模型,同时结合了EWT数据分解和FCM聚类方法。该论文的预测方法大致为先将训练集时间序列分解并对分解的训练集时间子序列进行重组,然后才将子序列输入BiGRU得到每个子序列的预测值,最后对每个子序列的预测值进行求和得到最终预测的结果。
Abstract
This week, We began our initial exploration of some fundamental concepts in Generative Adversarial Networks (GANs). This included understanding how to employ neural networks as generators to produce outputs that conform to a desired distribution and the rationale behind ensuring that neural networks generate outputs according to the specified distribution. Additionally, We delved into fundamental concepts and principles of GANs, gaining insights into the objectives and algorithmic processes involved in GAN implementation. Finally, We implemented a GAN application using code.
We also read an article on water quality prediction this week. The article utilized BiGRU as the foundational model, coupled with EWT data decomposition and FCM clustering methods. The predictive approach in this paper involves initially decomposing the time series of the training set, reorganizing the decomposed training set time sub-sequences, inputting these sub-sequences into BiGRU to obtain predictions for each sub-sequence, and finally summing the predicted values for each sub-sequence to derive the ultimate prediction result.
一、文献阅读
论文标题:
Water quality forecasting based on data decomposition, fuzzy clustering and deep learning neural network
论文摘要:
水质预报可为保护公众健康和支持水资源管理提供有用信息。为了更准确地预测水质,本文提出了一种将数据分解(Data Decomposition)、模糊c均值聚类(Fuzzy C-means Clustering,FCM)和双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)相结合的混合模型。首先通过经验小波变换(Empirical Wavelet Transform,EWT)将原始水质数据分解为若干子序列,然后通过模糊c均值聚类对分解后的子序列进行重组。其次,针对每个聚类序列,采用双向门控循环单元建立预测模型。最后,对各子序列的预测结果进行求和,得到预测结果。利用鄱阳湖水质资料对所建预测模型进行了评价。结果表明,本文提出的预测模型对6个水质数据均提供了较高的预测精度,6个水质数据预测结果的MAPE均值为4.59%。此外,我们的模型比其他模型具有更好的预测性能。特别是与单一BiGRU模型相比,MAPE平均下降了32.86%。结果表明,该预测模型可以有效地用于水质预测。
过去方案:对这一问题的研究主要有两种方式,一种是采用过程驱动的方法,另一种是采用数据驱动的方法。基于流体动力学定律的过程驱动方法是开发预测模型的有力工具,然而,过程驱动的建模需要支流和污染源的详细信息,还需要对物理和化学过程有深入的了解。另一方面,与过程驱动建模相比,数据驱动建模方法仅使用观测数据来绘制变量之间的数学关系,因此不需要模型校准等复杂的理论和过程。此外,为一个站点开发的数据驱动模型可以很容易地应用于其他站点。因此,鉴于数据驱动方法的优势,它已被许多科学家广泛研究。水质预报使用了几种数据驱动的模型,如自回归综合移动平均(ARIMA)、多元线性回归、广义自回归条件异方差等。然而,这些传统的基于统计的模型无法考虑输入数据的时间顺序,因此它们不适合时间序列预测。
随着人工智能的发展,机器学习模型正在成为数据驱动建模的焦点,特别是LSTM和GRU等深度学习模型,显示出强大的水质预测能力。然而,在某些情况下,单一的机器学习模型无法提供令人满意的预测结果,因为水质通常以非常复杂的方式变化,因此,一些研究提出了几种类型的混合模型,例如数据同化模型和理论引导模型。但是,这些模型直接使用单比例数据,因此它们只能使用数据的表面特征。研究表明,基于多尺度数据的模型,即基于数据分解的模型可以从原始时间序列中提取更详细的信息,从而通过此类模型获得更准确的预测。利用数据分解开发预测模型,许多研究人员开发了结合了数据分解和机器学习算法的新型混合模型,例如小波分解、经验模态分解、变分模态分解、经验小波变换等。从前人的研究结果可以看出,数据分解技能是增强回归模型仿真能力的有效方法。然而,一些研究表明,基于实时数据分解的预测模型比没有结合数据分解的单一模型提供更差的结果。这是因为在实时分解中,通过逐步分解获得的分解结果彼此具有不同的趋势,因此它在每一步提取不同的关系,导致回归建模失败。换言之,要想成功应用数据分解来开发预测模型,必须设计合适的数据分解策略和建模方法。水质时间序列数据与其他时间序列数据(如空气质量或风速)具有不同的特征。它在许多方面都与其他数据不同,例如监测周期和时间相关性等。因此,开发基于实时数据分解的水质预测模型具有现实意义。
论文方案:本文利用经验小波变换(EWT)、模糊C均值聚类(FCM)和双向门控循环单元(BiGRU)提出了一种新的基于数据分解的预测模型。新颖性如下:①采用FCM来减少实时数据分解带来的不必要的错误。在基于数据分解的预测模型中,大量的模式通常会对预测准确性造成负面影响。②BiGRU首次应用于水质预报。GRU只考虑单向关系,因此它不能完全表示具有双向相关性的数据的关系。由于BiGRU由两个GRU(前向传播和后向传播)组成,以考虑双向关系,因此BiGRU可以预期是比GRU更好的水质预测选择。③提出了一种新的基于数据分解的建模方法。与现有的基于数据分解的建模方法不同,所提方法收集每个时间点的分解结果,考虑整体动态趋势,构建投入产出关系。

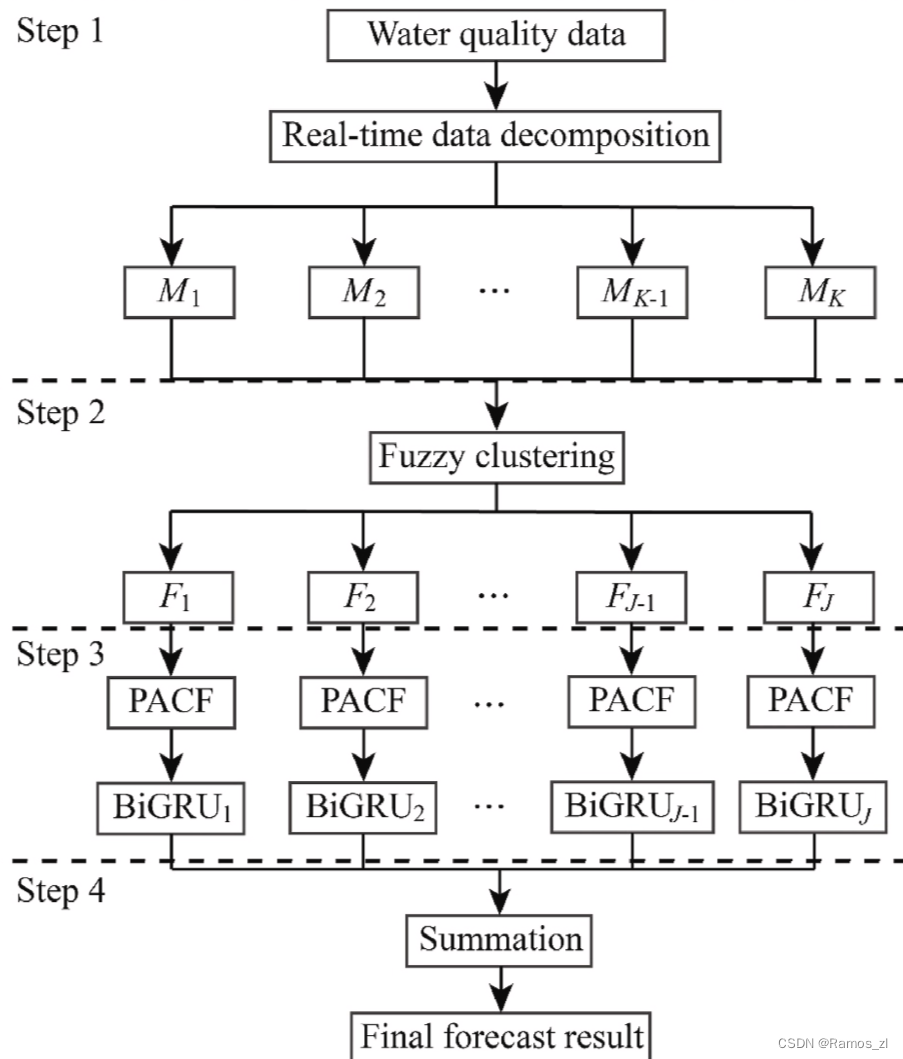
模型的预测过程如下:
step1:水质时间序列被分解为几个组成部分。
step2:分解的组成部分通过FCM重新组合。
step3:对step2中得到的每一个子序列进行部分自相关函数(Partial Autocorrelation Function,PACF)分析,从其时间滞后子序列中得到合适的输入数据,然后利用BiGRU得到预测结果。
step4:最终的预测结果是通过对step3中获得的预测结果的总和得到的。
二、 Network as Generator
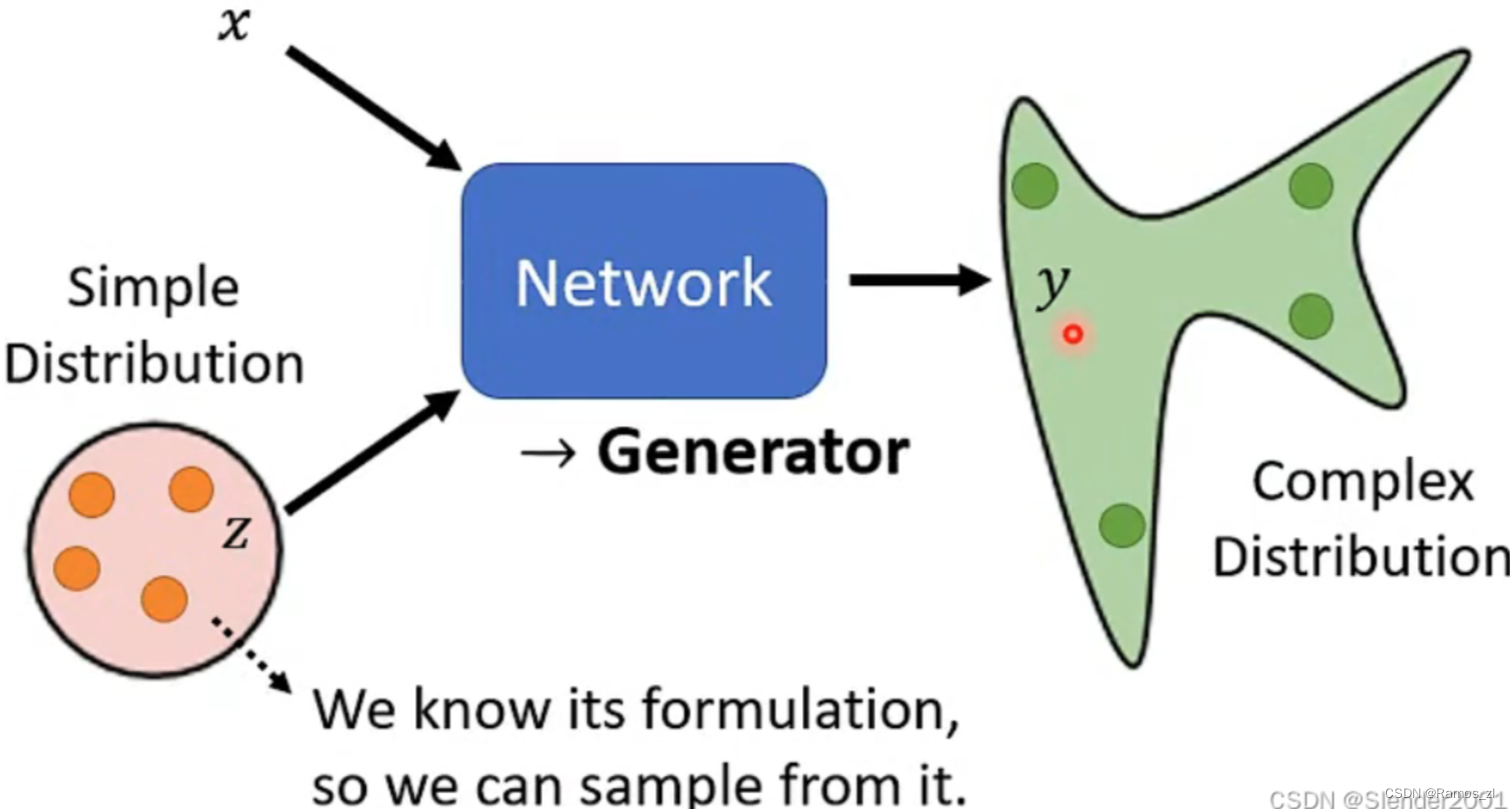
目前学习的各种各样的Network都是基于输入一个向量数据、图片数据、序列数据或者图结构数据等得到一个结果,这个结果可以是一个数据、类别或者是序列。现在我们要开始学习如何将Network当成Generator来用。和之前学习的Network唯一不同的地方在于,我们需要再加上一个z,这个z是从某一个Simple Distribution(例如Gaussian Distribution)中Sample出来的。也就是说此时的Network需要同时根据输入数据x和z来输出结果y。结合x和z的方式有很多种,比如将向量z接到向量x后面,根据x和z的数据形式的不同,结合方式也多种多样。z特别的地方在于其不确定性,每一次使用Network时的z都是随机生成的。正因为z的特性,所以使得输入x对应的输出y不再单一,成为了一个复杂的Distribution。而这种输出为Distribution的Network就是Generator。
2.1 Why Distribution?
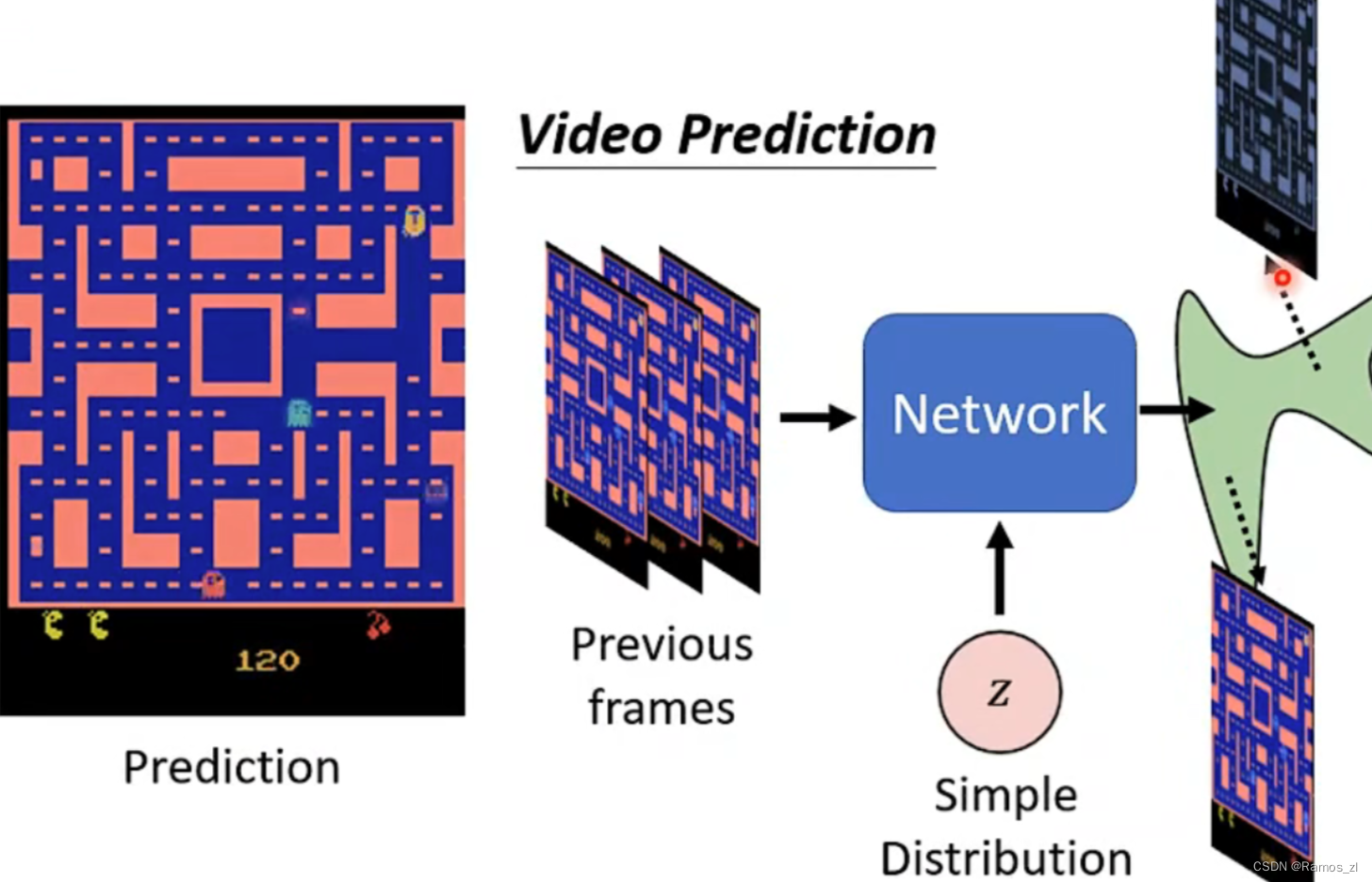
为什么我们需要Distribution作为输出?举一个简单的例子,在“吃豆人”这个游戏中,游戏NPC在地图内移动,如果我们想要预测这些NPC下一步的行动,需要将过去的游戏画面输入Network中,然后得到这些NPC下一步可能移动的结果。但有一个问题是,这些NPC在面对转向路口时,可能往左走,也可能往右走,此时Network得到两种方向的结果都是正确的,显然会给模型训练带来影响。因此需要机器的输出是有几率的,而不是确定的某一个结果。
2.2 Unconditional Generation
仅通过Simple Distribution来Sample出低维数据作为Generator的输入称之为无条件生成(Unconditional Generation),然后通过Generator产生Complex Distribution,这个Complex Distribution中都是高维数据,每一个高维数据都表示一种可能的结果

2.3 Basic Idea of GAN
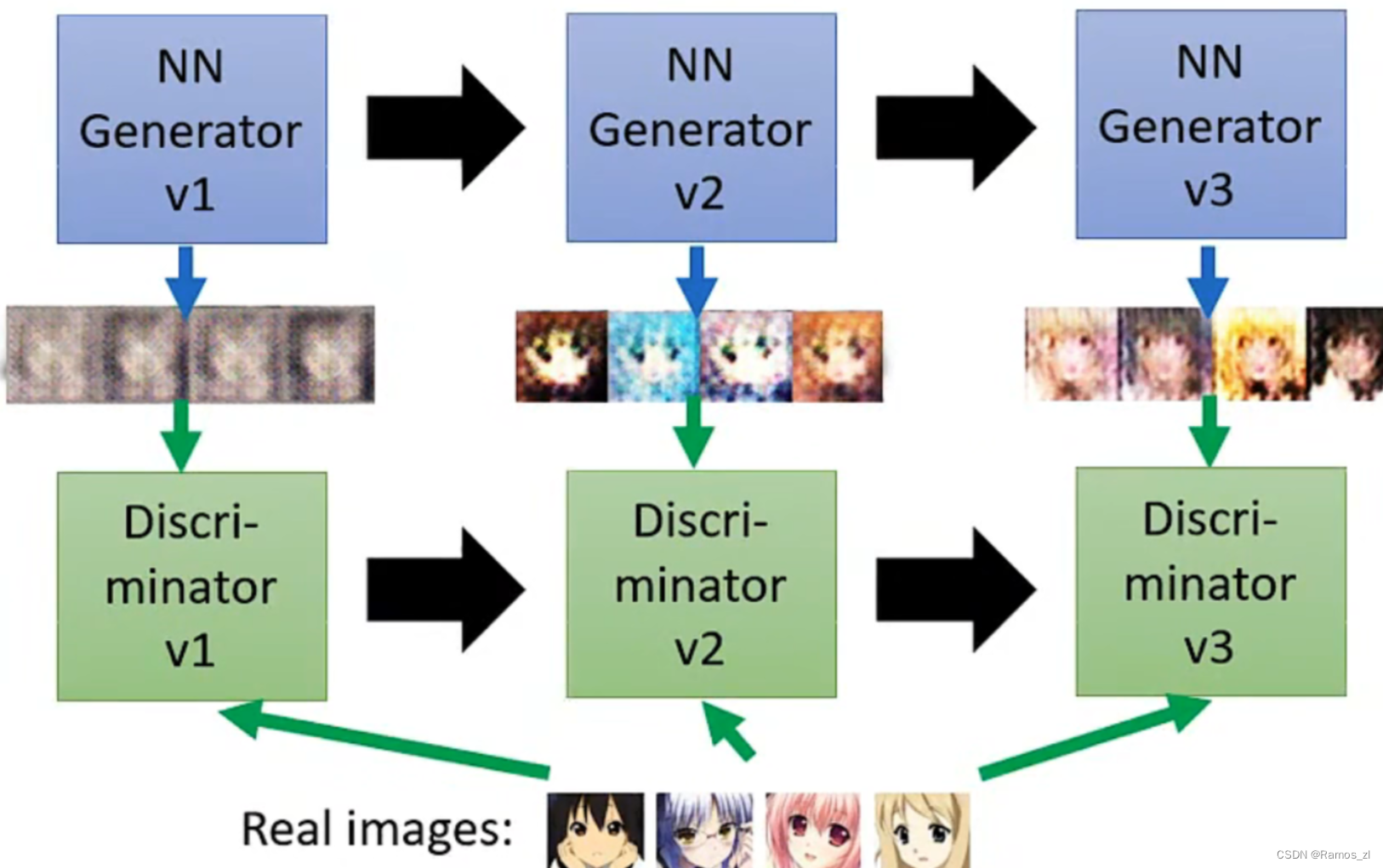
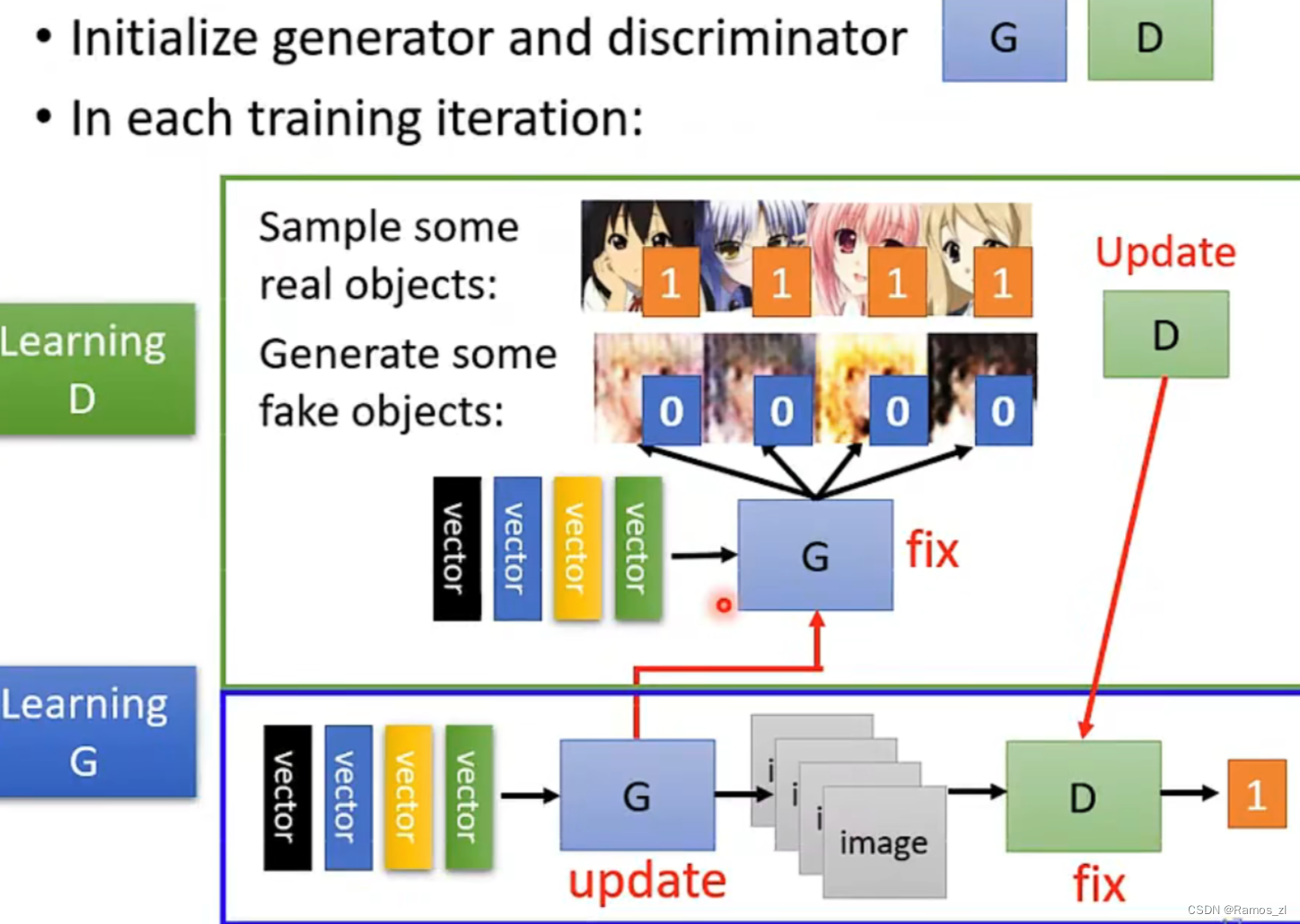
GAN主要包括了上述介绍的两个部分,即生成器Generator与判别器Discriminator。生成器主要用来学习真实图像分布从而让自身生成的图像更加真实,以骗过判别器;判别器则需要对接收的图片进行真假判别。在整个过程中,生成器努力地让生成的图像更加真实,而判别器则努力地去识别出图像的真假,这个过程相当于一个二人博弈,随着时间的推移,生成器和判别器在不断地进行对抗,最终两个网络达到了一个动态均衡:生成器生成的图像接近于真实图像分布,而判别器识别不出真假图像,对于给定图像的预测为真的概率基本接近 0.5(随机猜测类别)。
2.4 Algorithm of GAN
首先随机初始化的判别器和生成器,然后在每一个迭代中反复如下操作:1.固定生成器Generator的参数,去调节判别器Discriminator的参数。判别器要通过学习参数来给真实的目标打高分,给生成器生成的目标打低分。2.固定判别器Discriminator的参数,调节生成器Generator参数。不断优化它生成的images,使得判别器给它的分数提高。
三、相关代码
GAN实现手写数字识别数据集图像的生成:
import argparse
import os
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch
## 创建文件夹
os.makedirs("./images/gan/", exist_ok=True) ## 记录训练过程的图片效果
os.makedirs("./save/gan/", exist_ok=True) ## 训练完成时模型保存的位置
os.makedirs("./datasets/mnist", exist_ok=True) ## 下载数据集存放的位置
## 超参数配置
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=2, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=500, help="interval betwen image samples")
opt = parser.parse_args()
## opt = parser.parse_args(args=[]) ## 在colab中运行时,换为此行
print(opt)
## 图像的尺寸:(1, 28, 28), 和图像的像素面积:(784)
img_shape = (opt.channels, opt.img_size, opt.img_size)
img_area = np.prod(img_shape)
## 设置cuda:(cuda:0)
cuda = True if torch.cuda.is_available() else False
## mnist数据集下载
mnist = datasets.MNIST(
root='./datasets/', train=True, download=True, transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
)
## 配置数据到加载器
dataloader = DataLoader(
mnist,
batch_size=opt.batch_size,
shuffle=True,
)
## ##### 定义判别器 Discriminator ######
## 将图片28x28展开成784,然后通过多层感知器,中间经过斜率设置为0.2的LeakyReLU激活函数,
## 最后接sigmoid激活函数得到一个0到1之间的概率进行二分类
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(img_area, 512), ## 输入特征数为784,输出为512
nn.LeakyReLU(0.2, inplace=True), ## 进行非线性映射
nn.Linear(512, 256), ## 输入特征数为512,输出为256
nn.LeakyReLU(0.2, inplace=True), ## 进行非线性映射
nn.Linear(256, 1), ## 输入特征数为256,输出为1
nn.Sigmoid(), ## sigmoid是一个激活函数,二分类问题中可将实数映射到[0, 1],作为概率值, 多分类用softmax函数
)
def forward(self, img):
img_flat = img.view(img.size(0), -1) ## 鉴别器输入是一个被view展开的(784)的一维图像:(64, 784)
validity = self.model(img_flat) ## 通过鉴别器网络
return validity ## 鉴别器返回的是一个[0, 1]间的概率
## ###### 定义生成器 Generator #####
## 输入一个100维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维,
## 然后通过LeakyReLU激活函数,接着进行一个线性变换,再经过一个LeakyReLU激活函数,
## 然后经过线性变换将其变成784维,最后经过Tanh激活函数是希望生成的假的图片数据分布, 能够在-1~1之间。
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
## 模型中间块儿
def block(in_feat, out_feat, normalize=True): ## block(in, out )
layers = [nn.Linear(in_feat, out_feat)] ## 线性变换将输入映射到out维
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8)) ## 正则化
layers.append(nn.LeakyReLU(0.2, inplace=True)) ## 非线性激活函数
return layers
## prod():返回给定轴上的数组元素的乘积:1*28*28=784
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False), ## 线性变化将输入映射 100 to 128, 正则化, LeakyReLU
*block(128, 256), ## 线性变化将输入映射 128 to 256, 正则化, LeakyReLU
*block(256, 512), ## 线性变化将输入映射 256 to 512, 正则化, LeakyReLU
*block(512, 1024), ## 线性变化将输入映射 512 to 1024, 正则化, LeakyReLU
nn.Linear(1024, img_area), ## 线性变化将输入映射 1024 to 784
nn.Tanh() ## 将(784)的数据每一个都映射到[-1, 1]之间
)
## view():相当于numpy中的reshape,重新定义矩阵的形状:这里是reshape(64, 1, 28, 28)
def forward(self, z): ## 输入的是(64, 100)的噪声数据
imgs = self.model(z) ## 噪声数据通过生成器模型
imgs = imgs.view(imgs.size(0), *img_shape) ## reshape成(64, 1, 28, 28)
return imgs ## 输出为64张大小为(1, 28, 28)的图像
## 创建生成器,判别器对象
generator = Generator()
discriminator = Discriminator()
## 首先需要定义loss的度量方式 (二分类的交叉熵)
criterion = torch.nn.BCELoss()
## 其次定义 优化函数,优化函数的学习率为0.0003
## betas:用于计算梯度以及梯度平方的运行平均值的系数
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
## 如果有显卡,都在cuda模式中运行
if torch.cuda.is_available():
generator = generator.cuda()
discriminator = discriminator.cuda()
criterion = criterion.cuda()
## ----------
## Training
## ----------
## 进行多个epoch的训练
for epoch in range(opt.n_epochs): ## epoch:50
for i, (imgs, _) in enumerate(dataloader): ## imgs:(64, 1, 28, 28) _:label(64)
## =============================训练判别器==================
## view(): 相当于numpy中的reshape,重新定义矩阵的形状, 相当于reshape(128,784) 原来是(128, 1, 28, 28)
imgs = imgs.view(imgs.size(0), -1) ## 将图片展开为28*28=784 imgs:(64, 784)
real_img = Variable(imgs).cuda() ## 将tensor变成Variable放入计算图中,tensor变成variable之后才能进行反向传播求梯度
real_label = Variable(torch.ones(imgs.size(0), 1)).cuda() ## 定义真实的图片label为1
fake_label = Variable(torch.zeros(imgs.size(0), 1)).cuda() ## 定义假的图片的label为0
## ---------------------
## Train Discriminator
## 分为两部分:1、真的图像判别为真;2、假的图像判别为假
## ---------------------
## 计算真实图片的损失
real_out = discriminator(real_img) ## 将真实图片放入判别器中
loss_real_D = criterion(real_out, real_label) ## 得到真实图片的loss
real_scores = real_out ## 得到真实图片的判别值,输出的值越接近1越好
## 计算假的图片的损失
## detach(): 从当前计算图中分离下来避免梯度传到G,因为G不用更新
z = Variable(torch.randn(imgs.size(0), opt.latent_dim)).cuda() ## 随机生成一些噪声, 大小为(128, 100)
fake_img = generator(z).detach() ## 随机噪声放入生成网络中,生成一张假的图片。
fake_out = discriminator(fake_img) ## 判别器判断假的图片
loss_fake_D = criterion(fake_out, fake_label) ## 得到假的图片的loss
fake_scores = fake_out ## 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好
## 损失函数和优化
loss_D = loss_real_D + loss_fake_D ## 损失包括判真损失和判假损失
optimizer_D.zero_grad() ## 在反向传播之前,先将梯度归0
loss_D.backward() ## 将误差反向传播
optimizer_D.step() ## 更新参数
## -----------------
## Train Generator
## 原理:目的是希望生成的假的图片被判别器判断为真的图片,
## 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,
## 反向传播更新的参数是生成网络里面的参数,
## 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的, 这样就达到了对抗的目的
## -----------------
z = Variable(torch.randn(imgs.size(0), opt.latent_dim)).cuda() ## 得到随机噪声
fake_img = generator(z) ## 随机噪声输入到生成器中,得到一副假的图片
output = discriminator(fake_img) ## 经过判别器得到的结果
## 损失函数和优化
loss_G = criterion(output, real_label) ## 得到的假的图片与真实的图片的label的loss
optimizer_G.zero_grad() ## 梯度归0
loss_G.backward() ## 进行反向传播
optimizer_G.step() ## step()一般用在反向传播后面,用于更新生成网络的参数
## 打印训练过程中的日志
## item():取出单元素张量的元素值并返回该值,保持原元素类型不变
if (i + 1) % 100 == 0:
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [D real: %f] [D fake: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), loss_D.item(), loss_G.item(), real_scores.data.mean(),
fake_scores.data.mean())
)
## 保存训练过程中的图像
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(fake_img.data[:25], "./images/gan/%d.png" % batches_done, nrow=5, normalize=True)
## 保存模型
torch.save(generator.state_dict(), './save/gan/generator.pth')
torch.save(discriminator.state_dict(), './save/gan/discriminator.pth')
运行结果:
迭代46500次:

总结
GAN是一种强大而多才多艺的生成模型,具有许多令人振奋的应用前景。在深入学习和实践的过程中,我积累了一些经验,并希望能够在未来的项目中更加熟练地运用GAN技术。














 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









