






目录
摘要
传统的CNN只能考虑感受野范围的信息,即只能考虑局部范围而没有考虑全局信息,此时如果使用很大的kernel size一次覆盖掉所有的输入,这种情况下的模型的参数量就会非常多,容易overfitting。除此之外,机器翻译的输入是长度不一的。本周学习self-attention,self-attention是一种可以考虑全局信息以及不同输入向量之间关系的机制,在训练时可以充分发挥这些关系,优化训练的结果,同时self-attention在很多领域都能得以运用。
Abstract
Traditional CNN can only consider the information of the Receptive field range, that is, it can only consider the local range without considering the global information. In this case, if a large kernel size is used to cover all inputs at once, the model parameters in this case will be very large, which is easy to overfitting. In addition, the input of Machine translation varies in length. This week, we will learn about self-attention, which is a mechanism that can consider global information and the relationships between different inputs. During training, we can fully utilize these relationships and optimize the training results. At the same time, self-attention can be applied in many fields.
1 Self-attention
学习到目前为止,神经网络的输入都可以看作一个向量,当遇到更加复杂的问题时,输入是一个向量集且向量的长度不一,什么情况下输入的长度会不一呢?
1.1 Sophisticated Input
第一个例子:文字处理
当输入是一句英语,每个单词对应一个向量,而每个单词长度不一,就说明向量的长度不一,那么当输入的多个向量是长短不一,怎么将他们表示成向量?
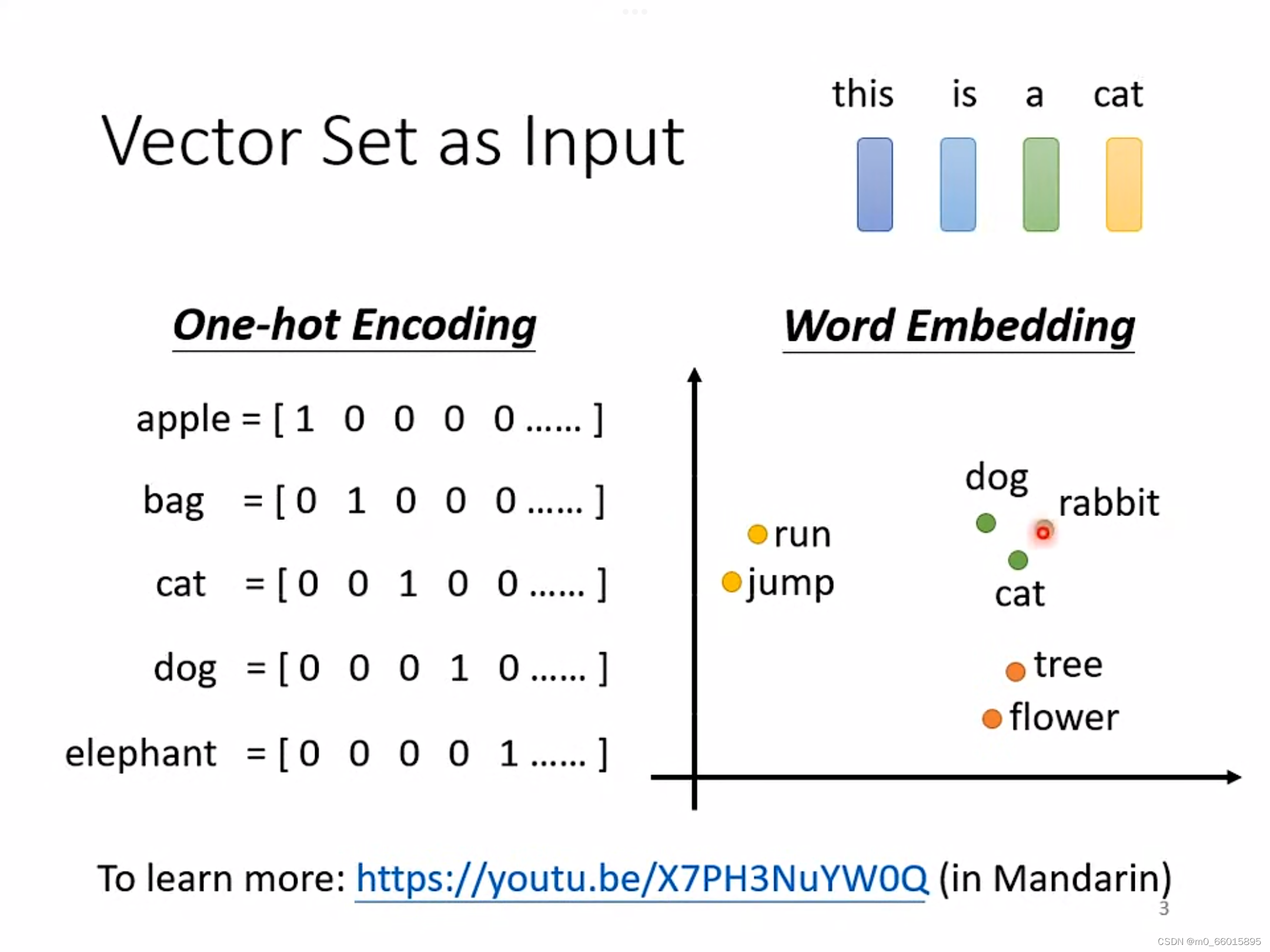
第一种方法:One-hot Encoding
假如有十万个词汇,就开一个十万维的向量,每一个维度对应到一个词汇,但存在一个问题,就是看不到词汇之间的任何关系,得不到任何信息。
第二种方法:Word Embedding
给每个词汇一个向量,相关的词汇会聚集在一个区域,关于这个方法的学习链接如图下方。
共同点:一个词对应一个向量,那么一句话对应一个向量集
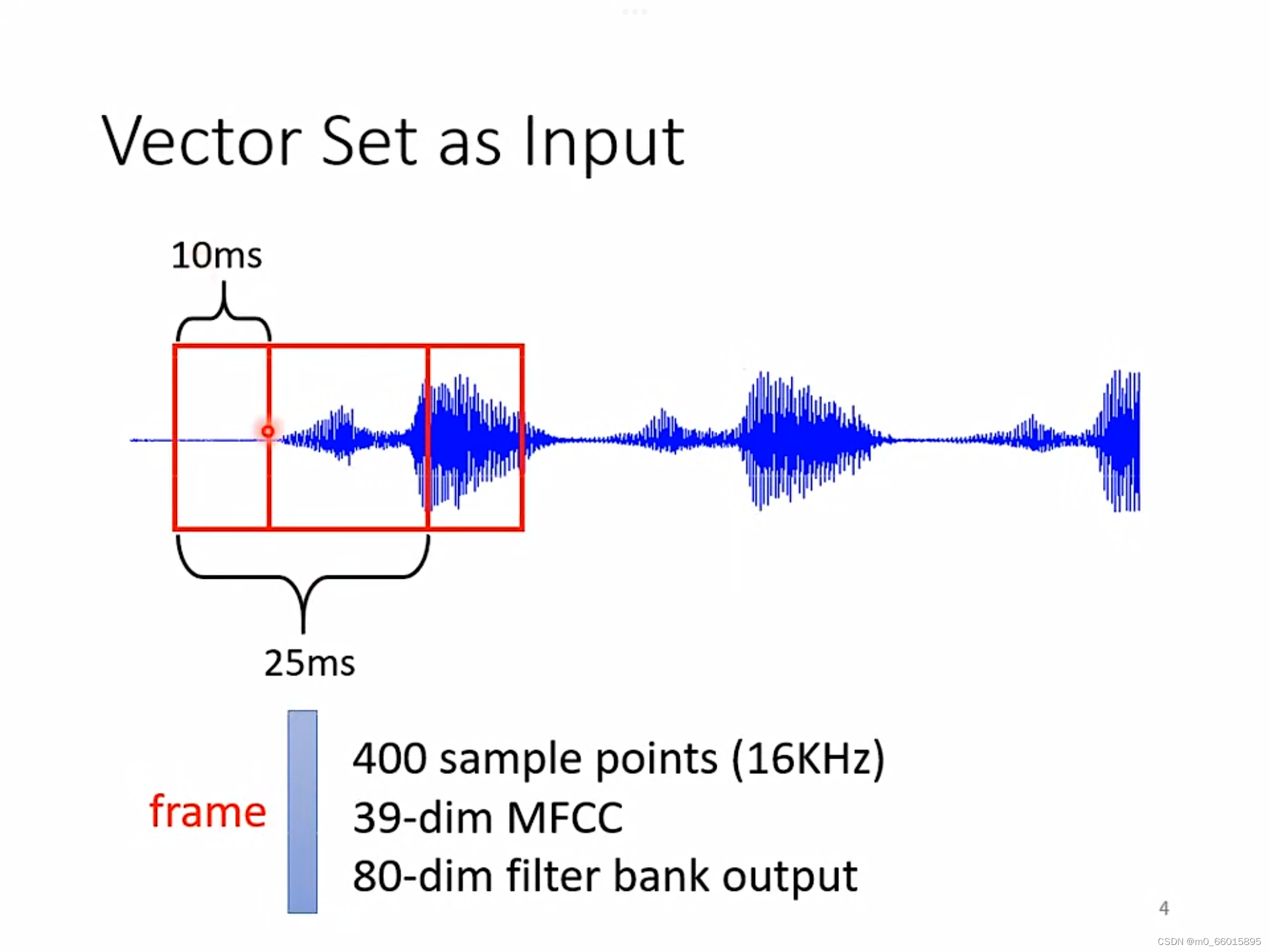
第二个例子:声音处理
一段声音讯号就是一排向量,一般会在声音讯号取一个范围,将这一范围的资讯描绘成向量,把这么一个向量叫作frame。
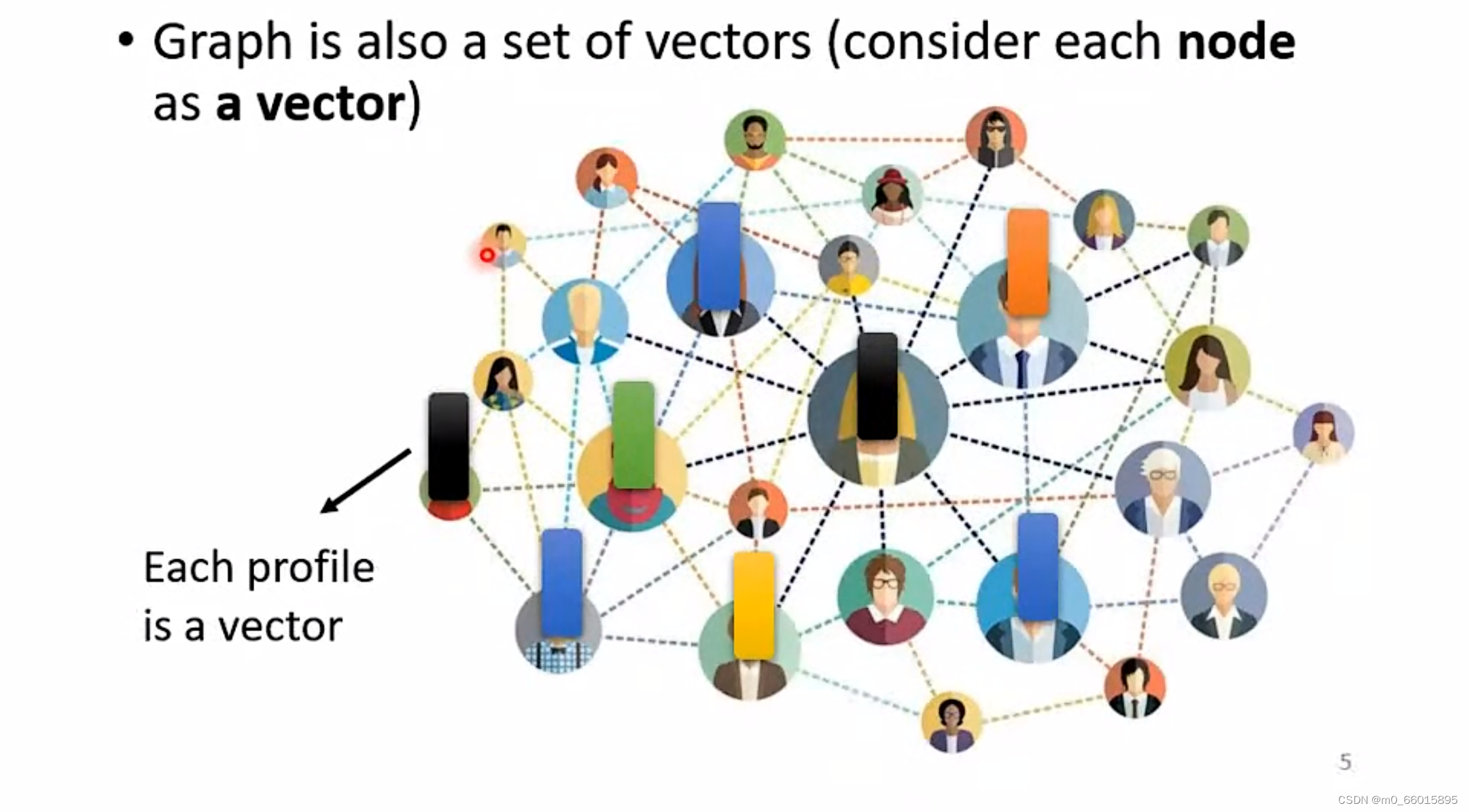
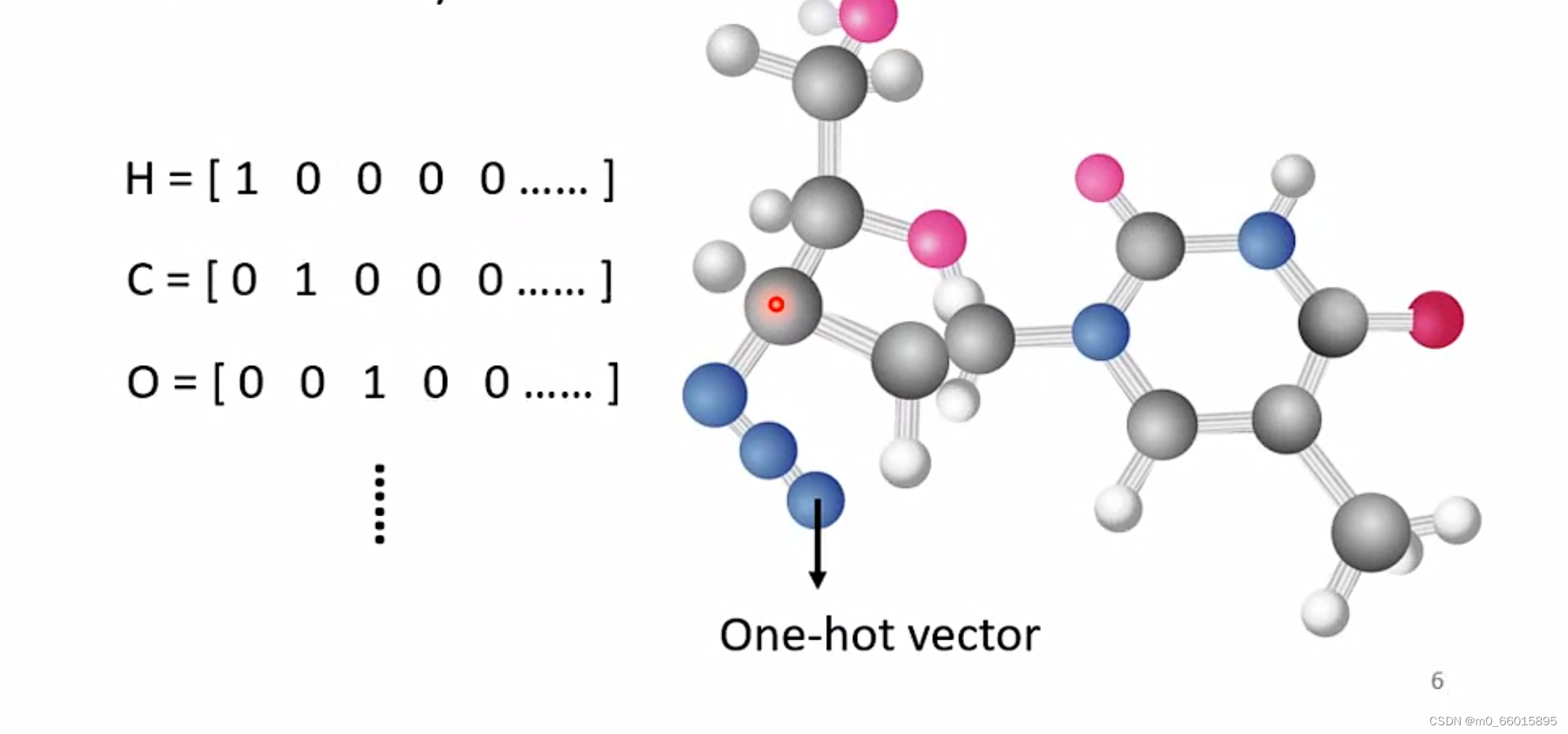
除此之外,一个graph也可以看成一堆向量组成,一个分子可以看作一组向量,每一个原子就是一个向量。
Q:输入可能是文字、语音等,那输出会有有几种呢?
A:一共有三种
第一种:当输入N个(一组)向量,经过Model预测后输出N个分类结果/数值型结果,例如词义辩识、语音声音讯号等。
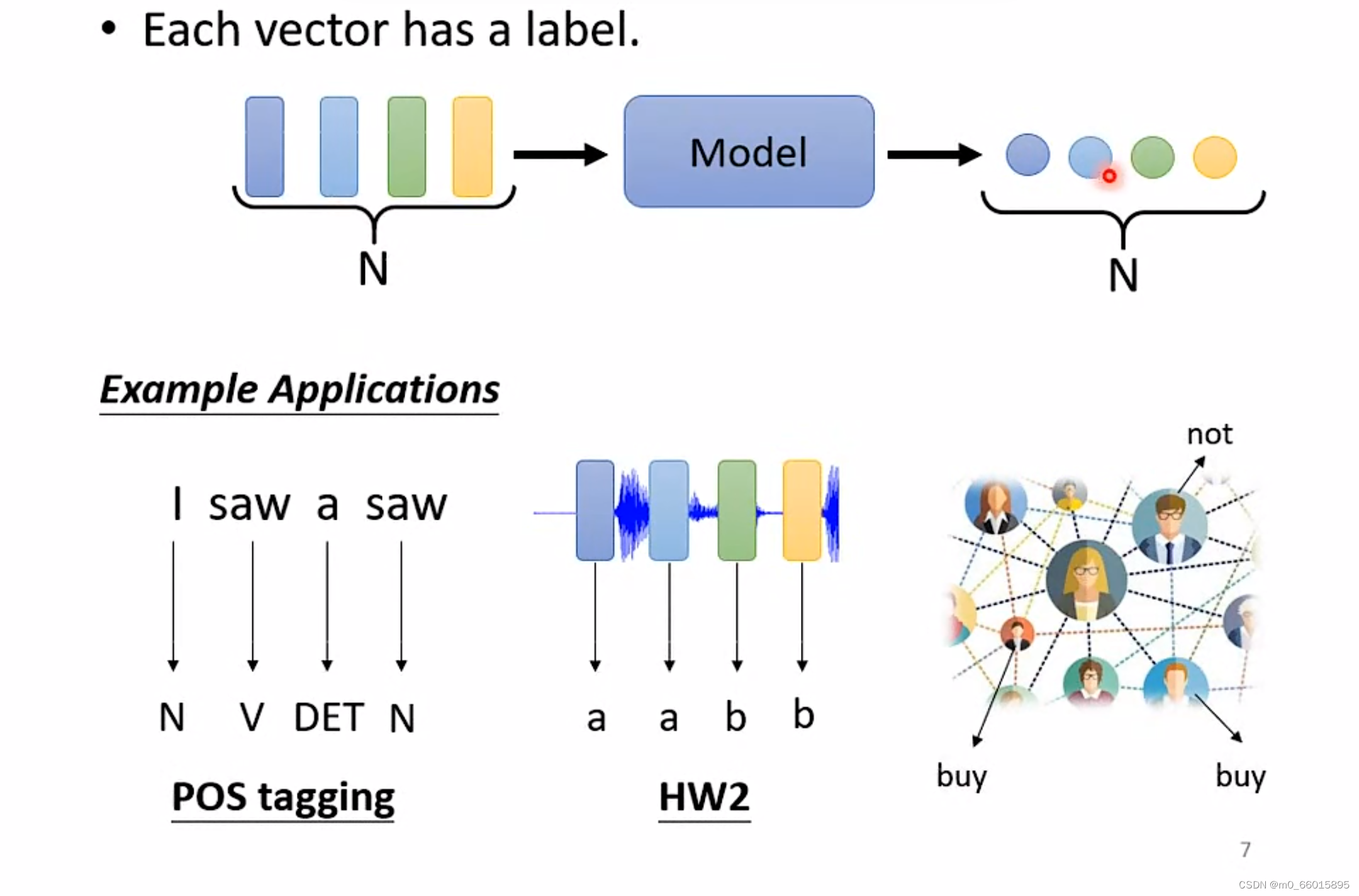
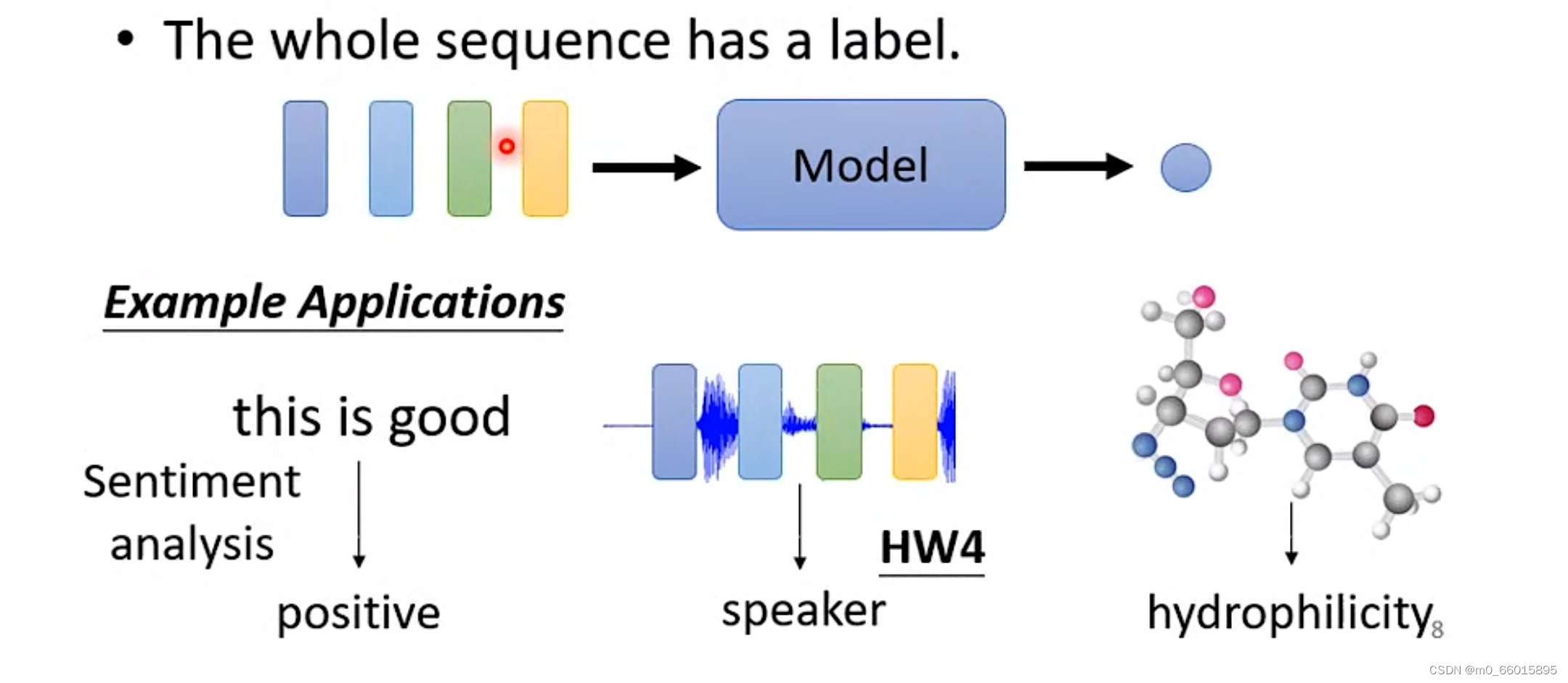
第二种:当输入N个(一组)向量,经过Model预测后输出一个分类结果/数值型结果。例如判断一句话是正面还是反面、语音辨认、判断分子是否具有某个性质等。
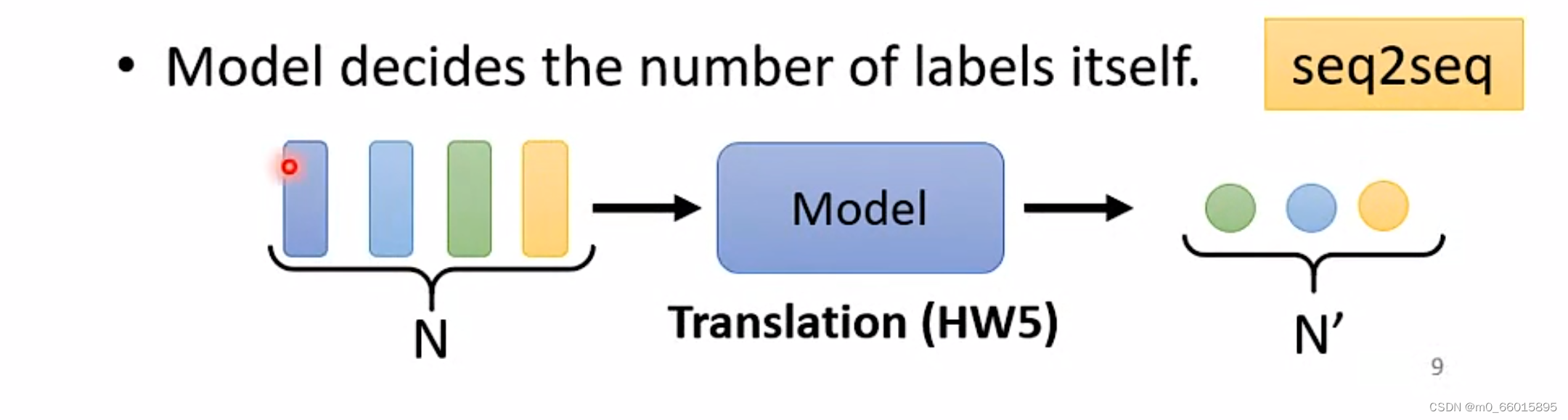
第三种:当输入任意个向量,经过Model预测后输出任意个分类结果/数值型结果,例如语音辩识、翻译等。
主要学习第一种情况
1.2 Sequence Labeling
每一个输入向量对应一个标签,这种叫做Sequence Labeling。把前后几个向量串起来一起输入Full-Connected,给Full-Connected一整个window的信息,让它可以考虑上下文,通过network 产生输出,有几个输入就有几个输出,输出的向量是考虑整个sequence的结果。
在输入的这句话中,每个词汇作为一个输入的向量,这里面的两个“saw”前面的是动词后面的是名词,但是对于Full-Connected来说,这两个“saw”没有任何区别,如果要判断一句话中相同词汇的不同词性,window的范围可能要覆盖整句话。
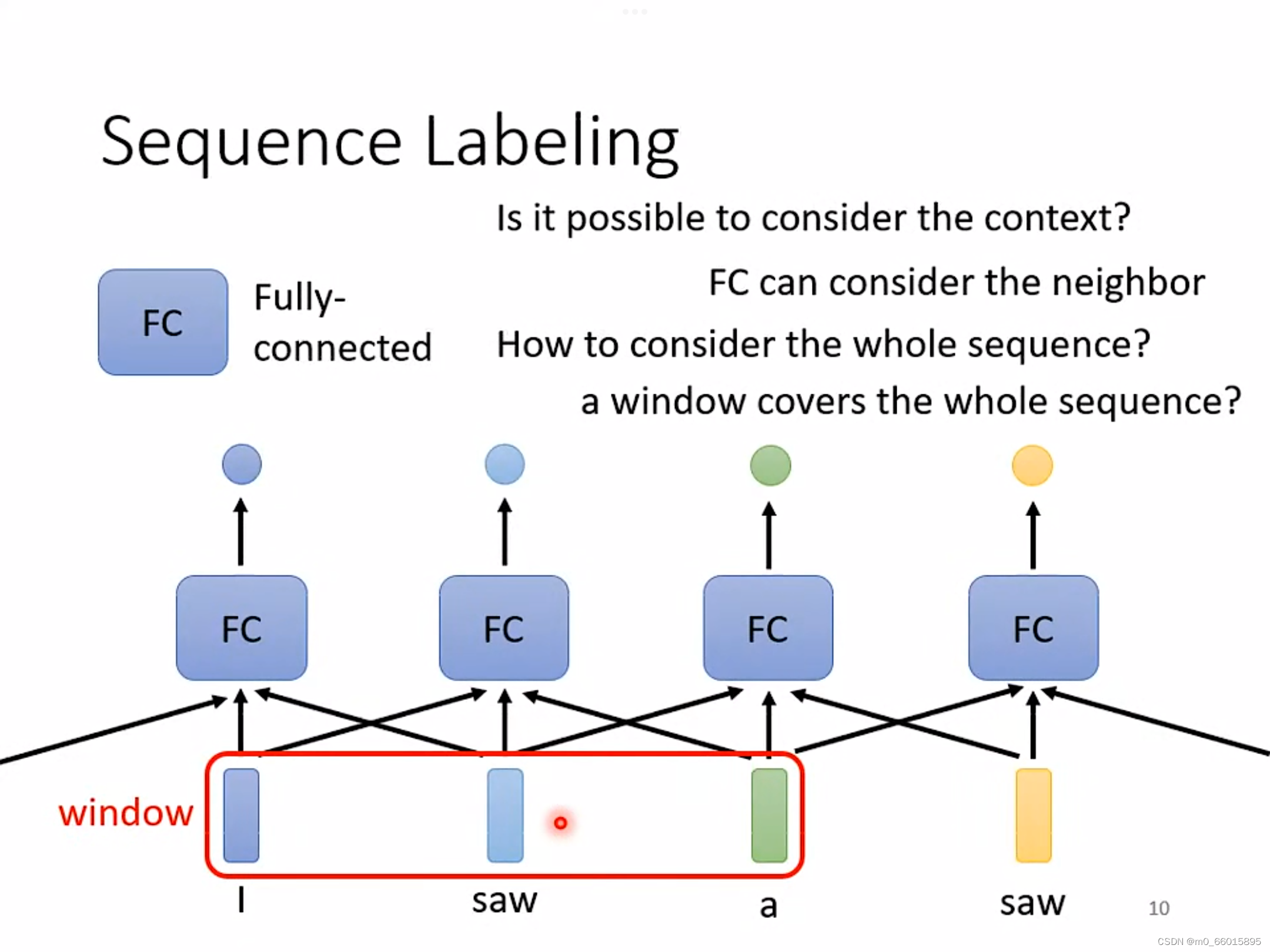 这样的方法还是存在极限的,如果window需要覆盖整个sequence,那么Full-Connected参数会很多,不止运算量大,还很容易overfitting,那么有什么方法可以将所有的sequence考虑进去呢?那就是self-attention。
这样的方法还是存在极限的,如果window需要覆盖整个sequence,那么Full-Connected参数会很多,不止运算量大,还很容易overfitting,那么有什么方法可以将所有的sequence考虑进去呢?那就是self-attention。
1.3 Self-attention+FC
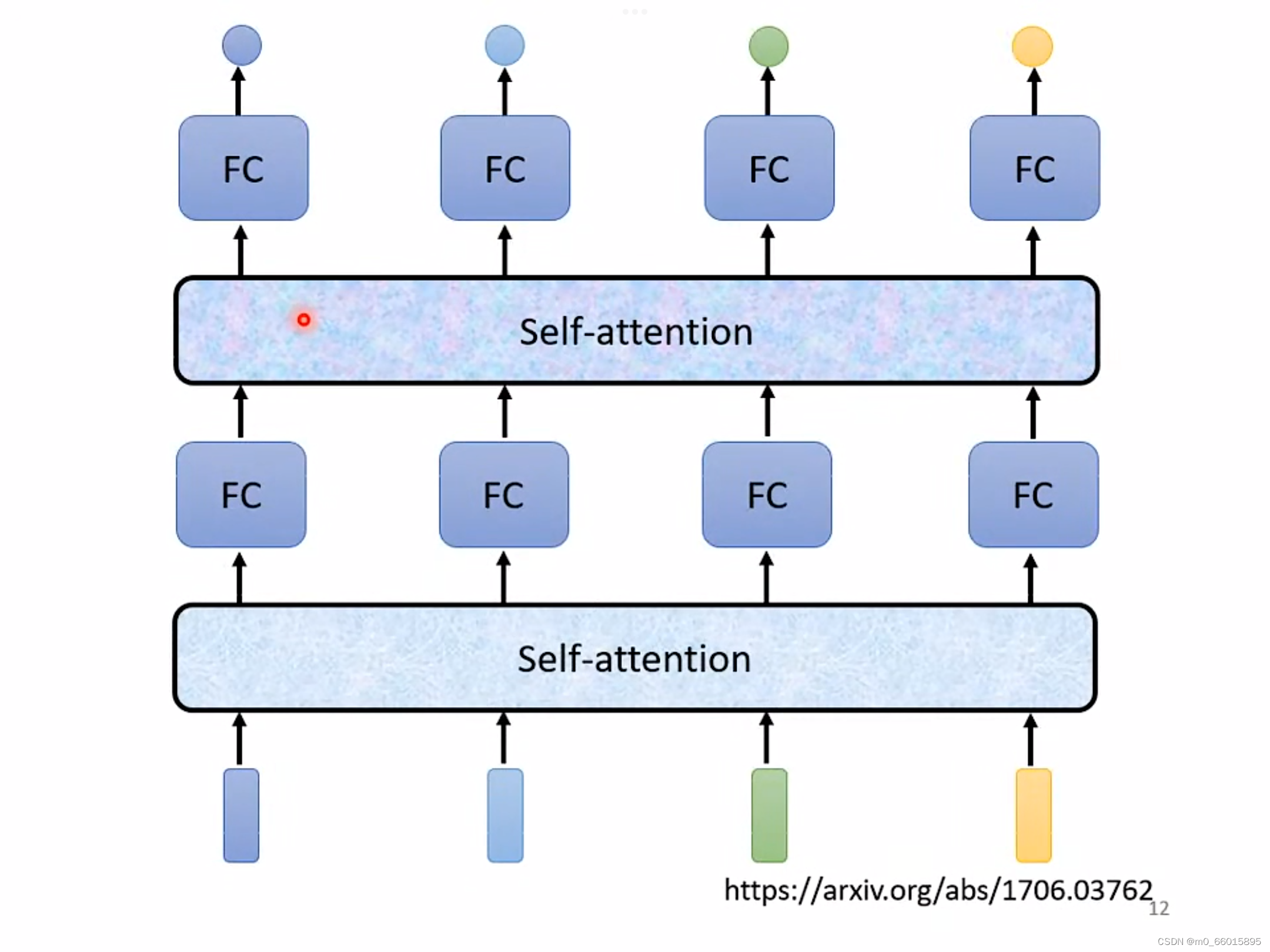
Self-attention不仅只能用一次,可以进行叠加使用,输入的向量通过Self-attention的输出可以传入Full-connected network,输出的结果再做一次Self-attention,再重新考虑一次整个sequence的信息,将结果再放入Full-connected network得到最终的结果。
Self-attention处理整个sequnece的信息,Full-connected负责处理某一位置的信息。
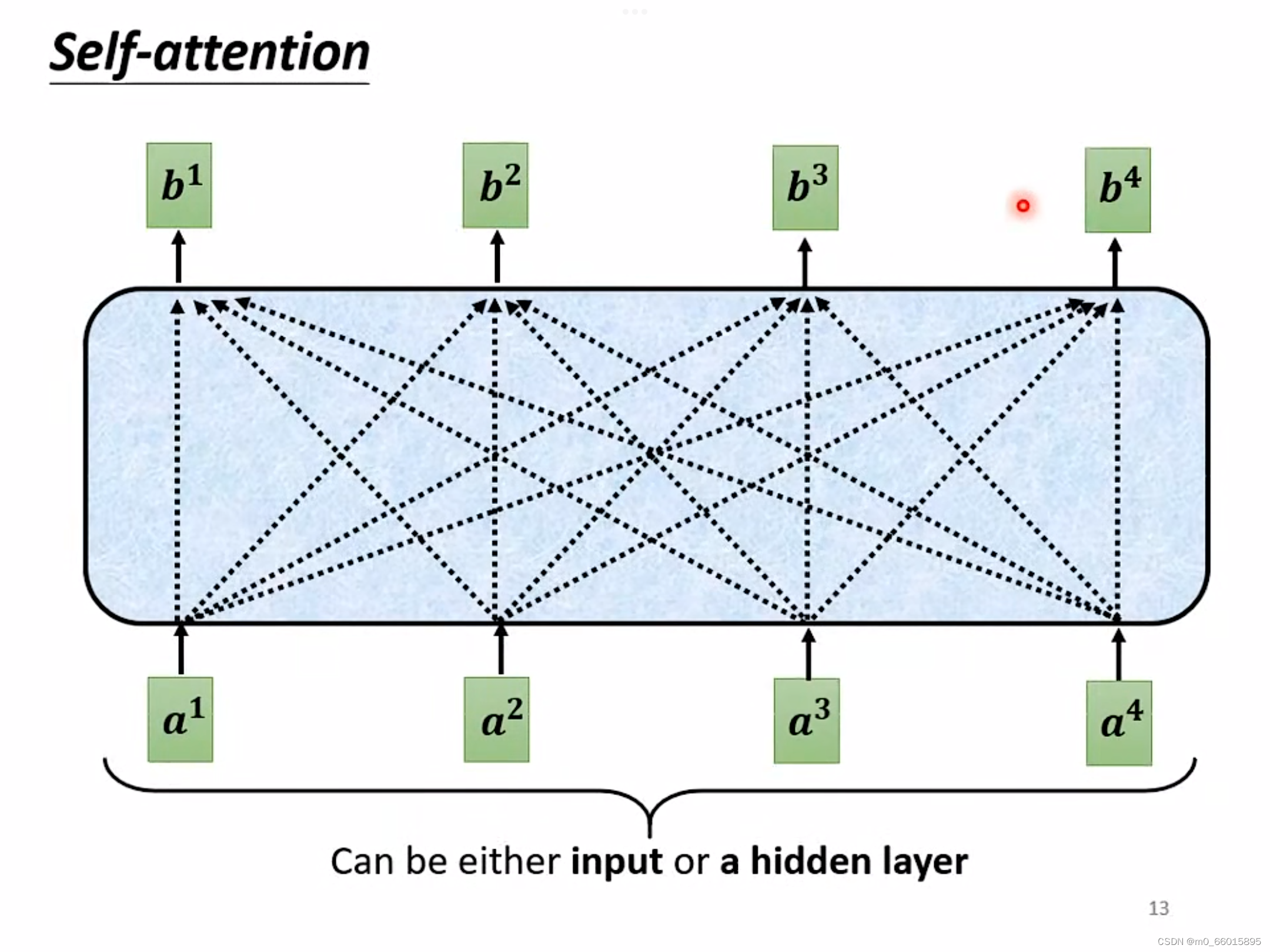
1.4 Self-attention的运作
Self-attention的输入通常是一串向量,而这个向量可能是这一整个神经网络的输入,也可能是某个隐藏层的输出。每个b都是考虑所有的a产生的。
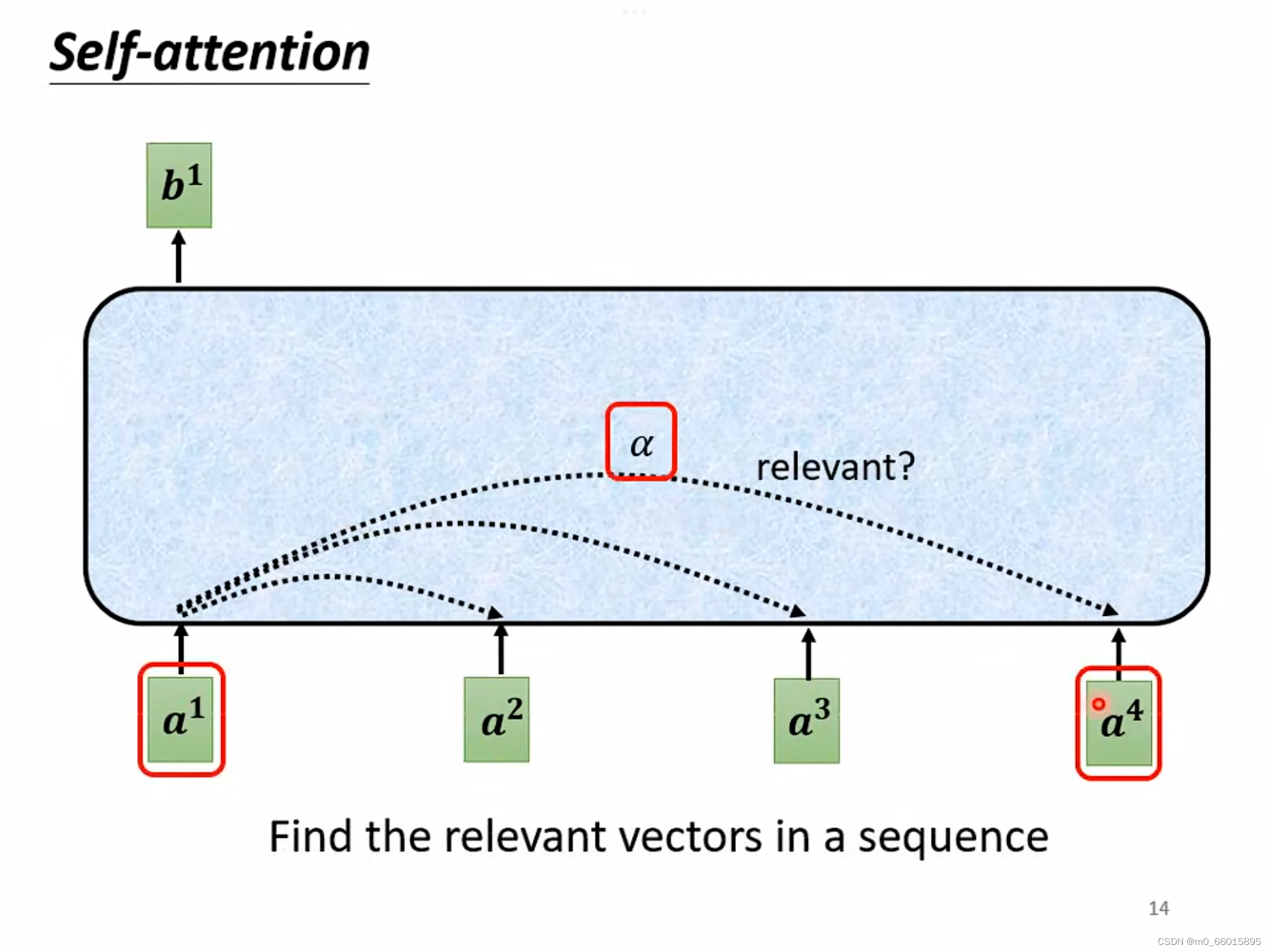
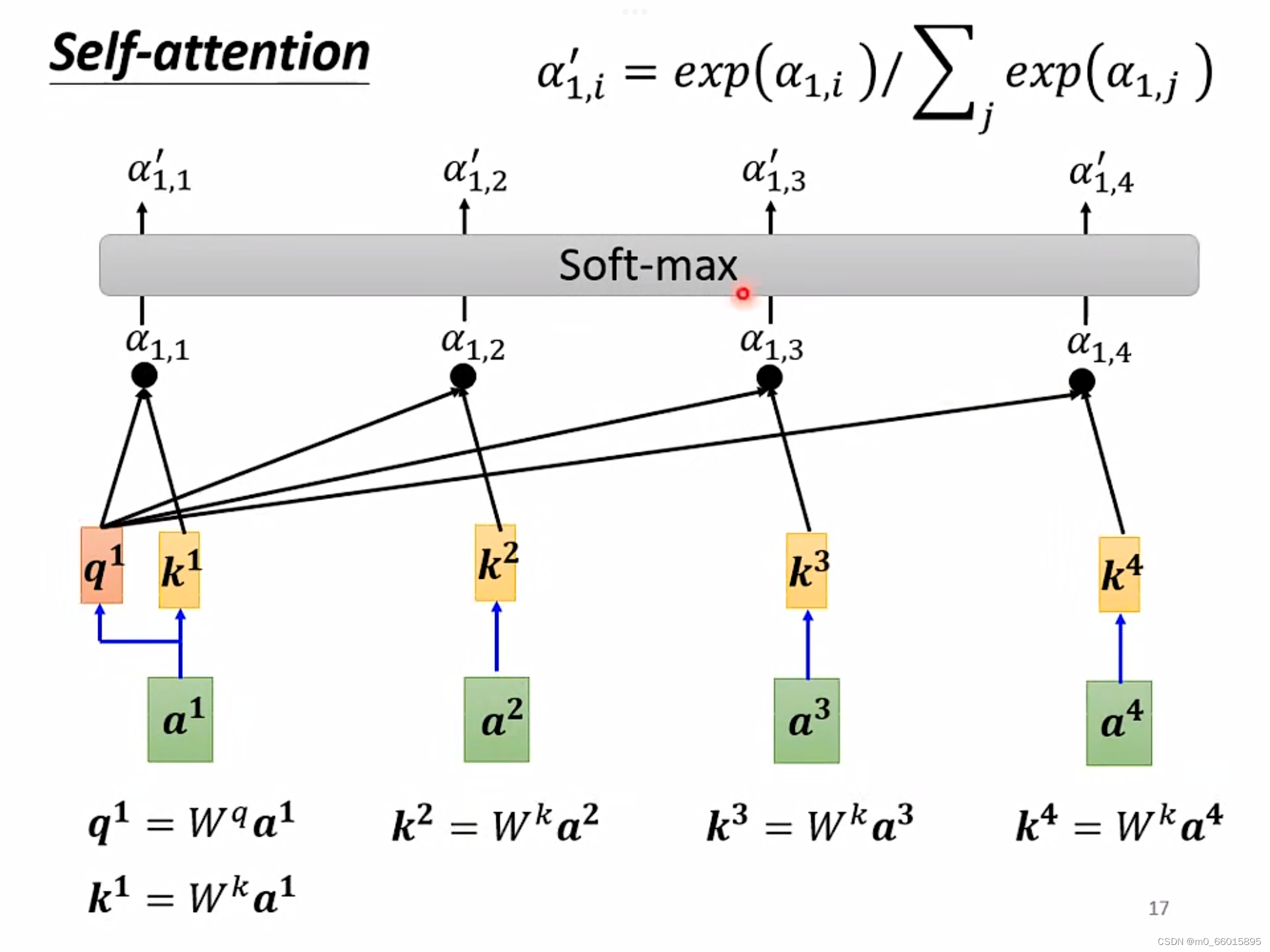
那么b是如何计算出来的?
以计算为例,首先根据
找出整个sequence里面跟
相关的其他向量,计算整个sequence里面所有向量跟向量
的关联度
,因为Self-attention就是为了考虑整个sequence,但又不希望把所有的信息都包括在window里面,所以需要找出哪些部分是重要的,因此通过这个机制过滤掉不重要的信息。
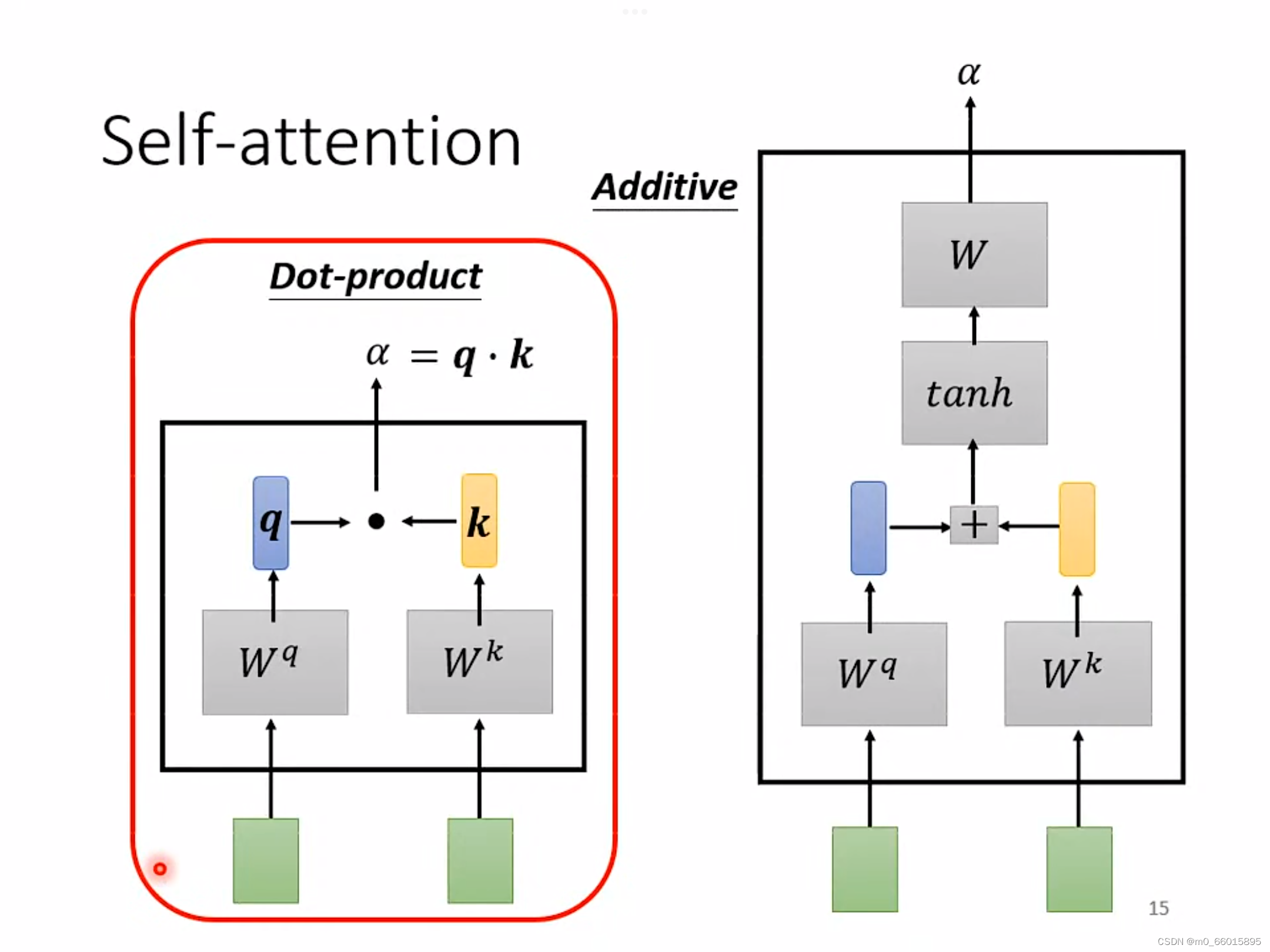
那么self-attention怎么找出每一个a呢?
方法一:Dot-product方法
将输入的两个向量分别乘以两个不同的矩阵
、
,得到向量q和一个数值k,最后q和k进行一个dot-product得到相关联度
。
方法二:Additive
同样将输入的向量与两个矩阵相乘得到的向量相加,然后使用tanh投射到一个新的函数空间,再相乘得到最后结果。·
对每个输入的向量,两两之间按上面的方法计算出关联度,在得到关联度之后,将结果进行soft-max(也可以使用Relu等方法)计算出一个attention distribution,在得到attention distribution之后相比较就知道哪些向量与
关系密切,就可以根据
抽取出这个sequence里面重要的信息。
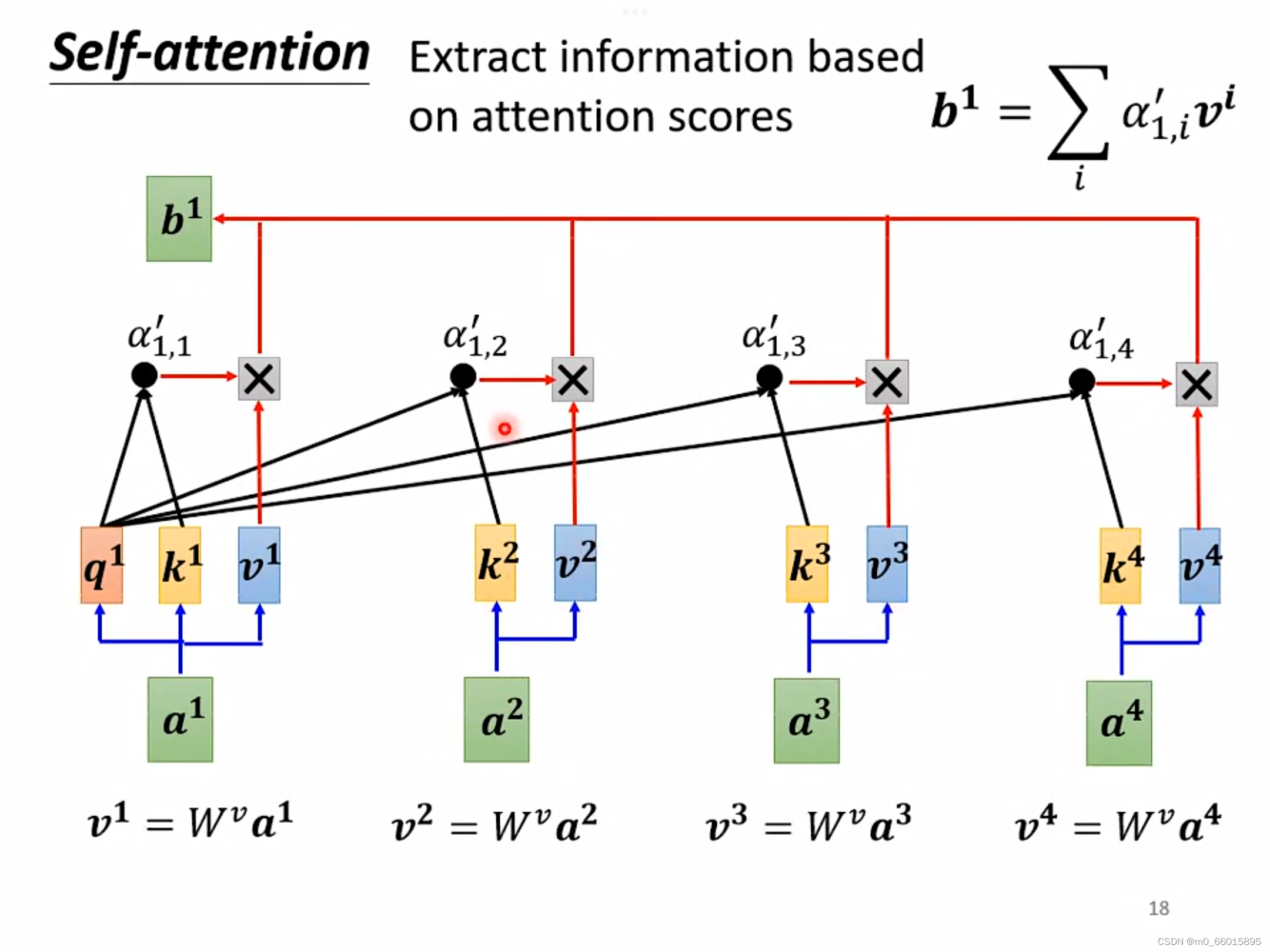
在得到每一个向量和之间的关联度之后,使用新的矩阵
乘上输入的向量
,得到一个新的矩阵
,然后将得到的关联度与矩阵
相乘,对每个输入的向量进行该操作,最后将每个关联度与矩阵
相乘的结果相加得到一个唯一数值
,最后将所有的关联度和数值
相比较,就可以得到其他输入向量与向量
的相似程度,越接近
,那么就和
越相似。
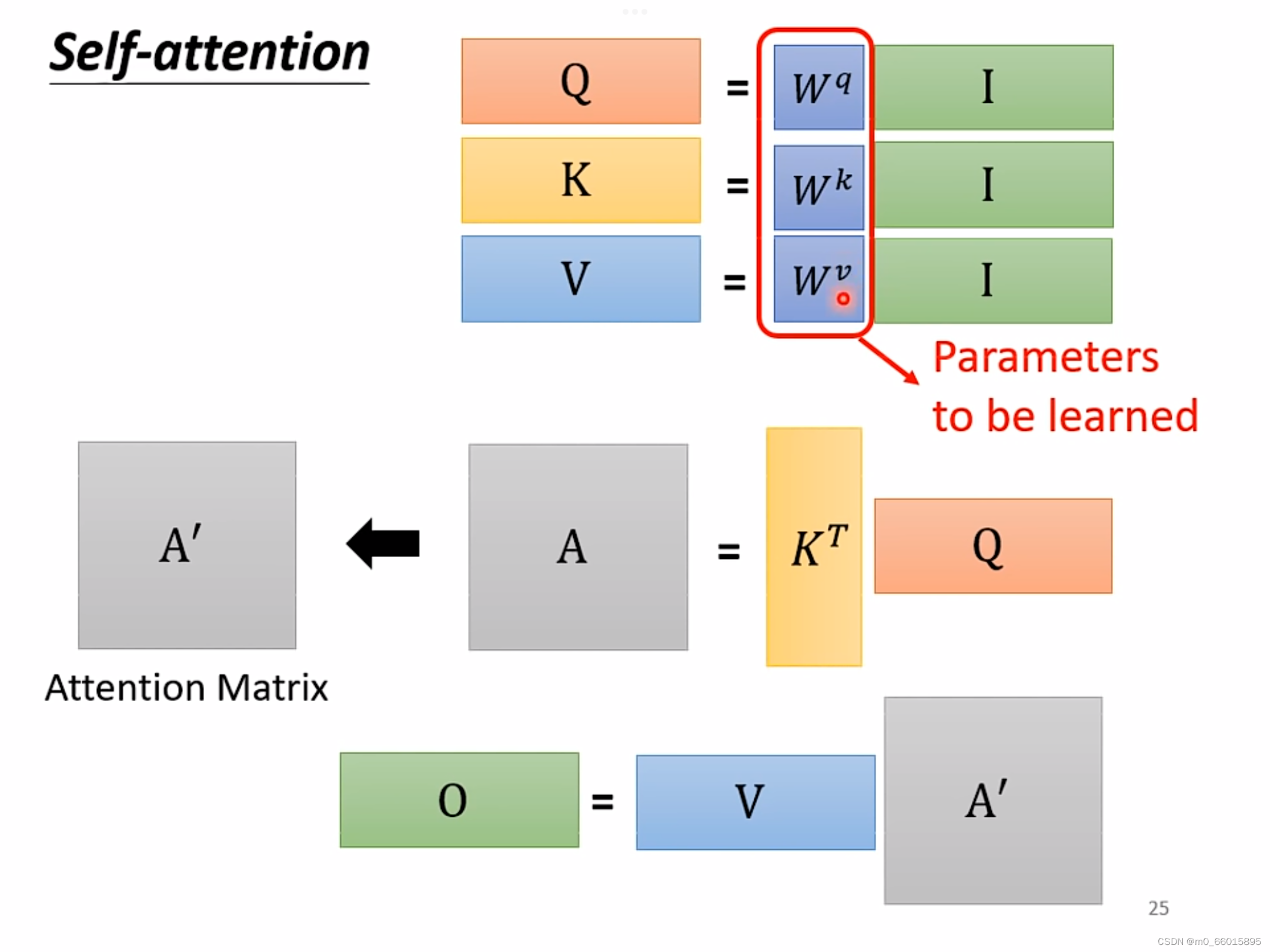
、
、
、
并不是依次产生而是同时被计算出来的
计算过程如下:

import torch
#第一步:输入三个长度为4的向量
x = [
[1, 0, 1, 0], # Input 1
[0, 2, 0, 2], # Input 2
[1, 1, 1, 1] # Input 3
]
x = torch.tensor(x, dtype=torch.float32)
#第二步:初始化key、query、value的权重
w_key = [
[0, 0, 1],
[1, 1, 0],
[0, 1, 0],
[1, 1, 0]
]
w_query = [
[1, 0, 1],
[1, 0, 0],
[0, 0, 1],
[0, 1, 1]
]
w_value = [
[0, 2, 0],
[0, 3, 0],
[1, 0, 3],
[1, 1, 0]
]
w_key = torch.tensor(w_key, dtype=torch.float32)
w_query = torch.tensor(w_query, dtype=torch.float32)
w_value = torch.tensor(w_value, dtype=torch.float32)
#第三步:通过输入和权重得到keys、querys、values
keys = x @ w_key
querys = x @ w_query
values = x @ w_value
#第四步:计算关联度
attn_scores = querys @ keys.T #两个矩阵相乘,一个转置
# tensor([[ 2., 4., 4.], # attention from Query 1
# [ 4., 16., 12.], # attention from Query 2
# [ 4., 12., 10.]]) # attention from Query 3
#第五步:将关联度的值进行softmax
from torch.nn.functional import softmax
attn_scores_softmax = softmax(attn_scores, dim=-1)
# tensor([[6.3379e-02, 4.6831e-01, 4.6831e-01],
# [6.0337e-06, 9.8201e-01, 1.7986e-02],
# [2.9539e-04, 8.8054e-01, 1.1917e-01]])
attn_scores_softmax = [
[0.0, 0.5, 0.5],
[0.0, 1.0, 0.0],
[0.0, 0.9, 0.1]
]
attn_scores_softmax = torch.tensor(attn_scores_softmax)
#第六步:将求得的每个关联度attention乘以对应的value矩阵
weighted_values = values[:,None] * attn_scores_softmax.T[:,:,None]
# tensor([[[0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000],
# [0.0000, 0.0000, 0.0000]],
#
# [[1.0000, 4.0000, 0.0000],
# [2.0000, 8.0000, 0.0000],
# [1.8000, 7.2000, 0.0000]],
#
# [[1.0000, 3.0000, 1.5000],
# [0.0000, 0.0000, 0.0000],
# [0.2000, 0.6000, 0.3000]]])
#第七步:将加权后的value求和得到唯一输出值
outputs = weighted_values.sum(dim=0)
# tensor([[2.0000, 7.0000, 1.5000], # Output 1
# [2.0000, 8.0000, 0.0000], # Output 2
# [2.0000, 7.8000, 0.3000]]) # Output 3
2 Muti-Head Self-attention
在transformation中,应用最广的一种self-attention机制叫做muti-head self-attention,这种attention相对之前的在attention而言,它对于每一个向量a可以具备多组的q,k,v来描述这一个向量,而之前的只用到了一组,使用多组q,k,v,那么就需要对每一组计算其b的值,有几组就有几个b值。不同的任务需要用到的head数目是不一样的,对于有些任务比如语音辨识,使用的head越多效果越好。
Q:为什么head越多越好呢?
A:在做self-attention的时候,就是用
去找相关的k,但是相关这件事情有不同的形式、不同的定义,因此需要更多的q负责不同种类的相关性。
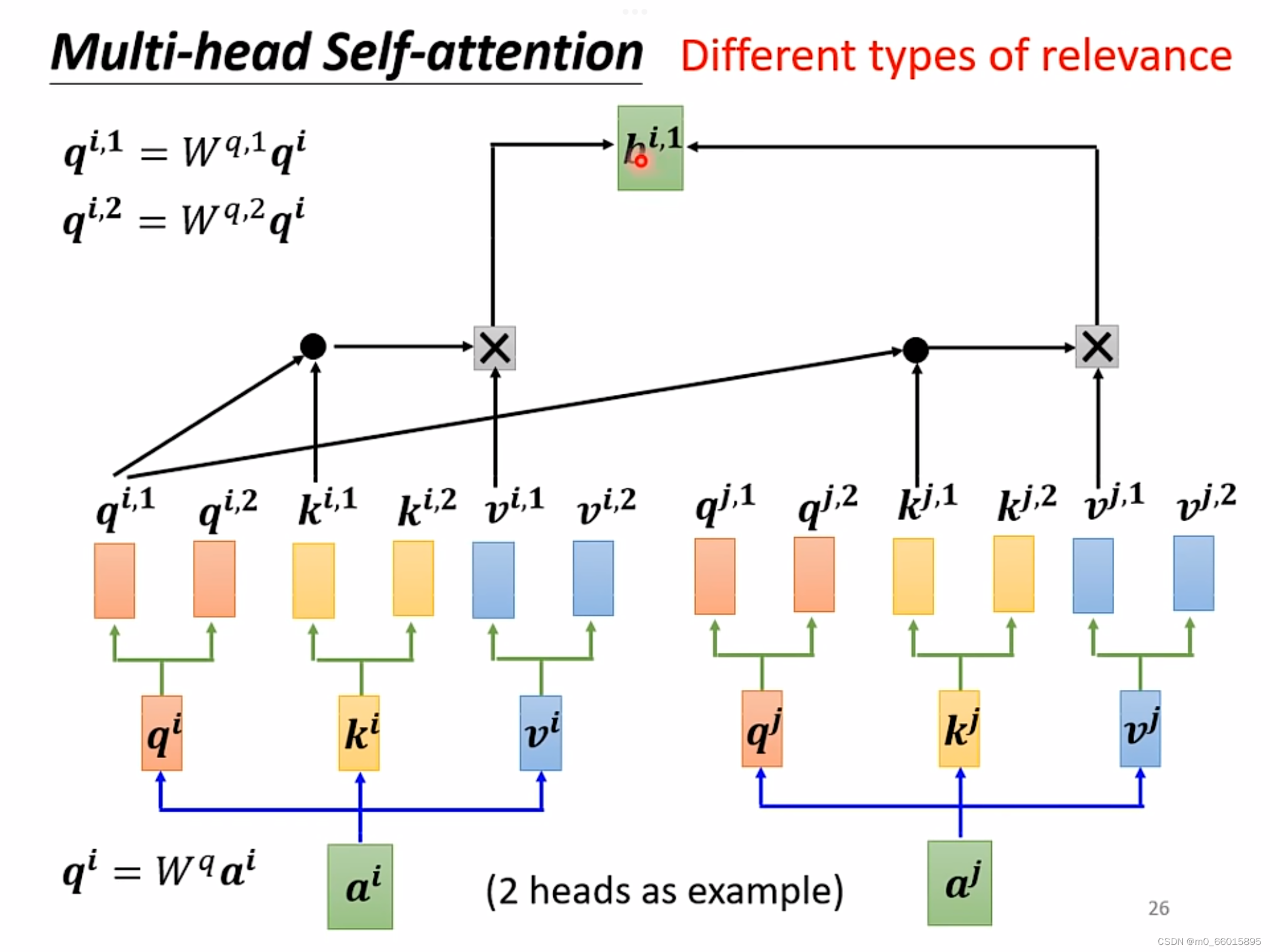
以2个head为例计算:

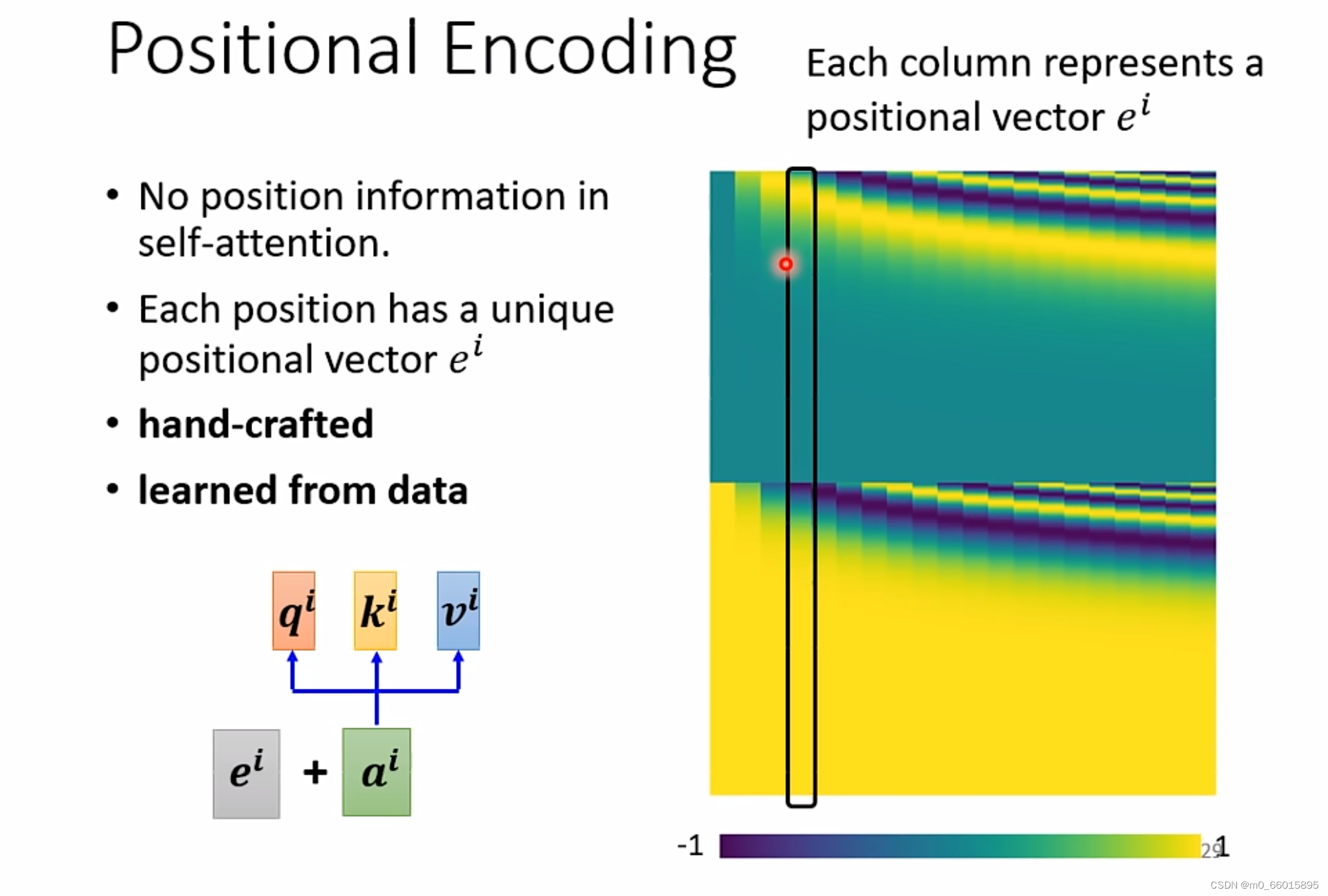
3 Positional Encoding
在self-attention这个layer中少了一个position information(位置信息),那么把这个位置信息插入到self-attention中去就需要用到positional encoding这个技术,为每个位置设定一个专属的位置向量,然后将这个位置向量
加到
上,现在
的位置就是已知的了。
4 Self-attention在多领域的应用
self-attention除了可以用在Transformaer上,还可以用在其他多个领域。
4.1 Self-attention for Speech
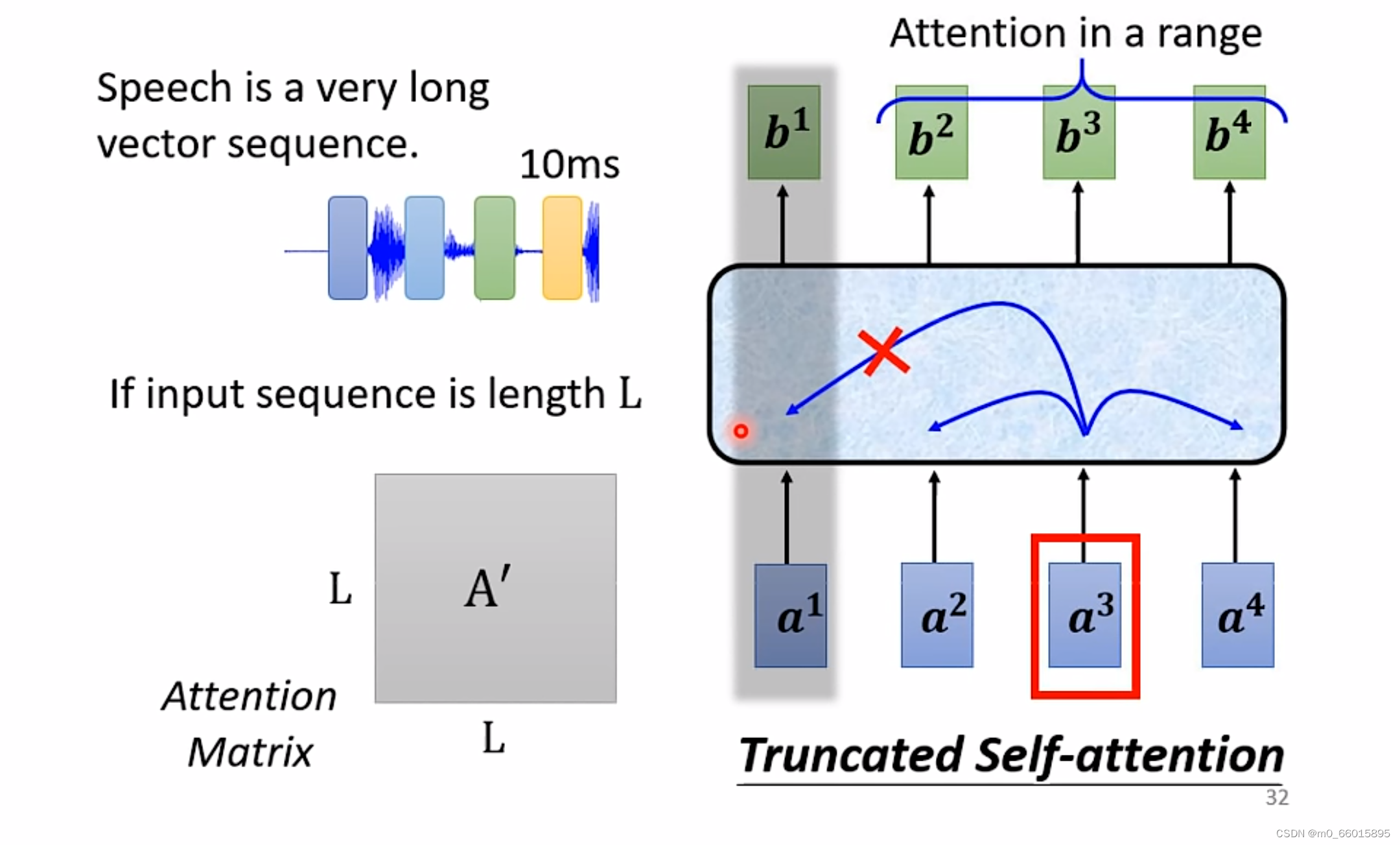
在做语音的时候,要把声音信号表示成一排向量,而每个向量只代表10ms的长度,假设有一秒钟的声音信号那就有一百个向量,因此要描述一段声音信息,那么需要的vector sequence是非常长的,如果采用self-attention的话,那么就需要很大的Attention Matrix。为了减少计算量,因此在做语音的时候可以采用Truncated Self-attention,在语音辨识里有可能不会考虑整个序列而是只考虑一个范围,这个范围是根据任务设定的。
4.2 Self-attention for Image
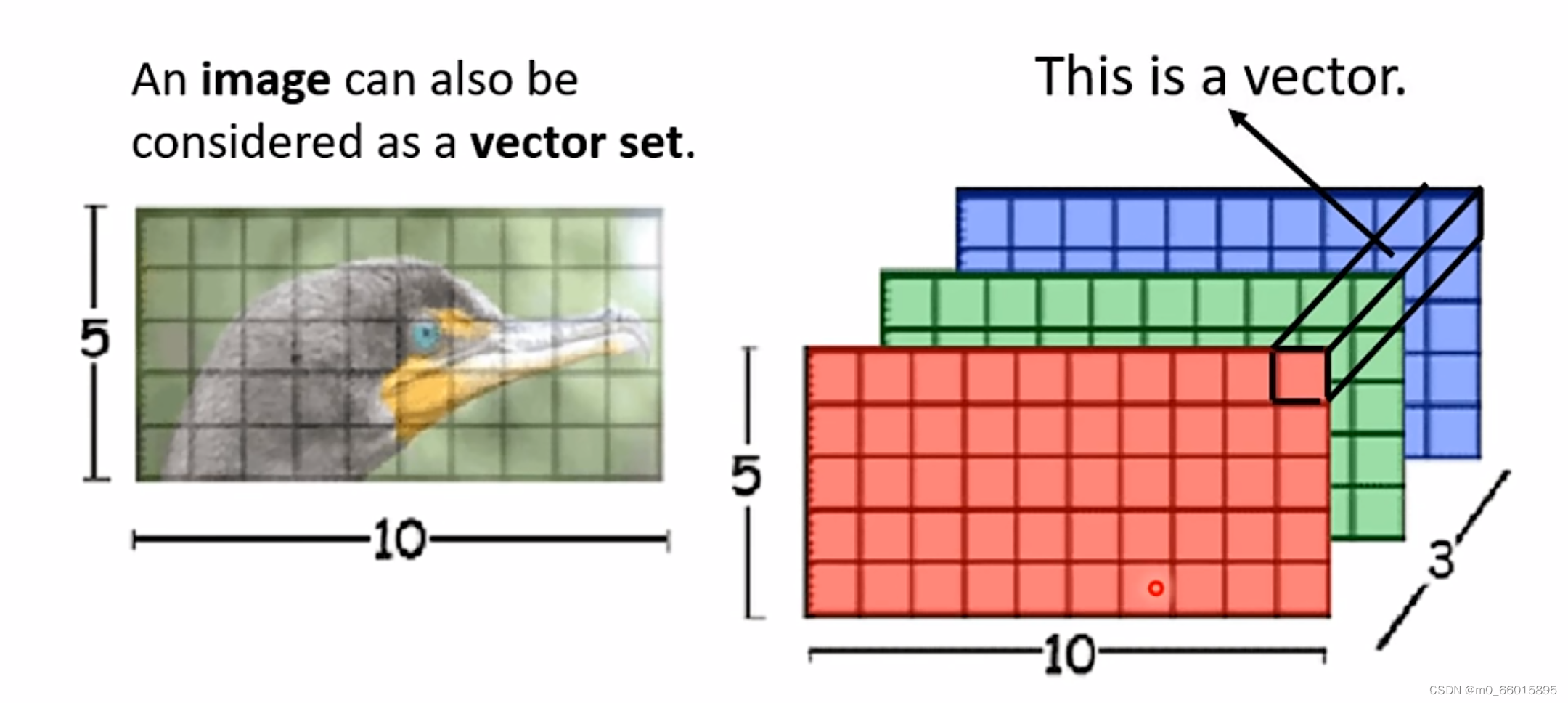
换一个角度来看image,可以把每一个三维的pixel看作一个vetor,然后所有合起来就是一个向量集。
4.3 Self-attention for Graph
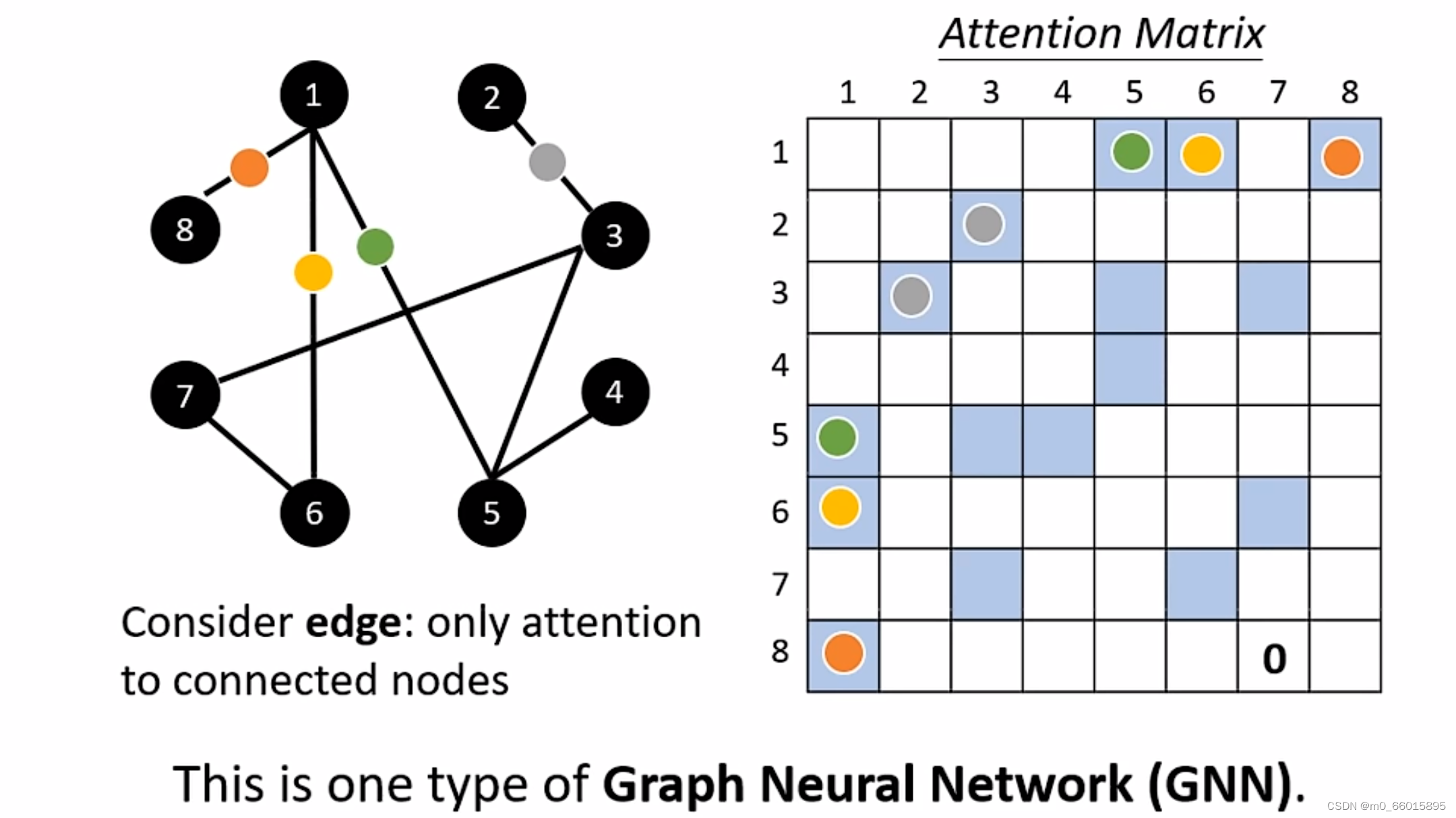
Self-attention应用在图上时,就可以知道节点之间关联,当计算Attention Matrix,只需要计算和该节点相连的节点。把Self-attention应用在graph上其实就是一种GNN。
5 Self-attention v.s. CNN
CNN可以看作简化版的Self-attention,因为在做CNN的时候只考虑receptive field里面的信息,而Self-attention是考虑全部的信息。(Self-attention如果设定一定的参数就可以做和CNN一样的事情)
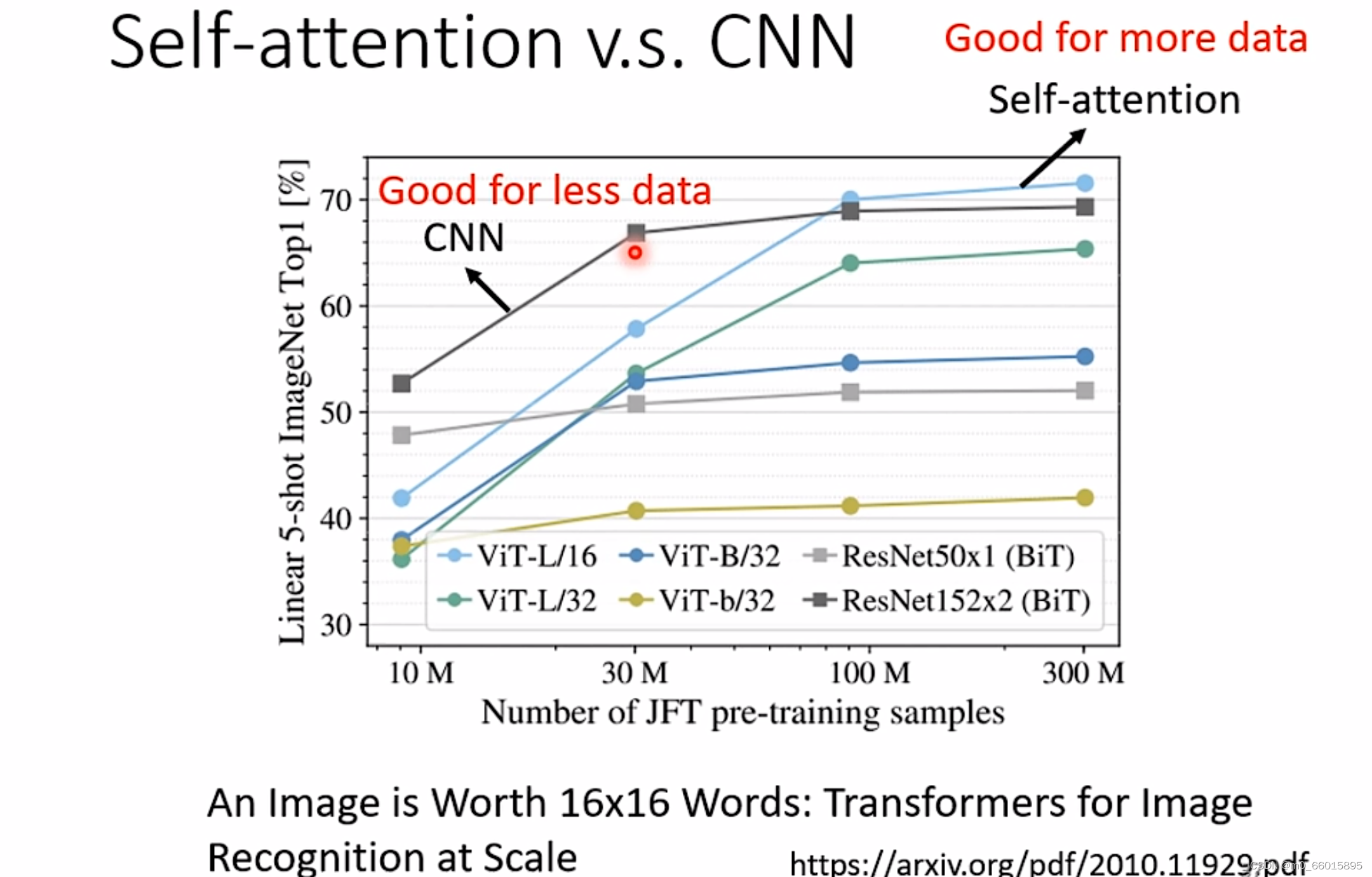
Self-attention考虑的范围更大,它的模型自由度高,因此需要更多的data,data不够就有可能overfitting,而对于CNN这种有限制的模型,在data比较少的时候也不会容易overfitting。从下图的一个测试中可以看出,在资料量少的时候,CNN表现得比Self-attention好,而当资料量越老越多达到一定数量后,Self-attention反而会超过CNN。
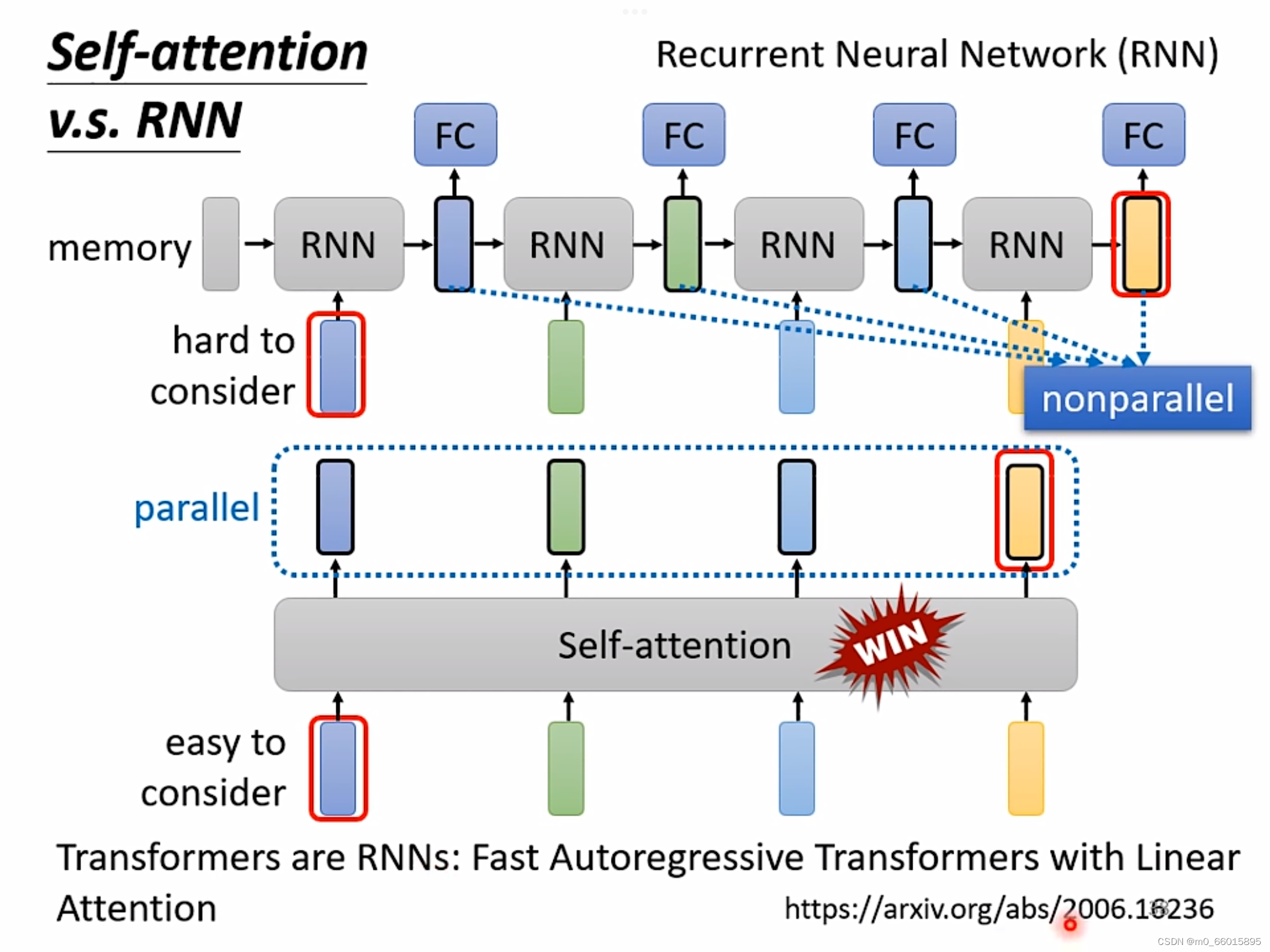
6 Self-attention v.s. RNN
共同点:都要处理一个input是一个sequence的状况
区别:①self-attention考虑了所有输入的向量,而RNN只能考虑左边已经输入的向量而不能考虑右边没有输入的向量。
②self-attention可以进行平行运算所有输出,而RNN不可以进行平行运算。
总结
本周学习了self-attention机制,通过手写运算了解了self-attention的运作方法,分析了self-attention与CNN、RNN等其他机制的异同点,以及学习了self-attention的相关应用领域。self-attention要解决的问题是:当神经网络的输入是多个大小不一样的向量,并且可能向量之间存在一定的关联,而在训练时却无法充分发挥这些关系,导致模型训练结果较差。通过计算输入之间的关联性,过滤掉无效的信息,减少计算量。















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









