







目录
3. 创建 analysis_results(数据分析结果表)
由于本人最近在考试周,所以先写个框架,后面再补细节
源码:https://github.com/ceilf6/startup-analysis-platform
技术栈:Python、HTML、JS、MyBricks、NocoBase、SpiderFlow、Superset、Dify、Docker、API集成
概述
本项目是一个多端应用,前端基于 Vue.js + Element UI 框架。后端是一个微服务架构,通过Docker容器化部署将基于Python、Java、Node.js的应用进行集成(包含SpiderFlow爬虫、Superset数据分析、NocoBase数据库、Dify-AI模型)。前后端间通过 Axios 库进行API通信
思维导图
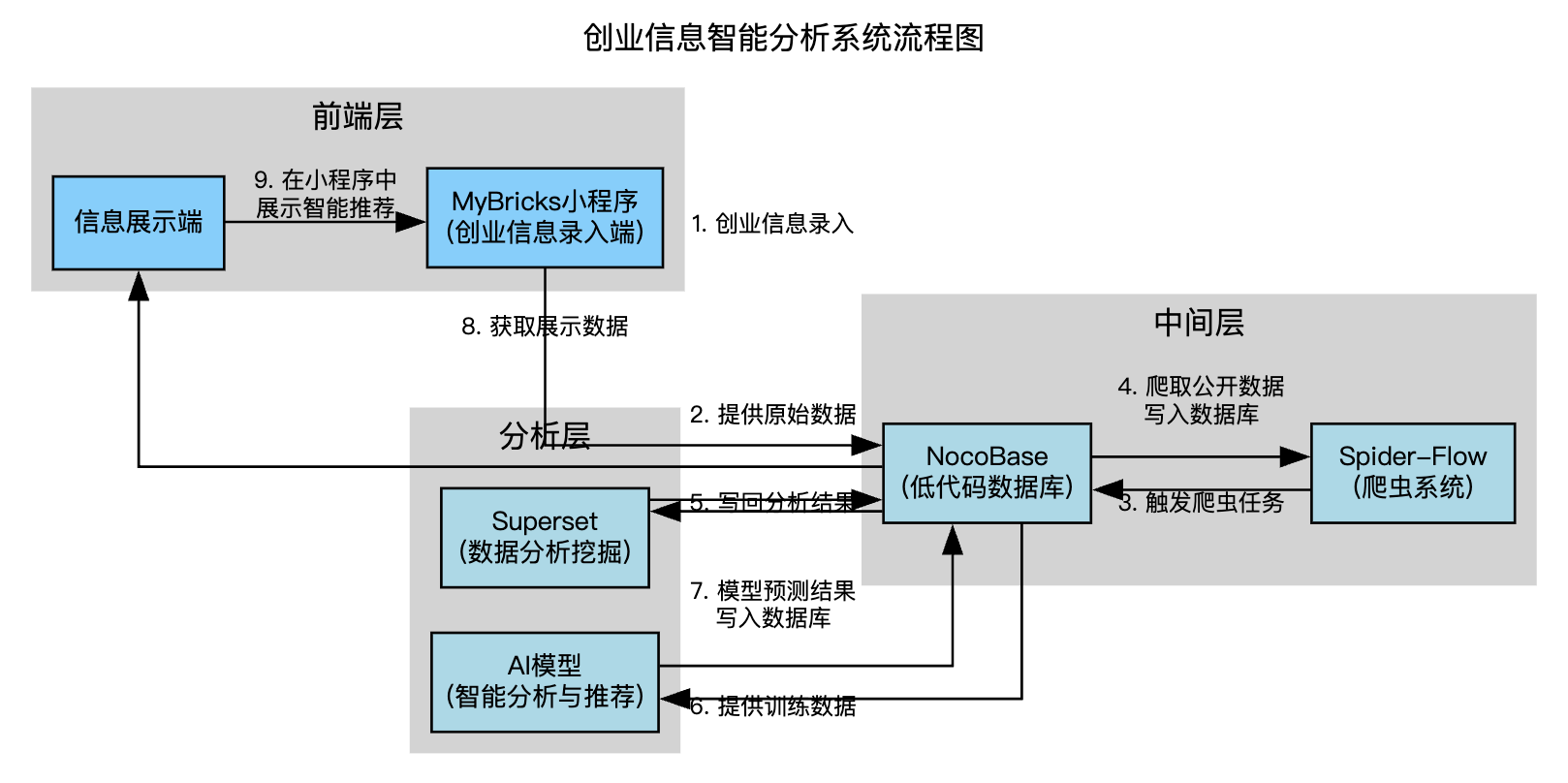
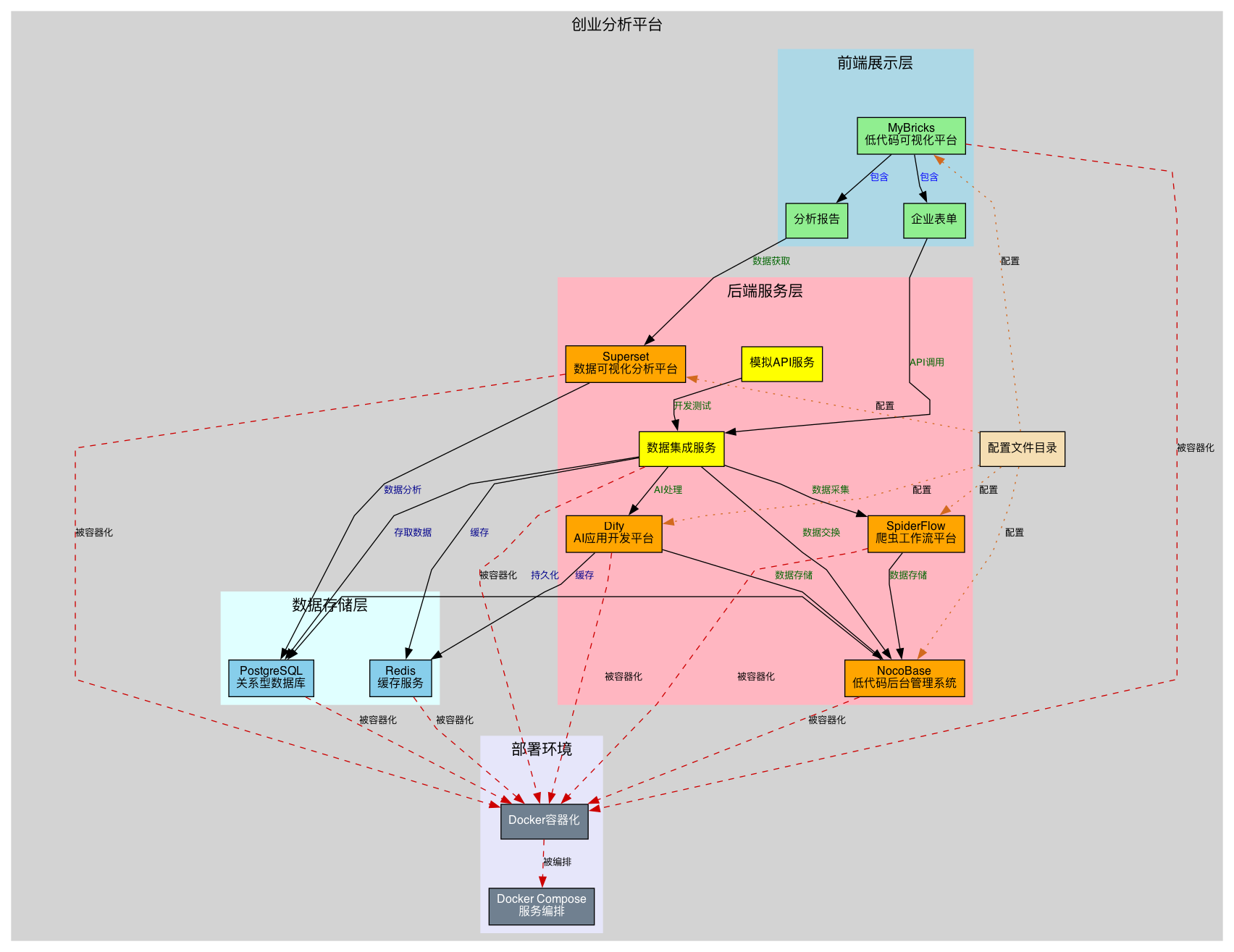
项目目录
创业分析平台_精简/
│
├── README.md (包含项目说明和启动指南)
│
├── 后端服务/
│ ├── nocobase/
│ │ └── docker-compose.yml
│ │
│ ├── 数据分析/
│ │ └── superset/
│ │ └── docker-compose.yml
│ │
│ └── 爬虫系统/
│ └── spider-flow/
│ └── docker-compose.yml
│
├── AI模型/
│ └── simple_model/
│ ├── app.py
│ ├── model.py
│ ├── Dockerfile
│ └── requirements.txt
│
├── web端/
│ ├── index.html
│ ├── css/
│ ├── js/
│ ├── images/
│ └── pages/
│ ├── ai-insights/
│ ├── analysis/
│ ├── login/
│ ├── startup/
│ └── user/
│
└── 小程序端/
└── mybricks-app/
├── app.js
├── app.json
└── pages/
├── index/
├── ai-insights/
├── analysis/
└── startup-form/前置知识
Docker是什么?
Docker是一个开源的容器化平台,它可以将应用程序及其依赖项打包到一个称为"容器"的标准化单元中。每个容器都是一个轻量级、可移植、自给自足的软件执行环境,包含了运行应用程序所需的一切:代码、运行时、系统工具、系统库和设置。
Docker的核心概念:
- 镜像(Image): 应用程序及其依赖的不可变模板,用于创建容器。
- 容器(Container): 镜像的运行实例,可以启动、停止、移动或删除。
- Dockerfile: 用于自动构建镜像的文本文件,包含构建镜像所需的所有命令。
- Docker Compose: 用于定义和运行多容器应用程序的工具。
Docker在本项目中的作用
1. 环境隔离与一致性
本项目用微服务架构,包含多个不同的服务:
- data-integration: 数据集成服务(Python应用)
- dify: AI应用开发平台
- mybricks: 低代码可视化平台
- nocobase: 低代码后台管理系统
- spiderflow: 爬虫工作流平台
- superset: 数据可视化和分析平台
每个服务可能有不同的依赖项和环境要求,Docker确保每个服务在其独立环境中运行
2. 简化部署流程
在deployment/docker-compose.yml文件中定义了项目中各个服务如何组合运行。通过一个简单的docker-compose up命令,可以启动整个应用栈,而不必手动配置每个组件。
例如,数据集成服务在Dockerfile中定义了如何构建镜像:
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY . .这个Dockerfile指定了使用Python 3.9作为基础镜像,安装了requirements.txt中列出的依赖项,并复制了服务代码到容器中。
3. 资源管理与扩展性
Docker容器使您可以更有效地管理系统资源,并且容器可以根据负载需求轻松扩展。在您的项目中,如果某个服务需要更多资源或需要扩展,可以在docker-compose.yml中调整配置。
4. 服务整合与通信
本项目作为一个API应用,这些服务需要相互通信:
- PostgreSQL数据库服务存储应用数据
- Redis缓存服务提高性能
- 数据集成服务连接不同数据源
- 前端应用提供用户界面
Docker网络使这些服务能够安全地相互发现和通信,无需暴露不必要的端口到主机。
5. 版本控制和回滚
使用Docker,可以对应用的不同版本进行标记,并在需要时轻松回滚到先前的稳定版本,这对于持续部署和维护非常重要。
6. 开发与生产环境一致性
Docker保证了在开发环境中测试的代码在生产环境中会以相同的方式运行,减少了"在开发环境工作但在生产环境失败"的问题。
总结
在本项目中,Docker提供了一个统一的平台来开发、测试和部署您的微服务架构。它简化了复杂应用的管理过程,使您能够专注于构建功能而不是处理环境配置问题。通过docker-compose.yml文件,可以一键启动整个应用栈,使应用的部署和运行变得简单高效。
前端
具体分析可以看:创业分析平台Web端-三大前端核心语言详解-首页index-CSDN博客
1.Web
本创业分析平台的Web端采用了前后端分离的架构,使用Vue.js和Element UI作为前端技术栈,通过API与后端服务进行交互。
1. 项目初始化与框架搭建
技术栈选择
- 前端框架:Vue.js 2.x(非脚手架方式引入)
- UI组件库:Element UI
- HTTP请求:Axios
- 图表库:ECharts (用于数据分析页面)
基础目录结构
web端/
├── css/ # 样式文件
│ ├── common.css # 公共样式
│ └── index.css # 首页样式
├── js/ # JavaScript文件
│ ├── common.js # 公共脚本和工具函数
│ ├── config.js # 配置文件(API地址等)
│ ├── services.js # API服务封装
│ └── index.js # 首页脚本
├── images/ # 图片资源
├── pages/ # 页面目录
└── index.html # 首页2. 公共模块与工具开发
配置文件 (config.js)
定义了系统的基础配置,包括:
- API基础路径
- 后端服务配置(NocoBase、Spider-Flow、Superset、AI模型)
- API路径映射
const CONFIG = {
apiBaseUrl: 'http://localhost:8000',
services: {
nocobase: {
baseUrl: 'http://localhost:13000/api',
apiKey: 'YOUR_API_KEY'
},
// 其他服务配置...
},
api: {
// API路径映射...
}
};公共工具库 (common.js)
封装了常用功能:
- API请求方法(GET、POST、PUT、DELETE)
- 用户认证逻辑(Auth对象)
- 工具函数(日期格式化、字符串处理等)
- 公共UI元素初始化
服务封装 (services.js)
将各后端服务API进行统一封装:
- NocoBase服务接口(创业项目CRUD)
- Spider-Flow服务接口(爬虫任务)
- Superset服务接口(数据分析)
- AI模型服务接口(分析和洞察)
3. 页面开发
首页 (index.html)
- 平台概览
- 统计数据展示
- 最新动态列表
- 热门分析推荐
用户认证页面
- 登录页面 (login/index.html)
- 注册页面 (login/register.html)
- 忘记密码页面 (login/forgot-password.html)
创业信息页面 (startup/index.html)
实现了分步表单:
1. 基本信息(项目名称、行业、阶段等)
2. 创始团队信息
3. 产品和市场信息
4. 财务状况
数据分析页面 (analysis/index.html)
- 创业项目综合评分
- 市场规模图表
- 竞争对手分析
- 风险评估雷达图
- 财务预测图表
AI洞察页面 (ai-insights/index.html)
- 项目概况分析
- SWOT分析
- 战略建议
- AI问答功能
用户中心页面 (user/index.html)
- 个人资料管理
- 创业项目管理
- 账户设置
4. 状态管理与用户认证
系统使用了简单的状态管理:
- 用localStorage存储用户信息和token
- 通过Auth对象管理用户认证状态:
const Auth = {
isLoggedIn() { /* 检查登录状态 */ },
getUserInfo() { /* 获取用户信息 */ },
logout() { /* 退出登录 */ }
// ...
};5. 数据流与API交互
页面加载流程以分析页面为例:
1. 检查用户登录状态
2. 获取用户信息
3. 获取创业项目数据
4. 基于项目数据请求分析结果
5. 渲染图表和分析内容
API交互示例:
// 获取创业项目数据
async fetchStartupData(id) {
try {
const response = await Services.nocobase.getStartupProjectDetail(id);
if (response && response.data) {
this.startup = {
// 处理数据...
};
this.initCharts(); // 初始化图表
}
} catch (error) {
console.error('获取创业项目数据失败:', error);
this.$message.error('获取项目数据失败');
}
}6. 页面路由与跳转
由于是使用原生HTML+JS而非SPA框架,使用传统的页面跳转方式:
window.location.href = '../analysis/index.html?id=' + startupId;参数传递主要通过URL查询参数实现。
7. 表单处理与数据提交
创业信息表单使用Element UI的表单组件,实现了:
- 分步填写逻辑
- 表单验证
- 草稿保存
- 表单提交
表单提交逻辑:
submitStartupData() {
// 显示加载状态
const loading = this.$loading({/*...*/});
// API提交
Services.nocobase.createStartupProject(this.startupForm)
.then(response => {
this.$message.success('创业信息提交成功');
// 跳转到分析结果页面
window.location.href = '../analysis/index.html';
})
.catch(error => {
this.$message.error('提交失败:' + error.message);
})
.finally(() => {
loading.close();
});
}这个系统Web端采用了组件化的思路,虽然没有使用构建工具,但通过良好的文件组织和模块化开发,实现了一个功能完善的前端应用。
2.小程序
后端
1. 整体架构与技术栈
核心服务组件
- NocoBase服务:核心数据管理与API服务
- Spider-Flow服务:数据采集与爬虫管理
- Superset服务:数据分析与可视化
- AI模型服务:智能分析与洞察生成
部署方式
- 基于Docker容器化部署
- 使用Docker Compose进行多容器编排
- 服务间通过REST API或消息队列通信
2. NocoBase服务(核心后端)
功能职责
- 数据存储与业务逻辑处理中心
- 提供统一API接口给前端应用
- 管理用户认证与权限控制
- 协调其他服务的调用与数据交换
技术特点
- 低代码/无代码平台,支持可视化配置
- RESTful API设计
- 插件化架构,支持功能扩展
核心数据模型
- 创业信息表(startup_info)
- 公开信息表(public_info)
- 数据分析结果表(analysis_results)
- AI模型输出表(ai_insights)
自定义插件开发
- 创业信息匹配插件
- 爬虫触发接口
- 数据分析集成
- AI模型集成
3. Spider-Flow服务(数据采集)
功能职责
- 爬取互联网公开创业数据
- 采集行业分析报告
- 监控竞争对手信息
- 市场趋势数据抓取
技术特点
- 基于图形化界面配置爬虫流程
- 支持定时任务与触发式执行
- 多种数据源支持(网页、API、文档等)
- 数据清洗与结构化处理能力
数据处理流程
- 任务配置与调度
- 数据抓取与提取
- 结构化处理
- 入库到NocoBase
4. Superset服务(数据分析)
功能职责
- 创业数据多维度分析
- 市场规模与趋势可视化
- 竞争格局分析
- 财务预测与模型构建
技术特点
- 强大的SQL查询能力
- 丰富的可视化图表
- 自定义仪表盘功能
- 支持多种数据源连接
分析功能
- 创业项目评分系统
- 市场规模预测模型
- 竞争态势分析
- 财务健康度评估
5. AI模型服务
功能职责
- SWOT分析生成
- 创业成功率预测
- 风险因素识别
- 战略建议生成
技术特点
- 基于机器学习的预测模型
- NLP技术处理文本数据
- 知识图谱分析行业关联
- 推荐算法生成战略建议
模型类型
- 分类模型:创业成功率预测
- NLP模型:文本分析与洞察提取
- 推荐系统:策略建议生成
6. 系统集成与通信
服务间通信
- RESTful API调用
- 消息队列异步通信
- Webhook事件触发
数据流转路径
- 用户输入创业信息 → NocoBase存储
- NocoBase触发爬虫任务 → Spider-Flow执行
- 爬虫数据回传 → NocoBase统一存储
- 数据分析请求 → Superset执行分析
- 分析结果存储 → NocoBase
- AI分析请求 → AI模型服务处理
- AI洞察结果 → 返回并存储到NocoBase
7. 安全与认证
用户认证
- 基于JWT的令牌认证
- 多角色权限控制
- 细粒度的API访问权限
数据安全
- 敏感数据加密存储
- API访问限流
- 完整的审计日志
8. 部署与运维
Docker容器部署
cd 后端服务/nocobase
docker-compose up -d服务管理
- 服务健康监控
- 日志收集与分析
- 自动化备份策略
运维工具
- Docker容器管理
- 日志查看:
docker logs [容器ID或名称] - 服务重启:
docker-compose restart [服务名]
初始配置
- NocoBase管理面板:http://localhost:8000
- 默认管理员账号:admin@nocobase.com
- 默认密码:admin123
这种微服务架构设计使得创业分析平台各组件松耦合,便于独立开发、部署和扩展,同时通过NocoBase作为核心数据管理中心,保证了数据的一致性和服务间的协调性。
使用过程
README.md启动
最好及时查看我在github上的README.md,因为有可能我push在仓库里面,但是这里忘记更新了
# 创业分析平台
这是一个用于分析创业公司数据的综合平台,包含爬虫系统、数据分析工具、创业评估AI模型、Web端和小程序端。
## 系统组件
### 后端服务
- **NocoBase**: 低代码平台作为后端数据管理系统
- **爬虫系统**: 基于Spider-Flow的数据爬取组件
- **数据分析**: 基于Superset的数据分析和可视化工具
### AI模型
- **创业分析模型**: 基于Python的创业公司分析和评估模型
### 前端展示
- **Web端**: 基于HTML/CSS/JavaScript的Web前端
- **小程序端**: 微信小程序界面
## 启动方法
### 0. 一键启动
在PowerShell中执行:
```
.\start_all_services.ps1
```
会依次启动NocoBase后端、数据分析服务(Superset)、爬虫系统(Spider-Flow)和AI模型服务,并提供选项启动Web端。
### 1. 启动NocoBase后端
```
cd 后端服务/nocobase
docker-compose up -d
```
### 2. 启动数据分析服务
```
cd 后端服务/数据分析/superset
docker-compose up -d
```
### 3. 启动爬虫系统
```
cd 后端服务/爬虫系统/spider-flow
docker-compose up -d
```
### 4. 构建并启动AI模型
```
cd AI模型/simple_model
docker build -t startup-analysis-model .
docker run -d -p 5000:5000 --name ai-model startup-analysis-model
```
### 5. 访问Web端
启动HTTP服务器并访问
```
cd web端
.\run_server.bat 或运行 powershell -ExecutionPolicy Bypass -File start_server.ps1
```
然后在浏览器中访问 http://localhost:3000
### 6. 开发小程序端
使用微信开发者工具打开 `小程序端/mybricks-app` 目录进行开发与预览
## 系统访问
- **NocoBase管理界面**: http://localhost:8000/
- **Superset数据分析平台**: http://localhost:8088/
- **AI模型API**: http://localhost:5000/
- **Web端**: http://localhost:3000/
- **小程序端**: 通过微信开发者工具预览
其中如果第四步在pull python3.9的过程中报错的话,可以先单独拉下python
docker pull python:3.9-slim
# 如果上面不行,试试这个
docker pull python:3.9-alpineNocoBase设置
在进入localhost:8000后登入我在nocobase目录下的README.md里面写的管理员登陆账号和密码,(然后可以先在settings里面的系统设置里面选择中文),打开设置里面的“数据源”,选择编辑edit,然后创建数据表,并在数据表中“配置字段”
注意下面的一对一都是选择 belongs to 因为后面创建的都是 startup 旗下的
1.创建 startup_info(创业信息表)
-
点击"创建数据表"按钮
-
填写表信息:
- 表名:
startup_info - 显示名:创业信息
- 描述:存储创业公司基本信息
- 表名:
-
创建以下字段(点击"添加字段"按钮):
- name(文本型):公司/项目名称
- founder(文本型):创始人
- industry(文本型):行业类别
- stage(文本型):发展阶段(选项可设为:种子轮、天使轮、A轮、B轮、C轮、D轮及以上)
- description(长文本型):项目描述
- funding(数字型):融资金额(单位:万元)
- team_size(整数型):团队规模
- founding_date(日期型):成立日期
- contact(文本型):联系方式
-
点击"保存"按钮创建表
2. 创建 public_info(公开信息表)
-
再次点击"创建数据表"按钮
-
填写表信息:
- 表名:
public_info - 显示名:公开信息
- 描述:存储从网络爬取的公开信息
- 表名:
-
创建以下字段:
- startup_id(关联型):关联创业项目
- 在创建此字段时,选择"关联"类型,并关联到 startup_info 表
- source(文本型):信息来源
- content(长文本型):内容
- published_date(日期型):发布日期
- url(文本型):原文链接
- startup_id(关联型):关联创业项目
-
点击"保存"按钮
3. 创建 analysis_results(数据分析结果表)
-
点击"创建数据表"按钮
-
填写表信息:
- 表名:
analysis_results - 显示名:分析结果
- 描述:存储创业项目的数据分析结果
- 表名:
-
创建以下字段:
- startup_id(关联型):关联创业项目(关联到 startup_info 表)
- market_size(数字型):市场规模(单位:亿元)
- competition_level(文本型):竞争程度(可设为选项:低、中、高)
- growth_potential(数字型):增长潜力评分(1-100分)
- risk_factors(长文本型):风险因素
- financial_metrics(JSON型):财务指标
- analysis_date(日期时间型):分析日期
-
点击"保存"按钮
4. 创建 ai_insights(AI模型输出表)
-
点击"创建数据表"按钮
-
填写表信息:
- 表名:
ai_insights - 显示名:AI洞察
- 描述:存储AI模型生成的分析洞察
- 表名:
-
创建以下字段:
- startup_id(关联型):关联创业项目(关联到 startup_info 表)
- success_rate(数字型):成功率评估(百分比)
- strengths(长文本型):优势分析
- weaknesses(长文本型):劣势分析
- opportunities(长文本型):机会分析
- threats(长文本型):威胁分析
- recommendations(长文本型):建议
- generated_date(日期时间型):生成日期
-
点击"保存"按钮
配置页面和表单
创建完所有数据表后,接着打开UI编辑模式,添加页面“创业信息管理”,创建相应的页面和表单:
- 创建"创业信息"管理页面,添加 startup_info 表的表格区块
- 创建"公开信息"页面,添加 public_info 表的表格区块
- 创建"分析结果"页面,添加 analysis_results 表的表格区块
- 创建"AI洞察"页面,添加 ai_insights 表的表格区块
查看服务日志
目的
查看日志可以帮助我们
故障排查、问题诊断
监控系统、优化系统
分析业务、保障安全
开发、运维
数据完整性保障
如何操作
本项目主要查看的有:
- 前端日志:记录用户交互和前端错误
- 后端API服务日志:记录请求处理和业务逻辑
- 爬虫服务日志:记录Spider-Flow爬虫执行情况
- 数据分析服务日志:记录Superset分析引擎运行状态
- AI模型服务日志:记录模型推理过程
docker logs
由于本项目是通过docker容器化部署的,所以可以通过docker语句查看
# 查看指定容器的日志
docker logs [容器ID或名称]
# 例如查看后端API服务日志
docker logs startup-api-service前端开发者控制台
// 在前端代码中查看日志(开发阶段)
console.log('调试信息');
console.error('错误信息');
管理员控制台
- 登录系统后,进入管理员界面
- 导航至"系统管理" → "日志中心"
- 选择日志类型(应用日志、系统日志、安全日志等)
服务器命令行访问
连接到各服务器通过命令行查看:
# 查看API服务最新日志
ssh user@api-server
cd /var/log/startup-platform/
tail -f api-service.log
# 查看爬虫服务日志
ssh user@crawler-server
cd /var/log/spider-flow/
less spider-flow-`date +%Y-%m-%d`.log日志聚合平台
系统集成了日志聚合平台,访问方式:
-
使用统一认证登录
-
进入仪表盘查看汇总日志
日志分析
问题排查流程
- 定位问题:根据用户报告的时间和现象,在日志中查找对应时段的ERROR级别日志
- 追踪上下文:查看错误前后的日志,了解完整调用链
- 确认影响范围:分析是个例还是普遍问题
- 验证解决方案:修复后检查日志确认问题解决
系统监控场景
定期检查以下日志指标:
- 错误率趋势
- API响应时间变化
- 资源使用率
- 爬虫任务成功率
- AI模型推理性能
心得
1.我认为,做一个项目首先要先立下一个基准的、简洁的框架,模块化拓展是后面的事情,base_model 必须要准确且简洁、效率高的,所以一般从思维导图入手,再编写代码
需求文档 -> 可行性分析 -> 流程图、思维导图 -> 产品原型图 -> 代码实现
而且这样也方便根据甲方要求进行修改
2.如果有个问题解决了,就先 push,防止后面更改代码的时候不小心改错了还能拉下来
3.让我对 git 的使用更加加深了,也更加频繁地使用 git status、rm 来防止某些残留
4.终端脚本最好在终端语句写,不知道为什么新建文件写一直报我{ }错误
5.有时候镜像资源会过期,得即时更新


















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









