







节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
一、背景
最近两年图像生成领域受到广泛关注,尤其是 Stable Diffusion 模型的开源,以及 DALL-E 系列模型的不断迭代更是将这一领域带到了新的高度。
为了更好地理解 Stable Diffusion 以及 DALL-E 3 等最新的图像生成模型,我们决定从头开始,以了解这些模型的演化过程。需要说明的是,本文中并不包含 Stable Diffusion、DALL-E 3 模型介绍,而是回到了它们更早的模型,作为后续的铺垫。Stable Diffusion 的作者其实也是 VQ-GAN 的作者。DALL-E 3 是 OpenAI 的工作,在此之前还有 DALL-E 和 DALL-E 2。
二、摘要(Abstract)
本文中我们从 AE(AutoEncoder)模型出发,逐步介绍了 VAE(Variational Autoencoder),VQ-VAE(Vector Quantised VAE)、VQ-VAE-2 以及 VQ-GAN 等工作。然而这些工作往往用于无条件生成,或者有条件的类别、图像等,其往往不支持文本输入,或者相关能力很弱。从 21 年初 DALL-E 的发布,文生图的模型开始大量出现。基于此,我们也进一步介绍了 DALL-E、DALL-E mini 和 CLIP-VQ-GAN 等模型。
由于篇幅的原因,本文中不包含大量的数学推导,只会梳理这些模型是怎么工作的。此外,我们也会提供一些代码示例,以便更好地理解。如下图所示为我们梳理的这些模型演进的脉络,本文的介绍也会自下而上进行(括号内为相关工作发布日期):

三、AutoEncoder(AE)
AutoEncoder 可以称作自编码器,是一种人工神经网络,可以用于学习无标签数据的有效编码,属于无监督学习。AutoEcoder 的目的是:学习对高维度数据进行低维度表示(Representation),也就是压缩,因此常用于降维。
AutoEncoder 由两个主要的部分组成:
-
Encoder(编码器):用于对输入进行编码(压缩)
-
Decoder(解码器):用于使用编码重构输入(解压缩)
如下图所示为一个 AutoEncoder 的典型示例,其中输入为一幅图像 x,经 Encoder 编码生成一个隐空间(Latent Space)的表征(Representation)z,然后 Decoder 可以使用这个表征 z 重构出输入 x(核心思想是:既然可以重建 x,那么表明表征 z 中已经充分包含 x 的潜在信息,不然无法恢复,这也就表明学习到了一个很好的 Encoder,可以用于生产输入图像的表征 z)。

训练该模型的目标就是让输入和输出的误差尽量小,如下所示,其中 e 表示 Encoder,d 表示 Decoder:

该模型的目的是获得最佳的重建效果。模型在 Latent Space 没有增加任何的约束或者正则化,这也就意味着我们并不知道 Latent Space 是如何构建的,这也就是为什么我们很难使用 Latent Space 来采样生成一个新的图像(也就是只能重建已经有隐空间表征的图像)。
四、Variational Autoencoder(VAE)
4.1. VAE 概述
VAE (也称变分自编码器)主要是在 AE 的基础上引入了概率生成模型的概念,通过在隐空间引入概率分布,使模型能够生成多样性的样本,并且在学习过程中可以更好地理解数据的分布。
对应的论文为:[1312.6114] Auto-Encoding Variational Bayes。
4.2. VAE 模型结构
VAE 的模型结构如下图所示:
-
Encode:输入图像经过 Encoder 生成一个中间表示,然后分别经过 Mean Layer(Linear 层) 和 Var Layer(Linear 层)来生成均值 m=(m0, m1, m2, m3) 和方差 v=(v0, v1, v2, v3)
-
Sampling:使用噪声 e=(e0, e1, e2, e3) 与 v 和 m 即可获得一个采样 c=(c0, c1, c2, c3)
-
Decode:使用采样 c 经过一个 UP Layer(Linear)来生成新的中间表示,然后经过 Decoder 来生成最终的结果。

4.3. AE 和 VAE 主要区别
AE 和 VAE 的结构非常类似,比如都包含 Encoder 和 Decoder,都是在 Encoder 输入图像,Decoder 输出图像。同时也有很大的区别,比如:
- 应用场景:
-
AE:主要用于降维(压缩)、特征学习和数据去噪等
-
VAE:除了上述应用外,还广泛应用于生成新的、与训练数据相似但不完全相同的样本
- 基本结构:
-
AE:Encoder 将输入映射到隐空间(latent space),Decoder 直接使用隐空间生成输出数据。但隐空间是未知的,只能从一个给定的输入生成
-
VAE:在隐空间上引入概率分布,通常是高斯分布
- 隐空间的学习:
-
AE:隐空间是一个确定性的表示,每一个都代表一个编码后的点
-
VAE:隐空间是一个概率分布,通常是高斯分布,使得我们可以在隐空间进行随机采样,从而生成具有变化的新样本
- 训练目标:
-
AE:通过最小化输入和输出之间的差异(重构误差)来训练
-
VAE:除了最小化重构误差外,还包括最小化隐空间的 KL 散度,以确保学到的隐空间与标准正态分布接近
如下图所示为一个 Latent Space 投影的示例,可以看出,AE 明显会聚焦于部分局部区域,而 VAE 分布更加广泛:

4.4. 示例
如下图所示为一个 AE 的示例,Encode 过程将输入映射到隐空间的一个点,而不同的点与点之间是没有规律可循的,可能是任何的内容,也就无法基于此来令 Decode 生成预期的输出:

如下图所示为 VAE 的示例,模型在隐空间是一个高斯分布,因此在圆月和残月交叉的部分就包含了圆月信息(蓝框),也包含残月信息(绿框),因此其通过 Decode 后生成了半月图片(红框):

4.5. 代码实现
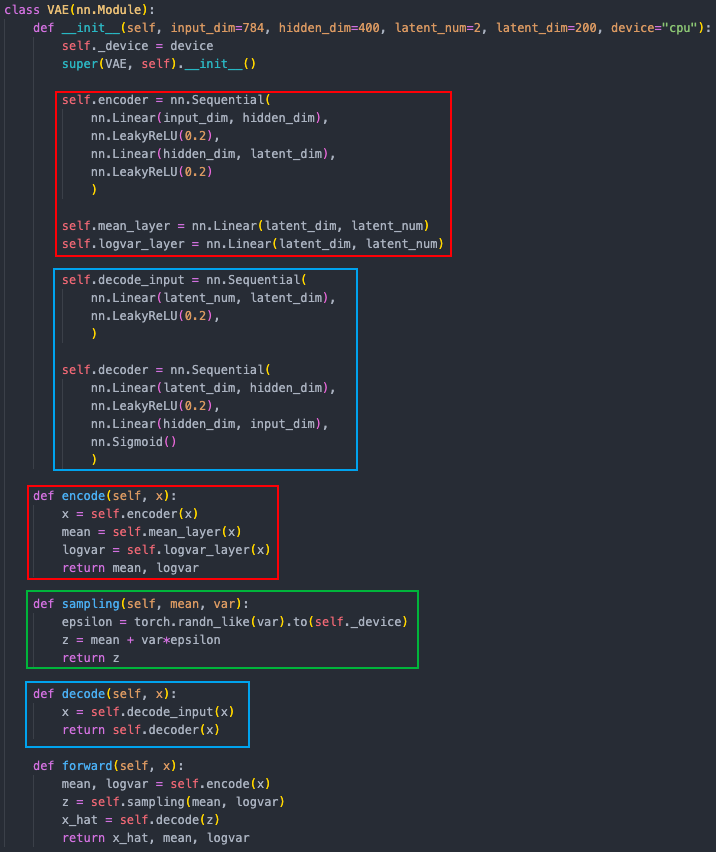
如下图是 VAE 的模型示例(用于 MNIST 训练),其结构很简单,Encoder 和 Decoder 都是由两层 Linear 组成,sampling 也很简单:
训练代码也很简单,主要是 loss 函数中除了重建损失(reproduction_loss)外,也增加了一个 KL 散度损失:
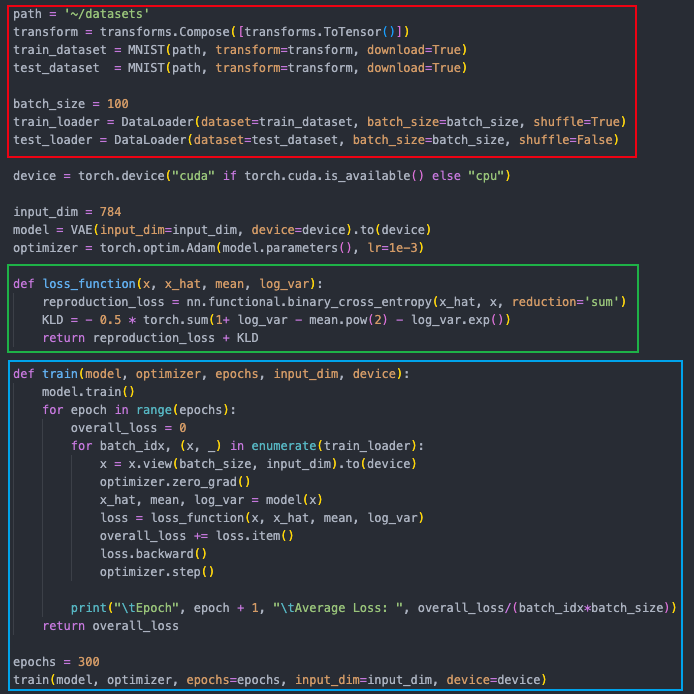
如下图所示为一个简单的生成示例,随便指定一个 mean、var 即可使用 decode 来生成一个图像:

如下图为使用 mean=[-1.0, 1.0],var=[-1.0, 1.0] 生成的结果,可以看出,数字 0-9 分布在不同的区域,并且在区域交叉的地方会存在四不像的结果(其同时包含了周围不同数字的信息):

五、 Vector Quantised VAE(VQ-VAE)
5.1. VQ-VAE 概述
VQ-VAE 主要是在 VAE 的基础上引入了离散的、可量化的隐空间表示,有助于模型更好地理解数据中的离散结构和语义信息,同时可以避免过拟合。
对应的论文为:[1711.00937] Neural Discrete Representation Learning
5.2. VQ(Vector Quantization)
VQ 是一种数据压缩和量化的技术,它可以将连续的向量映射到一组离散的具有代表性的向量中。在深度学习领域,VQ 通常用于将连续的隐空间表示映射到一个有限的、离散的 codebook 中。
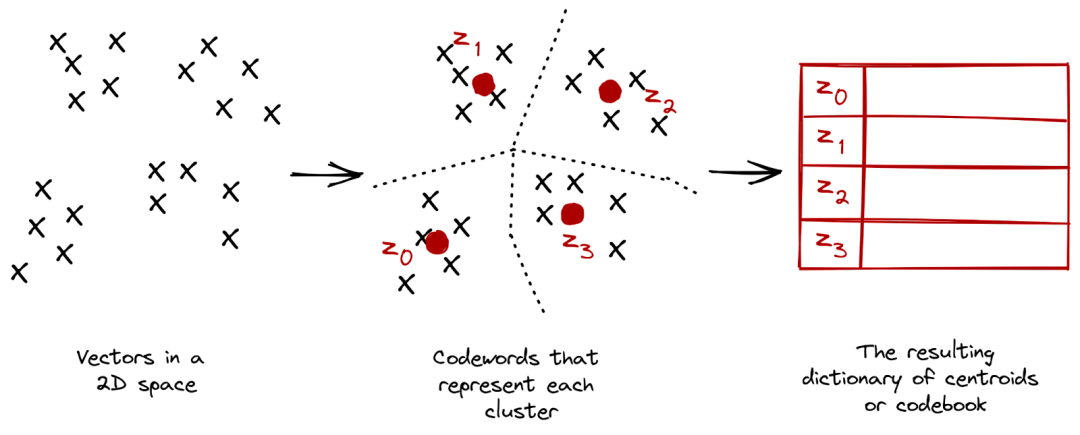
我们常见的 K-means 聚类算法就是 VQ 的一种,K-means 聚类的目标为:把 n 个点(样本)划分到 k 个聚类中(通常 k 远小于 n),使得每个点都属于离它最近的聚类中心对应的类别,以此实现聚类的目的。如下图所示,所有点都被映射到 z0,z1,z2 和 z3 中:
5.3. VQ-VAE 模型结构
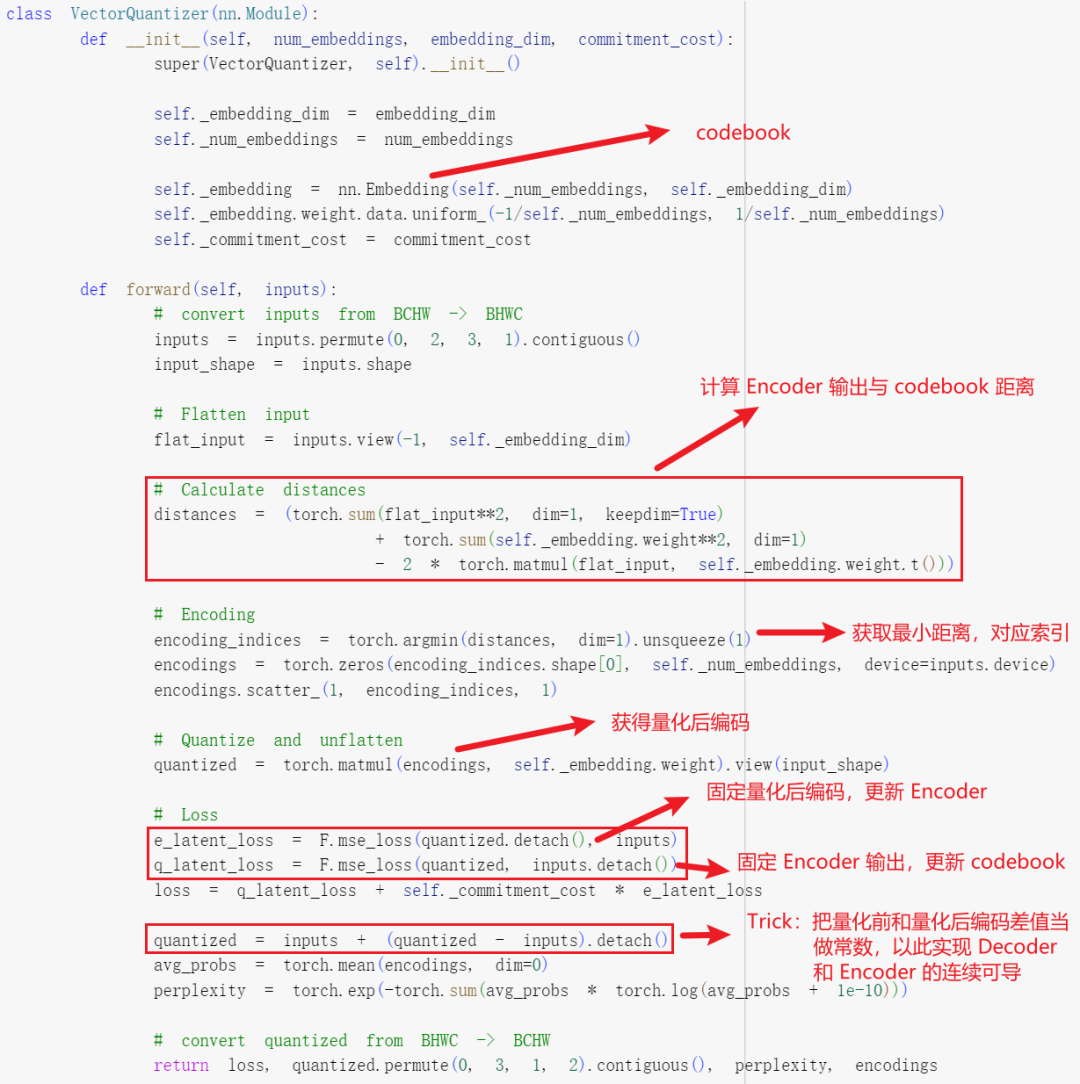
VQ-VAE 与 VAE 的结构非常相似,只是中间部分不是学习概率分布,而是换成 VQ 来学习 Codebook。
-
Encoder:将输入压缩成一个中间表示
-
VQ:
-
使用每一个中间表示与 Codebook 计算距离
-
计算与 Codebook 中距离最小的向量的索引(Argmin)
-
根据索引从 Codebook 中查表,获得最终量化后的表示
- Decoder:将量化后的表示输入 Decoder 生成最终的输出

5.4. VQ-VAE 训练
在 VQ 中使用 Argmin 来获取最小的距离,这一步是不可导的,因此也就无法将 Decoder 和 Encoder 联合训练,针对这个问题,作者添加了一个 Trick,如下图红线部分,直接将量化后表示的梯度拷贝到量化前的表示,以使其连续可导:

具体的代码实现如下所示:
https://colab.research.google.com/github/zalandoresearch/pytorch-vq-vae/blob/master/vq-vae.ipynb
5.5. VQ-VAE + PixelCNN
有了上述的 VQ-VAE 模型,可以很容易实现图像压缩、重建的目的,但是无法生成新的图像数据。当然可以随机生成 Index,然后对应生成量化后的 latent code,进而使用 Decoder 来生成输出图像。但是这样的 latent code 完全没有全局信息甚至局部信息,因为每个位置都是随机生成的。因此,作者引入了 PixelCNN 来自回归的生成考虑了全局信息的 latent code,进而可以生成更真实的图像,如下图所示:

PixelCNN 和 VQ-VAE 的一作是同一个人,来自 Google DeepMind,对应的论文为:[1606.05328] Conditional Image Generation with PixelCNN Decoders。此处我们不再对 PixelCNN 展开,只需要知道它是一个自回归生成模型,可以逐个像素的生成,因为其是自回归模型,所以每个位置都能看到之前位置的信息,这样生成的 latent code 能够更全面的考虑到空间信息,有助于提高模型生成图像的质量和多样性。
那么为什么不直接使用 PixelCNN 来生成图像呢,答案是肯定的,不过将 PixelCNN 和 VQ-VAE结合可以发挥各自的优势,比如提高训练效率和收敛性,对于 128x128x3 的图像,假设离散空间的大小为 32x32,那么 PixelCNN 不用生成 128x128x3 个像素(RGB),而只用生成 32x32 的离散 latent code 即可。
此外,有了 PixelCNN 也就可以更好地支持无条件生成和有条件生成:
-
无条件生成:模型在生成时不考虑任何外部条件,通常是输入一个随机噪声。比如可以在 PixelCNN 的起始输入给定一个随机像素(随机离散 latent code index),然后迭代逐个像素生成。
-
有条件生成:模型在生成时考虑外部条件。这个条件可以是类别标签、图像的一部分,或者任何与图像生成相关的信息。比如使用类别标签作为外部条件,可以将类别标签表示为一个 one-hot 的 embedding,然后作为条件输入 PixelCNN,如果是输入一个图像,也可以将图像编码为 embedding 之后输入。
那么怎么保证生成结果的多样性呢?有两种方式,一种是随机噪声,另一种就是在自回归生成过程中引入 top_p 和 top_k 采样等。
六、 Vector Quantised VAE-2(VQ-VAE-2)
6.1. VQ-VAE-2 概述
VQ-VAE-2 相比 VQ-VAE 主要的变化是增加了多尺度分层结构,以进一步增强 latent code 上的先验信息,以此来生成更高分辨率,更高质量的图像。
VQ-VAE-2 依旧是 Google DeepMind 的工作,作者基本都是 PixelCNN 和 VQ-VAE 的作者,对应的论文为:[1906.00446] Generating Diverse High-Fidelity Images with VQ-VAE-2
6.2. VQ-VAE-2 模型结构
VQ-VAE-2 的模型结构如下图所示,以 256x256 的图像压缩重建为例:
-
训练阶段:其首先使用 Encoder 将图像压缩到 Bottom Level,对应大小为 64x64,然后进一步使用 Encoder 压缩到 Top Level,大小为 32x32。重建时,首先将 32x32 的表征经过 VQ 量化为 latent code,然后经过 Decoder 重建 64x64 的压缩图像,再经过 VQ 和 Decoder 重建 256x256 的图像。
-
推理阶段(图像生成):使用 PixelCNN 首先生成 Top Level 的离散 latent code,然后作为条件输入 PixelCNN 以生成 Bottom Level 的更高分辨率的离散 latent code。之后使用两个 Level 的离散 latent code 生成最终的图像。

当然,基于这个思想作者也进一步验证了使用 3 个 Level 来生成 1024x1024 分辨率的图像,相应的压缩分辨率分别为 128x128、64x64、32x32。
七、 Vector Quantised GAN(VQ-GAN)
7.1. VQ-GAN 概述
VQ-GAN 相比 VQ-VAE 的主要改变有以下几点:
-
引入 GAN 的思想,将 VQ-VAE 当做生成器(Generator),并加入判别器(Discriminator),以对生成图像的质量进行判断、监督,以及加入感知重建损失(不只是约束像素的差异,还约束 feature map 的差异),以此来重建更具有保真度的图片,也就学习了更丰富的 codebook。
-
将 PixelCNN 替换为性能更强大的自回归 GPT2 模型(针对不同的任务可以选择不同的规格)。
-
引入滑动窗口自注意力机制,以降低计算负载,生成更大分辨率的图像。
VQ-GAN 的作者也是著名的 Stable Diffusion 的作者,对应的论文为:[2012.09841] Taming Transformers for High-Resolution Image Synthesis。对应的代码库为:Taming Transformers for High-Resolution Image Synthesis。
需要说明的是,VQ-GAN 的 v1 版本发表在 20 年 12 月,而 OpenAI 的 DALL-E 发表在 21 年 2 月,正好对应 VQ-GAN 的 v2 版本,因此 VQ-GAN 的前两个版本并没有与 DALL-E 对比,直到 21 年 6 月的 v3 版本才添加了和 DALL-E 的对比结果(可能也是这个原因,VQ-GAN 也并没有支持文本到图像的生成能力):

7.2. VQ-GAN 模型结构
7.2.1. VQ-GAN 模型概览
VQ-GAN 的整个模型结构如下图所示,整体看着比较复杂,实际训练时是分为两阶段训练的,先训练下面的 VQ-GAN 部分,再训练上面的 Transformer 部分:

7.2.2. VQ-GAN 训练
如下图所示为第一阶段训练,相比 VQ-VAE 主要是增加了 Discriminator,以及将重建损失替换为 LPIPS 损失:
-
Discriminator:对生成的图像块进行判别,每一块都会返回 True 和 False,然后将对应的损失加入整体损失中。
-
LPIPS:除了像素级误差外,也会使用 VGG 提取 input 图像和 reconstruction 图像的多尺度 feature map,以监督对应的误差(具体可参考 lpips.py - CompVis/taming-transformers · GitHub)。

7.2.3. Transformer 训练
如下图所示为第二阶段训练,此时会将 Encoder、Decoder、Discriminator 和 Codebook 固定,只训练 Transformer。
-
待训练图像经过 Encoder 和 VQ 后编码成离散的 latent code。
-
使用离散的 latent code 作为 Transformer 的输入和 target 来进行自回归的监督训练。也就是使用 S<i 来预测 Si 对应的 code。(当然,也可以加入可选的条件约束,比如类别信息)

7.3. 高分辨率生成
离散 latent code 相比原始图像的压缩率通常是 16x16 或 8x8,以 16x16 为例,要生产一个 1024x1024 分辨率的图片,对应的离散 latent code 为 64x64,而 GPT 模型推理中计算量与序列长度成二次方关系,也就是 O(644*K),其代价很高。因此作者提出了使用滑动窗口 Attention 机制来降低计算量的方案,具体来说,预测每一个位置的 code 时只考虑局部 code,而不是全局 code,比如使用 16x16 的窗口,计算量将降低到 O(642*162*K),几乎降低为原来的 1/16。当然,对于边界的区域,并不是使用当前位置作为中心,而是将窗口相应地向图像中心偏移,保证窗口大小:

7.4. 高分辨率生成示例
该示例对应的代码为:taming-transformers/scripts/taming-transformers.ipynb at master · CompVis/taming-transformers · GitHub。主要是输入一个分割掩码,然后将其作为条件生成高分辨率图像,Encoder 对应的压缩率为 16x16,滑动窗口大小也是 16x16。需要说明的是:当条件包含空间信息,比如分割图,深度图,或其他图像时,需要额外训练一个 VQ-GAN 用于对条件图像进行编码。
7.4.1. 读取分割掩码

掩码可视化如下图所示:

7.4.2. 生成分割条件对应的离散 latent code
如下图所示,encode_to_c 对应的是额外训练的 Encoder(https://github.com/CompVis/taming-transformers/blob/master/taming/models/cond_transformer.py#L168-L182):

7.4.3. 初始化待生成图像的离散 latent code

使用随机生成的离散 latent code 经 Decoder 生成的图像如下图所示,可以看出其更像是一些噪声:

7.4.4. 生成离散 latent code
如下图为具体的逐个生成离散 latent code 的过程,因为有 42x64 个 code,因此要迭代 42x64 次:

7.4.5. 生成结果
如下图所示为最终的生成结果,可以看出与输入的分割 mask 很匹配:

在上一部分生成离散 latent code 的过程中,需要将条件和待生成 patch concat 到一起,生成一个 1x512 的序列,但实际输入 Transformer 模型的是前 511 个 Token,这是因为 GPT 是自回归模型,在训练时第 255 个位置(从 0 开始)预测的是第 256 个 Token(也就是第一个图像 Token),第 510 个 Token 预测的是第 511 个 Token,而 511 位置生成的 Token 并没有被监督训练。因此预测生成的 Token 对应的 index 为 [255, 510],此时再根据 local_i 和 local_j 就可以正确获取当前位置对应的 code。在官方代码库 Issue 也有人问起这个问题,不过还未被回答:

如下图所示,如果输入 1x512 个 Token,然后根据 index [256, 511] 来获取生成 Token,并根据 local_i 和 local_j 来获取 code(实际位置已经出现偏差),最终生成的图像质量非常差:

八、 DALL-E(dVAE、DALL-E)
8.1. DALL-E 概述
DALL-E 是 OpenAI 的工作,其最主要的贡献是提供不错的文本引导图片生成的能力,其不是在 VQ-VAE 基础上修改,而是首先引入 VAE 的变种 dVAE,然后在此基础上进一步训练 DALL-E。可惜的是,OpenAI 并不 Open,只开源了 dVAE 部分模型,文本引导生成部分并没有开源,不过 Huggingface 和 Google Cloud 团队进行了复现,并发布对应的 DALL-E mini 模型。
DALL-E 对应的论文为:[2102.12092] Zero-Shot Text-to-Image Generation。对应的代码库为:GitHub - openai/DALL-E: PyTorch package for the discrete VAE used for DALL·E.。
DALL-E mini 对应的文档为:DALL-E Mini Explained,对应的代码库为:GitHub - borisdayma/dalle-mini: DALL·E Mini - Generate images from a text prompt。
8.2. dVAE
8.2.1. 模型概述
与 VQ-GAN 类似,DALL-E 的训练也是分为两个阶段,第一阶段是训练 VAE,不过并没有使用 VQ-VAE,而是使用 Discrete VAE(dVAE),整体来说与 VQ-VAE 类似,主要的区别是引入 Gumbel Softmax 来训练,避免 VQ-VAE 训练中 ArgMin 不可导的问题。

8.2.2. Gumbel Softmax
Gumbel Softmax 是一种将离散采样问题转化为可微分操作的技术,常用于深度学习中的生成模型,特别是 VAE 和 GAN 等模型中。Gumbel Softmax 使用 Gumbel 分布来近似离散分布的采样过程。具体来说,它首先使用 Gumbel 分布生成一组噪声样本,然后通过 Softmax 函数将这些样本映射到一个类别分布。这个过程是可微分的,因此可以在反向传播中进行梯度计算。
如下图所示,一个图像经 Encoder 编码会生成 32x32 个 embedding,和 codebook (8192 个)内积再经 Softmax 即可得到在每个 codebook 向量的概率:

应用 Gumbel Softmax 采样即可获得新的概率分布,然后将其作为权重,对相应的 codebook 向量进行累积就可以获得 latent vector。然后 Decoder 可以基于此 latent vector 重构输出图像。

在上述的过程中,通过添加 Gumbel 噪声的方式进行离散采样,可以近似为选择 logits 中概率最大的类别,从而提供一种可微分的方式来处理离散采样问题。具体来说,其关键为 Gumbel-Max Trick,其中 gi 是从 Gumbel(0, 1) 分布中采样得到的噪声,τ 是温度系数。需要说明的是,t 越小,此处的 Softmax 就会越逼近于 ArgMax。τ 越大,就越接近于均匀分布。这也就引入了训练的一个 Trick:训练起始的温度系数 τ 很高,在训练的过程中,逐渐降低 τ,以便其逐渐逼近 ArgMax。在推理阶段就不再需要 Gumbel Softmax,直接使用 ArgMax 即可。
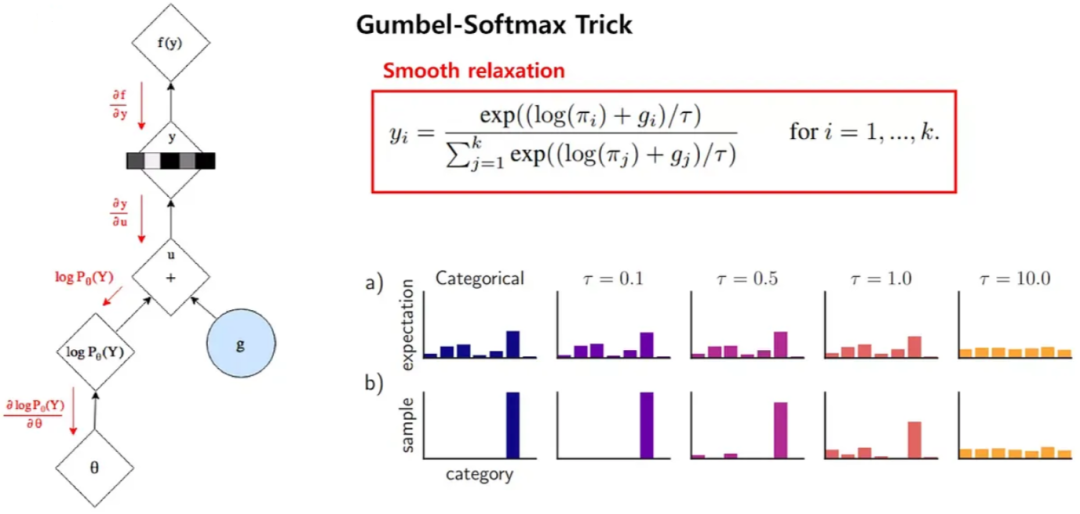
如下图 DALL-E 的示例中正是直接使用的 ArgMax:

8.3. Transformer
8.3.1. 模型结构
对于 Transformer 模型,作者使用 12B 参数量的 Sparse Transformer(64 层,每层 62 个注意力头,每个头的 hidden size 为 64),对于文本,使用 BPE-encode 编码为 Token,限制了最大 256 个 Token,词表大小为 16,384。图像词表也就对应 codebook,大小为 8192。图像 Token 直接使用 dVAE 的 Encoder + ArgMax 采样获得,未添加 Gumbel 噪声。(需要说明的是,此部分训练、推理代码都没有开源)
作者将文本输入固定为 256 个 Token,因此当文本 Token 不足 256 个时会进行 Padding,如下图所示,同时也会给 Image Token 添加行索引 embedding 和列索引 embedding。还会有一个特殊的 Token 来标识无文本输入的情况。此外,因为输入中既包含文本 Token,又包含图像 Token,而学习的主要目标是生成图像 Token,因此训练中文本相关的交叉熵损失权重为 1/8,而图像相关的交叉熵损失权重为 7/8。
针对 Transformer 模型,作者用了 3 种 Attention Mask(所有图像 Token 都能看到所有文本
Token,但只能看到部分图像 Token):
-
Row Attention:对于 (i-2)%4 != 0 的层使用,比如第 2 层,第 6 层。其中 i = [1, 63]
-
Column Attention:对于 (i-2)%4 = 0 的层使用,比如第 1 层,第 3 层。
-
Convolutional Attention:只在最后一层使用。

8.3.2. 模型训练
有了 dVAE 模型之后,第二阶段就是就是训练 Transformer(此阶段会固定 dVAE),使其具备文本引导生成的能力。DALL-E 使用大规模的图像-文本对数据集进行训练,训练过程中使用 dVAE 的 Encoder 将图像编码为离散的 latent code。然后将文本输入 Transformer,并使用生成的 latent code 来作为 target 输出。以此就可以完成有监督的自回归训练。推理时只需输入文本,然后逐个生成图像对应的 Token,直到生成 1024 个,然后将其作为离散的 latent code 进一步生成最终图像。
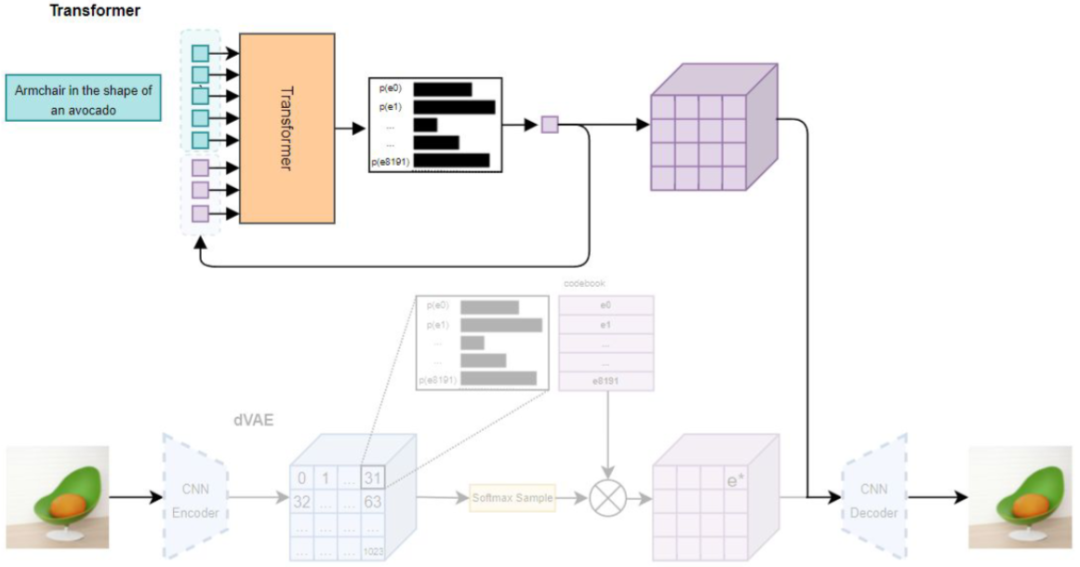
最终作者在 1024 个 16G 的 V100 GPU 上完成训练,batch size 为 1024,总共更新了 430,000 次模型,也就相当于训练了 4.3 亿图像-文本对(训练集包含 250M 图像-文本对,主要是 Conceptual Captions 和 YFFCC100M)。
九、 DALL-E mini
9.1. DALL-E mini 模型概述
如下图所示,DALL-E mini 中作者使用 VQ-GAN 替代 dVAE,使用 Encoder + Decoder 的 BART 替代 DALL-E 中 Decoder only 的 Transformer。

9.2. DALL-E mini 模型推理
在推理过程中,不是生成单一的图像,而是会经过采样机制生成多个 latent code,并使用 VQ-GAN 的 Decoder 生成多个候选图像,之后再使用 CLIP 提取这些图像的 embedding 和文本 embedding,之后进行比对排序,挑选出最匹配的生成结果。

9.2. DALL-E mini 和 DALL-E 对比
DALL-E mini 和 DALL-E 在模型、训练上都有比较大的差异,具体体现在:
-
DALL-E 使用 12B 的 GPT-3 作为 Transformer,而 mini 使用的是 0.4B 的 BART,小 27 倍。
-
mini 中使用预训练的 VQ-GAN、BART 的 Encoder 以及 CLIP,而 DALL-E 从头开始训练,mini 训练代价更小。
-
DALL-E 使用 1024 个图像 Token,词表更小为 8192,而 mini 使用 256 个图像 Token,词表大小为 16384。
-
DALL-E 支持最多 256 个文本 Token,对应词表为 16,384,mini 支持最多 1024 文本 Token,词表大小为 50,264。
-
mini 使用的 BART 是 Encoder + Decoder 的,因此文本是使用双向编码,也就是每个文本 Token 都能看到所有文本 Token,而 DALL-E 是 Decoder only 的 GPT-3,文本 Token 只能看到之前的 Token。
-
DALL-E 使用 250M 图像-文本对训练,而 mini 只使用了 15M。
十、 CLIP + VQ-GAN(VQGAN-CLIP)
10.1. VQGAN-CLIP 概述
VQ-GAN 几乎和 DALL-E 在同期发布,但不具备文本引导生成的能力,而这是 DALL-E 受到广泛关注的一个主要原因,也是生成图像中一种非常自然的方式。Katherine 等人将 VQ-GAN 和 OpenAI 发布的 CLIP 模型结合起来,利用 CLIP 的图文对齐能力来赋予 VQ-GAN 文本引导生成的能力。其最大的优势是不需要额外的预训练,也不需要对 CLIP 和 VQ-GAN 进行微调,只需在推理阶段执行少量的迭代即可实现。
作者首先是将其作为开源代码发布的,后续才提交了论文。对应的代码为:https://colab.research.google.com/drive/1_4Jl0a7WIJeqy5LTjPJfZOwMZopG5C-W?usp=sharing#scrollTo=g7EDme5RYCrt。对应的论文为:[2204.08583] VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance。
10.2. CLIP 模型
CLIP 是 OpenAI 发布的在大规模图文数据对(4亿)上通过对比学习进行预训练的图文对齐模型。如下图左侧是其对比预训练过程,在一个 batch 中对应的图文特征作为正对,图片特征和其他文本特征作为负对。如下图右侧,可广泛用于 zero-shot 的图像分类等任务,在 LMM(大规模多模态模型)中也常作为 image encoder 使用。

10.3. VQGAN-CLIP 方案
如下图 Figure 1 所示,作者的思路很简单:使用初始图像通过 VQ-GAN 生成一个图像,然后使用 CLIP 对生成图像和 Target Text 提取 embedding,然后计算相似性,并将其误差作为反馈对隐空间的 Z-vector 进行迭代更新,直到生成图像和 Target Text 对应的 embedding 很相似为止。
当然,在实际应用中会存在一些挑战,作者也提供了相应的解决方案:
-
Random Crops + Augmentation:如果在单个图像上计算,则 CLIP 损失的梯度更新噪声比较大。为了克服这个问题,作者对生成的图像进行多次修改,从而产生大量增强的图像。涉及随机裁剪、翻转、色彩抖动、噪声等。图像的高级语义特征往往对这些变化并不敏感(随机裁剪有可能影响语义内容,不过作者测试发现影响不大),因此平均所有增强图像的 CLIP 损失可以减小每个更新步骤的方差。
-
Latent Vector 正则化:当使用无约束 VQ-GAN 图像生成时,输出往往是非结构化的,添加增强有助于实现整体的一致性,但最终输出通常仍包含不需要的纹理块。为了解决这个问题,作者将 L2 正则化应用于 Z-vector,并赋予相应权重。


VQGAN-CLIP 无需训练,但其迭代更新的方式同样导致其生成效率相对比较低,如下图 Table 2 所示为作者的对比结果:

十一、参考链接(Reference)
-
https://arxiv.org/abs/1312.6114
-
https://arxiv.org/abs/1711.00937
-
https://arxiv.org/abs/1606.05328
-
https://arxiv.org/abs/1906.00446
-
https://arxiv.org/abs/2012.09841
-
https://github.com/CompVis/taming-transformers
-
https://arxiv.org/abs/2102.12092
-
https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mini-Explained–Vmlldzo4NjIxODA
-
https://github.com/borisdayma/dalle-mini
-
https://arxiv.org/abs/2204.08583
-
https://python.plainenglish.io/variational-autoencoder-1eb543f5f055
-
https://ljvmiranda921.github.io/notebook/2021/08/08/clip-vqgan/


















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









